 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to EdgePouring by Feel: An Analysis of Tactile and Proprioceptive Sensing for Accurate Pouring
Oct 27, 2023As service robots begin to be deployed to assist humans, it is important for them to be able to perform a skill as ubiquitous as pouring. Specifically, we focus on the task of pouring an exact amount of water without any environmental instrumentation, that is, using only the robot's own sensors to perform this task in a general way robustly. In our approach we use a simple PID controller which uses the measured change in weight of the held container to supervise the pour. Unlike previous methods which use specialized force-torque sensors at the robot wrist, we use our robot joint torque sensors and investigate the added benefit of tactile sensors at the fingertips. We train three estimators from data which regress the poured weight out of the source container and show that we can accurately pour within 10 ml of the target on average while being robust enough to pour at novel locations and with different grasps on the source container.
EV-Catcher: High-Speed Object Catching Using Low-latency Event-based Neural Networks
Apr 14, 2023



Event-based sensors have recently drawn increasing interest in robotic perception due to their lower latency, higher dynamic range, and lower bandwidth requirements compared to standard CMOS-based imagers. These properties make them ideal tools for real-time perception tasks in highly dynamic environments. In this work, we demonstrate an application where event cameras excel: accurately estimating the impact location of fast-moving objects. We introduce a lightweight event representation called Binary Event History Image (BEHI) to encode event data at low latency, as well as a learning-based approach that allows real-time inference of a confidence-enabled control signal to the robot. To validate our approach, we present an experimental catching system in which we catch fast-flying ping-pong balls. We show that the system is capable of achieving a success rate of 81% in catching balls targeted at different locations, with a velocity of up to 13 m/s even on compute-constrained embedded platforms such as the Nvidia Jetson NX.
KUIELab-MDX-Net: A Two-Stream Neural Network for Music Demixing
Nov 24, 2021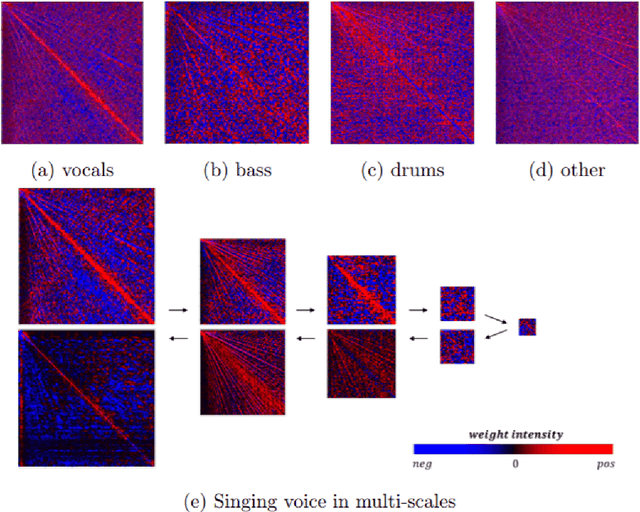

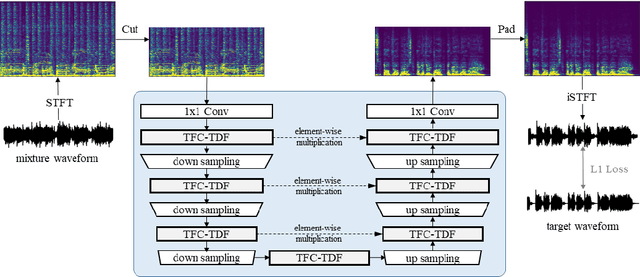
Recently, many methods based on deep learning have been proposed for music source separation. Some state-of-the-art methods have shown that stacking many layers with many skip connections improve the SDR performance. Although such a deep and complex architecture shows outstanding performance, it usually requires numerous computing resources and time for training and evaluation. This paper proposes a two-stream neural network for music demixing, called KUIELab-MDX-Net, which shows a good balance of performance and required resources. The proposed model has a time-frequency branch and a time-domain branch, where each branch separates stems, respectively. It blends results from two streams to generate the final estimation. KUIELab-MDX-Net took second place on leaderboard A and third place on leaderboard B in the Music Demixing Challenge at ISMIR 2021. This paper also summarizes experimental results on another benchmark, MUSDB18. Our source code is available online.
