 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to EdgeCombinatorial optimization solving by coherent Ising machines based on spiking neural networks
Aug 16, 2022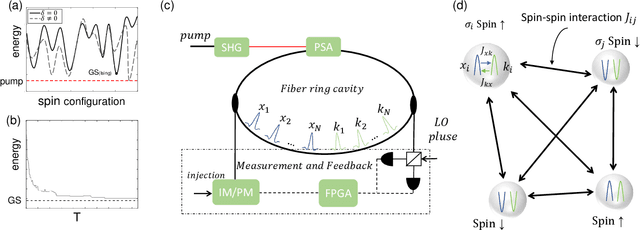
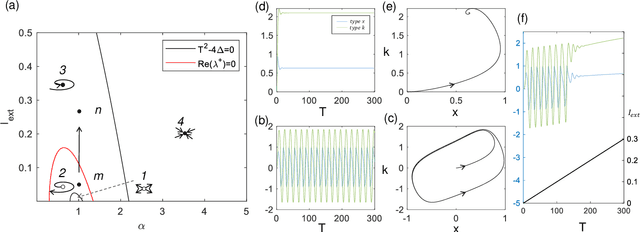
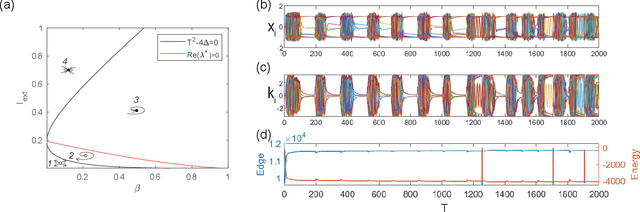
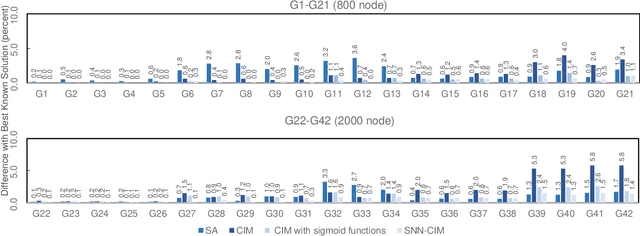
Spiking neural network is a kind of neuromorphic computing which is believed to improve on the level of intelligence and provide advabtages for quantum computing. In this work, we address this issue by designing an optical spiking neural network and prove that it can be used to accelerate the speed of computation, especially on the combinatorial optimization problems. Here the spiking neural network is constructed by the antisymmetrically coupled degenerate optical parametric oscillator pulses and dissipative pulses. A nonlinear transfer function is chosen to mitigate amplitude inhomogeneities and destabilize the resulting local minima according to the dynamical behavior of spiking neurons. It is numerically proved that the spiking neural network-coherent Ising machines has excellent performance on combinatorial optimization problems, for which is expected to offer a new applications for neural computing and optical computing.
On the Use of BERT for Automated Essay Scoring: Joint Learning of Multi-Scale Essay Representation
May 21, 2022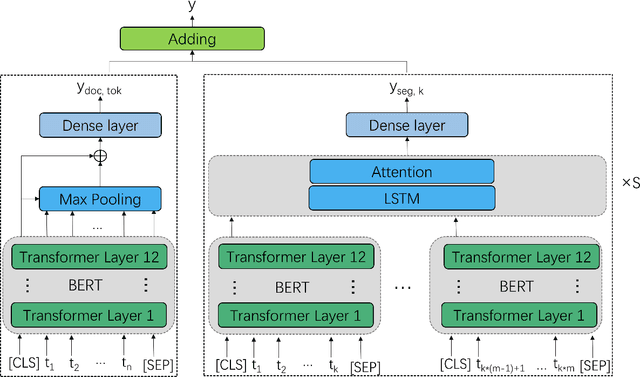
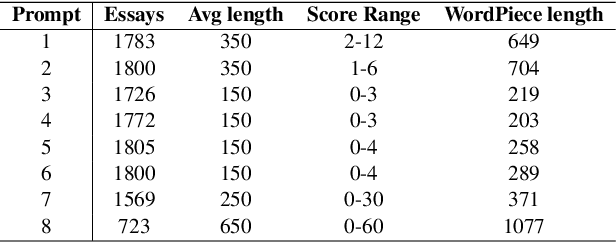
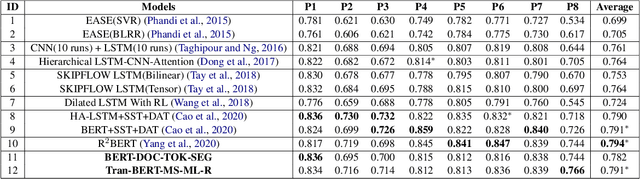
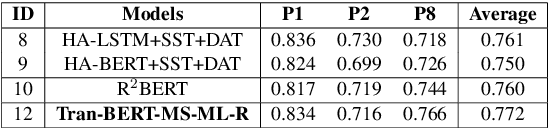
In recent years, pre-trained models have become dominant in most natural language processing (NLP) tasks. However, in the area of Automated Essay Scoring (AES), pre-trained models such as BERT have not been properly used to outperform other deep learning models such as LSTM. In this paper, we introduce a novel multi-scale essay representation for BERT that can be jointly learned. We also employ multiple losses and transfer learning from out-of-domain essays to further improve the performance. Experiment results show that our approach derives much benefit from joint learning of multi-scale essay representation and obtains almost the state-of-the-art result among all deep learning models in the ASAP task. Our multi-scale essay representation also generalizes well to CommonLit Readability Prize data set, which suggests that the novel text representation proposed in this paper may be a new and effective choice for long-text tasks.
