 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to EdgeDistilling Object Detectors via Decoupled Features
Mar 26, 2021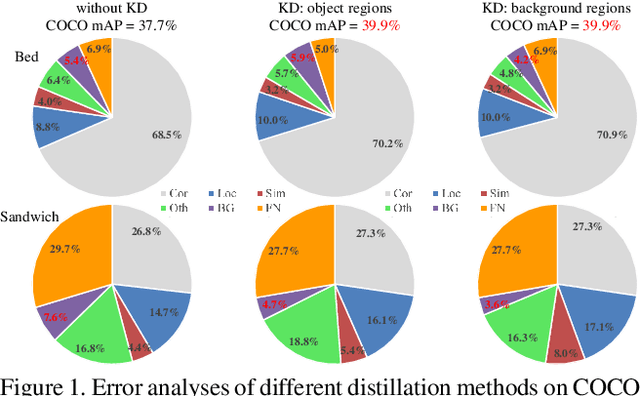
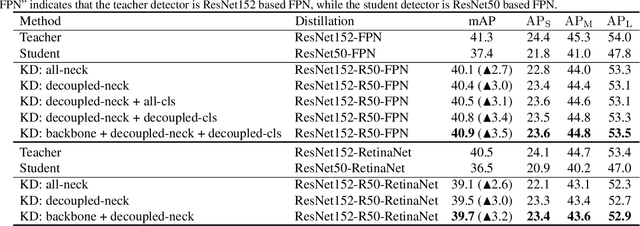

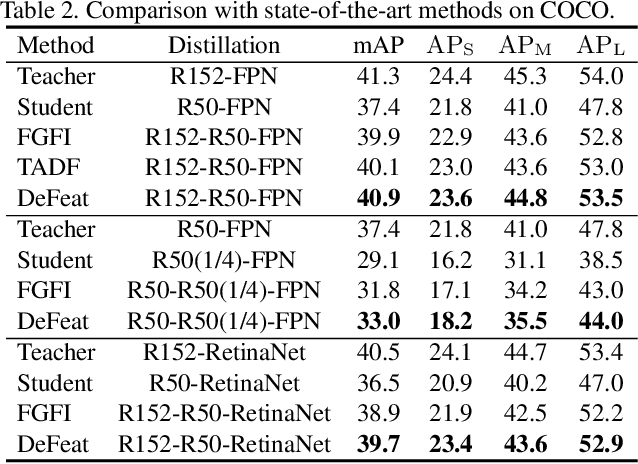
Knowledge distillation is a widely used paradigm for inheriting information from a complicated teacher network to a compact student network and maintaining the strong performance. Different from image classification, object detectors are much more sophisticated with multiple loss functions in which features that semantic information rely on are tangled. In this paper, we point out that the information of features derived from regions excluding objects are also essential for distilling the student detector, which is usually ignored in existing approaches. In addition, we elucidate that features from different regions should be assigned with different importance during distillation. To this end, we present a novel distillation algorithm via decoupled features (DeFeat) for learning a better student detector. Specifically, two levels of decoupled features will be processed for embedding useful information into the student, i.e., decoupled features from neck and decoupled proposals from classification head. Extensive experiments on various detectors with different backbones show that the proposed DeFeat is able to surpass the state-of-the-art distillation methods for object detection. For example, DeFeat improves ResNet50 based Faster R-CNN from 37.4% to 40.9% mAP, and improves ResNet50 based RetinaNet from 36.5% to 39.7% mAP on COCO benchmark. Our implementation is available at https://github.com/ggjy/DeFeat.pytorch.
