 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to EdgeHOP, UNION, GENERATE: Explainable Multi-hop Reasoning without Rationale Supervision
May 23, 2023



Explainable multi-hop question answering (QA) not only predicts answers but also identifies rationales, i. e. subsets of input sentences used to derive the answers. This problem has been extensively studied under the supervised setting, where both answer and rationale annotations are given. Because rationale annotations are expensive to collect and not always available, recent efforts have been devoted to developing methods that do not rely on supervision for rationales. However, such methods have limited capacities in modeling interactions between sentences, let alone reasoning across multiple documents. This work proposes a principled, probabilistic approach for training explainable multi-hop QA systems without rationale supervision. Our approach performs multi-hop reasoning by explicitly modeling rationales as sets, enabling the model to capture interactions between documents and sentences within a document. Experimental results show that our approach is more accurate at selecting rationales than the previous methods, while maintaining similar accuracy in predicting answers.
Fashionpedia-Ads: Do Your Favorite Advertisements Reveal Your Fashion Taste?
May 03, 2023
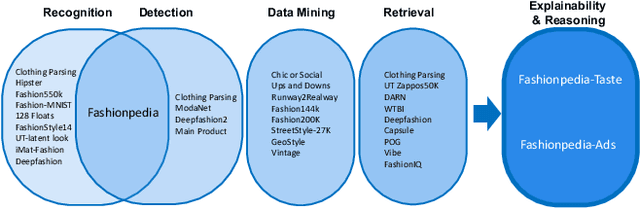


Consumers are exposed to advertisements across many different domains on the internet, such as fashion, beauty, car, food, and others. On the other hand, fashion represents second highest e-commerce shopping category. Does consumer digital record behavior on various fashion ad images reveal their fashion taste? Does ads from other domains infer their fashion taste as well? In this paper, we study the correlation between advertisements and fashion taste. Towards this goal, we introduce a new dataset, Fashionpedia-Ads, which asks subjects to provide their preferences on both ad (fashion, beauty, car, and dessert) and fashion product (social network and e-commerce style) images. Furthermore, we exhaustively collect and annotate the emotional, visual and textual information on the ad images from multi-perspectives (abstractive level, physical level, captions, and brands). We open-source Fashionpedia-Ads to enable future studies and encourage more approaches to interpretability research between advertisements and fashion taste.
Fashionpedia-Taste: A Dataset towards Explaining Human Fashion Taste
May 03, 2023



Existing fashion datasets do not consider the multi-facts that cause a consumer to like or dislike a fashion image. Even two consumers like a same fashion image, they could like this image for total different reasons. In this paper, we study the reason why a consumer like a certain fashion image. Towards this goal, we introduce an interpretability dataset, Fashionpedia-taste, consist of rich annotation to explain why a subject like or dislike a fashion image from the following 3 perspectives: 1) localized attributes; 2) human attention; 3) caption. Furthermore, subjects are asked to provide their personal attributes and preference on fashion, such as personality and preferred fashion brands. Our dataset makes it possible for researchers to build computational models to fully understand and interpret human fashion taste from different humanistic perspectives and modalities.
Automatic Error Analysis for Document-level Information Extraction
Sep 15, 2022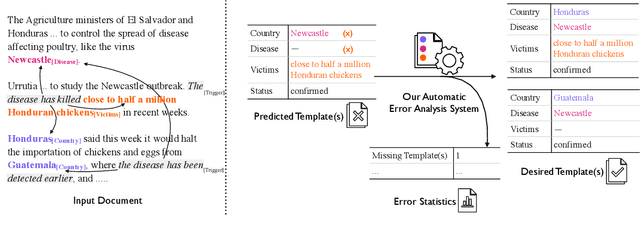
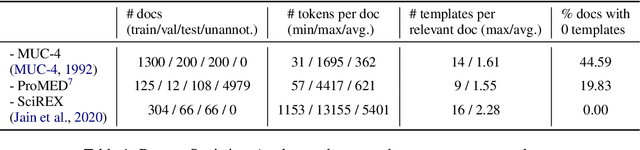
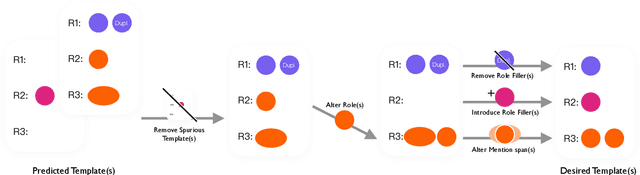
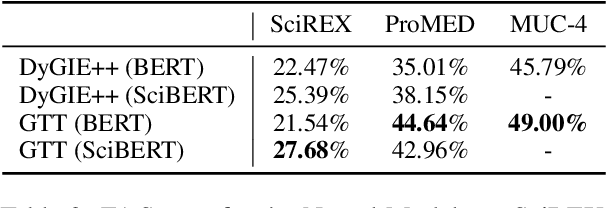
Document-level information extraction (IE) tasks have recently begun to be revisited in earnest using the end-to-end neural network techniques that have been successful on their sentence-level IE counterparts. Evaluation of the approaches, however, has been limited in a number of dimensions. In particular, the precision/recall/F1 scores typically reported provide few insights on the range of errors the models make. We build on the work of Kummerfeld and Klein (2013) to propose a transformation-based framework for automating error analysis in document-level event and (N-ary) relation extraction. We employ our framework to compare two state-of-the-art document-level template-filling approaches on datasets from three domains; and then, to gauge progress in IE since its inception 30 years ago, vs. four systems from the MUC-4 (1992) evaluation.