ASFlow: Unsupervised Optical Flow Learning with Adaptive Pyramid Sampling
Apr 08, 2021
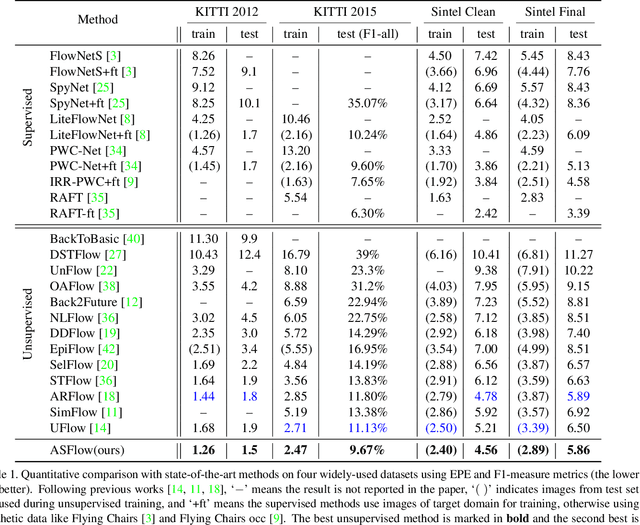
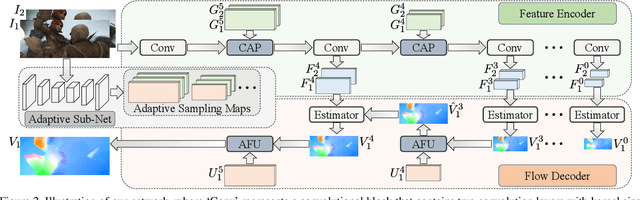
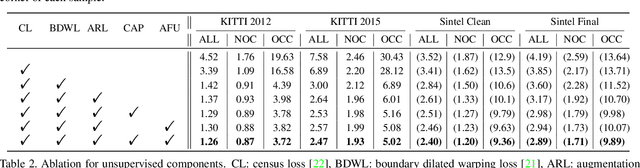
We present an unsupervised optical flow estimation method by proposing an adaptive pyramid sampling in the deep pyramid network. Specifically, in the pyramid downsampling, we propose an Content Aware Pooling (CAP) module, which promotes local feature gathering by avoiding cross region pooling, so that the learned features become more representative. In the pyramid upsampling, we propose an Adaptive Flow Upsampling (AFU) module, where cross edge interpolation can be avoided, producing sharp motion boundaries. Equipped with these two modules, our method achieves the best performance for unsupervised optical flow estimation on multiple leading benchmarks, including MPI-SIntel, KITTI 2012 and KITTI 2015. Particuarlly, we achieve EPE=1.5 on KITTI 2012 and F1=9.67% KITTI 2015, which outperform the previous state-of-the-art methods by 16.7% and 13.1%, respectively.
