 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to EdgeExploiting Depth from Single Monocular Images for Object Detection and Semantic Segmentation
Oct 06, 2016
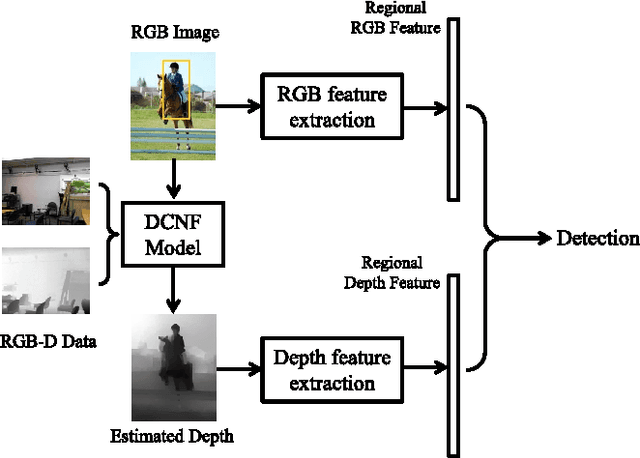
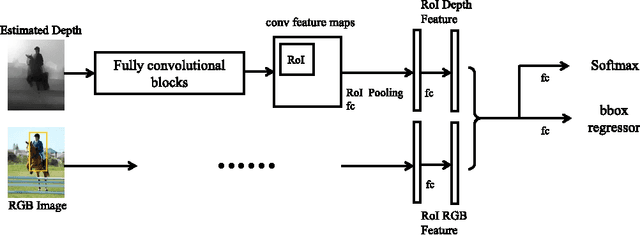

Augmenting RGB data with measured depth has been shown to improve the performance of a range of tasks in computer vision including object detection and semantic segmentation. Although depth sensors such as the Microsoft Kinect have facilitated easy acquisition of such depth information, the vast majority of images used in vision tasks do not contain depth information. In this paper, we show that augmenting RGB images with estimated depth can also improve the accuracy of both object detection and semantic segmentation. Specifically, we first exploit the recent success of depth estimation from monocular images and learn a deep depth estimation model. Then we learn deep depth features from the estimated depth and combine with RGB features for object detection and semantic segmentation. Additionally, we propose an RGB-D semantic segmentation method which applies a multi-task training scheme: semantic label prediction and depth value regression. We test our methods on several datasets and demonstrate that incorporating information from estimated depth improves the performance of object detection and semantic segmentation remarkably.
Image Restoration Using Very Deep Convolutional Encoder-Decoder Networks with Symmetric Skip Connections
Sep 01, 2016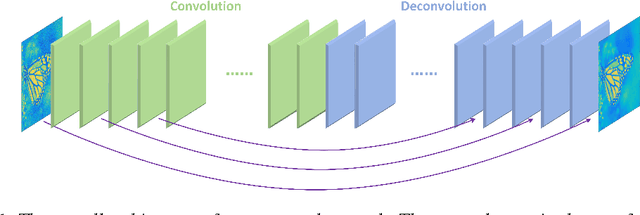
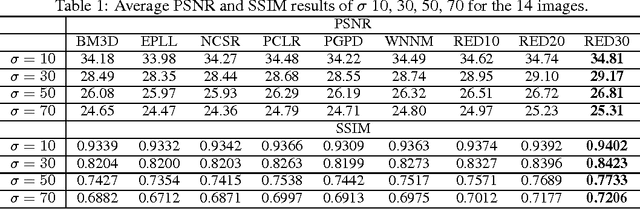
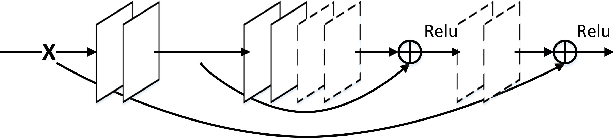
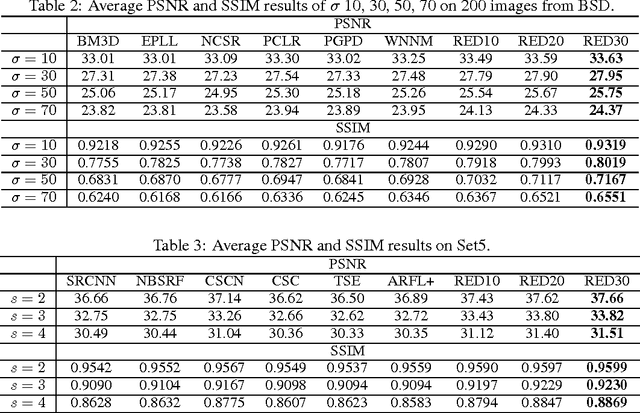
In this paper, we propose a very deep fully convolutional encoding-decoding framework for image restoration such as denoising and super-resolution. The network is composed of multiple layers of convolution and de-convolution operators, learning end-to-end mappings from corrupted images to the original ones. The convolutional layers act as the feature extractor, which capture the abstraction of image contents while eliminating noises/corruptions. De-convolutional layers are then