Learning Frequency-aware Dynamic Network for Efficient Super-Resolution
Mar 15, 2021
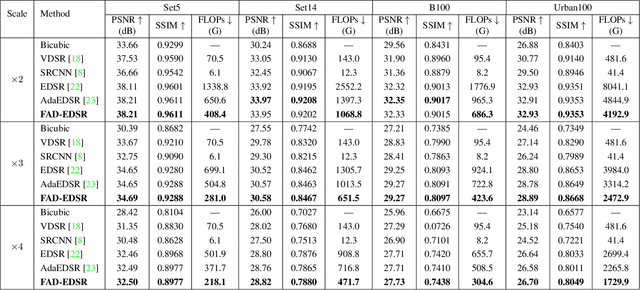
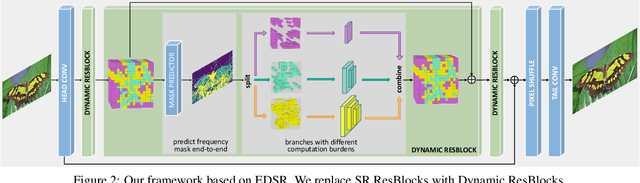
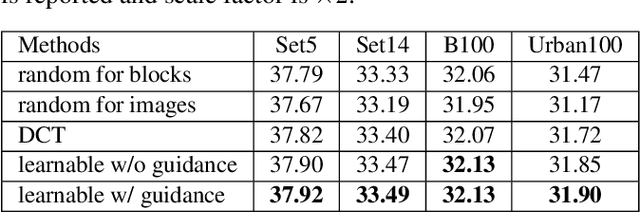
Deep learning based methods, especially convolutional neural networks (CNNs) have been successfully applied in the field of single image super-resolution (SISR). To obtain better fidelity and visual quality, most of existing networks are of heavy design with massive computation. However, the computation resources of modern mobile devices are limited, which cannot easily support the expensive cost. To this end, this paper explores a novel frequency-aware dynamic network for dividing the input into multiple parts according to its coefficients in the discrete cosine transform (DCT) domain. In practice, the high-frequency part will be processed using expensive operations and the lower-frequency part is assigned with cheap operations to relieve the computation burden. Since pixels or image patches belong to low-frequency areas contain relatively few textural details, this dynamic network will not affect the quality of resulting super-resolution images. In addition, we embed predictors into the proposed dynamic network to end-to-end fine-tune the handcrafted frequency-aware masks. Extensive experiments conducted on benchmark SISR models and datasets show that the frequency-aware dynamic network can be employed for various SISR neural architectures to obtain the better tradeoff between visual quality and computational complexity. For instance, we can reduce the FLOPs of EDSR model by approximate $50\%$ while preserving state-of-the-art SISR performance.
Learning Frequency Domain Approximation for Binary Neural Networks
Mar 01, 2021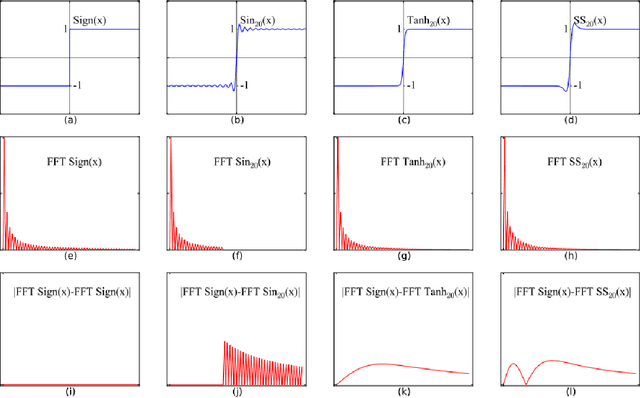
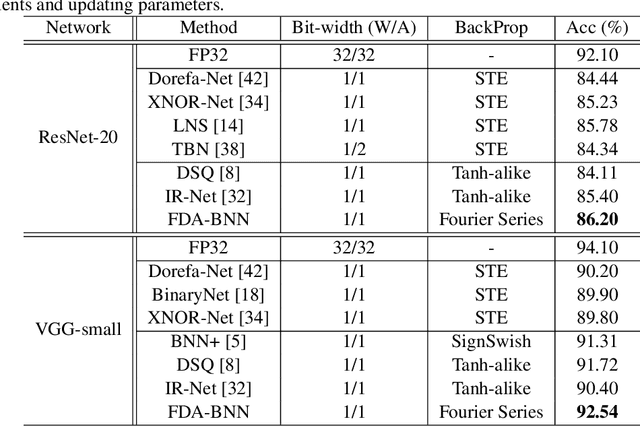
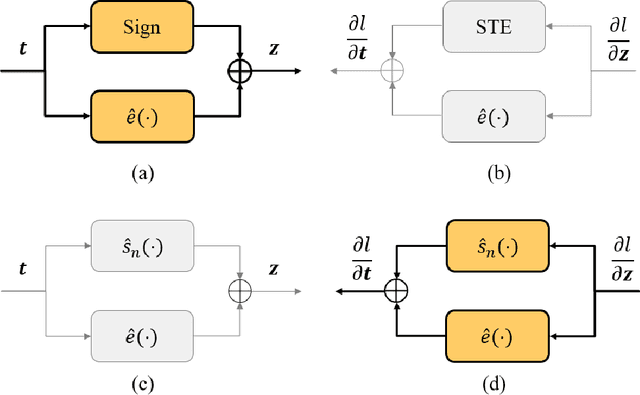

Binary neural networks (BNNs) represent original full-precision weights and activations into 1-bit with sign function. Since the gradient of the conventional sign function is almost zero everywhere which cannot be used for back-propagation, several attempts have been proposed to alleviate the optimization difficulty by using approximate gradient. However, those approximations corrupt the main direction of de facto gradient. To this end, we propose to estimate the gradient of sign function in the Fourier frequency domain using the combination of sine functions for training BNNs, namely frequency domain approximation (FDA). The proposed approach does not affect the low-frequency information of the original sign function which occupies most of the overall energy, and high-frequency coefficients will be ignored to avoid the huge computational overhead. In addition, we embed a noise adaptation module into the training phase to compensate the approximation error. The experiments on several benchmark datasets and neural architectures illustrate that the binary network learned using our method achieves the state-of-the-art accuracy.