Motion Basis Learning for Unsupervised Deep Homography Estimation with Subspace Projection
Mar 29, 2021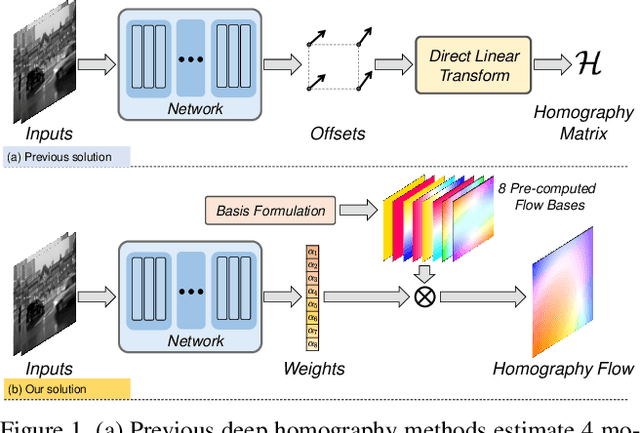
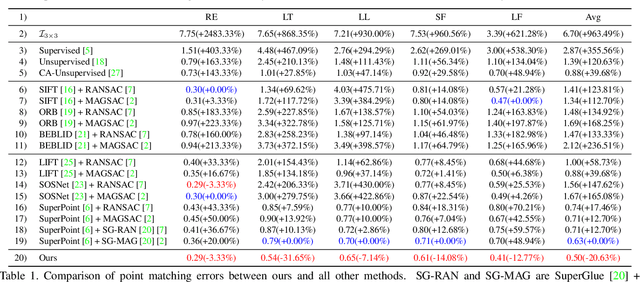

In this paper, we introduce a new framework for unsupervised deep homography estimation. Our contributions are 3 folds. First, unlike previous methods that regress 4 offsets for a homography, we propose a homography flow representation, which can be estimated by a weighted sum of 8 pre-defined homography flow bases. Second, considering a homography contains 8 Degree-of-Freedoms (DOFs) that is much less than the rank of the network features, we propose a Low Rank Representation (LRR) block that reduces the feature rank, so that features corresponding to the dominant motions are retained while others are rejected. Last, we propose a Feature Identity Loss (FIL) to enforce the learned image feature warp-equivariant, meaning that the result should be identical if the order of warp operation and feature extraction is swapped. With this constraint, the unsupervised optimization is achieved more effectively and more stable features are learned. Extensive experiments are conducted to demonstrate the effectiveness of all the newly proposed components, and results show our approach outperforms the state-of-the-art on the homography benchmark datasets both qualitatively and quantitatively.
UPHDR-GAN: Generative Adversarial Network for High Dynamic Range Imaging with Unpaired Data
Feb 03, 2021
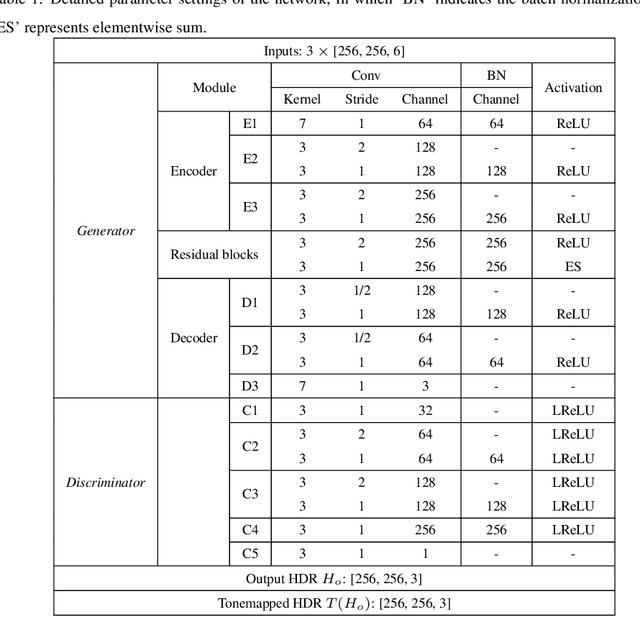
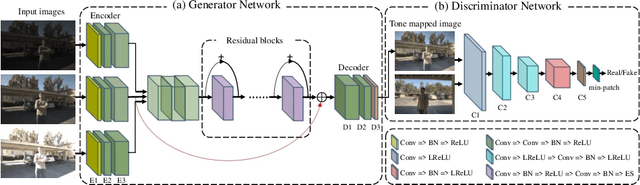

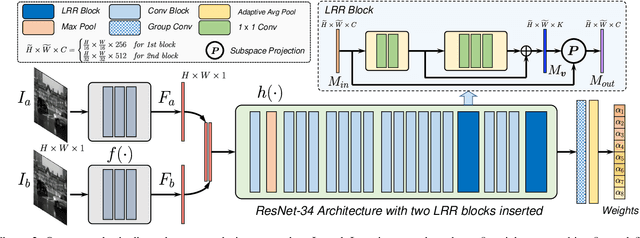
The paper proposes a method to effectively fuse multi-exposure inputs and generates high-quality high dynamic range (HDR) images with unpaired datasets. Deep learning-based HDR image generation methods rely heavily on paired datasets. The ground truth provides information for the network getting HDR images without