* Accepted to ACL 2022 Main Conference. First three authors contributed equally to this work
Compositional Task-Oriented Parsing as Abstractive Question Answering
May 04, 2022
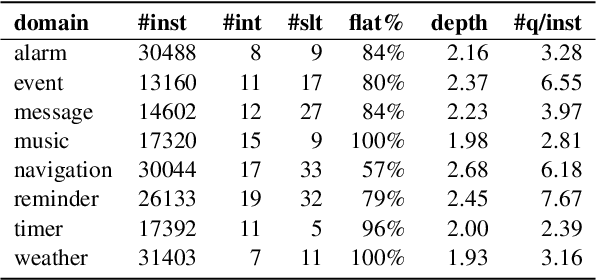
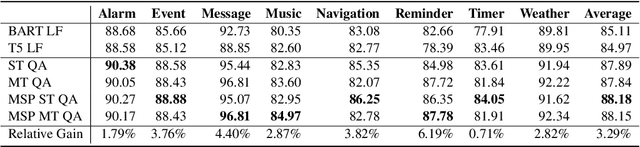

Task-oriented parsing (TOP) aims to convert natural language into machine-readable representations of specific tasks, such as setting an alarm. A popular approach to TOP is to apply seq2seq models to generate linearized parse trees. A more recent line of work argues that pretrained seq2seq models are better at generating outputs that are themselves natural language, so they replace linearized parse trees with canonical natural-language paraphrases that can then be easily translated into parse trees, resulting in so-called naturalized parsers. In this work we continue to explore naturalized semantic parsing by presenting a general reduction of TOP to abstractive question answering that overcomes some limitations of canonical paraphrasing. Experimental results show that our QA-based technique outperforms state-of-the-art methods in full-data settings while achieving dramatic improvements in few-shot settings.
Visual Prompt Tuning
Mar 23, 2022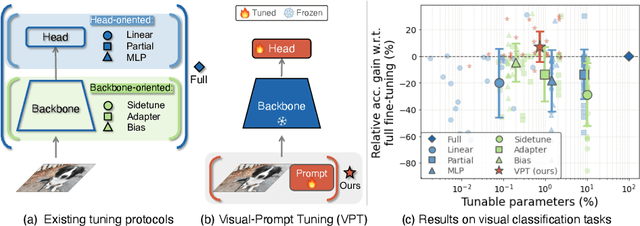

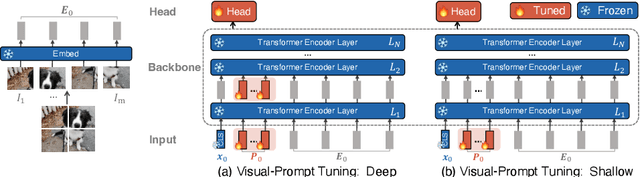
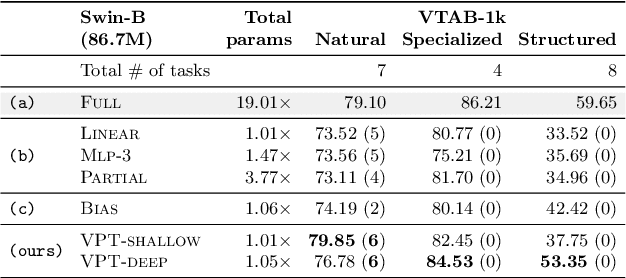
The current modus operandi in adapting pre-trained models involves updating all the backbone parameters, ie, full fine-tuning. This paper introduces Visual Prompt Tuning (VPT) as an efficient and effective alternative to full fine-tuning for large-scale Transformer models in vision. Taking inspiration from recent advances in efficiently tuning large language models, VPT introduces only a small amount (less than 1% of model parameters) of trainable parameters in the input space while keeping the model backbone frozen. Via extensive experiments on a wide variety of downstream recognition tasks, we show that VPT achieves significant performance gains compared to other parameter efficient tuning protocols. Most importantly, VPT even outperforms full fine-tuning in many cases across model capacities and training data scales, while reducing per-task storage cost.
