 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to EdgeImproving Machine Reading Comprehension with General Reading Strategies
Oct 31, 2018
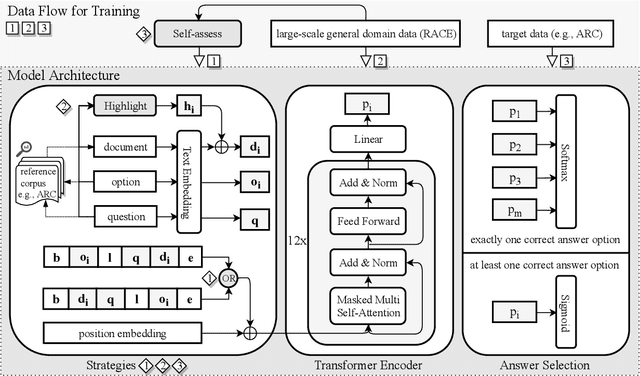
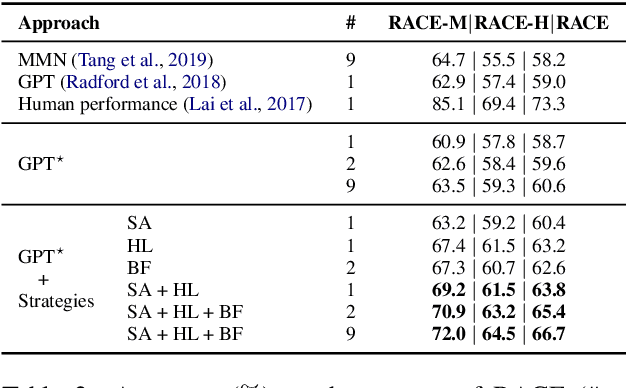
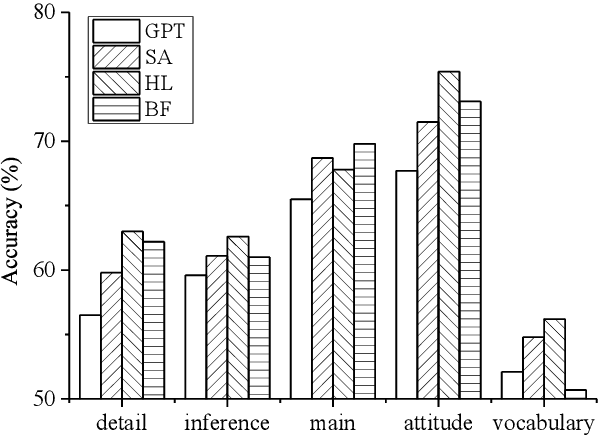
Reading strategies have been shown to improve comprehension levels, especially for readers lacking adequate prior knowledge. Just as the process of knowledge accumulation is time-consuming for human readers, it is resource-demanding to impart rich general domain knowledge into a language model via pre-training (Radford et al., 2018; Devlin et al., 2018). Inspired by reading strategies identified in cognitive science, and given limited computational resources - just a pre-trained model and a fixed number of training instances - we therefore propose three simple domain-independent strategies aimed to improve non-extractive machine reading comprehension (MRC): (i) BACK AND FORTH READING that considers both the original and reverse order of an input sequence, (ii) HIGHLIGHTING, which adds a trainable embedding to the text embedding of tokens that are relevant to the question and candidate answers, and (iii) SELF-ASSESSMENT that generates practice questions and candidate answers directly from the text in an unsupervised manner. By fine-tuning a pre-trained language model (Radford et al., 2018) with our proposed strategies on the largest existing general domain multiple-choice MRC dataset RACE, we obtain a 5.8% absolute increase in accuracy over the previous best result achieved by the same pre-trained model fine-tuned on RACE without the use of strategies. We further fine-tune the resulting model on a target task, leading to new state-of-the-art results on six representative non-extractive MRC datasets from different domains (i.e., ARC, OpenBookQA, MCTest, MultiRC, SemEval-2018, and ROCStories). These results indicate the effectiveness of the proposed strategies and the versatility and general applicability of our fine-tuned models that incorporate these strategies.