AuraSense: Robot Collision Avoidance by Full Surface Proximity Detection
Aug 10, 2021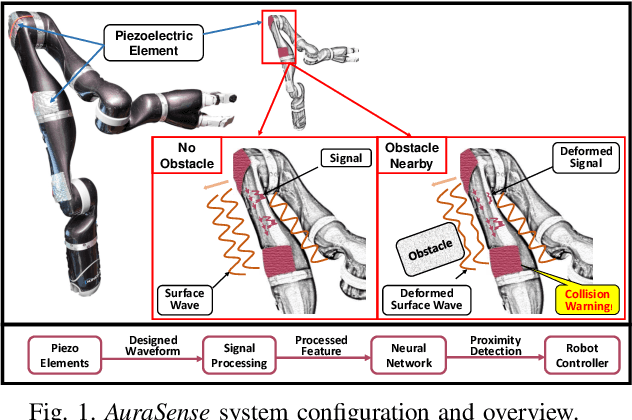
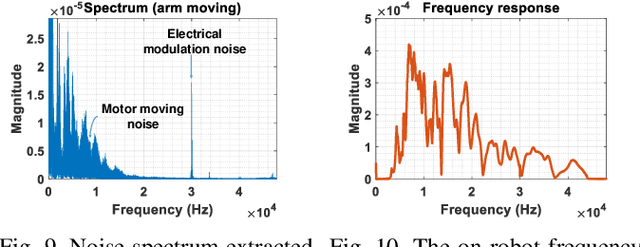
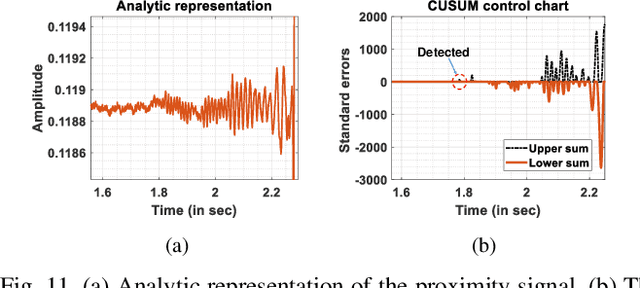
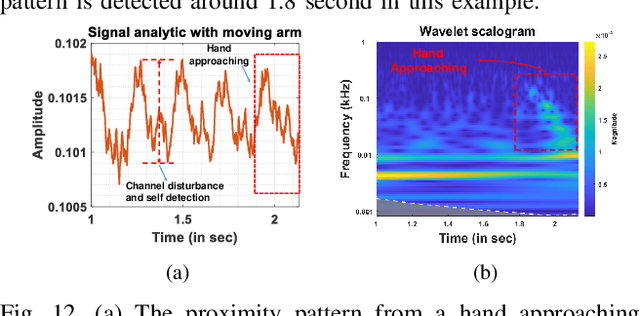
Perceiving obstacles and avoiding collisions is fundamental to the safe operation of a robot system, particularly when the robot must operate in highly dynamic human environments. Proximity detection using on-robot sensors can be used to avoid or mitigate impending collisions. However, existing proximity sensing methods are orientation and placement dependent, resulting in blind spots even with large numbers of sensors. In this paper, we introduce the phenomenon of the Leaky Surface Wave (LSW), a novel sensing modality, and present AuraSense, a proximity detection system using the LSW. AuraSense is the first system to realize no-dead-spot proximity sensing for robot arms. It requires only a single pair of piezoelectric transducers, and can easily be applied to off-the-shelf robots with minimal modifications. We further introduce a set of signal processing techniques and a lightweight neural network to address the unique challenges in using the LSW for proximity sensing. Finally, we demonstrate a prototype system consisting of a single piezoelectric element pair on a robot manipulator, which validates our design. We conducted several micro benchmark experiments and performed more than 2000 on-robot proximity detection trials with various potential robot arm materials, colliding objects, approach patterns, and robot movement patterns. AuraSense achieves 100% and 95.3% true positive proximity detection rates when the arm approaches static and mobile obstacles respectively, with a true negative rate over 99%, showing the real-world viability of this system.
