 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to EdgeLearning To Reach Goals Without Reinforcement Learning
Dec 13, 2019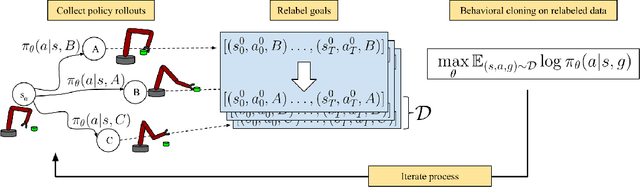

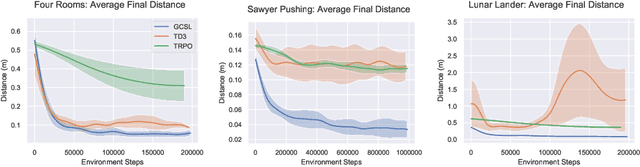
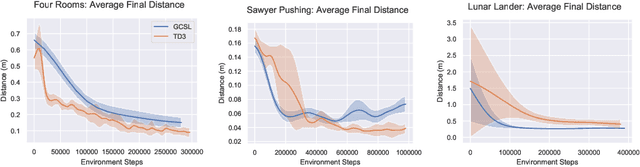
Imitation learning algorithms provide a simple and straightforward approach for training control policies via supervised learning. By maximizing the likelihood of good actions provided by an expert demonstrator, supervised imitation learning can produce effective policies without the algorithmic complexities and optimization challenges of reinforcement learning, at the cost of requiring an expert demonstrator to provide the demonstrations. In this paper, we ask: can we take insights from imitation learning to design algorithms that can effectively acquire optimal policies from scratch without any expert demonstrations? The key observation that makes this possible is that, in the multi-task setting, trajectories that are generated by a suboptimal policy can still serve as optimal examples for other tasks. In particular, when tasks correspond to different goals, every trajectory is a successful demonstration for the goal state that it actually reaches. We propose a simple algorithm for learning goal-reaching behaviors without any demonstrations, complicated user-provided reward functions, or complex reinforcement learning methods. Our method simply maximizes the likelihood of actions the agent actually took in its own previous rollouts, conditioned on the goal being the state that it actually reached. Although related variants of this approach have been proposed previously in imitation learning with demonstrations, we show how this approach can effectively learn goal-reaching policies from scratch. We present a theoretical result linking self-supervised imitation learning and reinforcement learning, and empirical results showing that it performs competitively with more complex reinforcement learning methods on a range of challenging goal reaching problems, while yielding advantages in terms of stability and use of offline data.
SMiRL: Surprise Minimizing RL in Dynamic Environments
Dec 11, 2019

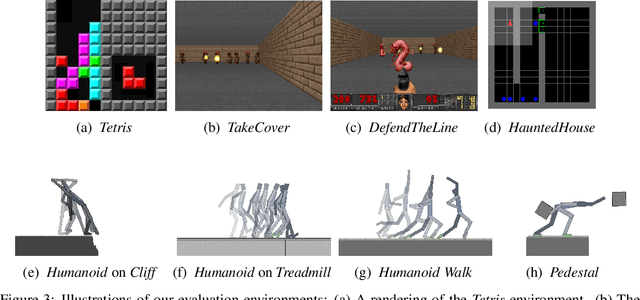
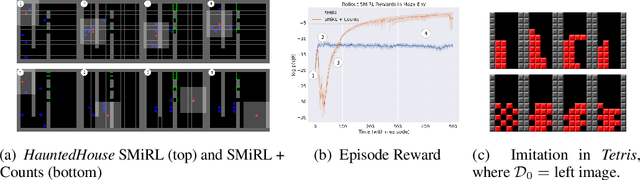
All living organisms struggle against the forces of nature to carve out niches where they can maintain homeostasis. We propose that such a search for order amidst chaos might offer a unifying principle for the emergence of useful behaviors in artificial agents. We formalize this idea into an unsupervised reinforcement learning method called surprise minimizing RL (SMiRL). SMiRL trains an agent with the objective of maximizing the probability of observed states under a model trained on previously seen states. The resulting agents can acquire proactive behaviors that seek out and maintain stable conditions, such as balancing and damage avoidance, that are closely tied to an environment's prevailing sources of entropy, such as wind, earthquakes, and other agents. We demonstrate that our surprise minimizing agents can successfully play Tetris, Doom, control a humanoid to avoid falls and navigate to escape enemy agents, without any task-specific reward supervision. We further show that SMiRL can be used together with a standard task reward to accelerate reward-driven learning.
