 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to EdgeA Novel Graph-based Multi-modal Fusion Encoder for Neural Machine Translation
Jul 17, 2020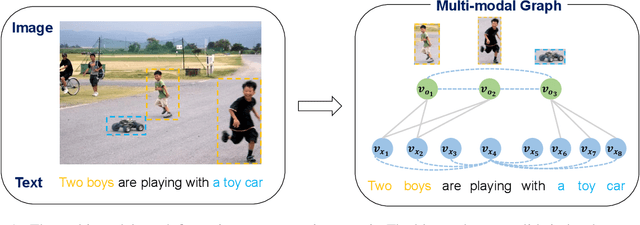
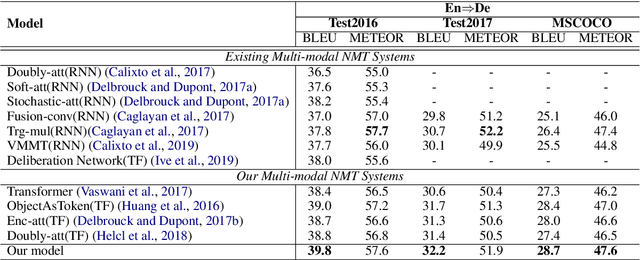
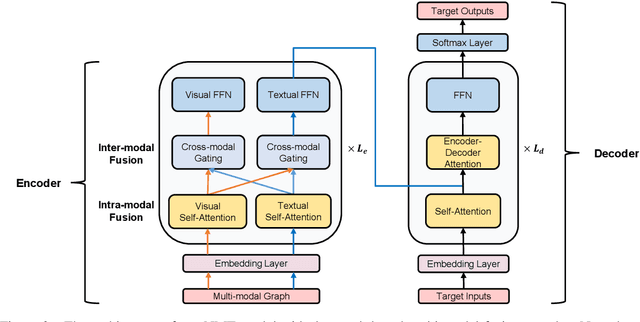
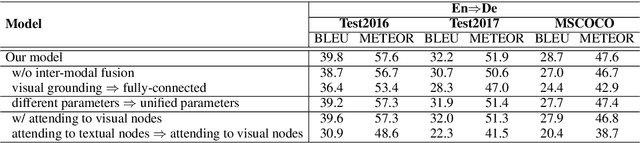
Multi-modal neural machine translation (NMT) aims to translate source sentences into a target language paired with images. However, dominant multi-modal NMT models do not fully exploit fine-grained semantic correspondences between semantic units of different modalities, which have potential to refine multi-modal representation learning. To deal with this issue, in this paper, we propose a novel graph-based multi-modal fusion encoder for NMT. Specifically, we first represent the input sentence and image using a unified multi-modal graph, which captures various semantic relationships between multi-modal semantic units (words and visual objects). We then stack multiple graph-based multi-modal fusion layers that iteratively perform semantic interactions to learn node representations. Finally, these representations provide an attention-based context vector for the decoder. We evaluate our proposed encoder on the Multi30K datasets. Experimental results and in-depth analysis show the superiority of our multi-modal NMT model.
Modeling Discourse Structure for Document-level Neural Machine Translation
Jun 08, 2020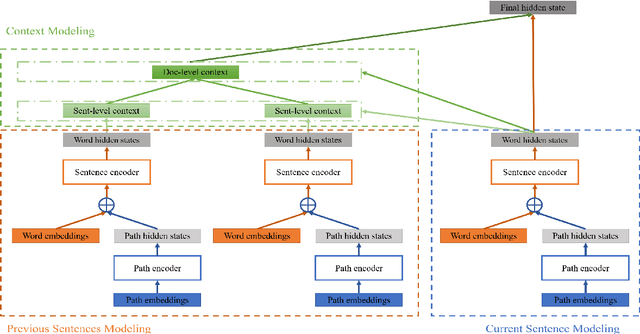
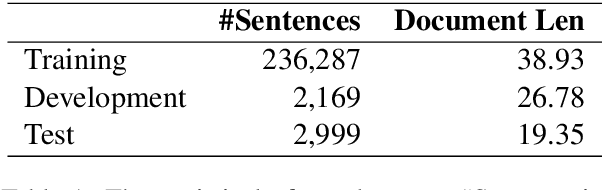
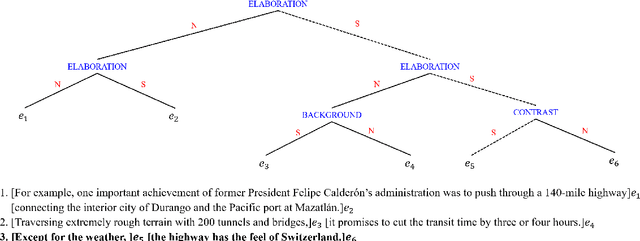
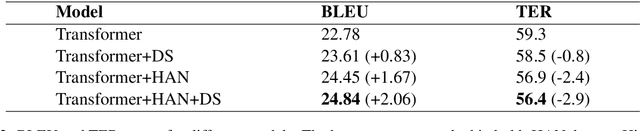
Recently, document-level neural machine translation (NMT) has become a hot topic in the community of machine translation. Despite its success, most of existing studies ignored the discourse structure information of the input document to be translated, which has shown effective in other tasks. In this paper, we propose to improve document-level NMT with the aid of discourse structure information. Our encoder is based on a hierarchical attention network (HAN). Specifically, we first parse the input document to obtain its discourse structure. Then, we introduce a Transformer-based path encoder to embed the discourse structure information of each word. Finally, we combine the discourse structure information with the word embedding before it is fed into the encoder. Experimental results on the English-to-German dataset show that our model can significantly outperform both Transformer and Transformer+HAN.