Zero-Resource Multilingual Model Transfer: Learning What to Share
Oct 08, 2018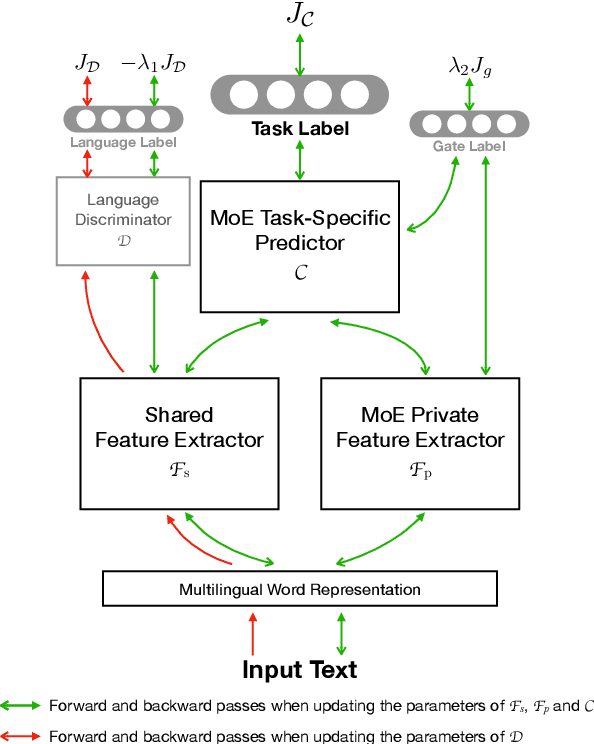
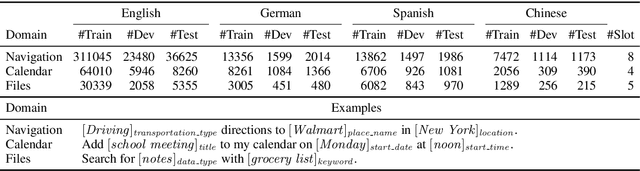
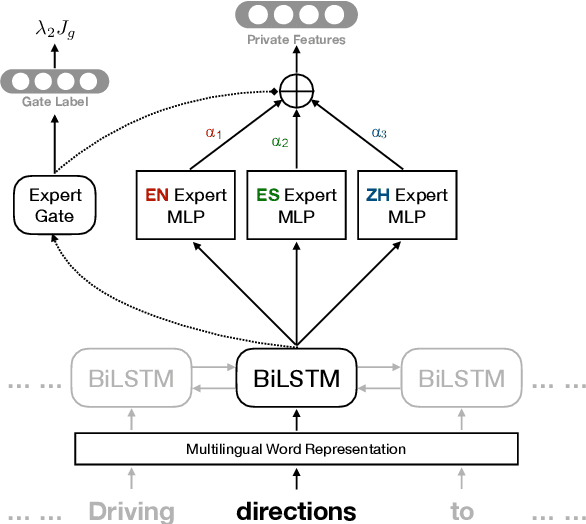
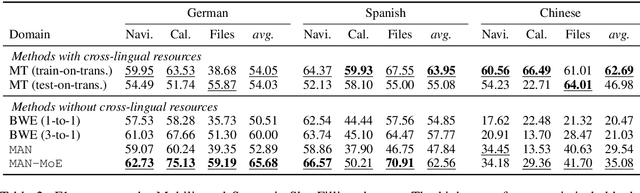
Modern natural language processing and understanding applications have enjoyed a great boost utilizing neural networks models. However, this is not the case for most languages especially low-resource ones with insufficient annotated training data. Cross-lingual transfer learning methods improve the performance on a low-resource target language by leveraging labeled data from other (source) languages, typically with the help of cross-lingual resources such as parallel corpora. In this work, we propose the first zero-resource multilingual transfer learning model that can utilize training data in multiple source languages, while not requiring target language training data nor cross-lingual supervision. Unlike existing methods that only rely on language-invariant features for cross-lingual transfer, our approach utilizes both language-invariant and language-specific features in a coherent way. Our model leverages adversarial networks to learn language-invariant features and mixture-of-experts models to dynamically exploit the relation between the target language and each individual source language. This enables our model to learn effectively what to share between various languages in the multilingual setup. It results in significant performance gains over prior art, as shown in an extensive set of experiments over multiple text classification and sequence tagging tasks including a large-scale real-world industry dataset.