Plan Arithmetic: Compositional Plan Vectors for Multi-Task Control
Oct 30, 2019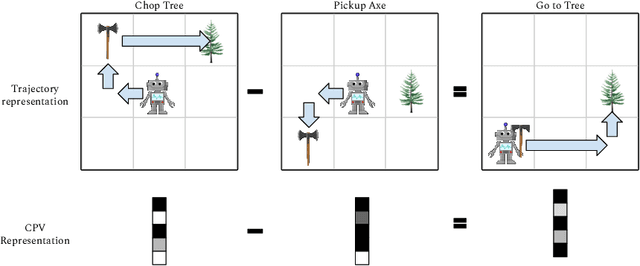
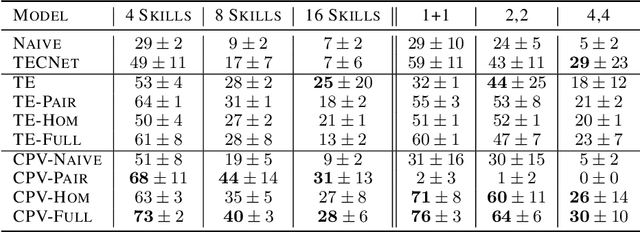
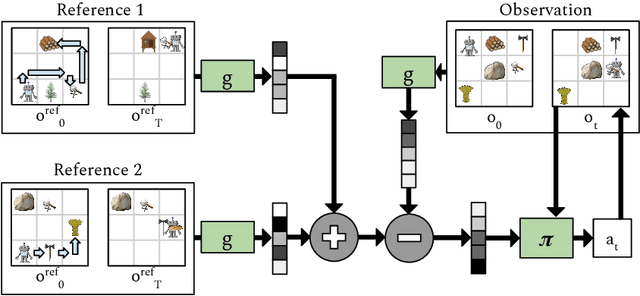
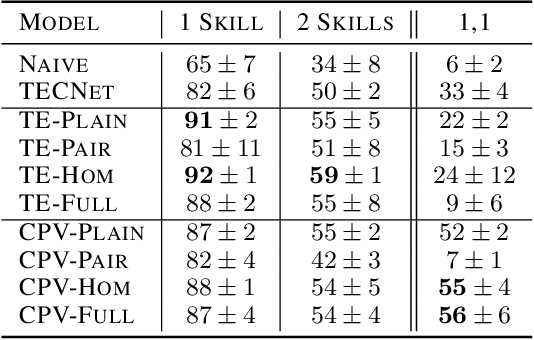
Autonomous agents situated in real-world environments must be able to master large repertoires of skills. While a single short skill can be learned quickly, it would be impractical to learn every task independently. Instead, the agent should share knowledge across behaviors such that each task can be learned efficiently, and such that the resulting model can generalize to new tasks, especially ones that are compositions or subsets of tasks seen previously. A policy conditioned on a goal or demonstration has the potential to share knowledge between tasks if it sees enough diversity of inputs. However, these methods may not generalize to a more complex task at test time. We introduce compositional plan vectors (CPVs) to enable a policy to perform compositions of tasks without additional supervision. CPVs represent trajectories as the sum of the subtasks within them. We show that CPVs can be learned within a one-shot imitation learning framework without any additional supervision or information about task hierarchy, and enable a demonstration-conditioned policy to generalize to tasks that sequence twice as many skills as the tasks seen during training. Analogously to embeddings such as word2vec in NLP, CPVs can also support simple arithmetic operations -- for example, we can add the CPVs for two different tasks to command an agent to compose both tasks, without any additional training.
