 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to EdgeLow Latency of object detection for spikng neural network
Sep 27, 2023Spiking Neural Networks, as a third-generation neural network, are well-suited for edge AI applications due to their binary spike nature. However, when it comes to complex tasks like object detection, SNNs often require a substantial number of time steps to achieve high performance. This limitation significantly hampers the widespread adoption of SNNs in latency-sensitive edge devices. In this paper, our focus is on generating highly accurate and low-latency SNNs specifically for object detection. Firstly, we systematically derive the conversion between SNNs and ANNs and analyze how to improve the consistency between them: improving the spike firing rate and reducing the quantization error. Then we propose a structural replacement, quantization of ANN activation and residual fix to allevicate the disparity. We evaluate our method on challenging dataset MS COCO, PASCAL VOC and our spike dataset. The experimental results show that the proposed method achieves higher accuracy and lower latency compared to previous work Spiking-YOLO. The advantages of SNNs processing of spike signals are also demonstrated.
RestNet: Boosting Cross-Domain Few-Shot Segmentation with Residual Transformation Network
Sep 14, 2023



Cross-domain few-shot segmentation (CD-FSS) aims to achieve semantic segmentation in previously unseen domains with a limited number of annotated samples. Although existing CD-FSS models focus on cross-domain feature transformation, relying exclusively on inter-domain knowledge transfer may lead to the loss of critical intra-domain information. To this end, we propose a novel residual transformation network (RestNet) that facilitates knowledge transfer while retaining the intra-domain support-query feature information. Specifically, we propose a Semantic Enhanced Anchor Transform (SEAT) module that maps features to a stable domain-agnostic space using advanced semantics. Additionally, an Intra-domain Residual Enhancement (IRE) module is designed to maintain the intra-domain representation of the original discriminant space in the new space. We also propose a mask prediction strategy based on prototype fusion to help the model gradually learn how to segment. Our RestNet can transfer cross-domain knowledge from both inter-domain and intra-domain without requiring additional fine-tuning. Extensive experiments on ISIC, Chest X-ray, and FSS-1000 show that our RestNet achieves state-of-the-art performance. Our code will be available soon.
An Adaptive Spatial-Temporal Local Feature Difference Method for Infrared Small-moving Target Detection
Sep 05, 2023Detecting small moving targets accurately in infrared (IR) image sequences is a significant challenge. To address this problem, we propose a novel method called spatial-temporal local feature difference (STLFD) with adaptive background suppression (ABS). Our approach utilizes filters in the spatial and temporal domains and performs pixel-level ABS on the output to enhance the contrast between the target and the background. The proposed method comprises three steps. First, we obtain three temporal frame images based on the current frame image and extract two feature maps using the designed spatial domain and temporal domain filters. Next, we fuse the information of the spatial domain and temporal domain to produce the spatial-temporal feature maps and suppress noise using our pixel-level ABS module. Finally, we obtain the segmented binary map by applying a threshold. Our experimental results demonstrate that the proposed method outperforms existing state-of-the-art methods for infrared small-moving target detection.
Temporal Consistent Automatic Video Colorization via Semantic Correspondence
May 13, 2023Video colorization task has recently attracted wide attention. Recent methods mainly work on the temporal consistency in adjacent frames or frames with small interval. However, it still faces severe challenge of the inconsistency between frames with large interval.To address this issue, we propose a novel video colorization framework, which combines semantic correspondence into automatic video colorization to keep long-range consistency. Firstly, a reference colorization network is designed to automatically colorize the first frame of each video, obtaining a reference image to supervise the following whole colorization process. Such automatically colorized reference image can not only avoid labor-intensive and time-consuming manual selection, but also enhance the similarity between reference and grayscale images. Afterwards, a semantic correspondence network and an image colorization network are introduced to colorize a series of the remaining frames with the help of the reference. Each frame is supervised by both the reference image and the immediately colorized preceding frame to improve both short-range and long-range temporal consistency. Extensive experiments demonstrate that our method outperforms other methods in maintaining temporal consistency both qualitatively and quantitatively. In the NTIRE 2023 Video Colorization Challenge, our method ranks at the 3rd place in Color Distribution Consistency (CDC) Optimization track.
A Self-Training Framework Based on Multi-Scale Attention Fusion for Weakly Supervised Semantic Segmentation
May 10, 2023