Transformer in Transformer
Feb 27, 2021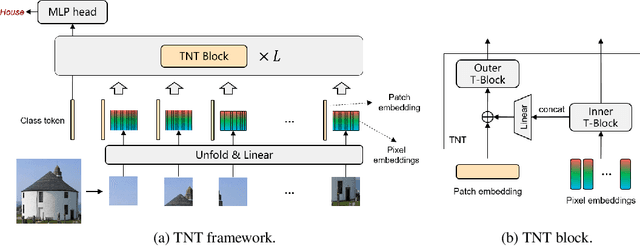

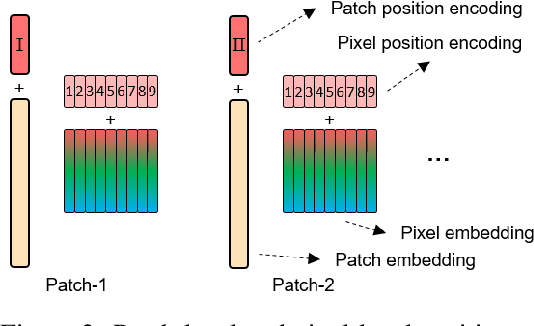
Transformer is a type of self-attention-based neural networks originally applied for NLP tasks. Recently, pure transformer-based models are proposed to solve computer vision problems. These visual transformers usually view an image as a sequence of patches while they ignore the intrinsic structure information inside each patch. In this paper, we propose a novel Transformer-iN-Transformer (TNT) model for modeling both patch-level and pixel-level representation. In each TNT block, an outer transformer block is utilized to process patch embeddings, and an inner transformer block extracts local features from pixel embeddings. The pixel-level feature is projected to the space of patch embedding by a linear transformation layer and then added into the patch. By stacking the TNT blocks, we build the TNT model for image recognition. Experiments on ImageNet benchmark and downstream tasks demonstrate the superiority and efficiency of the proposed TNT architecture. For example, our TNT achieves $81.3\%$ top-1 accuracy on ImageNet which is $1.5\%$ higher than that of DeiT with similar computational cost. The code will be available at https://github.com/huawei-noah/noah-research/tree/master/TNT.
AdderNet and its Minimalist Hardware Design for Energy-Efficient Artificial Intelligence
Feb 03, 2021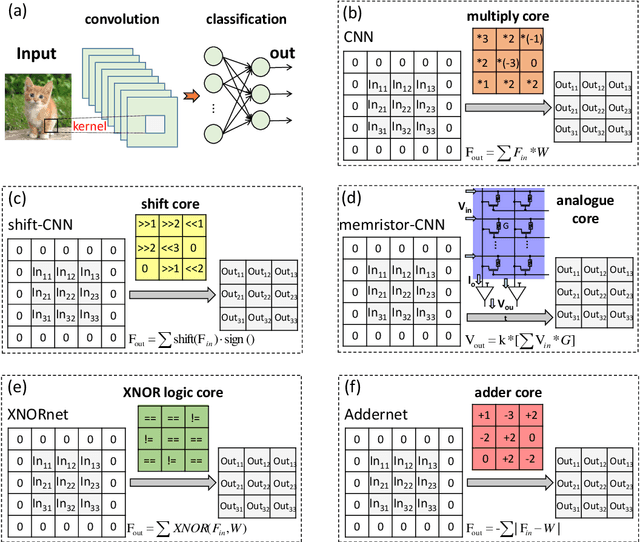
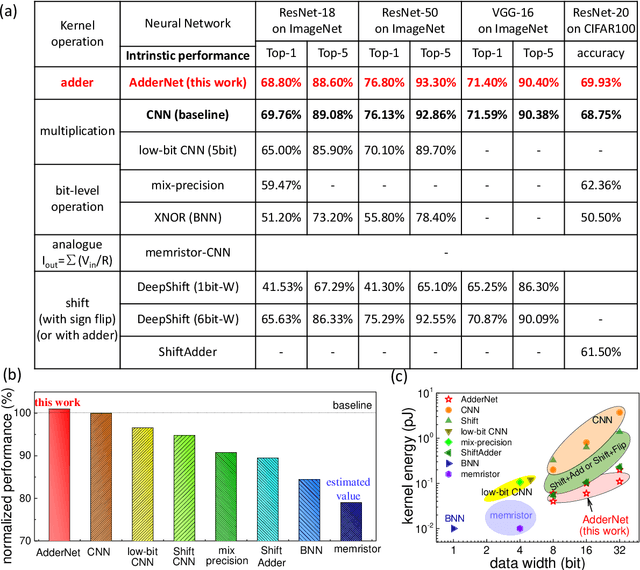
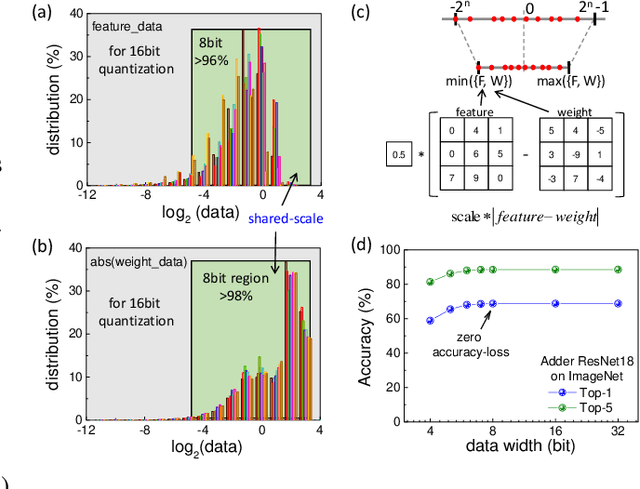
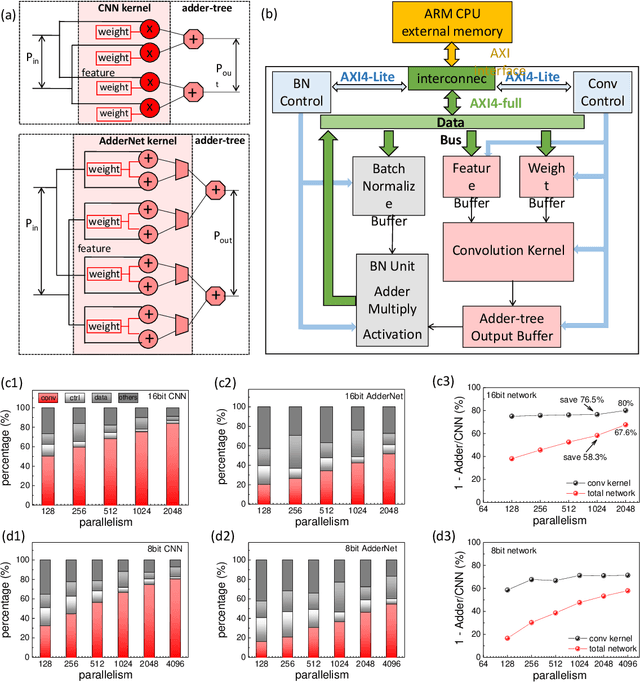