Unsupervised Multilingual Word Embeddings
Sep 06, 2018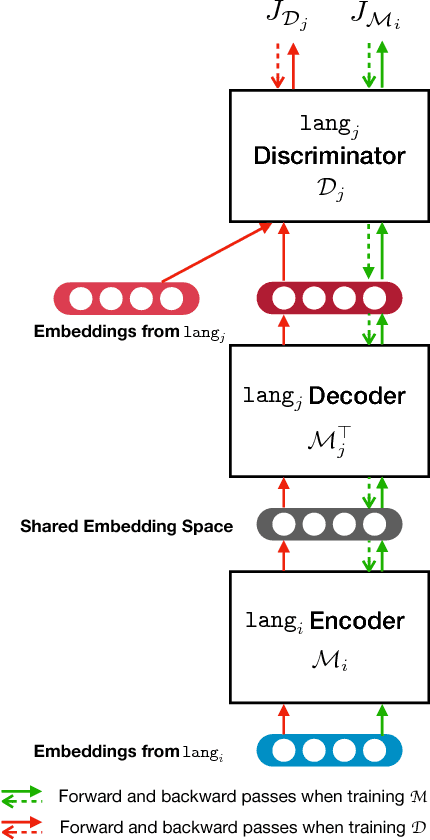
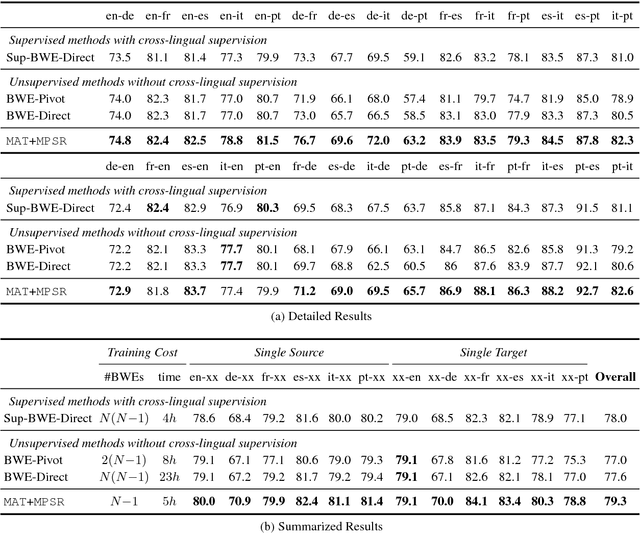
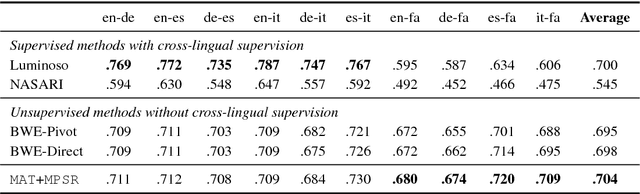
Multilingual Word Embeddings (MWEs) represent words from multiple languages in a single distributional vector space. Unsupervised MWE (UMWE) methods acquire multilingual embeddings without cross-lingual supervision, which is a significant advantage over traditional supervised approaches and opens many new possibilities for low-resource languages. Prior art for learning UMWEs, however, merely relies on a number of independently trained Unsupervised Bilingual Word Embeddings (UBWEs) to obtain multilingual embeddings. These methods fail to leverage the interdependencies that exist among many languages. To address this shortcoming, we propose a fully unsupervised framework for learning MWEs that directly exploits the relations between all language pairs. Our model substantially outperforms previous approaches in the experiments on multilingual word translation and cross-lingual word similarity. In addition, our model even beats supervised approaches trained with cross-lingual resources.