Investigating Deep Neural Transformations for Spectrogram-based Musical Source Separation
Dec 09, 2019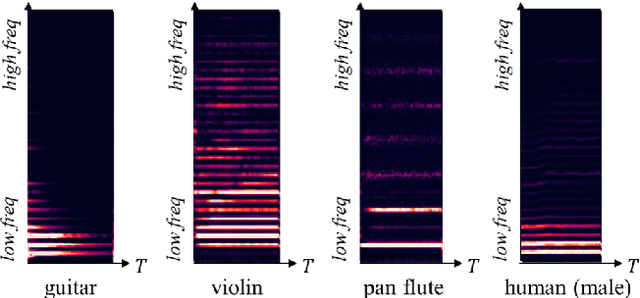
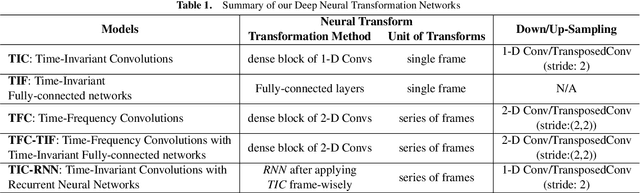
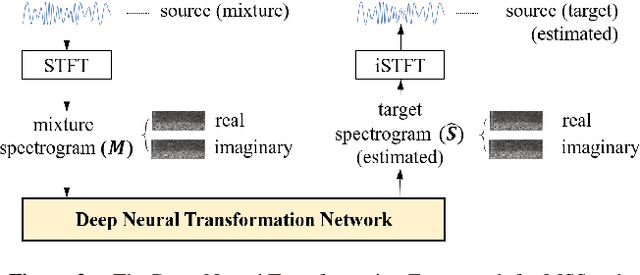

Musical Source Separation (MSS) is a signal processing task that tries to separate the mixed musical signal into each acoustic sound source, such as singing voice or drums. Recently many machine learning-based methods have been proposed for the MSS task, but there were no existing works that evaluate and directly compare various types of networks. In this paper, we aim to design a variety of neural transformation methods, including time-invariant methods, time-frequency methods, and mixtures of two different transformations. Our experiments provide abundant material for future works by comparing several transformation methods. We train our models on raw complex-valued STFT outputs and achieve state-of-the-art SDR performance on the MUSDB singing voice separation task by a large margin of 1.0 dB.
Higher Order Function Networks for View Planning and Multi-View Reconstruction
Oct 04, 2019
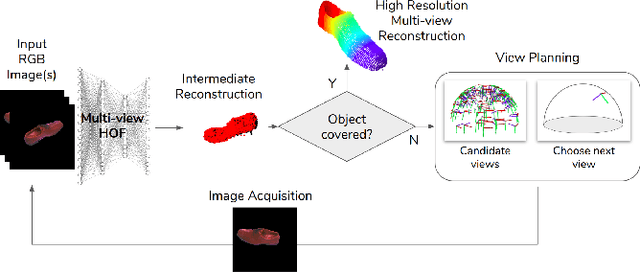
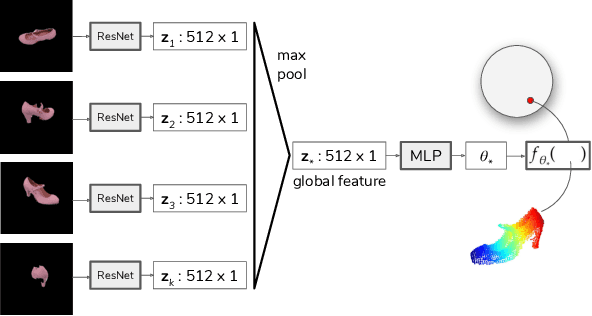
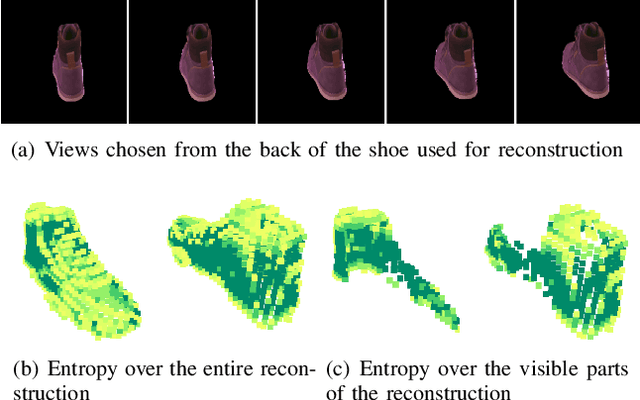
We consider the problem of planning views for a robot to acquire images of an object for visual inspection and reconstruction. In contrast to offline methods which require a 3D model of the object as input or online methods which rely on only local measurements, our method uses a neural network which encodes shape information for a large number of objects. We build on recent deep learning methods capable of generating a complete 3D reconstruction of an object from a single image. Specifically, in this work, we extend a recent method which uses Higher Order Functions (HOF) to represent the shape of the object. We present a new generalization of this method to incorporate multiple images as input and establish a connection between visibility and reconstruction quality. This relationship forms the foundation of our view planning method where we compute viewpoints to visually cover the output of the multi-view HOF network with as few images as possible. Experiments indicate that our method provides a good compromise between online and offline methods: Similar to online methods, our method does not require the true object model as input. In terms of number of views, it is much more efficient. In most cases, its performance is comparable to the optimal offline case even on object classes the network has not been trained on.