used to recover the image details. We propose to symmetrically link convolutional and de-convolutional layers with skip-layer connections, with which the training converges much faster and attains a higher-quality local optimum. First, The skip connections allow the signal to be back-propagated to bottom layers directly, and thus tackles the problem of gradient vanishing, making training deep networks easier and achieving restoration performance gains consequently. Second, these skip connections pass image details from convolutional layers to de-convolutional layers, which is beneficial in recovering the original image. Significantly, with the large capacity, we can handle different levels of noises using a single model. Experimental results show that our network achieves better performance than all previously reported state-of-the-art methods.
Image Restoration Using Convolutional Auto-encoders with Symmetric Skip Connections
Aug 30, 2016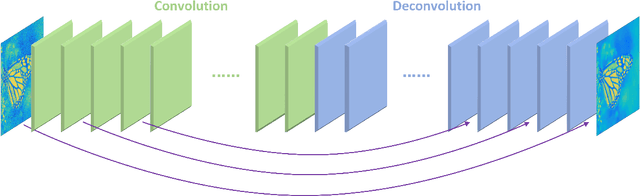
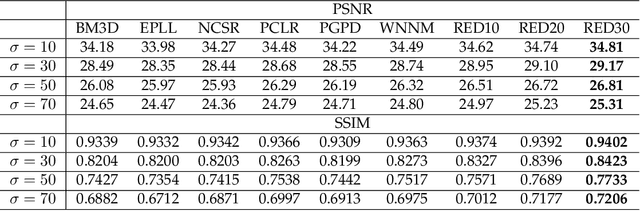
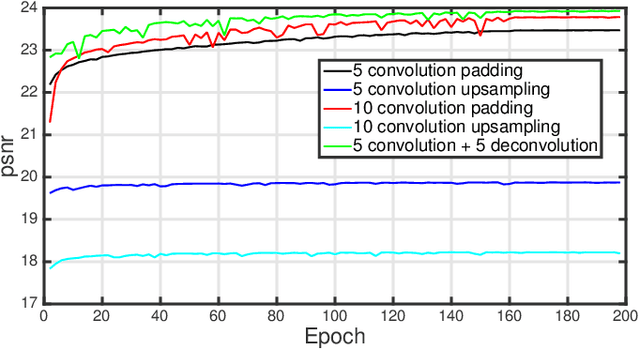
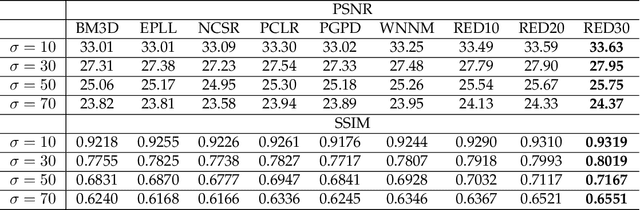
Image restoration, including image denoising, super resolution, inpainting, and so on, is a well-studied problem in computer vision and image processing, as well as a test bed for low-level image modeling algorithms. In this work, we propose a very deep fully convolutional auto-encoder network for image restoration, which is a encoding-decoding framework with symmetric convolutional-deconvolutional layers. In other words, the network is composed of multiple layers of convolution and de-convolution operators, learning end-to-end mappings from corrupted images to the original ones. The convolutional layers capture the abstraction of image contents while eliminating corruptions. Deconvolutional layers have the capability to upsample the feature maps and recover the image details. To deal with the problem that deeper networks tend to be more difficult to train, we propose to symmetrically link convolutional and deconvolutional layers with skip-layer connections, with which the training converges much faster and attains better results.