Convolutional neural networks (CNN) have been widely used for boosting the performance of many machine intelligence tasks. However, the CNN models are usually computationally intensive and energy consuming, since they are often designed with numerous multiply-operations and considerable parameters for the accuracy reason. Thus, it is difficult to directly apply them in the resource-constrained environments such as 'Internet of Things' (IoT) devices and smart phones. To reduce the computational complexity and energy burden, here we present a novel minimalist hardware architecture using adder convolutional neural network (AdderNet), in which the original convolution is replaced by adder kernel using only additions. To maximally excavate the potential energy consumption, we explore the low-bit quantization algorithm for AdderNet with shared-scaling-factor method, and we design both specific and general-purpose hardware accelerators for AdderNet. Experimental results show that the adder kernel with int8/int16 quantization also exhibits high performance, meanwhile consuming much less resources (theoretically ~81% off). In addition, we deploy the quantized AdderNet on FPGA (Field Programmable Gate Array) platform. The whole AdderNet can practically achieve 16% enhancement in speed, 67.6%-71.4% decrease in logic resource utilization and 47.85%-77.9% decrease in power consumption compared to CNN under the same circuit architecture. With a comprehensive comparison on the performance, power consumption, hardware resource consumption and network generalization capability, we conclude the AdderNet is able to surpass all the other competitors including the classical CNN, novel memristor-network, XNOR-Net and the shift-kernel based network, indicating its great potential in future high performance and energy-efficient artificial intelligence applications.