Monocular Plan View Networks for Autonomous Driving
May 16, 2019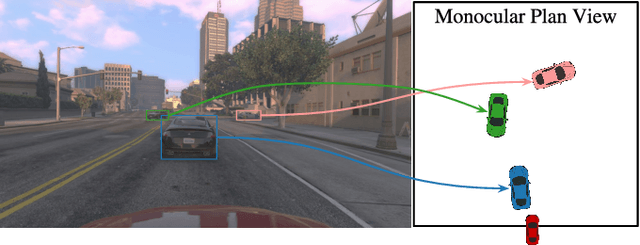

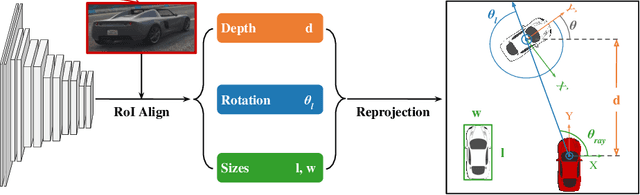
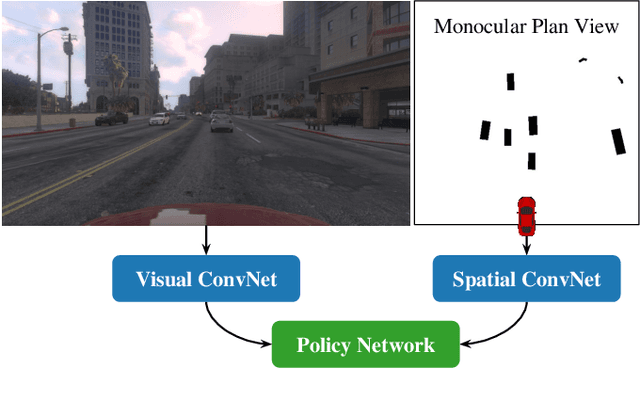
Convolutions on monocular dash cam videos capture spatial invariances in the image plane but do not explicitly reason about distances and depth. We propose a simple transformation of observations into a bird's eye view, also known as plan view, for end-to-end control. We detect vehicles and pedestrians in the first person view and project them into an overhead plan view. This representation provides an abstraction of the environment from which a deep network can easily deduce the positions and directions of entities. Additionally, the plan view enables us to leverage advances in 3D object detection in conjunction with deep policy learning. We evaluate our monocular plan view network on the photo-realistic Grand Theft Auto V simulator. A network using both a plan view and front view causes less than half as many collisions as previous detection-based methods and an order of magnitude fewer collisions than pure pixel-based policies.
Deep Object-Centric Policies for Autonomous Driving
Mar 01, 2019
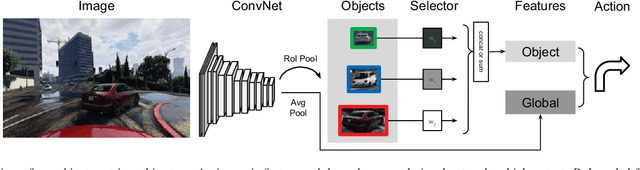

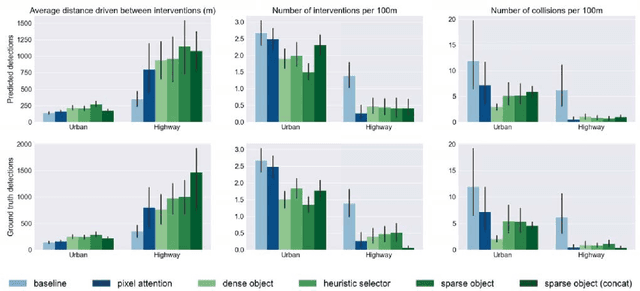
While learning visuomotor skills in an end-to-end manner is appealing, deep neural networks are often uninterpretable and fail in surprising ways. For robotics tasks, such as autonomous driving, models that explicitly represent objects may be more robust to new scenes and provide intuitive visualizations. We describe a taxonomy of "object-centric" models which leverage both object instances and end-to-end learning. In the Grand Theft Auto V simulator, we show that object-centric models outperform object-agnostic methods in scenes with other vehicles and pedestrians, even with an imperfect detector. We also demonstrate that our architectures perform well on real-world environments by evaluating on the Berkeley DeepDrive Video dataset, where an object-centric model outperforms object-agnostic models in the low-data regimes.