Fast Training of Triplet-based Deep Binary Embedding Networks
Aug 01, 2016

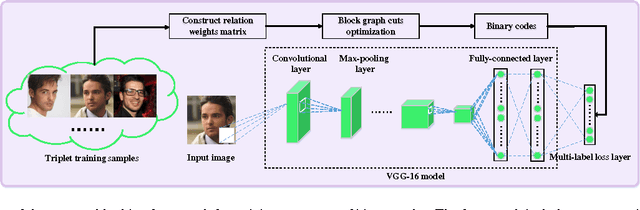
In this paper, we aim to learn a mapping (or embedding) from images to a compact binary space in which Hamming distances correspond to a ranking measure for the image retrieval task. We make use of a triplet loss because this has been shown to be most effective for ranking problems. However, training in previous works can be prohibitively expensive due to the fact that optimization is directly performed on the triplet space, where the number of possible triplets for training is cubic in the number of training examples. To address this issue, we propose to formulate high-order binary codes learning as a multi-label classification problem by explicitly separating learning into two interleaved stages. To solve the first stage, we design a large-scale high-order binary codes inference algorithm to reduce the high-order objective to a standard binary quadratic problem such that graph cuts can be used to efficiently infer the binary code which serve as the label of each training datum. In the second stage we propose to map the original image to compact binary codes via carefully designed deep convolutional neural networks (CNNs) and the hashing function fitting can be solved by training binary CNN classifiers. An incremental/interleaved optimization strategy is proffered to ensure that these two steps are interactive with each other during training for better accuracy. We conduct experiments on several benchmark datasets, which demonstrate both improved training time (by as much as two orders of magnitude) as well as producing state-of-the-art hashing for various retrieval tasks.
Image Co-localization by Mimicking a Good Detector's Confidence Score Distribution
Jul 23, 2016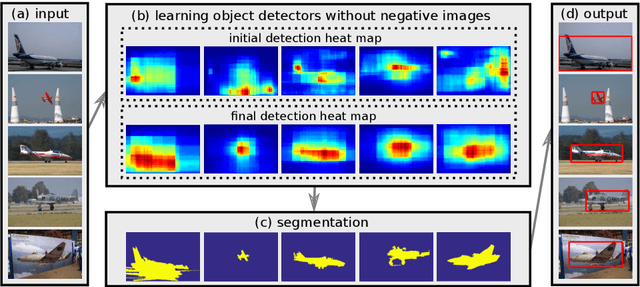

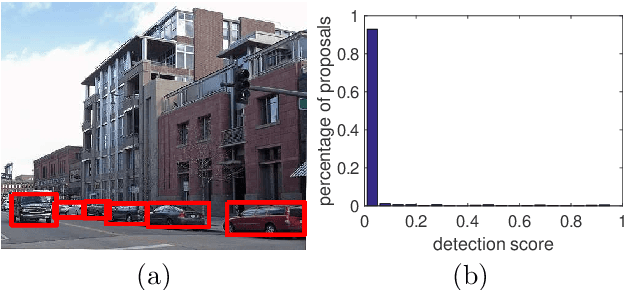
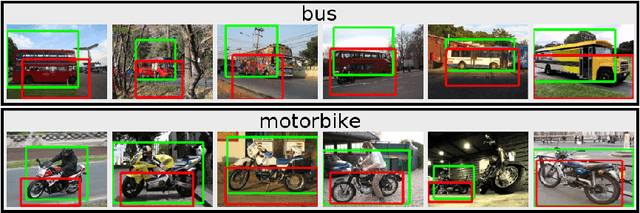
Given a set of images containing objects from the same category, the task of image co-localization is to identify and localize each instance. This paper shows that this problem can be solved by a simple but intriguing idea, that is, a common object detector can be learnt by making its detection confidence scores distributed like those of a strongly supervised detector. More specifically, we observe that given a set of object proposals extracted from an image that contains the object of interest, an accurate strongly supervised object detector should give high scores to only a small minority of proposals, and low scores to most of them. Thus, we devise an entropy-based objective function to enforce the above property when learning the common object detector. Once the detector is learnt, we resort to a segmentation approach to refine the localization. We show that despite its simplicity, our approach outperforms state-of-the-art methods.