Towards Dynamic Computation Graphs via Sparse Latent Structure
Sep 03, 2018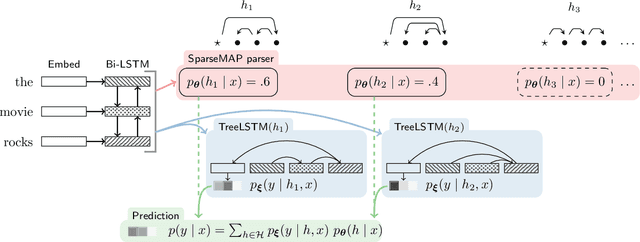
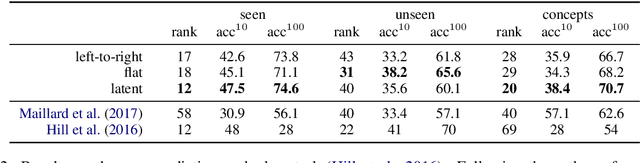
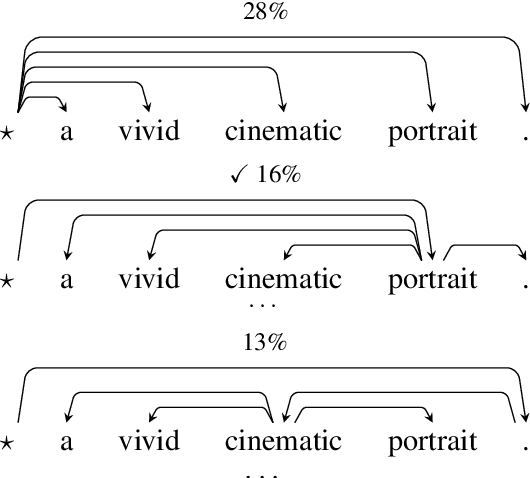
Deep NLP models benefit from underlying structures in the data---e.g., parse trees---typically extracted using off-the-shelf parsers. Recent attempts to jointly learn the latent structure encounter a tradeoff: either make factorization assumptions that limit expressiveness, or sacrifice end-to-end differentiability. Using the recently proposed SparseMAP inference, which retrieves a sparse distribution over latent structures, we propose a novel approach for end-to-end learning of latent structure predictors jointly with a downstream predictor. To the best of our knowledge, our method is the first to enable unrestricted dynamic computation graph construction from the global latent structure, while maintaining differentiability.
Adversarial Deep Averaging Networks for Cross-Lingual Sentiment Classification
Aug 18, 2018In recent years great success has been achieved in sentiment classification for English, thanks in part to the availability of copious annotated resources. Unfortunately, most languages do not enjoy such an abundance of labeled data. To tackle the sentiment classification problem in low-resource languages without adequate annotated data, we propose an Adversarial Deep Averaging Network (ADAN) to transfer the knowledge learned from labeled data on a resource-rich source language to low-resource languages where only unlabeled data exists. ADAN has two discriminative branches: a sentiment classifier and an adversarial language discriminator. Both branches take input from a shared feature extractor to learn hidden representations that are simultaneously indicative for the classification task and invariant across languages. Experiments on Chinese and Arabic sentiment classification demonstrate that ADAN significantly outperforms state-of-the-art systems.
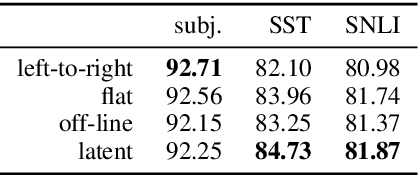