Grasp2Vec: Learning Object Representations from Self-Supervised Grasping
Nov 19, 2018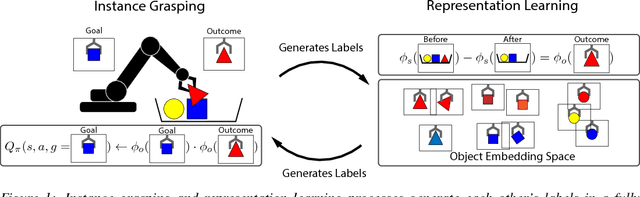


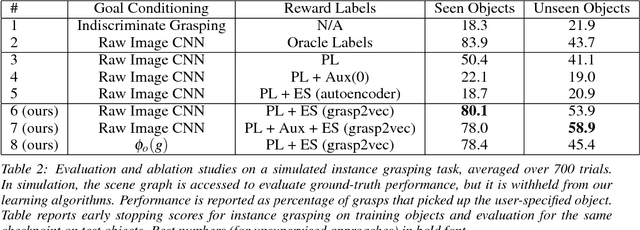
Well structured visual representations can make robot learning faster and can improve generalization. In this paper, we study how we can acquire effective object-centric representations for robotic manipulation tasks without human labeling by using autonomous robot interaction with the environment. Such representation learning methods can benefit from continuous refinement of the representation as the robot collects more experience, allowing them to scale effectively without human intervention. Our representation learning approach is based on object persistence: when a robot removes an object from a scene, the representation of that scene should change according to the features of the object that was removed. We formulate an arithmetic relationship between feature vectors from this observation, and use it to learn a representation of scenes and objects that can then be used to identify object instances, localize them in the scene, and perform goal-directed grasping tasks where the robot must retrieve commanded objects from a bin. The same grasping procedure can also be used to automatically collect training data for our method, by recording images of scenes, grasping and removing an object, and recording the outcome. Our experiments demonstrate that this self-supervised approach for tasked grasping substantially outperforms direct reinforcement learning from images and prior representation learning methods.
* CoRL 2018. Eric Jang and Coline Devin contributed equally to this work
Deep Object-Centric Representations for Generalizable Robot Learning
Sep 26, 2017

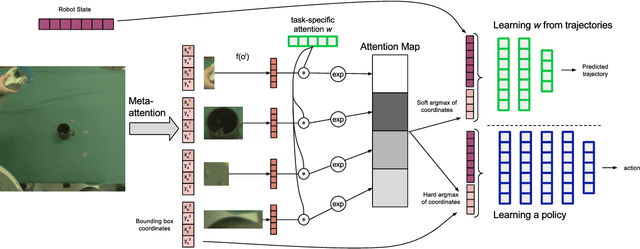

Robotic manipulation in complex open-world scenarios requires both reliable physical manipulation skills and effective and generalizable perception. In this paper, we propose a method where general purpose pretrained visual models serve as an object-centric prior for the perception system of a learned policy. We devise an object-level attentional mechanism that can be used to determine relevant objects from a few trajectories or demonstrations, and then immediately incorporate those objects into a learned policy. A task-independent meta-attention locates possible objects in the scene, and a task-specific attention identifies which objects are predictive of the trajectories. The scope of the task-specific attention is easily adjusted by showing demonstrations with distractor objects or with diverse relevant objects. Our results indicate that this approach exhibits good generalization across object instances using very few samples, and can be used to learn a variety of manipulation tasks using reinforcement learning.
