 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to EdgeNeural Network-Based Time-Frequency-Bin-Wise Linear Combination of Beamformers for Underdetermined Target Source Extraction
Mar 16, 2026Extracting a target source from underdetermined mixtures is challenging for beamforming approaches. Recently proposed time-frequency-bin-wise switching (TFS) and linear combination (TFLC) strategies mitigate this by combining multiple beamformers in each time-frequency (TF) bin and choosing combination weights that minimize the output power. However, making this decision independently for each TF bin can weaken temporal-spectral coherence, causing discontinuities and consequently degrading extraction performance. In this paper, we propose a novel neural network-based time-frequency-bin-wise linear combination (NN-TFLC) framework that constructs minimum power distortionless response (MPDR) beamformers without explicit noise covariance estimation. The network encodes the mixture and beamformer outputs, and predicts temporally and spectrally coherent linear combination weights via a cross-attention mechanism. On dual-microphone mixtures with multiple interferers, NN-TFLC-MPDR consistently outperforms TFS/TFLC-MPDR and achieves competitive performance with TFS/TFLC built on the minimum variance distortionless response (MVDR) beamformers that require noise priors.
Entropy-Guided GRVQ for Ultra-Low Bitrate Neural Speech Codec
Mar 02, 2026Neural audio codec (NAC) is essential for reconstructing high-quality speech signals and generating discrete representations for downstream speech language models. However, ensuring accurate semantic modeling while maintaining high-fidelity reconstruction under ultra-low bitrate constraints remains challenging. We propose an entropy-guided group residual vector quantization (EG-GRVQ) for an ultra-low bitrate neural speech codec, which retains a semantic branch for linguistic information and incorporates an entropy-guided grouping strategy in the acoustic branch. Assuming that channel activations follow approximately Gaussian statistics, the variance of each channel can serve as a principled proxy for its information content. Based on this assumption, we partition the encoder output such that each group carries an equal share of the total information. This balanced allocation improves codebook efficiency and reduces redundancy. Trained on LibriTTS and VCTK, our model shows improvements in perceptual quality and intelligibility metrics under ultra-low bitrate conditions, with a focus on codec-level fidelity for communication-oriented scenarios.
Robust Online Overdetermined Independent Vector Analysis Based on Bilinear Decomposition
Jan 18, 2026Online blind source separation is essential for both speech communication and human-machine interaction. Among existing approaches, overdetermined independent vector analysis (OverIVA) delivers strong performance by exploiting the statistical independence of source signals and the orthogonality between source and noise subspaces. However, when applied to large microphone arrays, the number of parameters grows rapidly, which can degrade online estimation accuracy. To overcome this challenge, we propose decomposing each long separation filter into a bilinear form of two shorter filters, thereby reducing the number of parameters. Because the two filters are closely coupled, we design an alternating iterative projection algorithm to update them in turn. Simulation results show that, with far fewer parameters, the proposed method achieves improved performance and robustness.
Low algorithmic delay implementation of convolutional beamformer for online joint source separation and dereverberation
Jun 14, 2024Blind-audio-source-separation (BASS) techniques, particularly those with low latency, play an important role in a wide range of real-time systems, e.g., hearing aids, in-car hand-free voice communication, real-time human-machine interaction, etc. Most existing BASS algorithms are deduced to run on batch mode, and therefore large latency is unavoidable. Recently, some online algorithms were developed, which achieve separation on a frame-by-frame basis in the short-time-Fourier-transform (STFT) domain and the latency is significantly reduced as compared to those batch methods. However, the latency with these algorithms may still be too long for many real-time systems to bear. To further reduce latency while achieving good separation performance, we propose in this work to integrate a weighted prediction error (WPE) module into a non-causal sample-truncating-based independent vector analysis (NST-IVA). The resulting algorithm can maintain the algorithmic delay as NST-IVA if the delay with WPE is appropriately controlled while achieving significantly better performance, which is validated by simulations.