ghosting. Datasets without ground truth are hard to apply to train deep neural networks. Recently, Generative Adversarial Networks (GAN) have demonstrated their potentials of translating images from source domain X to target domain Y in the absence of paired examples. In this paper, we propose a GAN-based network for solving such problems while generating enjoyable HDR results, named UPHDR-GAN. The proposed method relaxes the constraint of paired dataset and learns the mapping from LDR domain to HDR domain. Although the pair data are missing, UPHDR-GAN can properly handle the ghosting artifacts caused by moving objects or misalignments with the help of modified GAN loss, improved discriminator network and useful initialization phase. The proposed method preserves the details of important regions and improves the total image perceptual quality. Qualitative and quantitative comparisons against other methods demonstrated the superiority of our method.
UPFlow: Upsampling Pyramid for Unsupervised Optical Flow Learning
Dec 01, 2020
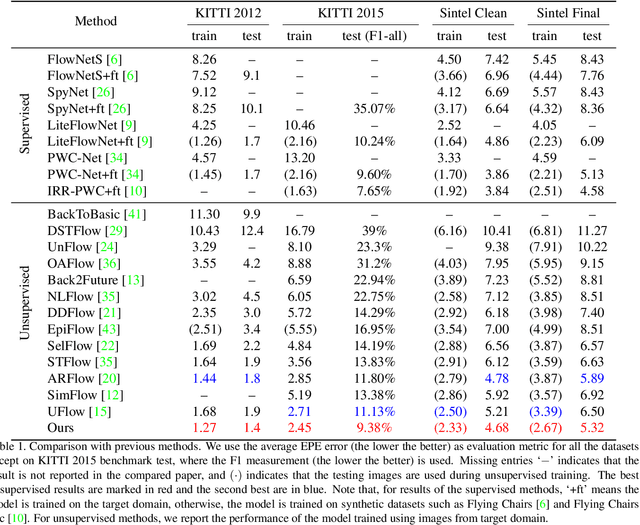
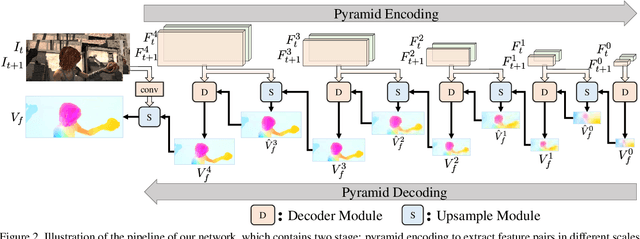
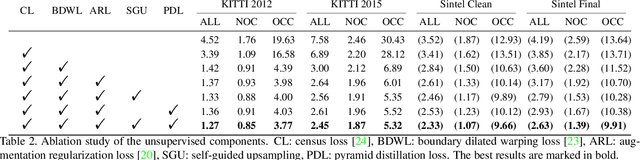
We present an unsupervised learning approach for optical flow estimation by improving the upsampling and learning of pyramid network. We design a self-guided upsample module to tackle the interpolation blur problem caused by bilinear upsampling between pyramid levels. Moreover, we propose a pyramid distillation loss to add supervision for intermediate levels via distilling the finest flow as pseudo labels. By integrating these two components together, our method achieves the best performance for unsupervised optical flow learning on multiple leading benchmarks, including MPI-SIntel, KITTI 2012 and KITTI 2015. In particular, we achieve EPE=1.4 on KITTI 2012 and F1=9.38% on KITTI 2015, which outperform the previous state-of-the-art methods by 22.2% and 15.7%, respectively.