Pixels to Plans: Learning Non-Prehensile Manipulation by Imitating a Planner
Apr 05, 2019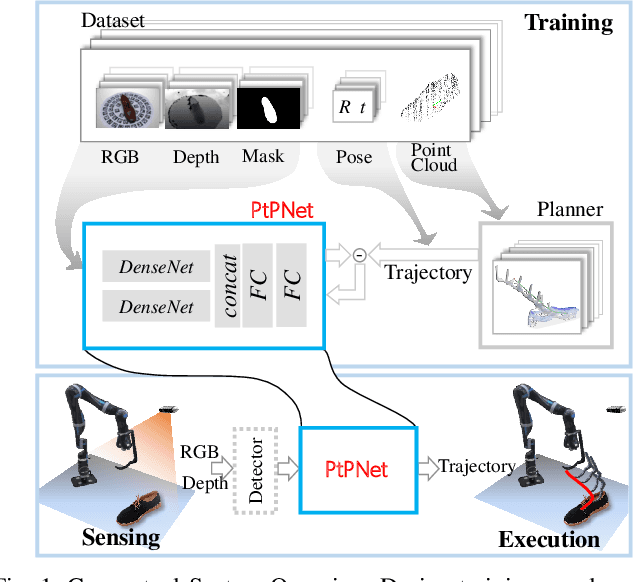
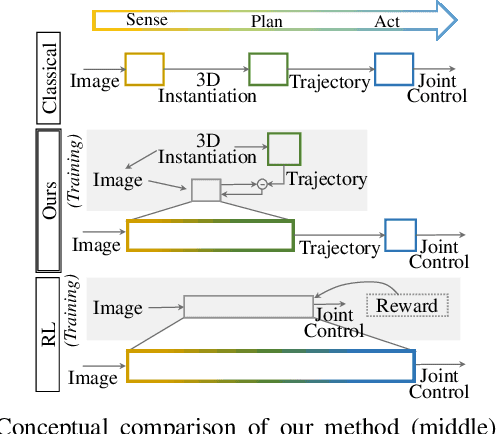
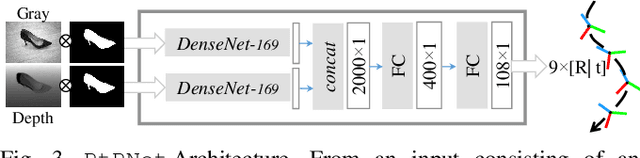
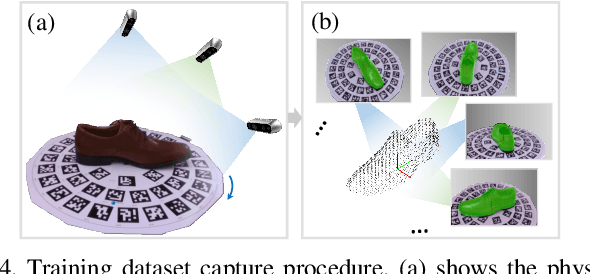
We present a novel method enabling robots to quickly learn to manipulate objects by leveraging a motion planner to generate "expert" training trajectories from a small amount of human-labeled data. In contrast to the traditional sense-plan-act cycle, we propose a deep learning architecture and training regimen called PtPNet that can estimate effective end-effector trajectories for manipulation directly from a single RGB-D image of an object. Additionally, we present a data collection and augmentation pipeline that enables the automatic generation of large numbers (millions) of training image and trajectory examples with almost no human labeling effort. We demonstrate our approach in a non-prehensile tool-based manipulation task, specifically picking up shoes with a hook. In hardware experiments, PtPNet generates motion plans (open-loop trajectories) that reliably (89% success over 189 trials) pick up four very different shoes from a range of positions and orientations, and reliably picks up a shoe it has never seen before. Compared with a traditional sense-plan-act paradigm, our system has the advantages of operating on sparse information (single RGB-D frame), producing high-quality trajectories much faster than the "expert" planner (300ms versus several seconds), and generalizing effectively to previously unseen shoes.