A Survey on Visual Transformer
Jan 30, 2021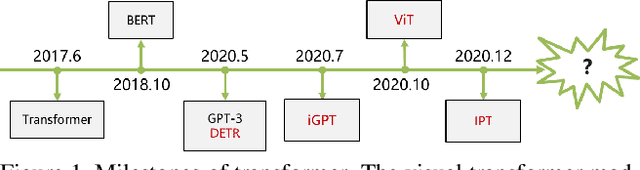

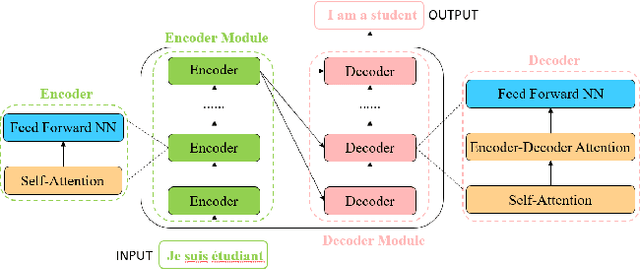
Transformer, first applied to the field of natural language processing, is a type of deep neural network mainly based on the self-attention mechanism. Thanks to its strong representation capabilities, researchers are looking at ways to apply transformer to computer vision tasks. In a variety of visual benchmarks, transformer-based models perform similar to or better than other types of networks such as convolutional and recurrent networks. Given its high performance and no need for human-defined inductive bias, transformer is receiving more and more attention from the computer vision community. In this paper, we review these visual transformer models by categorizing them in different tasks and analyzing their advantages and disadvantages. The main categories we explore include the backbone network, high/mid-level vision, low-level vision, and video processing. We also take a brief look at the self-attention mechanism in computer vision, as it is the base component in transformer. Furthermore, we include efficient transformer methods for pushing transformer into real device-based applications. Toward the end of this paper, we discuss the challenges and provide several further research directions for visual transformers.
GhostSR: Learning Ghost Features for Efficient Image Super-Resolution
Jan 21, 2021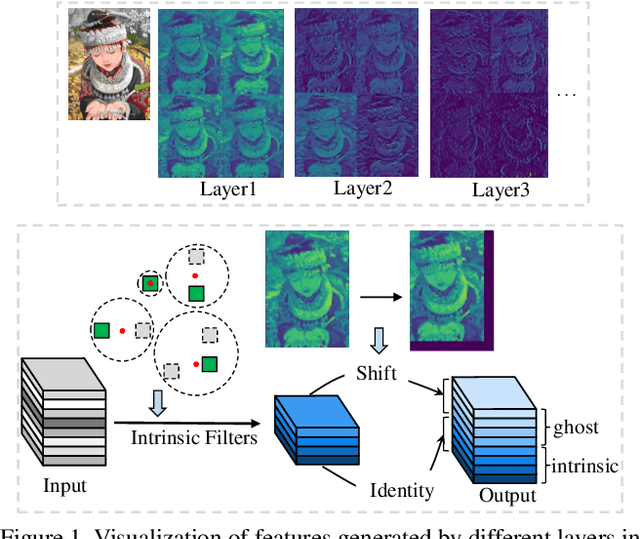
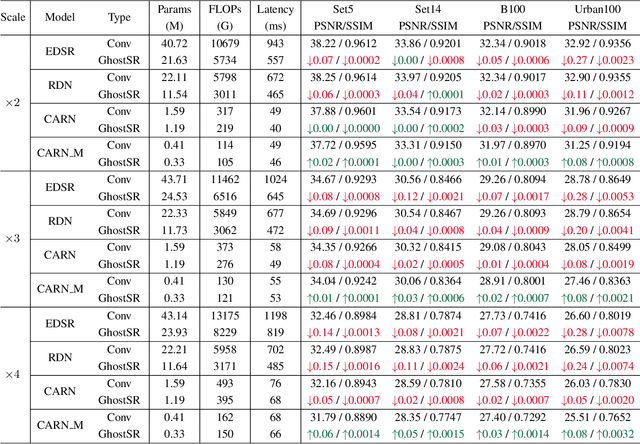
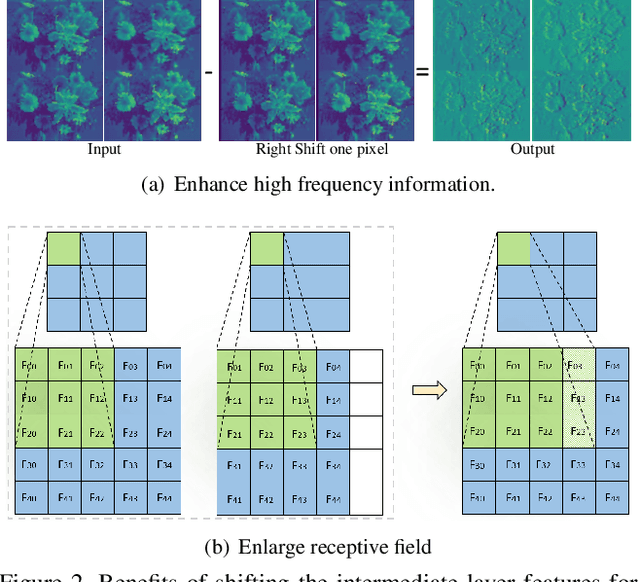
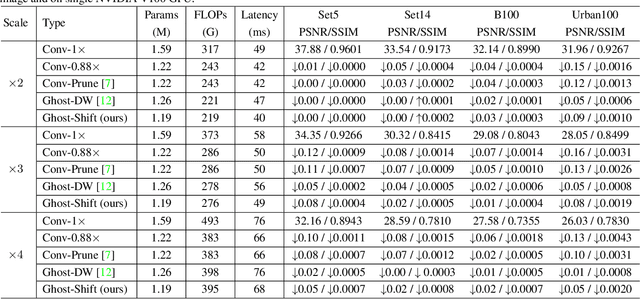
Modern single image super-resolution (SISR) system based on convolutional neural networks (CNNs) achieves fancy performance while requires huge computational costs. The problem on feature redundancy is well studied in visual recognition task, but rarely discussed in SISR. Based on the observation that many features in SISR models are also similar to each other, we propose to use shift