HypperSteer: Hypothetical Steering and Data Perturbation in Sequence Prediction with Deep Learning
Nov 04, 2020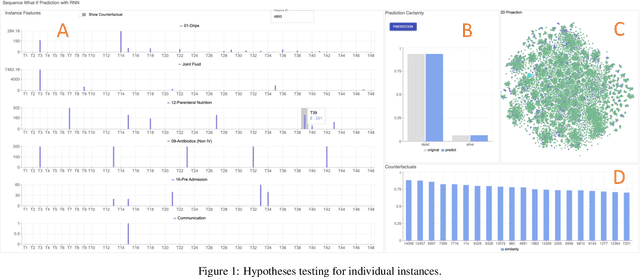
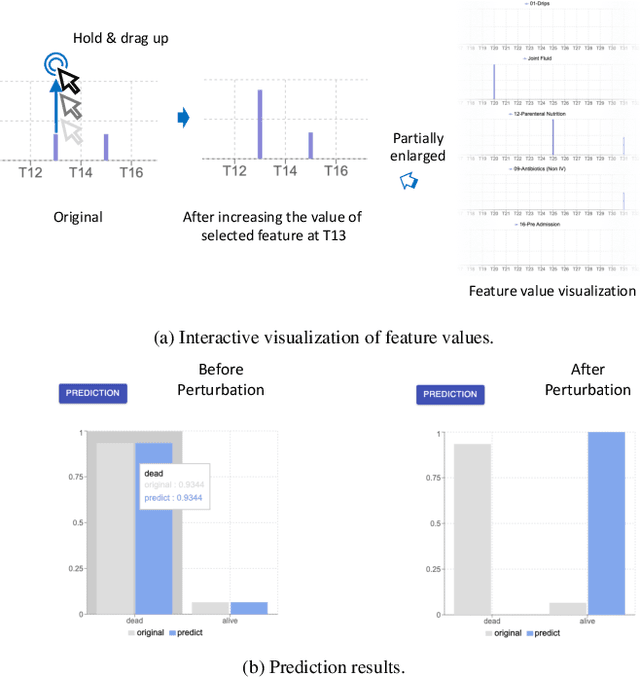
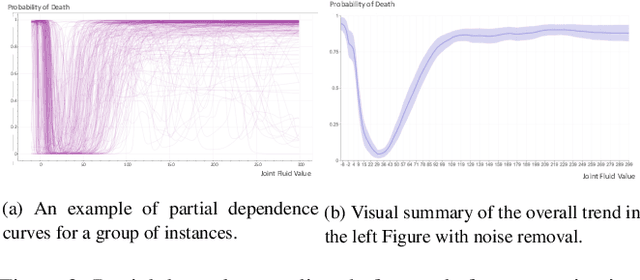
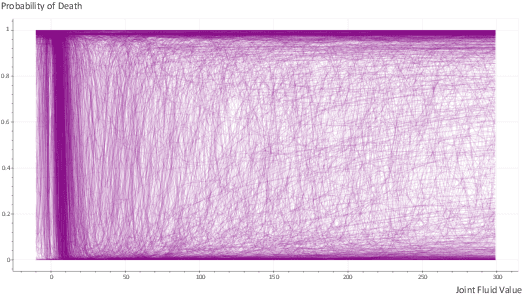
Deep Recurrent Neural Networks (RNN) continues to find success in predictive decision-making with temporal event sequences. Recent studies have shown the importance and practicality of visual analytics in interpreting deep learning models for real-world applications. However, very limited work enables interactions with deep learning models and guides practitioners to form hypotheticals towards the desired prediction outcomes, especially for sequence prediction. Specifically, no existing work has addressed the what-if analysis and value perturbation along different time-steps for sequence outcome prediction. We present a model-agnostic visual analytics tool, HypperSteer, that steers hypothetical testing and allows users to perturb data for sequence predictions interactively. We showcase how HypperSteer helps in steering patient data to achieve desired treatment outcomes and discuss how HypperSteer can serve as a comprehensive solution for other practical scenarios.