Weakly supervised semantic segmentation (WSSS) based on image-level labels is challenging since it is hard to obtain complete semantic regions. To address this issue, we propose a self-training method that utilizes fused multi-scale class-aware attention maps. Our observation is that attention maps of different scales contain rich complementary information, especially for large and small objects. Therefore, we collect information from attention maps of different scales and obtain multi-scale attention maps. We then apply denoising and reactivation strategies to enhance the potential regions and reduce noisy areas. Finally, we use the refined attention maps to retrain the network. Experiments showthat our method enables the model to extract rich semantic information from multi-scale images and achieves 72.4% mIou scores on both the PASCAL VOC 2012 validation and test sets. The code is available at https://bupt-ai-cz.github.io/SMAF.
Breast Cancer Immunohistochemical Image Generation: a Benchmark Dataset and Challenge Review
May 05, 2023



For invasive breast cancer, immunohistochemical (IHC) techniques are often used to detect the expression level of human epidermal growth factor receptor-2 (HER2) in breast tissue to formulate a precise treatment plan. From the perspective of saving manpower, material and time costs, directly generating IHC-stained images from hematoxylin and eosin (H&E) stained images is a valuable research direction. Therefore, we held the breast cancer immunohistochemical image generation challenge, aiming to explore novel ideas of deep learning technology in pathological image generation and promote research in this field. The challenge provided registered H&E and IHC-stained image pairs, and participants were required to use these images to train a model that can directly generate IHC-stained images from corresponding H&E-stained images. We selected and reviewed the five highest-ranking methods based on their PSNR and SSIM metrics, while also providing overviews of the corresponding pipelines and implementations. In this paper, we further analyze the current limitations in the field of breast cancer immunohistochemical image generation and forecast the future development of this field. We hope that the released dataset and the challenge will inspire more scholars to jointly study higher-quality IHC-stained image generation.
Semi-supervised Domain Adaptation via Prototype-based Multi-level Learning
May 04, 2023In semi-supervised domain adaptation (SSDA), a few labeled target samples of each class help the model to transfer knowledge representation from the fully labeled source domain to the target domain. Many existing methods ignore the benefits of making full use of the labeled target samples from multi-level. To make better use of this additional data, we propose a novel Prototype-based Multi-level Learning (ProML) framework to better tap the potential of labeled target samples. To achieve intra-domain adaptation, we first introduce a pseudo-label aggregation based on the intra-domain optimal transport to help the model align the feature distribution of unlabeled target samples and the prototype. At the inter-domain level, we propose a cross-domain alignment loss to help the model use the target prototype for cross-domain knowledge transfer. We further propose a dual consistency based on prototype similarity and linear classifier to promote discriminative learning of compact target feature representation at the batch level. Extensive experiments on three datasets, including DomainNet, VisDA2017, and Office-Home demonstrate that our proposed method achieves state-of-the-art performance in SSDA.
Hard-aware Instance Adaptive Self-training for Unsupervised Cross-domain Semantic Segmentation
Feb 14, 2023



The divergence between labeled training data and unlabeled testing data is a significant challenge for recent deep learning models. Unsupervised domain adaptation (UDA) attempts to solve such problem. Recent works show that self-training is a powerful approach to UDA. However, existing methods have difficulty in balancing the scalability and performance. In this paper, we propose a hard-aware instance adaptive self-training framework for UDA on the task of semantic segmentation. To effectively improve the quality and diversity of pseudo-labels, we develop a novel pseudo-label generation strategy with an instance adaptive selector. We further enrich the hard class pseudo-labels with inter-image information through a skillfully designed hard-aware pseudo-label augmentation. Besides, we propose the region-adaptive regularization to smooth the pseudo-label region and sharpen the non-pseudo-label region. For the non-pseudo-label region, consistency constraint is also constructed to introduce stronger supervision signals during model optimization. Our method is so concise and efficient that it is easy to be generalized to other UDA methods. Experiments on GTA5 to Cityscapes, SYNTHIA to Cityscapes, and Cityscapes to Oxford RobotCar demonstrate the superior performance of our approach compared with the state-of-the-art methods.
TCNL: Transparent and Controllable Network Learning Via Embedding Human-Guided Concepts
Oct 07, 2022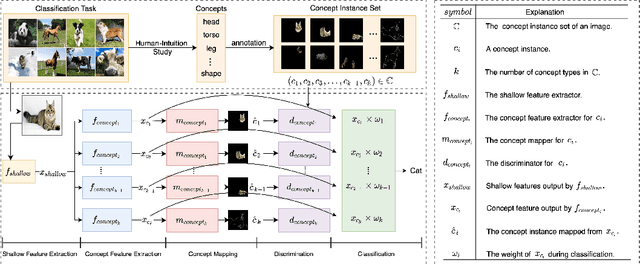


