 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to EdgeWild Face Anti-Spoofing Challenge 2023: Benchmark and Results
May 05, 2023Face anti-spoofing (FAS) is an essential mechanism for safeguarding the integrity of automated face recognition systems. Despite substantial advancements, the generalization of existing approaches to real-world applications remains challenging. This limitation can be attributed to the scarcity and lack of diversity in publicly available FAS datasets, which often leads to overfitting during training or saturation during testing. In terms of quantity, the number of spoof subjects is a critical determinant. Most datasets comprise fewer than 2,000 subjects. With regard to diversity, the majority of datasets consist of spoof samples collected in controlled environments using repetitive, mechanical processes. This data collection methodology results in homogenized samples and a dearth of scenario diversity. To address these shortcomings, we introduce the Wild Face Anti-Spoofing (WFAS) dataset, a large-scale, diverse FAS dataset collected in unconstrained settings. Our dataset encompasses 853,729 images of 321,751 spoof subjects and 529,571 images of 148,169 live subjects, representing a substantial increase in quantity. Moreover, our dataset incorporates spoof data obtained from the internet, spanning a wide array of scenarios and various commercial sensors, including 17 presentation attacks (PAs) that encompass both 2D and 3D forms. This novel data collection strategy markedly enhances FAS data diversity. Leveraging the WFAS dataset and Protocol 1 (Known-Type), we host the Wild Face Anti-Spoofing Challenge at the CVPR2023 workshop. Additionally, we meticulously evaluate representative methods using Protocol 1 and Protocol 2 (Unknown-Type). Through an in-depth examination of the challenge outcomes and benchmark baselines, we provide insightful analyses and propose potential avenues for future research. The dataset is released under Insightface.
Towards Speeding up Adversarial Training in Latent Spaces
Feb 01, 2021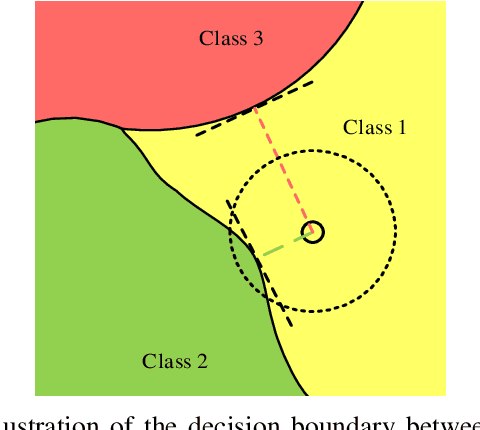
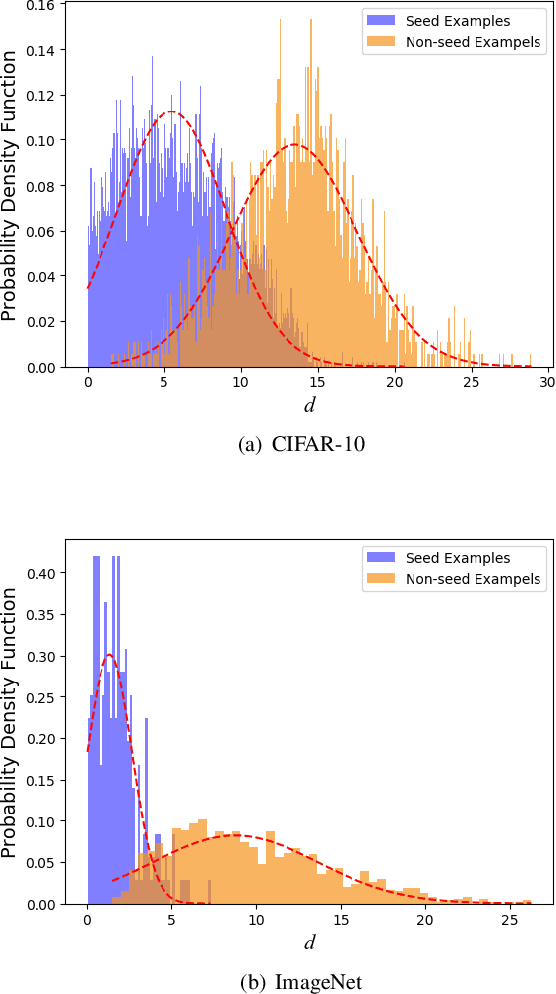
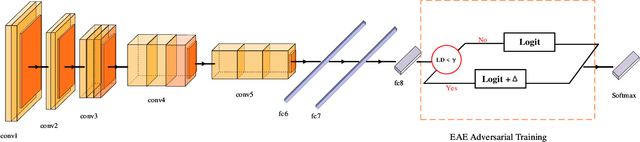
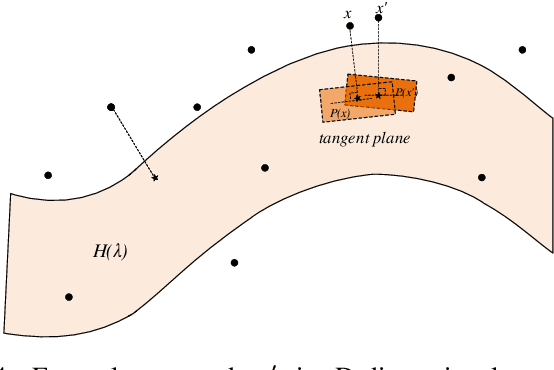
Adversarial training is wildly considered as the most effective way to defend against adversarial examples. However, existing adversarial training methods consume unbearable time cost, since they need to generate adversarial examples in the input space, which accounts for the main part of total time-consuming. For speeding up the training process, we propose a novel adversarial training method that does not need to generate real adversarial examples. We notice that a clean example is closer to the decision boundary of the class with the second largest logit component than any other class besides its own class. Thus, by adding perturbations to logits to generate Endogenous Adversarial Examples(EAEs) -- adversarial examples in the latent space, it can avoid calculating gradients to speed up the training process. We further gain a deep insight into the existence of EAEs by the theory of manifold. To guarantee the added perturbation is within the range of constraint, we use statistical distributions to select seed examples to craft EAEs. Extensive experiments are conducted on CIFAR-10 and ImageNet, and the results show that compare with state-of-the-art "Free" and "Fast" methods, our EAE adversarial training not only shortens the training time, but also enhances the robustness of the model. Moreover, the EAE adversarial training has little impact on the accuracy of clean examples than the existing methods.