SparseMAP: Differentiable Sparse Structured Inference
Jun 20, 2018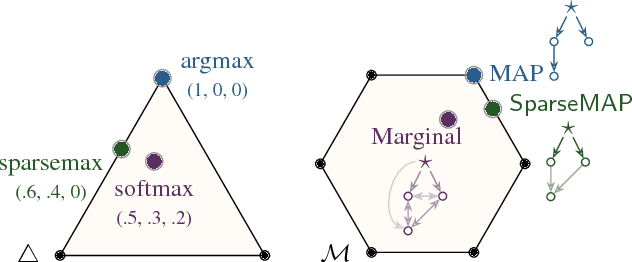
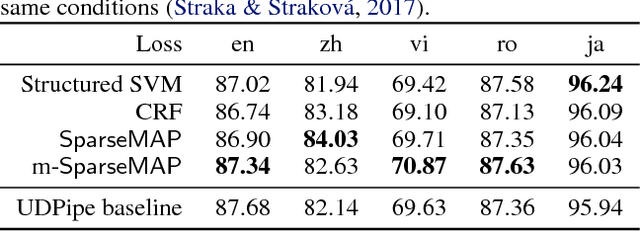
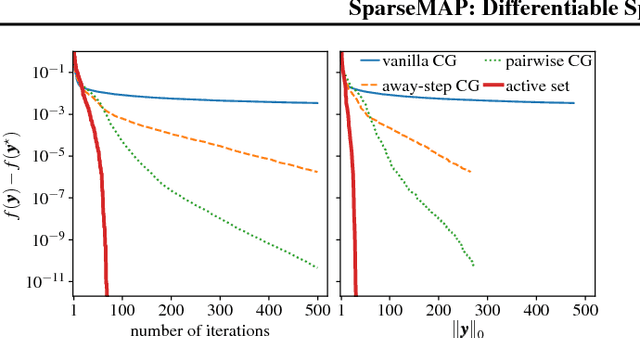

Structured prediction requires searching over a combinatorial number of structures. To tackle it, we introduce SparseMAP: a new method for sparse structured inference, and its natural loss function. SparseMAP automatically selects only a few global structures: it is situated between MAP inference, which picks a single structure, and marginal inference, which assigns probability mass to all structures, including implausible ones. Importantly, SparseMAP can be computed using only calls to a MAP oracle, making it applicable to problems with intractable marginal inference, e.g., linear assignment. Sparsity makes gradient backpropagation efficient regardless of the structure, enabling us to augment deep neural networks with generic and sparse structured hidden layers. Experiments in dependency parsing and natural language inference reveal competitive accuracy, improved interpretability, and the ability to capture natural language ambiguities, which is attractive for pipeline systems.
The Neural Painter: Multi-Turn Image Generation
Jun 16, 2018
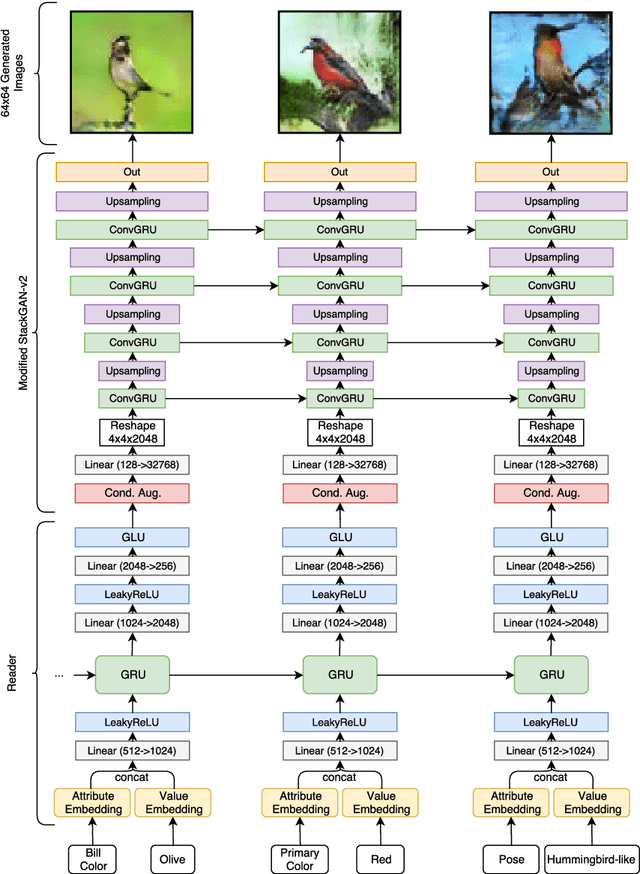
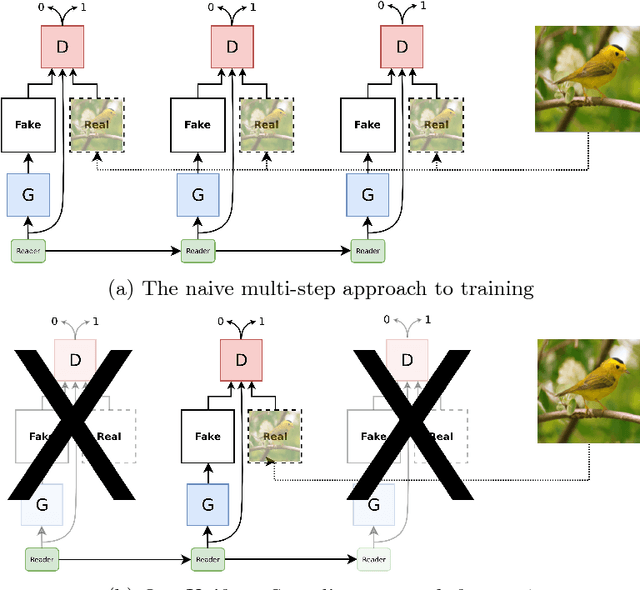

In this work we combine two research threads from Vision/ Graphics and Natural Language Processing to formulate an image generation task conditioned on attributes in a multi-turn setting. By multiturn, we mean the image is generated in a series of steps of user-specified conditioning information. Our proposed approach is practically useful and offers insights into neural interpretability. We introduce a framework that includes a novel training algorithm as well as model improvements built for the multi-turn setting. We demonstrate that this framework generates a sequence of images that match the given conditioning information and that this task is useful for more detailed benchmarking and analysis of conditional image generation methods.