operation to generate the redundant features (i.e., Ghost features). Compared with depth-wise convolution which is not friendly to GPUs or NPUs, shift operation can bring practical inference acceleration for CNNs on common hardware. We analyze the benefits of shift operation for SISR and make the shift orientation learnable based on Gumbel-Softmax trick. For a given pre-trained model, we first cluster all filters in each convolutional layer to identify the intrinsic ones for generating intrinsic features. Ghost features will be derived by moving these intrinsic features along a specific orientation. The complete output features are constructed by concatenating the intrinsic and ghost features together. Extensive experiments on several benchmark models and datasets demonstrate that both the non-compact and lightweight SISR models embedded in our proposed module can achieve comparable performance to that of their baselines with large reduction of parameters, FLOPs and GPU latency. For instance, we reduce the parameters by 47%, FLOPs by 46% and GPU latency by 41% of EDSR x2 network without significant performance degradation.
Pre-Trained Image Processing Transformer
Dec 03, 2020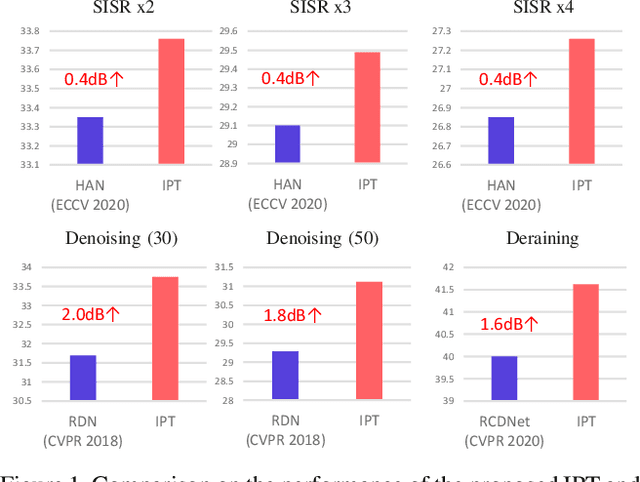

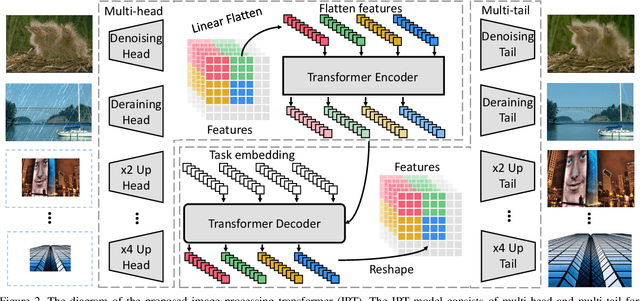
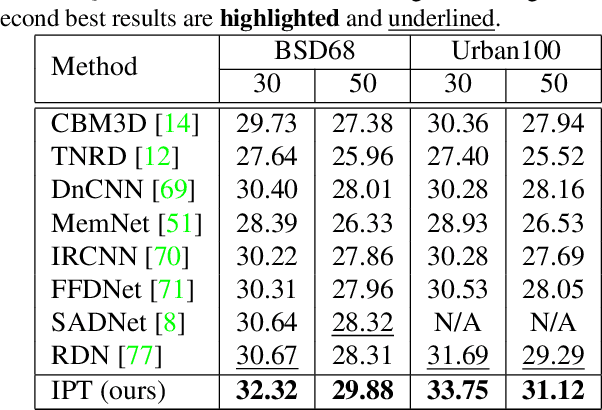
As the computing power of modern hardware is increasing strongly, pre-trained deep learning models (e.g., BERT, GPT-3) learned on large-scale datasets have shown their effectiveness over conventional methods. The big progress is mainly contributed to the representation ability of transformer and its variant architectures. In this paper, we study the low-level computer vision task (e.g., denoising, super-resolution and deraining) and develop a new pre-trained model, namely, image processing transformer (IPT). To maximally excavate the capability of transformer, we present to utilize the well-known ImageNet benchmark for generating a large amount of corrupted image pairs. The