Visual Question Answering: A Survey of Methods and Datasets
Jul 20, 2016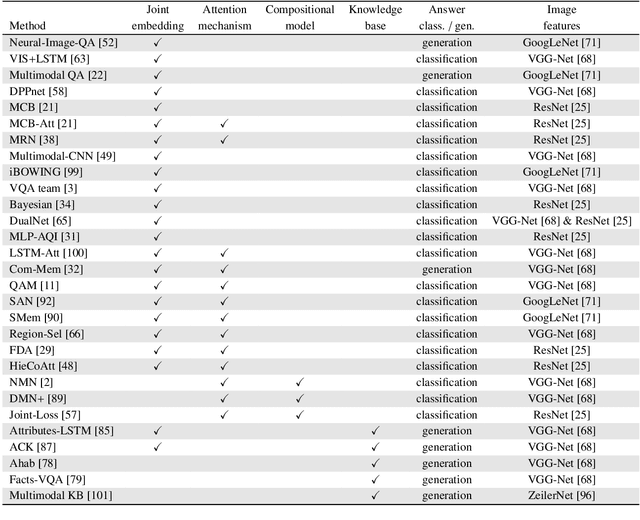
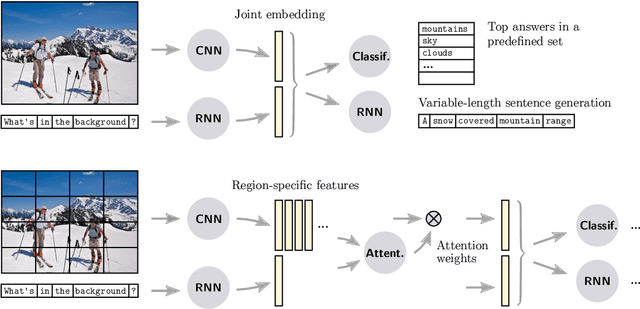
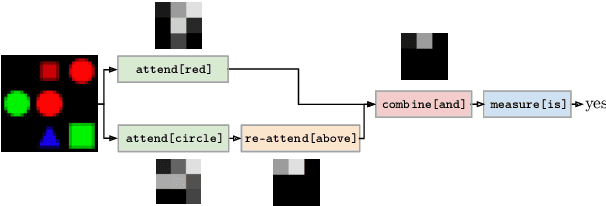
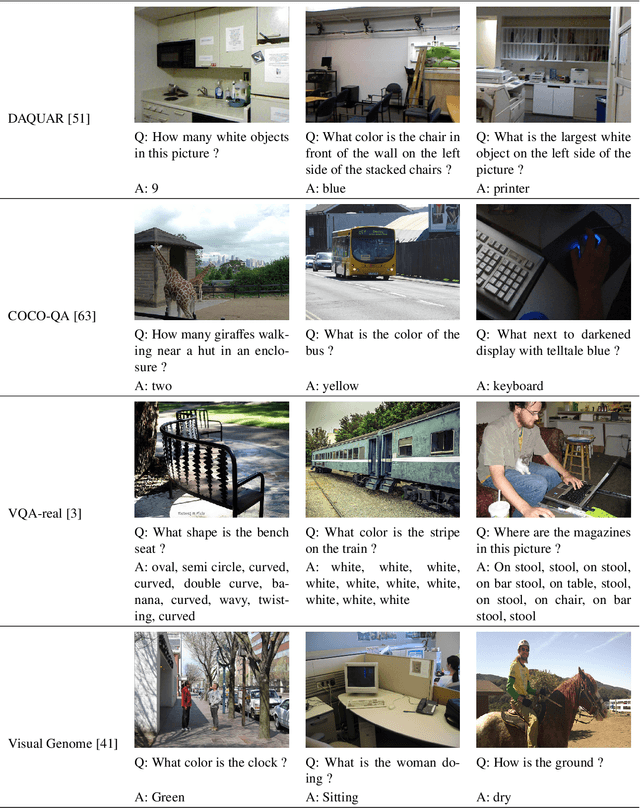
Visual Question Answering (VQA) is a challenging task that has received increasing attention from both the computer vision and the natural language processing communities. Given an image and a question in natural language, it requires reasoning over visual elements of the image and general knowledge to infer the correct answer. In the first part of this survey, we examine the state of the art by comparing modern approaches to the problem. We classify methods by their mechanism to connect the visual and textual modalities. In particular, we examine the common approach of combining convolutional and recurrent neural networks to map images and questions to a common feature space. We also discuss memory-augmented and modular architectures that interface with structured knowledge bases. In the second part of this survey, we review the datasets available for training and evaluating VQA systems. The various datatsets contain questions at different levels of complexity, which require different capabilities and types of reasoning. We examine in depth the question/answer pairs from the Visual Genome project, and evaluate the relevance of the structured annotations of images with scene graphs for VQA. Finally, we discuss promising future directions for the field, in particular the connection to structured knowledge bases and the use of natural language processing models.
Where to Focus: Query Adaptive Matching for Instance Retrieval Using Convolutional Feature Maps