Harvesting Paragraph-Level Question-Answer Pairs from Wikipedia
May 15, 2018

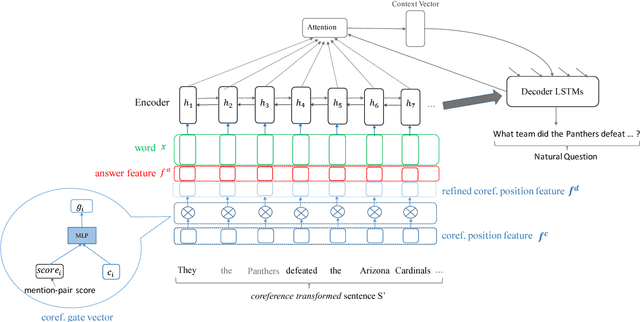
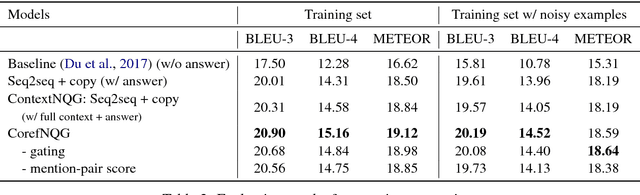
We study the task of generating from Wikipedia articles question-answer pairs that cover content beyond a single sentence. We propose a neural network approach that incorporates coreference knowledge via a novel gating mechanism. Compared to models that only take into account sentence-level information (Heilman and Smith, 2010; Du et al., 2017; Zhou et al., 2017), we find that the linguistic knowledge introduced by the coreference representation aids question generation significantly, producing models that outperform the current state-of-the-art. We apply our system (composed of an answer span extraction system and the passage-level QG system) to the 10,000 top-ranking Wikipedia articles and create a corpus of over one million question-answer pairs. We also provide a qualitative analysis for this large-scale generated corpus from Wikipedia.
Multinomial Adversarial Networks for Multi-Domain Text Classification
Feb 15, 2018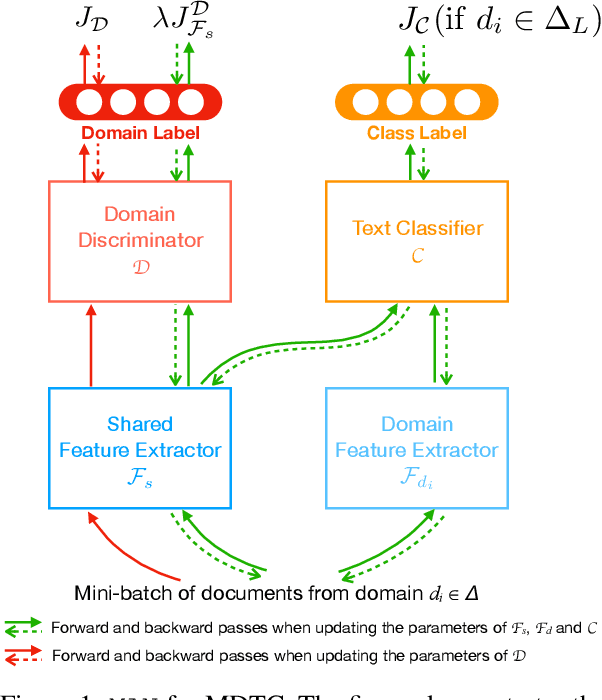
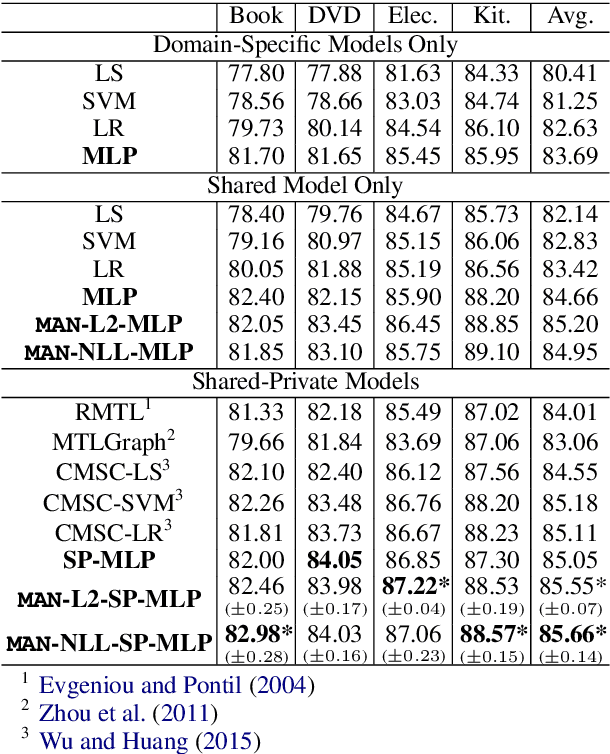
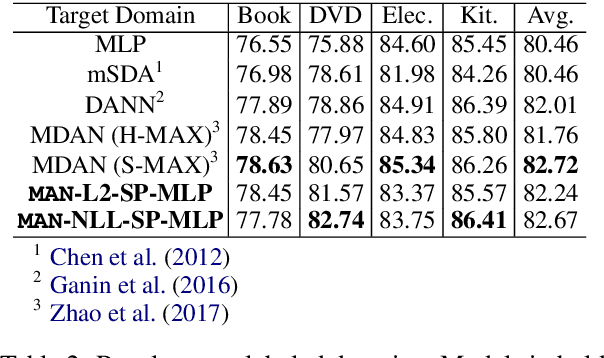
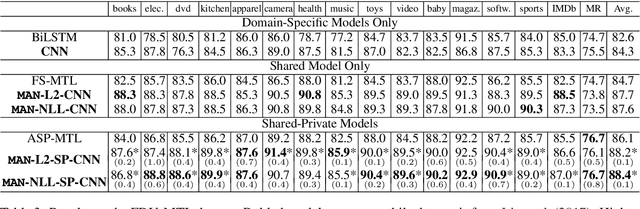
Many text classification tasks are known to be highly domain-dependent. Unfortunately, the availability of training data can vary drastically across domains. Worse still, for some domains there may not be any annotated data at all. In this work, we propose a multinomial adversarial network (MAN) to tackle the text classification problem in this real-world multidomain setting (MDTC). We provide theoretical justifications for the MAN framework, proving that different instances of MANs are essentially minimizers of various f-divergence metrics (Ali and Silvey, 1966) among multiple probability distributions. MANs are thus a theoretically sound generalization of traditional adversarial networks that discriminate over two distributions. More specifically, for the MDTC task, MAN learns features that are invariant across multiple domains by resorting to its ability to reduce the divergence among the feature distributions of each domain. We present experimental results showing that MANs significantly outperform the prior art on the MDTC task. We also show that MANs achieve state-of-the-art performance for domains with no labeled data.
Learning to Ask: Neural Question Generation for Reading Comprehension
Apr 29, 2017

We study automatic question generation for sentences from text passages in reading comprehension. We introduce an attention-based sequence learning model for the task and investigate the effect of encoding sentence- vs. paragraph-level information. In contrast to all previous work, our model does not rely on hand-crafted rules or a sophisticated NLP pipeline; it is instead trainable end-to-end via sequence-to-sequence learning. Automatic evaluation results show that our system significantly outperforms the state-of-the-art rule-based system. In human evaluations, questions generated by our system are also rated as being more natural (i.e., grammaticality, fluency) and as more difficult to answer (in terms of syntactic and lexical divergence from the original text and reasoning needed to answer).