IPT model is trained on these images with multi-heads and multi-tails. In addition, the contrastive learning is introduced for well adapting to different image processing tasks. The pre-trained model can therefore efficiently employed on desired task after fine-tuning. With only one pre-trained model, IPT outperforms the current state-of-the-art methods on various low-level benchmarks.
Model Rubik's Cube: Twisting Resolution, Depth and Width for TinyNets
Oct 28, 2020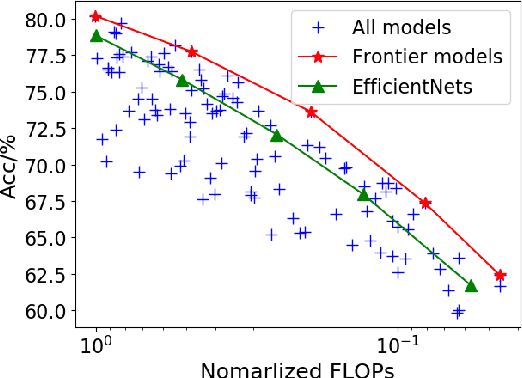

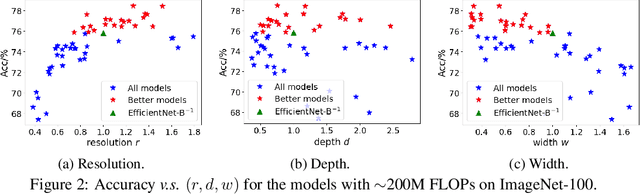
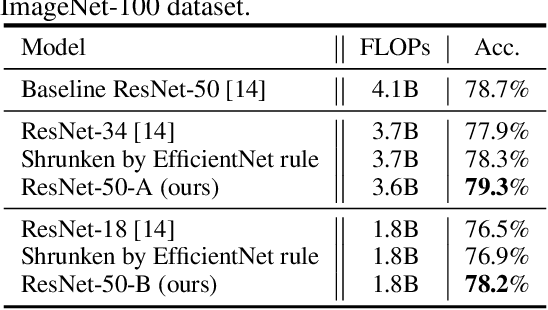
To obtain excellent deep neural architectures, a series of techniques are carefully designed in EfficientNets. The giant formula for simultaneously enlarging the resolution, depth and width provides us a Rubik's cube for neural networks. So that we can find networks with high efficiency and excellent performance by twisting the three dimensions. This paper aims to explore the twisting rules for obtaining deep neural networks with minimum model sizes and computational costs. Different from the network enlarging, we observe that resolution and depth are more important than width for tiny networks. Therefore, the original method, i.e., the compound scaling in EfficientNet is no longer suitable. To this end, we summarize a tiny formula for downsizing neural architectures through a series of smaller models derived from the EfficientNet-B0 with the FLOPs constraint. Experimental results on the ImageNet benchmark illustrate that our TinyNet performs much better than the smaller version of EfficientNets using the inversed giant formula. For instance, our TinyNet-E achieves a 59.9% Top-1 accuracy with only 24M FLOPs, which is about 1.9% higher than that of the previous best MobileNetV3 with similar computational cost. Code will be available at https://github.com/huawei-noah/CV-Backbones/tree/main/tinynet, and https://gitee.com/mindspore/mindspore/tree/master/model_zoo/research/cv/tinynet.