Jun 22, 2016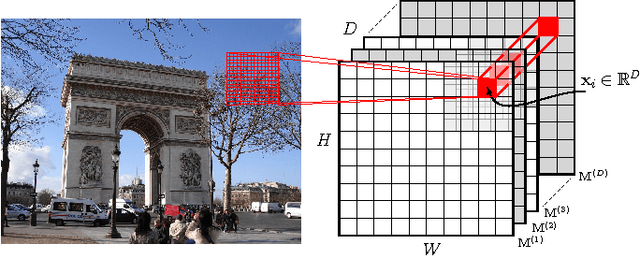

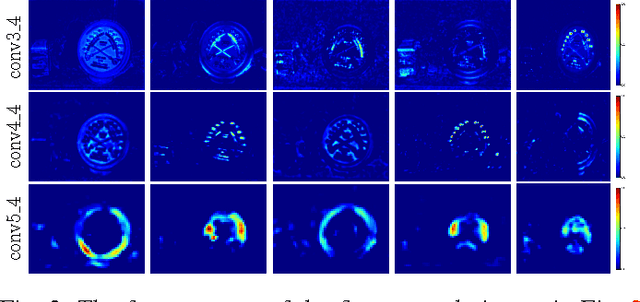
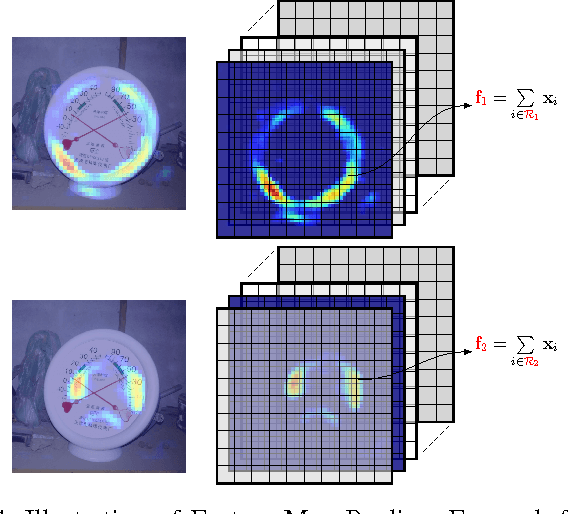
Instance retrieval requires one to search for images that contain a particular object within a large corpus. Recent studies show that using image features generated by pooling convolutional layer feature maps (CFMs) of a pretrained convolutional neural network (CNN) leads to promising performance for this task. However, due to the global pooling strategy adopted in those works, the generated image feature is less robust to image clutter and tends to be contaminated by the irrelevant image patterns. In this article, we alleviate this drawback by proposing a novel reranking algorithm using CFMs to refine the retrieval result obtained by existing methods. Our key idea, called query adaptive matching (QAM), is to first represent the CFMs of each image by a set of base regions which can be freely combined into larger regions-of-interest. Then the similarity between the query and a candidate image is measured by the best similarity score that can be attained by comparing the query feature and the feature pooled from a combined region. We show that the above procedure can be cast as an optimization problem and it can be solved efficiently with an off-the-shelf solver. Besides this general framework, we also propose two practical ways to create the base regions. One is based on the property of the CFM and the other one is based on a multi-scale spatial pyramid scheme. Through extensive experiments, we show that our reranking approaches bring substantial performance improvement and by applying them we can outperform the state of the art on several instance retrieval benchmarks.