EI-MTD:Moving Target Defense for Edge Intelligence against Adversarial Attacks
Oct 11, 2020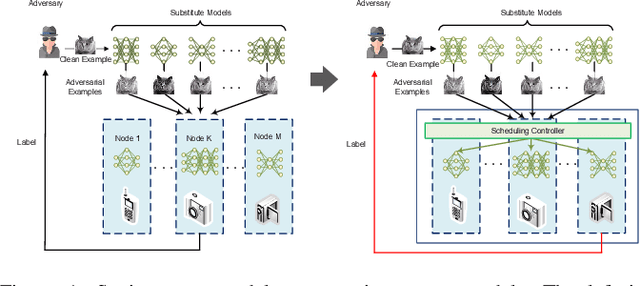
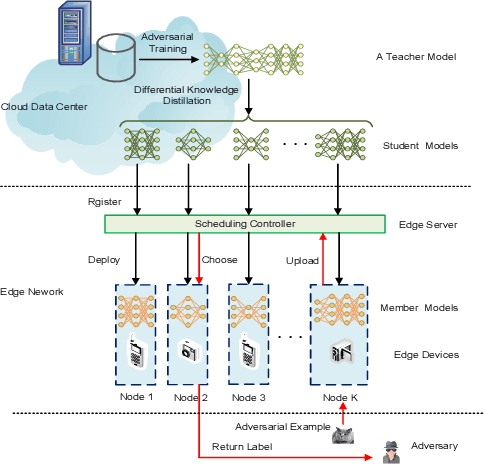
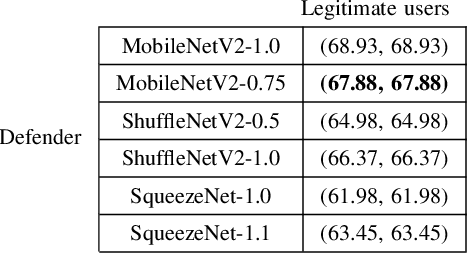
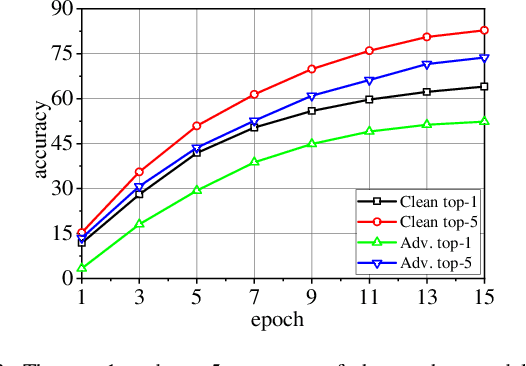
With the boom of edge intelligence, its vulnerability to adversarial attacks becomes an urgent problem. The so-called adversarial example can fool a deep learning model on the edge node to misclassify. Due to the property of transferability, the adversary can easily make a black-box attack using a local substitute model. Nevertheless, the limitation of resource of edge nodes cannot afford a complicated defense mechanism as doing on the cloud data center. To overcome the challenge, we propose a dynamic defense mechanism, namely EI-MTD. It first obtains robust member models with small size through differential knowledge distillation from a complicated teacher model on the cloud data center. Then, a dynamic scheduling policy based on a Bayesian Stackelberg game is applied to the choice of a target model for service. This dynamic defense can prohibit the adversary from selecting an optimal substitute model for black-box attacks. Our experimental result shows that this dynamic scheduling can effectively protect edge intelligence against adversarial attacks under the black-box setting.