Rethinking Nearest Neighbors for Visual Classification
Dec 17, 2021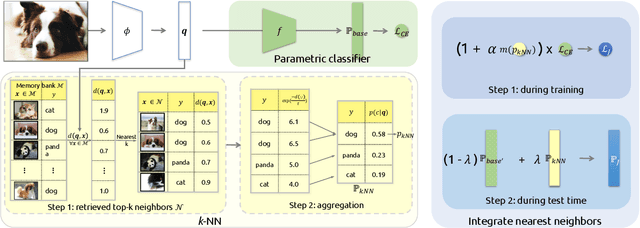
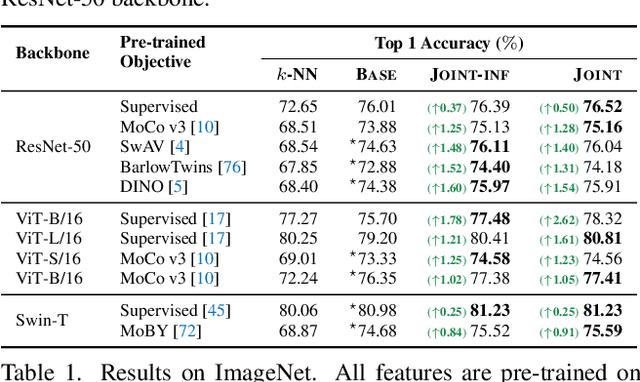
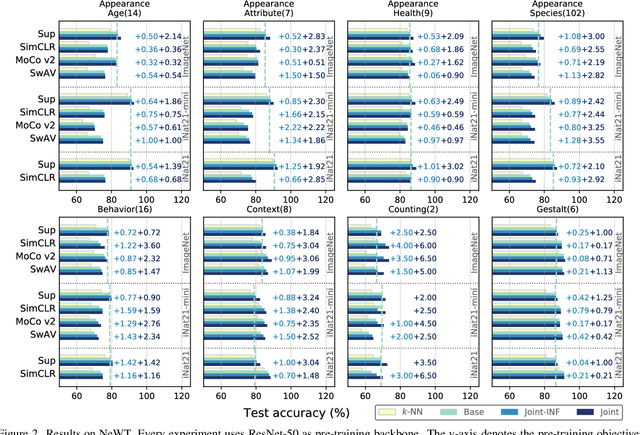
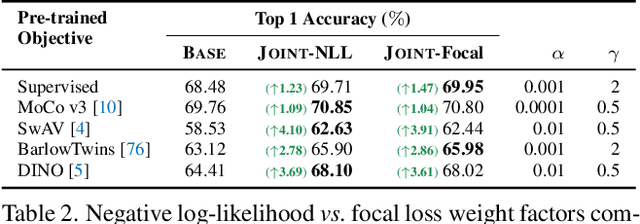
Neural network classifiers have become the de-facto choice for current "pre-train then fine-tune" paradigms of visual classification. In this paper, we investigate k-Nearest-Neighbor (k-NN) classifiers, a classical model-free learning method from the pre-deep learning era, as an augmentation to modern neural network based approaches. As a lazy learning method, k-NN simply aggregates the distance between the test image and top-k neighbors in a training set. We adopt k-NN with pre-trained visual representations produced by either supervised or self-supervised methods in two steps: (1) Leverage k-NN predicted probabilities as indications for easy vs. hard examples during training. (2) Linearly interpolate the k-NN predicted distribution with that of the augmented classifier. Via extensive experiments on a wide range of classification tasks, our study reveals the generality and flexibility of k-NN integration with additional insights: (1) k-NN achieves competitive results, sometimes even outperforming a standard linear classifier. (2) Incorporating k-NN is especially beneficial for tasks where parametric classifiers perform poorly and / or in low-data regimes. We hope these discoveries will encourage people to rethink the role of pre-deep learning, classical methods in computer vision. Our code is available at: https://github.com/KMnP/nn-revisit.