PersonNet: Person Re-identification with Deep Convolutional Neural Networks
Jun 20, 2016
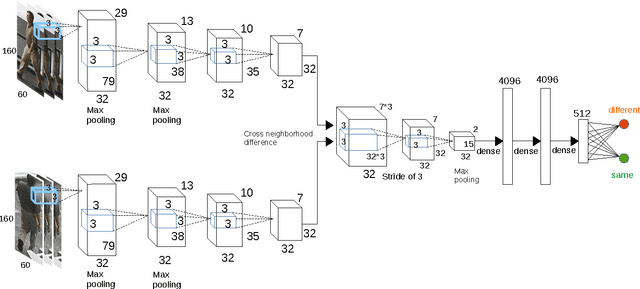
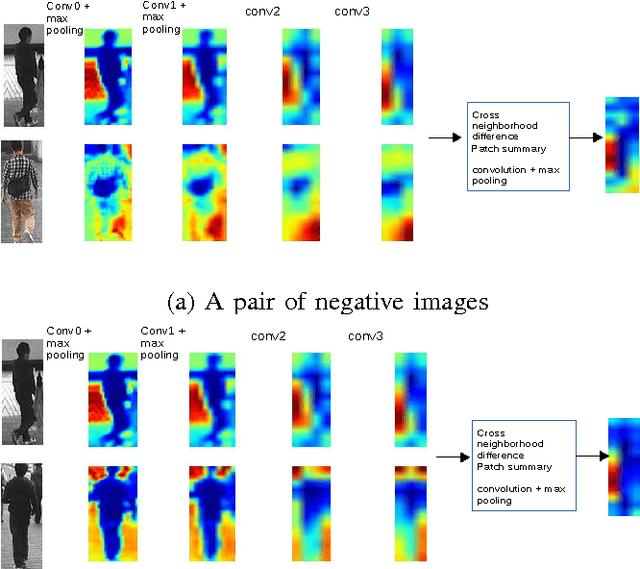
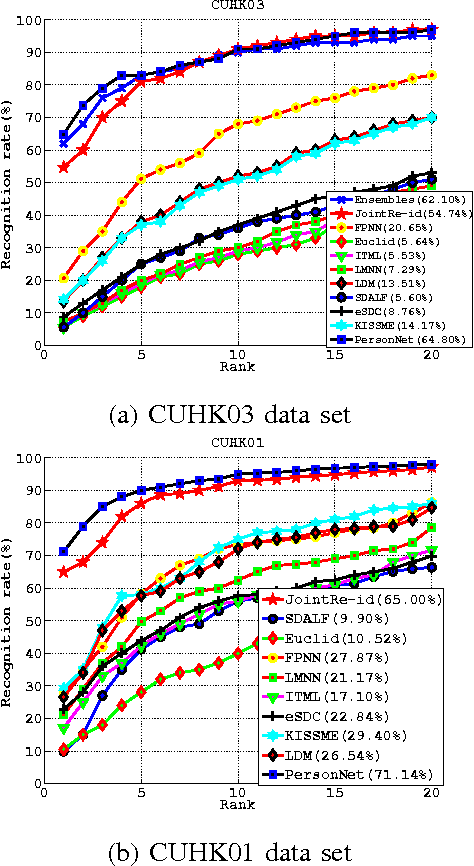
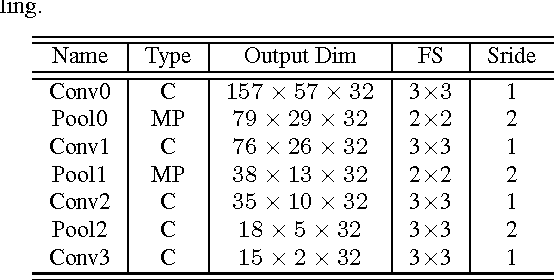
In this paper, we propose a deep end-to-end neu- ral network to simultaneously learn high-level features and a corresponding similarity metric for person re-identification. The network takes a pair of raw RGB images as input, and outputs a similarity value indicating whether the two input images depict the same person. A layer of computing neighborhood range differences across two input images is employed to capture local relationship between patches. This operation is to seek a robust feature from input images. By increasing the depth to 10 weight layers and using very small (3$\times$3) convolution filters, our architecture achieves a remarkable improvement on the prior-art configurations. Meanwhile, an adaptive Root- Mean-Square (RMSProp) gradient decent algorithm is integrated into our architecture, which is beneficial to deep nets. Our method consistently outperforms state-of-the-art on two large datasets (CUHK03 and Market-1501), and a medium-sized data set (CUHK01).
Deep Recurrent Convolutional Networks for Video-based Person Re-identification: An End-to-End Approach
Jun 12, 2016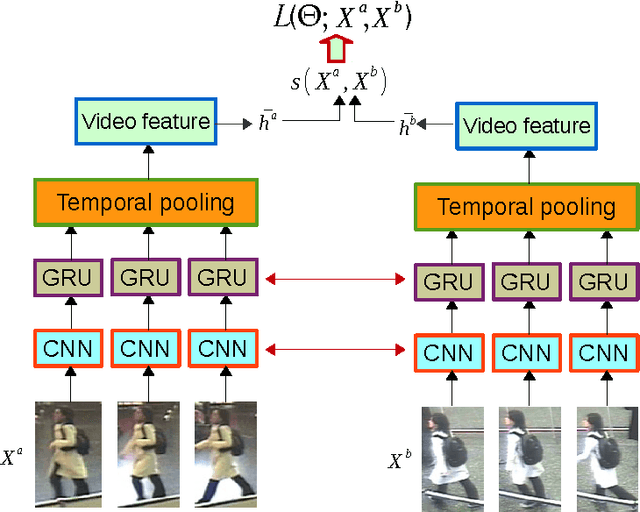