Adapting Deep Visuomotor Representations with Weak Pairwise Constraints
May 25, 2017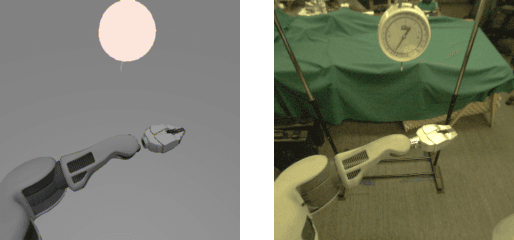

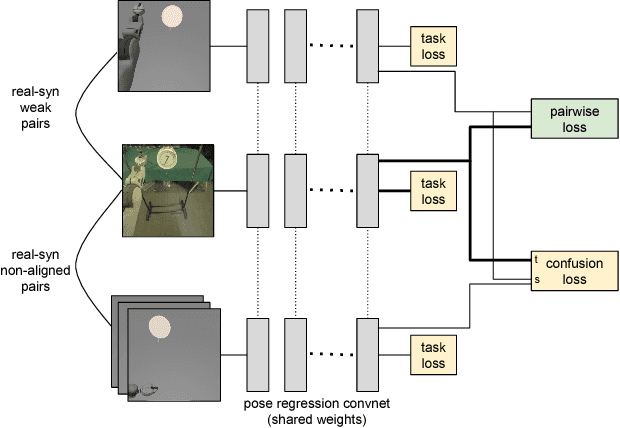
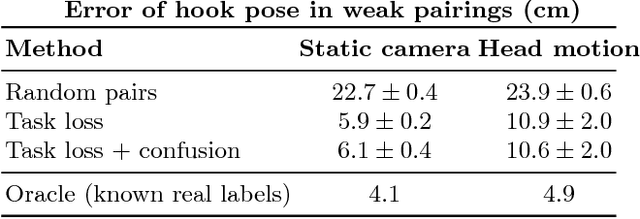
Real-world robotics problems often occur in domains that differ significantly from the robot's prior training environment. For many robotic control tasks, real world experience is expensive to obtain, but data is easy to collect in either an instrumented environment or in simulation. We propose a novel domain adaptation approach for robot perception that adapts visual representations learned on a large easy-to-obtain source dataset (e.g. synthetic images) to a target real-world domain, without requiring expensive manual data annotation of real world data before policy search. Supervised domain adaptation methods minimize cross-domain differences using pairs of aligned images that contain the same object or scene in both the source and target domains, thus learning a domain-invariant representation. However, they require manual alignment of such image pairs. Fully unsupervised adaptation methods rely on minimizing the discrepancy between the feature distributions across domains. We propose a novel, more powerful combination of both distribution and pairwise image alignment, and remove the requirement for expensive annotation by using weakly aligned pairs of images in the source and target domains. Focusing on adapting from simulation to real world data using a PR2 robot, we evaluate our approach on a manipulation task and show that by using weakly paired images, our method compensates for domain shift more effectively than previous techniques, enabling better robot performance in the real world.
Learning Invariant Feature Spaces to Transfer Skills with Reinforcement Learning
Mar 08, 2017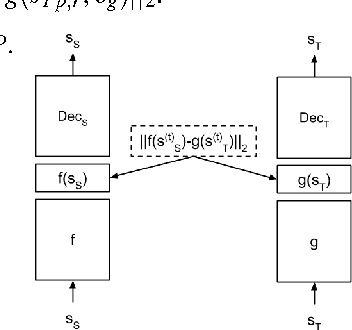



People can learn a wide range of tasks from their own experience, but can also learn from observing other creatures. This can accelerate acquisition of new skills even when the observed agent differs substantially from the learning agent in terms of morphology. In this paper, we examine how reinforcement learning algorithms can transfer knowledge between morphologically different agents (e.g., different robots). We introduce a problem formulation where two agents are tasked with learning multiple skills by sharing information. Our method uses the skills that were learned by both agents to train invariant feature spaces that can then be used to transfer other skills from one agent to another. The process of learning these invariant feature spaces can be viewed as a kind of "analogy making", or implicit learning of partial correspondences between two distinct domains. We evaluate our transfer learning algorithm in two simulated robotic manipulation skills, and illustrate that we can transfer knowledge between simulated robotic arms with different numbers of links, as well as simulated arms with different actuation mechanisms, where one robot is torque-driven while the other is tendon-driven.