Unrestricted Global Phase Bias-Aware Single-channel Speech Enhancement with Conformer-based Metric GAN
Feb 13, 2024With the rapid development of neural networks in recent years, the ability of various networks to enhance the magnitude spectrum of noisy speech in the single-channel speech enhancement domain has become exceptionally outstanding. However, enhancing the phase spectrum using neural networks is often ineffective, which remains a challenging problem. In this paper, we found that the human ear cannot sensitively perceive the difference between a precise phase spectrum and a biased phase (BP) spectrum. Therefore, we propose an optimization method of phase reconstruction, allowing freedom on the global-phase bias instead of reconstructing the precise phase spectrum. We applied it to a Conformer-based Metric Generative Adversarial Networks (CMGAN) baseline model, which relaxes the existing constraints of precise phase and gives the neural network a broader learning space. Results show that this method achieves a new state-of-the-art performance without incurring additional computational overhead.
A computationally efficient semi-blind source separation based approach for nonlinear echo cancellation based on an element-wise iterative source steering
Dec 14, 2023



While the semi-blind source separation-based acoustic echo cancellation (SBSS-AEC) has received much research attention due to its promising performance during double-talk compared to the traditional adaptive algorithms, it suffers from system latency and nonlinear distortions. To circumvent these drawbacks, the recently developed ideas on convolutive transfer function (CTF) approximation and nonlinear expansion have been used in the iterative projection (IP)-based semi-blind source separation (SBSS) algorithm. However, because of the introduction of CTF approximation and nonlinear expansion, this algorithm becomes computationally very expensive, which makes it difficult to implement in embedded systems. Thus, we attempt in this paper to improve this IP-based algorithm, thereby developing an element-wise iterative source steering (EISS) algorithm. In comparison with the IP-based SBSS algorithm, the proposed algorithm is computationally much more efficient, especially when the nonlinear expansion order is high and the length of the CTF filter is long. Meanwhile, its AEC performance is as good as that of IP-based SBSS.
Neural network-based virtual microphone estimation with virtual microphone and beamformer-level multi-task loss
Nov 20, 2023


Array processing performance depends on the number of microphones available. Virtual microphone estimation (VME) has been proposed to increase the number of microphone signals artificially. Neural network-based VME (NN-VME) trains an NN with a VM-level loss to predict a signal at a microphone location that is available during training but not at inference. However, this training objective may not be optimal for a specific array processing back-end, such as beamforming. An alternative approach is to use a training objective considering the array-processing back-end, such as a loss on the beamformer output. This approach may generate signals optimal for beamforming but not physically grounded. To combine the advantages of both approaches, this paper proposes a multi-task loss for NN-VME that combines both VM-level and beamformer-level losses. We evaluate the proposed multi-task NN-VME on multi-talker underdetermined conditions and show that it achieves a 33.1 % relative WER improvement compared to using only real microphones and 10.8 % compared to using a prior NN-VME approach.
FastMVAE2: On improving and accelerating the fast variational autoencoder-based source separation algorithm for determined mixtures
Sep 28, 2021
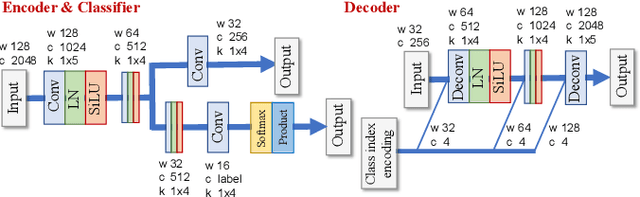
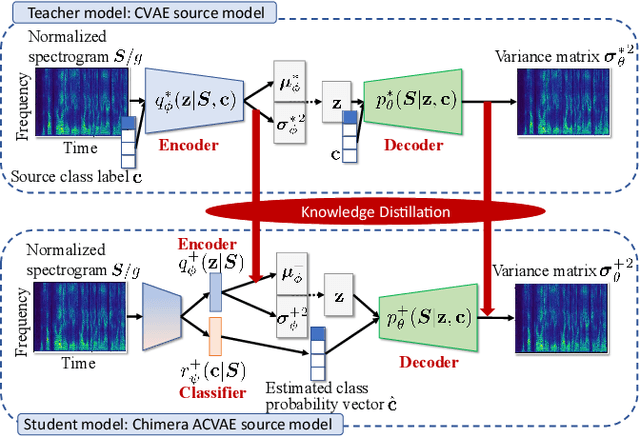
This paper proposes a new source model and training scheme to improve the accuracy and speed of the multichannel variational autoencoder (MVAE) method. The MVAE method is a recently proposed powerful multichannel source separation method. It consists of pretraining a source model represented by a conditional VAE (CVAE) and then estimating separation matrices along with other unknown parameters so that the log-likelihood is non-decreasing given an observed mixture signal. Although the MVAE method has been shown to provide high source separation performance, one drawback is the computational cost of the backpropagation steps in the separation-matrix estimation algorithm. To overcome this drawback, a method called "FastMVAE" was subsequently proposed, which uses an auxiliary classifier VAE (ACVAE) to train the source model. By using the classifier and encoder trained in this way, the optimal parameters of the source model can be inferred efficiently, albeit approximately, in each step of the algorithm. However, the generalization capability of the trained ACVAE source model was not satisfactory, which led to poor performance in situations with unseen data. To improve the generalization capability, this paper proposes a new model architecture (called the "ChimeraACVAE" model) and a training scheme based on knowledge distillation. The experimental results revealed that the proposed source model trained with the proposed loss function achieved better source separation performance with less computation time than FastMVAE. We also confirmed that our methods were able to separate 18 sources with a reasonably good accuracy.