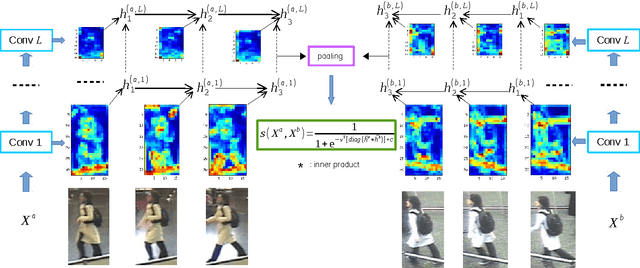
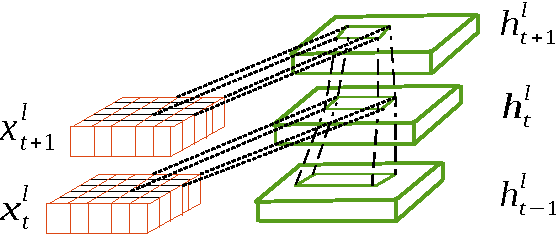
In this paper, we present an end-to-end approach to simultaneously learn spatio-temporal features and corresponding similarity metric for video-based person re-identification. Given the video sequence of a person, features from each frame that are extracted from all levels of a deep convolutional network can preserve a higher spatial resolution from which we can model finer motion patterns. These low-level visual percepts are leveraged into a variant of recurrent model to characterize the temporal variation between time-steps. Features from all time-steps are then summarized using temporal pooling to produce an overall feature representation for the complete sequence. The deep convolutional network, recurrent layer, and the temporal pooling are jointly trained to extract comparable hidden-unit representations from input pair of time series to compute their corresponding similarity value. The proposed framework combines time series modeling and metric learning to jointly learn relevant features and a good similarity measure between time sequences of person. Experiments demonstrate that our approach achieves the state-of-the-art performance for video-based person re-identification on iLIDS-VID and PRID 2011, the two primary public datasets for this purpose.