OccInpFlow: Occlusion-Inpainting Optical Flow Estimation by Unsupervised Learning
Jun 30, 2020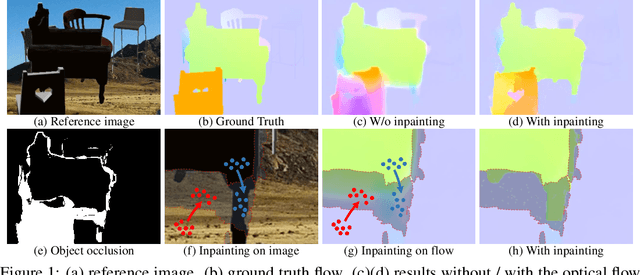
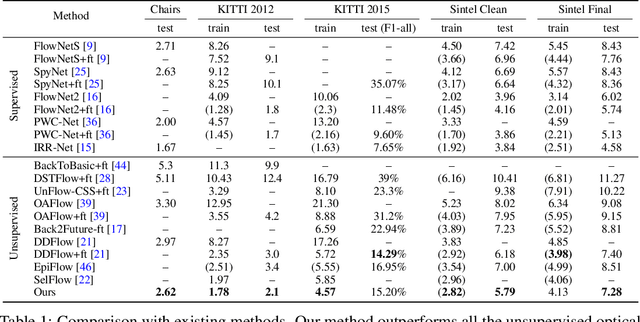
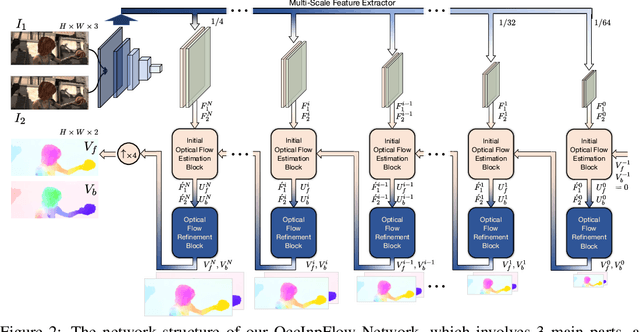
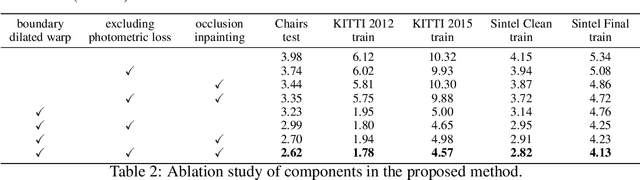
Occlusion is an inevitable and critical problem in unsupervised optical flow learning. Existing methods either treat occlusions equally as non-occluded regions or simply remove them to avoid incorrectness. However, the occlusion regions can provide effective information for optical flow learning. In this paper, we present OccInpFlow, an occlusion-inpainting framework to make full use of occlusion regions. Specifically, a new appearance-flow network is proposed to inpaint occluded flows based on the image content. Moreover, a boundary warp is proposed to deal with occlusions caused by displacement beyond image border. We conduct experiments on multiple leading flow benchmark data sets such as Flying Chairs, KITTI and MPI-Sintel, which demonstrate that the performance is significantly improved by our proposed occlusion handling framework.
FA-GANs: Facial Attractiveness Enhancement with Generative Adversarial Networks on Frontal Faces
Jun 06, 2020
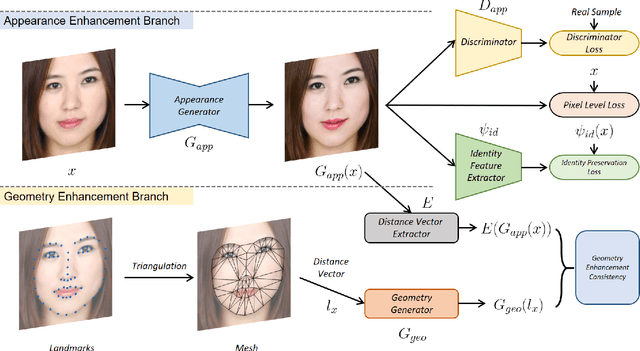


Facial attractiveness enhancement has been an interesting application in Computer Vision and Graphics over these years. It aims to generate a more attractive face via manipulations on image and geometry structure while preserving face identity. In this paper, we propose the first Generative Adversarial Networks (GANs) for enhancing facial attractiveness in both geometry and appearance aspects, which we call "FA-GANs". FA-GANs contain two branches and enhance facial attractiveness in two perspectives: facial geometry and facial appearance. Each branch consists of individual GANs with the appearance branch adjusting the facial image and the geometry branch adjusting the facial landmarks in appearance and geometry aspects, respectively. Unlike the traditional facial manipulations learning from paired faces, which are infeasible to collect before and after enhancement of the same individual, we achieve this by learning the features of attractiveness faces through unsupervised adversarial learning. The proposed FA-GANs are able to extract attractiveness features and impose them on the enhancement results. To better enhance faces, both the geometry and appearance networks are considered to refine the facial attractiveness by adjusting the geometry layout of faces and the appearance of faces independently. To the best of our knowledge, we are the first to enhance the facial attractiveness with GANs in both geometry and appearance aspects. The experimental results suggest that our FA-GANs can generate compelling perceptual results in both geometry structure and facial appearance and outperform current state-of-the-art methods.