Speech Enhancement by Noise Self-Supervised Rank-Constrained Spatial Covariance Matrix Estimation via Independent Deeply Learned Matrix Analysis
Sep 10, 2021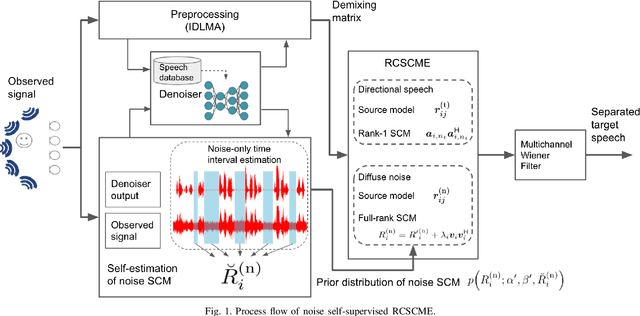
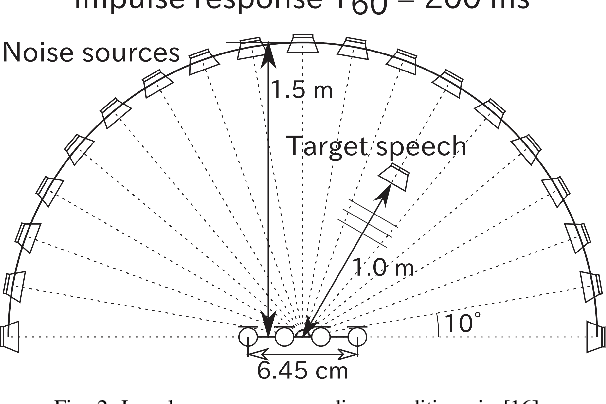
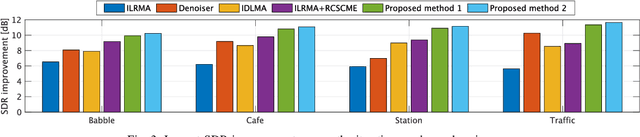
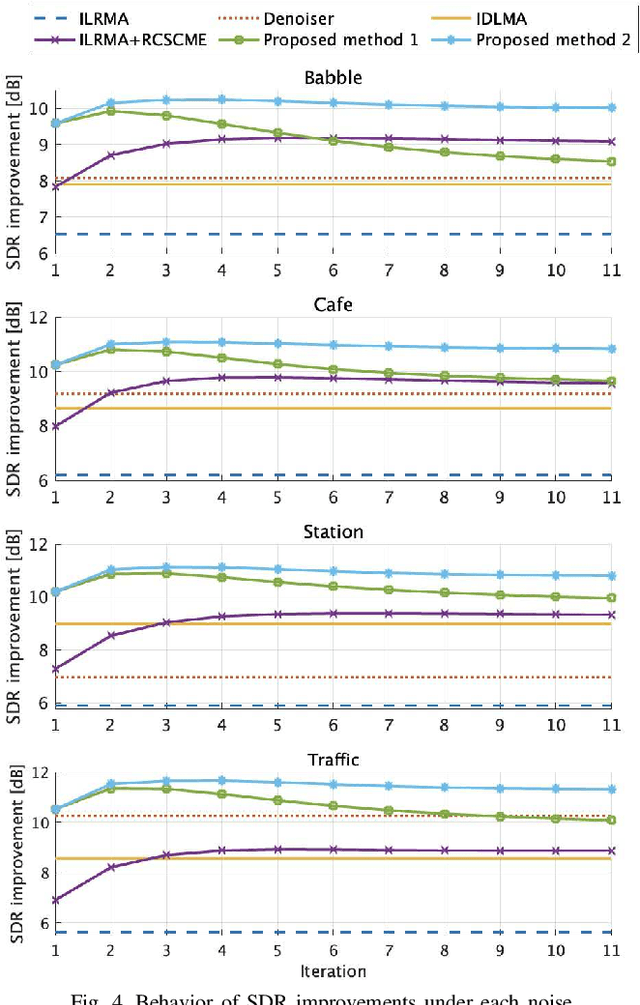
Rank-constrained spatial covariance matrix estimation (RCSCME) is a method for the situation that the directional target speech and the diffuse noise are mixed. In conventional RCSCME, independent low-rank matrix analysis (ILRMA) is used as the preprocessing method. We propose RCSCME using independent deeply learned matrix analysis (IDLMA), which is a supervised extension of ILRMA. In this method, IDLMA requires deep neural networks (DNNs) to separate the target speech and the noise. We use Denoiser, which is a single-channel speech enhancement DNN, in IDLMA to estimate not only the target speech but also the noise. We also propose noise self-supervised RCSCME, in which we estimate the noise-only time intervals using the output of Denoiser and design the prior distribution of the noise spatial covariance matrix for RCSCME. We confirm that the proposed methods outperform the conventional methods under several noise conditions.
Fast MVAE: Joint separation and classification of mixed sources based on multichannel variational autoencoder with auxiliary classifier