SCOP: Scientific Control for Reliable Neural Network Pruning
Oct 21, 2020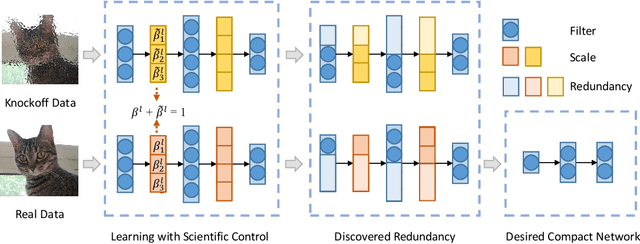
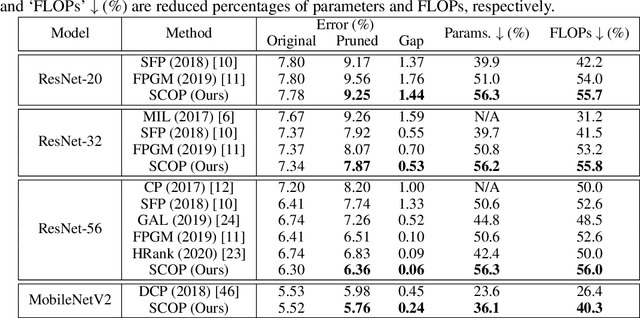
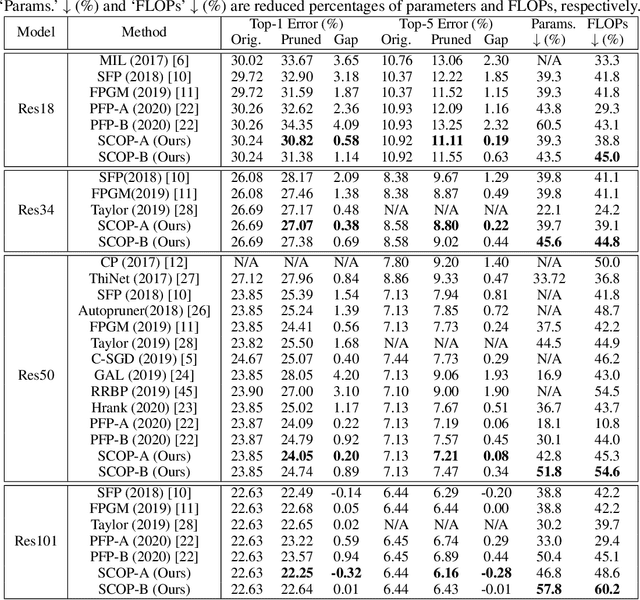
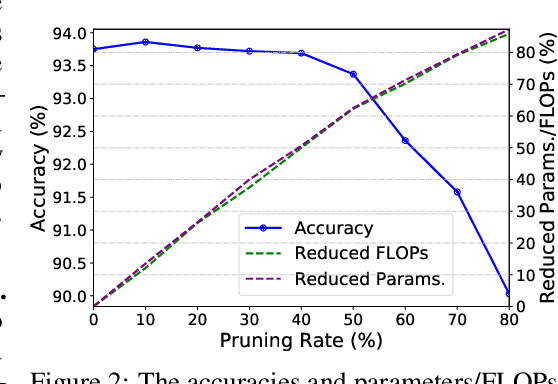
This paper proposes a reliable neural network pruning algorithm by setting up a scientific control. Existing pruning methods have developed various hypotheses to approximate the importance of filters to the network and then execute filter pruning accordingly. To increase the reliability of the results, we prefer to have a more rigorous research design by including a scientific control group as an essential part to minimize the effect of all factors except the association between the filter and expected network output. Acting as a control group, knockoff feature is generated to mimic the feature map produced by the network filter, but they are conditionally independent of the example label given the real feature map. We theoretically suggest that the knockoff condition can be approximately preserved given the information propagation of network layers. Besides the real feature map on an intermediate layer, the corresponding knockoff feature is brought in as another auxiliary input signal for the subsequent layers. Redundant filters can be discovered in the adversarial process of different features. Through experiments, we demonstrate the superiority of the proposed algorithm over state-of-the-art methods. For example, our method can reduce 57.8% parameters and 60.2% FLOPs of ResNet-101 with only 0.01% top-1 accuracy loss on ImageNet.