Visual Summary of Value-level Feature Attribution in Prediction Classes with Recurrent Neural Networks
Jan 23, 2020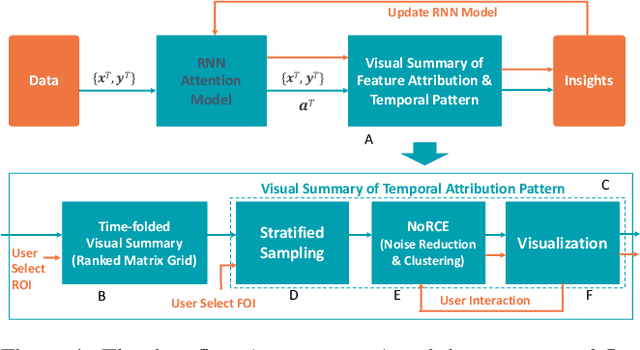
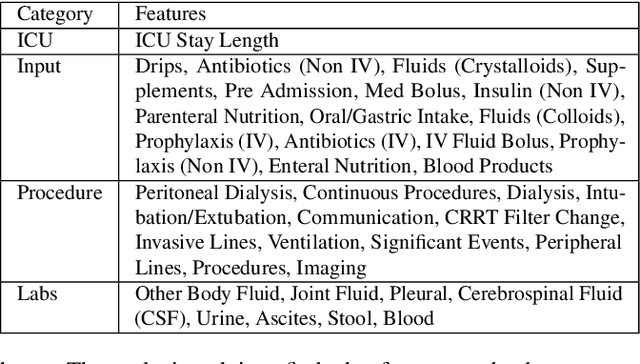
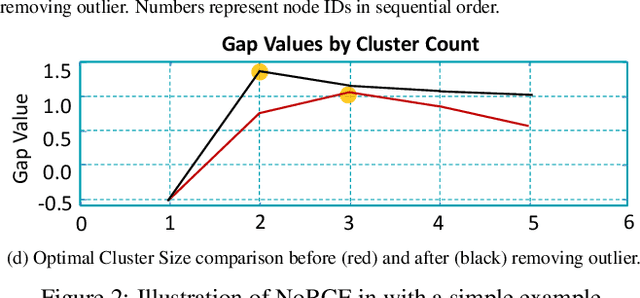
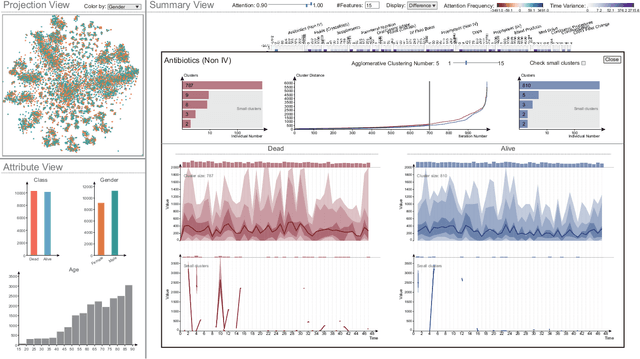
Deep Recurrent Neural Networks (RNN) is increasingly used in decision-making with temporal sequences. However, understanding how RNN models produce final predictions remains a major challenge. Existing work on interpreting RNN models for sequence predictions often focuses on explaining predictions for individual data instances (e.g., patients or students). Because state-of-the-art predictive models are formed with millions of parameters optimized over millions of instances, explaining predictions for single data instances can easily miss a bigger picture. Besides, many outperforming RNN models use multi-hot encoding to represent the presence/absence of features, where the interpretability of feature value attribution is missing. We present ViSFA, an interactive system that visually summarizes feature attribution over time for different feature values. ViSFA scales to large data such as the MIMIC dataset containing the electronic health records of 1.2 million high-dimensional temporal events. We demonstrate that ViSFA can help us reason RNN prediction and uncover insights from data by distilling complex attribution into compact and easy-to-interpret visualizations.