Learning Modular Neural Network Policies for Multi-Task and Multi-Robot Transfer
Sep 22, 2016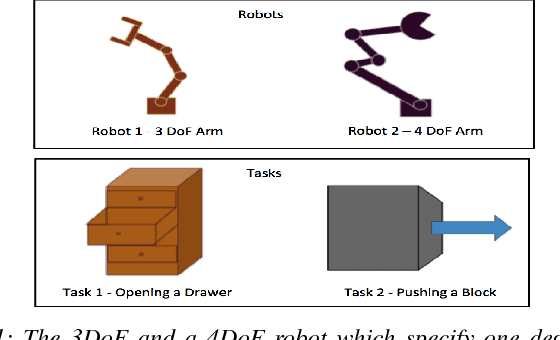
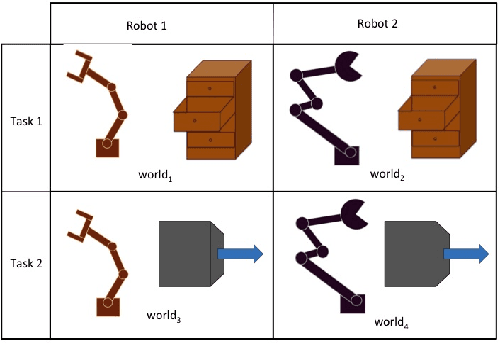
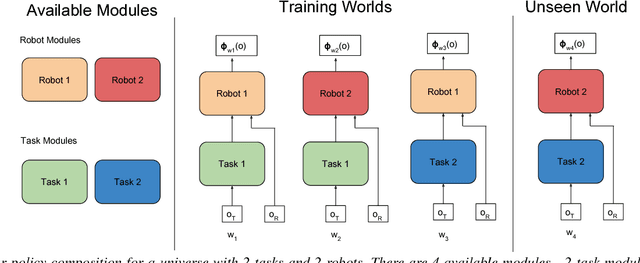
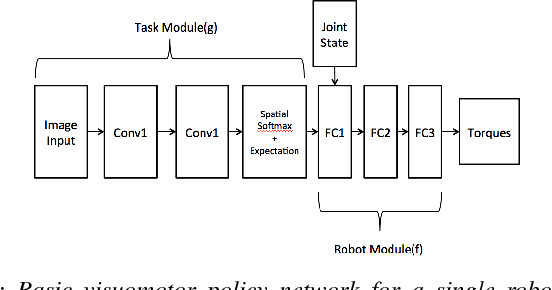
Reinforcement learning (RL) can automate a wide variety of robotic skills, but learning each new skill requires considerable real-world data collection and manual representation engineering to design policy classes or features. Using deep reinforcement learning to train general purpose neural network policies alleviates some of the burden of manual representation engineering by using expressive policy classes, but exacerbates the challenge of data collection, since such methods tend to be less efficient than RL with low-dimensional, hand-designed representations. Transfer learning can mitigate this problem by enabling us to transfer information from one skill to another and even from one robot to another. We show that neural network policies can be decomposed into "task-specific" and "robot-specific" modules, where the task-specific modules are shared across robots, and the robot-specific modules are shared across all tasks on that robot. This allows for sharing task information, such as perception, between robots and sharing robot information, such as dynamics and kinematics, between tasks. We exploit this decomposition to train mix-and-match modules that can solve new robot-task combinations that were not seen during training. Using a novel neural network architecture, we demonstrate the effectiveness of our transfer method for enabling zero-shot generalization with a variety of robots and tasks in simulation for both visual and non-visual tasks.