Exploring Contextual Word-level Style Relevance for Unsupervised Style Transfer
May 05, 2020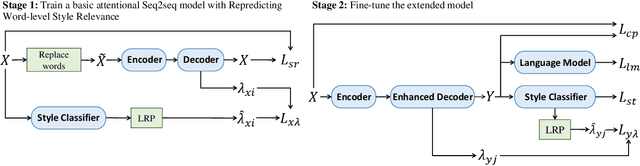
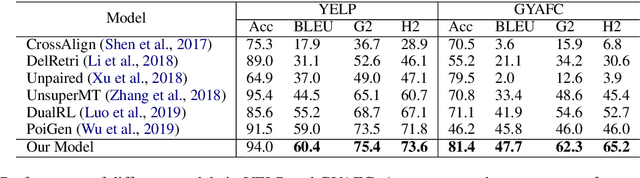
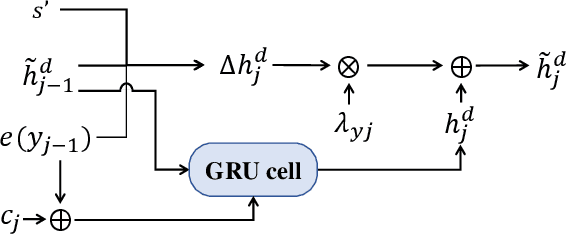
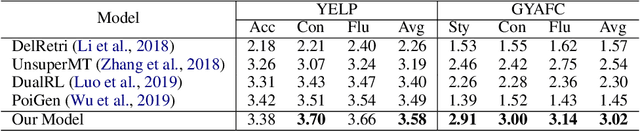
Unsupervised style transfer aims to change the style of an input sentence while preserving its original content without using parallel training data. In current dominant approaches, owing to the lack of fine-grained control on the influence from the target style,they are unable to yield desirable output sentences. In this paper, we propose a novel attentional sequence-to-sequence (Seq2seq) model that dynamically exploits the relevance of each output word to the target style for unsupervised style transfer. Specifically, we first pretrain a style classifier, where the relevance of each input word to the original style can be quantified via layer-wise relevance propagation. In a denoising auto-encoding manner, we train an attentional Seq2seq model to reconstruct input sentences and repredict word-level previously-quantified style relevance simultaneously. In this way, this model is endowed with the ability to automatically predict the style relevance of each output word. Then, we equip the decoder of this model with a neural style component to exploit the predicted wordlevel style relevance for better style transfer. Particularly, we fine-tune this model using a carefully-designed objective function involving style transfer, style relevance consistency, content preservation and fluency modeling loss terms. Experimental results show that our proposed model achieves state-of-the-art performance in terms of both transfer accuracy and content preservation.
Graph-based Neural Sentence Ordering
Dec 16, 2019
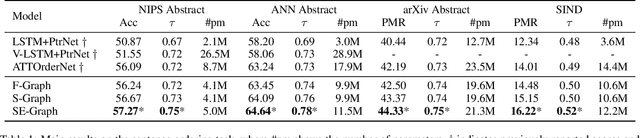
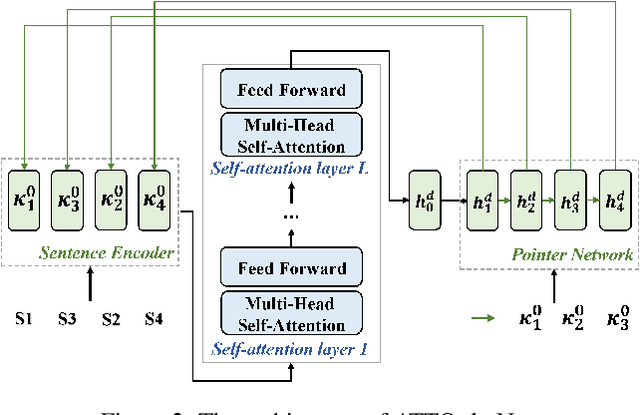
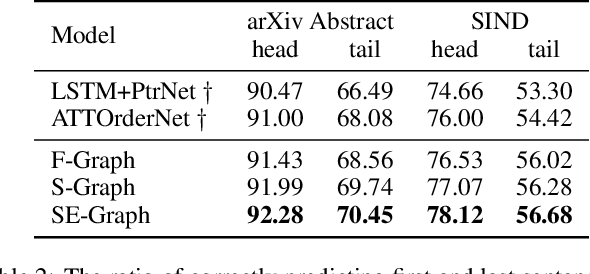
Sentence ordering is to restore the original paragraph from a set of sentences. It involves capturing global dependencies among sentences regardless of their input order. In this paper, we propose a novel and flexible graph-based neural sentence ordering model, which adopts graph recurrent network \cite{Zhang:acl18} to accurately learn semantic representations of the sentences. Instead of assuming connections between all pairs of input sentences, we use entities that are shared among multiple sentences to make more expressive graph representations with less noise. Experimental results show that our proposed model outperforms the existing state-of-the-art systems on several benchmark datasets, demonstrating the effectiveness of our model. We also conduct a thorough analysis on how entities help the performance.