Dec 16, 2018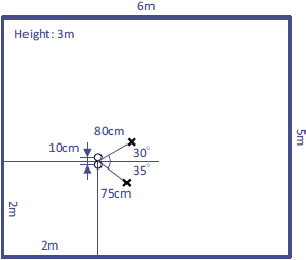
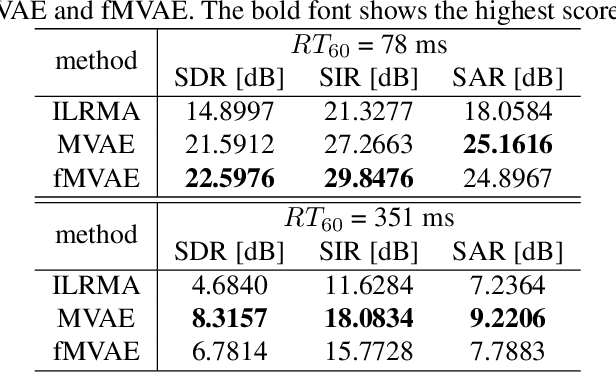
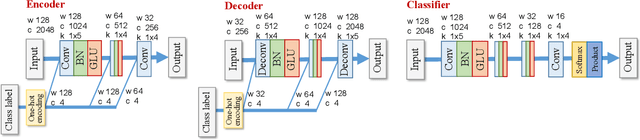
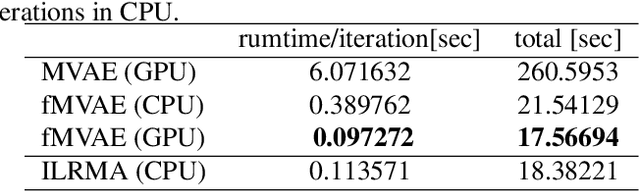
This paper proposes an alternative algorithm for multichannel variational autoencoder (MVAE), a recently proposed multichannel source separation approach. While MVAE is notable in its impressive source separation performance, the convergence-guaranteed optimization algorithm and that it allows us to estimate source-class labels simultaneously with source separation, there are still two major drawbacks, i.e., the high computational complexity and unsatisfactory source classification accuracy. To overcome these drawbacks, the proposed method employs an auxiliary classifier VAE, an information-theoretic extension of the conditional VAE, for learning the generative model of the source spectrograms. Furthermore, with the trained auxiliary classifier, we introduce a novel algorithm for the optimization that is able to not only reduce the computational time but also improve the source classification performance. We call the proposed method "fast MVAE (fMVAE)". Experimental evaluations revealed that fMVAE achieved comparative source separation performance to MVAE and about 80% source classification accuracy rate while it reduced about 93% computational time.