When in Doubt: Improving Classification Performance with Alternating Normalization
Sep 28, 2021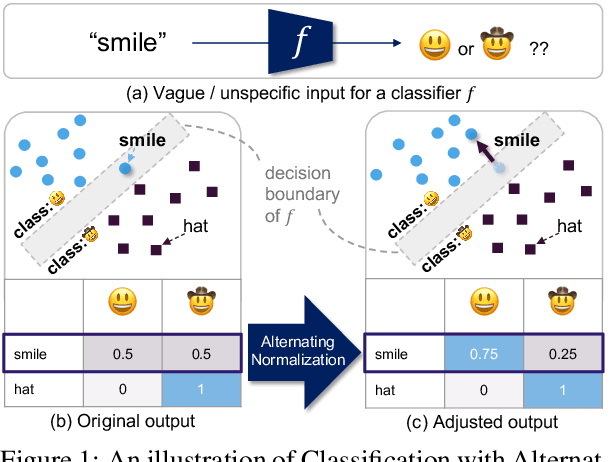
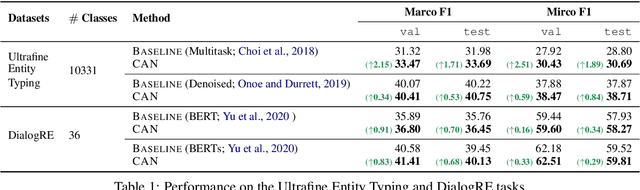
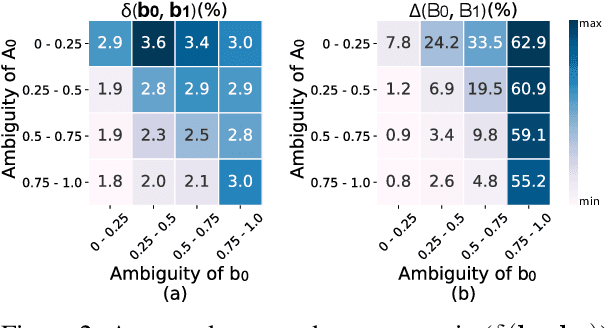
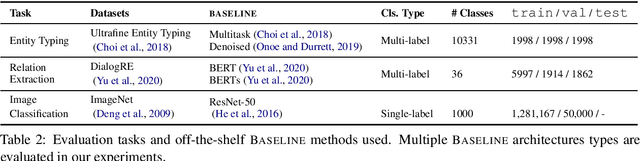
We introduce Classification with Alternating Normalization (CAN), a non-parametric post-processing step for classification. CAN improves classification accuracy for challenging examples by re-adjusting their predicted class probability distribution using the predicted class distributions of high-confidence validation examples. CAN is easily applicable to any probabilistic classifier, with minimal computation overhead. We analyze the properties of CAN using simulated experiments, and empirically demonstrate its effectiveness across a diverse set of classification tasks.
Faithful or Extractive? On Mitigating the Faithfulness-Abstractiveness Trade-off in Abstractive Summarization
Aug 31, 2021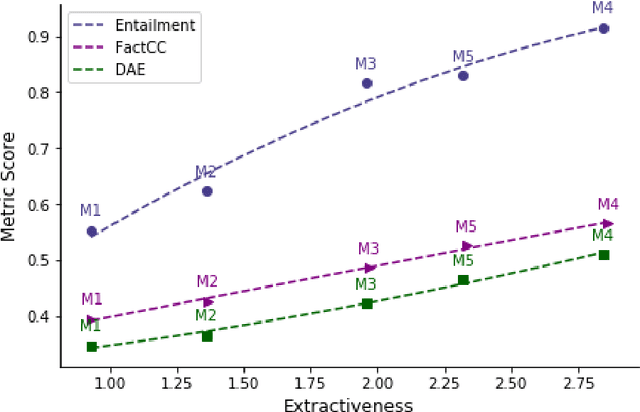

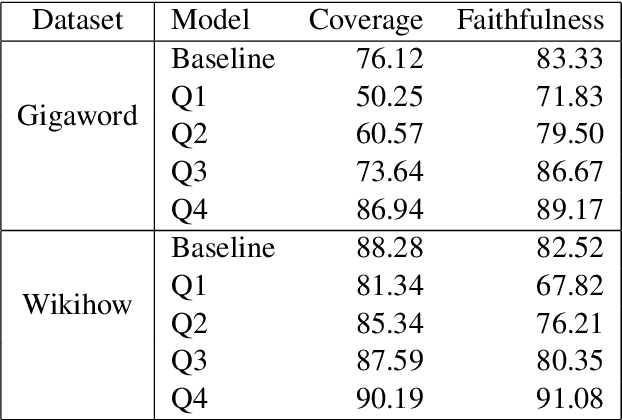
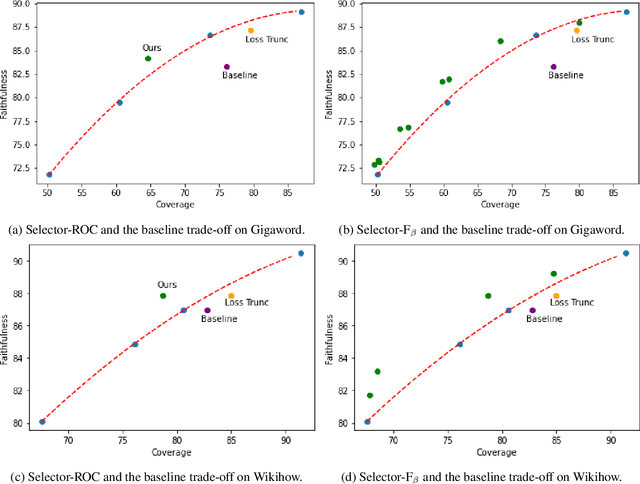
Despite recent progress in abstractive summarization, systems still suffer from faithfulness errors. While prior work has proposed models that improve faithfulness, it is unclear whether the improvement comes from an increased level of extractiveness of the model outputs as one naive way to improve faithfulness is to make summarization models more extractive. In this work, we present a framework for evaluating the effective faithfulness of summarization systems, by generating a faithfulnessabstractiveness trade-off curve that serves as a control at different operating points on the abstractiveness