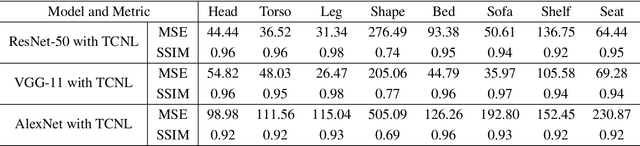
Explaining deep learning models is of vital importance for understanding artificial intelligence systems, improving safety, and evaluating fairness. To better understand and control the CNN model, many methods for transparency-interpretability have been proposed. However, most of these works are less intuitive for human understanding and have insufficient human control over the CNN model. We propose a novel method, Transparent and Controllable Network Learning (TCNL), to overcome such challenges. Towards the goal of improving transparency-interpretability, in TCNL, we define some concepts for specific classification tasks through scientific human-intuition study and incorporate concept information into the CNN model. In TCNL, the shallow feature extractor gets preliminary features first. Then several concept feature extractors are built right after the shallow feature extractor to learn high-dimensional concept representations. The concept feature extractor is encouraged to encode information related to the predefined concepts. We also build the concept mapper to visualize features extracted by the concept extractor in a human-intuitive way. TCNL provides a generalizable approach to transparency-interpretability. Researchers can define concepts corresponding to certain classification tasks and encourage the model to encode specific concept information, which to a certain extent improves transparency-interpretability and the controllability of the CNN model. The datasets (with concept sets) for our experiments will also be released (https://github.com/bupt-ai-cz/TCNL).
WUDA: Unsupervised Domain Adaptation Based on Weak Source Domain Labels
Oct 05, 2022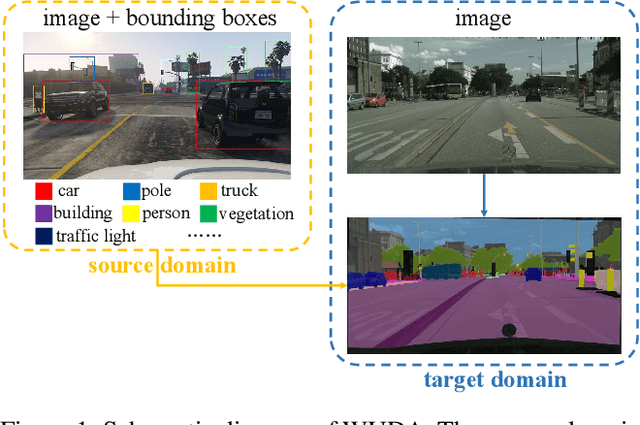

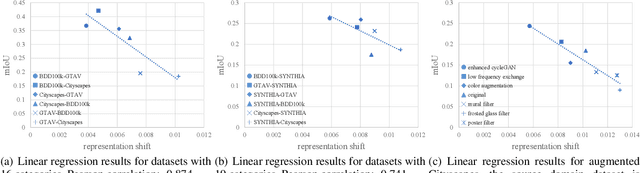
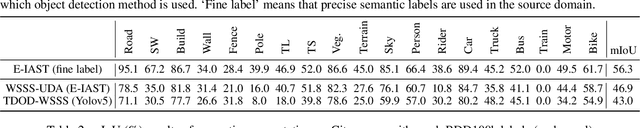
Unsupervised domain adaptation (UDA) for semantic segmentation addresses the cross-domain problem with fine source domain labels. However, the acquisition of semantic labels has always been a difficult step, many scenarios only have weak labels (e.g. bounding boxes). For scenarios where weak supervision and cross-domain problems coexist, this paper defines a new task: unsupervised domain adaptation based on weak source domain labels (WUDA). To explore solutions for this task, this paper proposes two intuitive frameworks: 1) Perform weakly supervised semantic segmentation in the source domain, and then implement unsupervised domain adaptation; 2) Train an object detection model using source domain data, then detect objects in the target domain and implement weakly supervised semantic segmentation. We observe that the two frameworks behave differently when the datasets change. Therefore, we construct dataset pairs with a wide range of domain shifts and conduct extended experiments to analyze the impact of different domain shifts on the two frameworks. In addition, to measure domain shift, we apply the metric representation shift to urban landscape image segmentation for the first time. The source code and constructed datasets are available at \url{https://github.com/bupt-ai-cz/WUDA}.