Pushing the Limits of Deep CNNs for Pedestrian Detection
Jun 06, 2016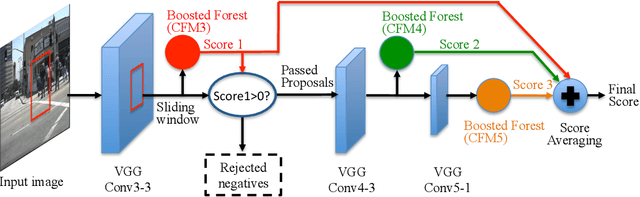
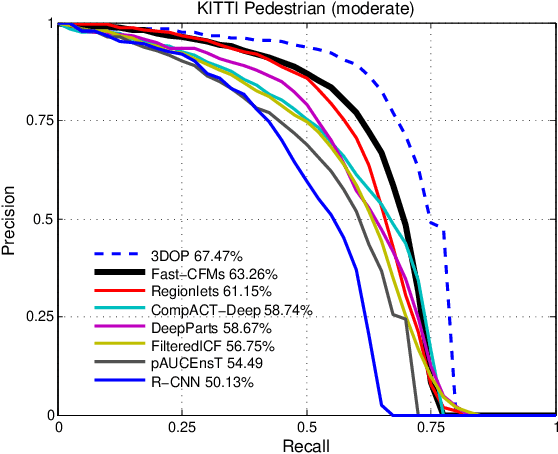
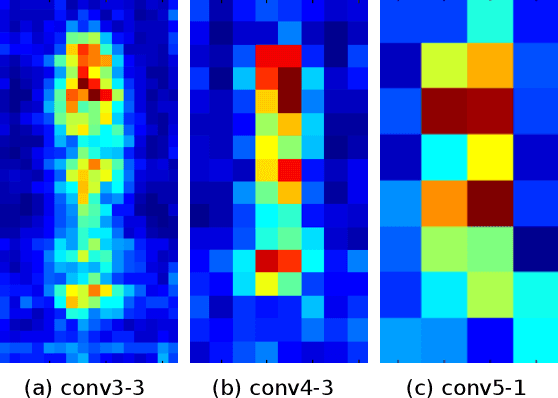
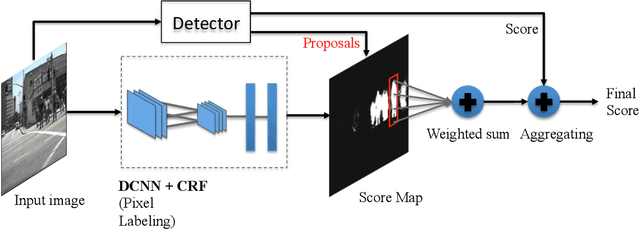
Compared to other applications in computer vision, convolutional neural networks have under-performed on pedestrian detection. A breakthrough was made very recently by using sophisticated deep CNN models, with a number of hand-crafted features, or explicit occlusion handling mechanism. In this work, we show that by re-using the convolutional feature maps (CFMs) of a deep convolutional neural network (DCNN) model as image features to train an ensemble of boosted decision models, we are able to achieve the best reported accuracy without using specially designed learning algorithms. We empirically identify and disclose important implementation details. We also show that pixel labelling may be simply combined with a detector to boost the detection performance. By adding complementary hand-crafted features such as optical flow, the DCNN based detector can be further improved. We set a new record on the Caltech pedestrian dataset, lowering the log-average miss rate from $11.7\%$ to $8.9\%$, a relative improvement of $24\%$. We also achieve a comparable result to the state-of-the-art approaches on the KITTI dataset.