spectrum. We then show that the Maximum Likelihood Estimation (MLE) baseline as well as a recently proposed method for improving faithfulness, are both worse than the control at the same level of abstractiveness. Finally, we learn a selector to identify the most faithful and abstractive summary for a given document, and show that this system can attain higher faithfulness scores in human evaluations while being more abstractive than the baseline system on two datasets. Moreover, we show that our system is able to achieve a better faithfulness-abstractiveness trade-off than the control at the same level of abstractiveness.
Exploring Visual Engagement Signals for Representation Learning
Apr 15, 2021
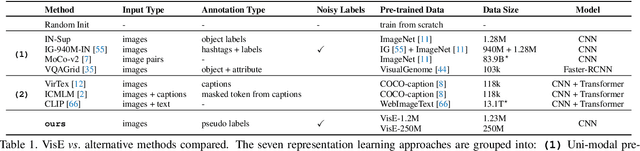
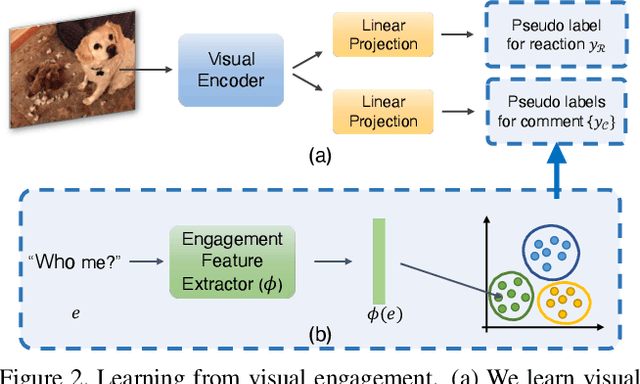
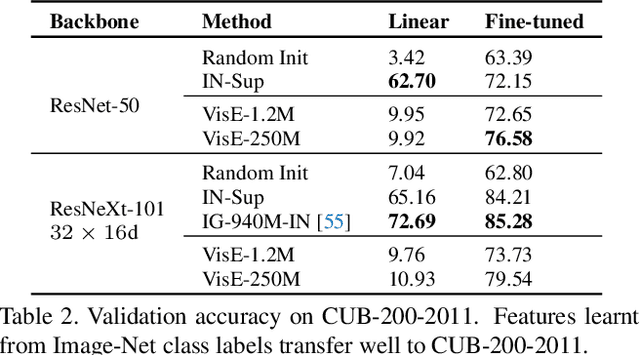
Visual engagement in social media platforms comprises interactions with photo posts including comments, shares, and likes. In this paper, we leverage such visual engagement clues as supervisory signals for representation learning. However, learning from engagement signals is non-trivial as it is not clear how to bridge the gap between low-level visual information and high-level social interactions. We present VisE, a weakly supervised learning approach, which maps social images to pseudo labels derived by clustered engagement signals. We then study how models trained in this way benefit subjective downstream computer vision tasks such as emotion recognition or political bias detection. Through extensive studies, we empirically demonstrate the effectiveness of VisE across a diverse set of classification tasks beyond the scope of conventional recognition.