 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to EdgeSystematic Evaluation of Causal Discovery in Visual Model Based Reinforcement Learning
Jul 02, 2021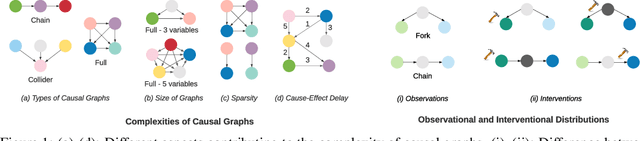
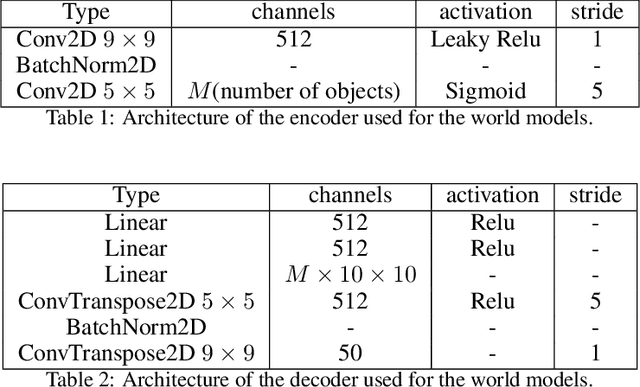
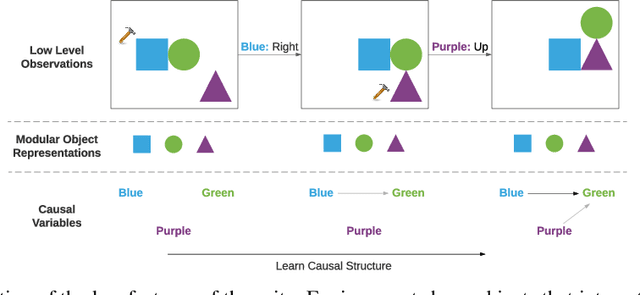
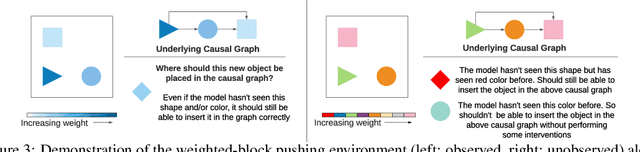
Inducing causal relationships from observations is a classic problem in machine learning. Most work in causality starts from the premise that the causal variables themselves are observed. However, for AI agents such as robots trying to make sense of their environment, the only observables are low-level variables like pixels in images. To generalize well, an agent must induce high-level variables, particularly those which are causal or are affected by causal variables. A central goal for AI and causality is thus the joint discovery of abstract representations and causal structure. However, we note that existing environments for studying causal induction are poorly suited for this objective because they have complicated task-specific causal graphs which are impossible to manipulate parametrically (e.g., number of nodes, sparsity, causal chain length, etc.). In this work, our goal is to facilitate research in learning representations of high-level variables as well as causal structures among them. In order to systematically probe the ability of methods to identify these variables and structures, we design a suite of benchmarking RL environments. We evaluate various representation learning algorithms from the literature and find that explicitly incorporating structure and modularity in models can help causal induction in model-based reinforcement learning.
Multi-Resolution Continuous Normalizing Flows
Jun 22, 2021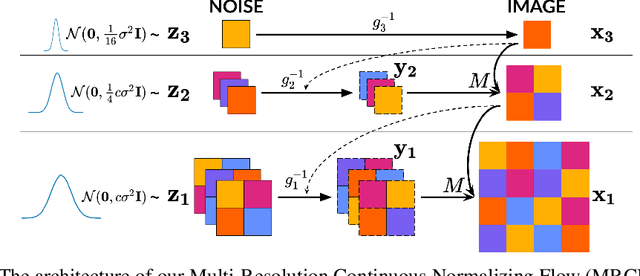
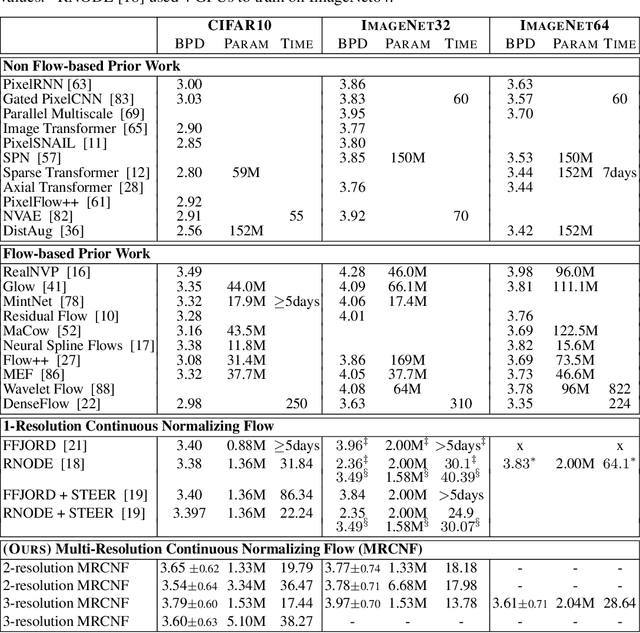
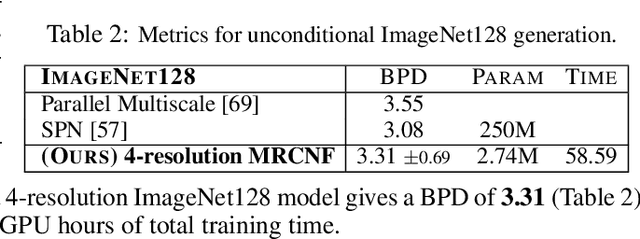

Recent work has shown that Neural Ordinary Differential Equations (ODEs) can serve as generative models of images using the perspective of Continuous Normalizing Flows (CNFs). Such models offer exact likelihood calculation, and invertible generation/density estimation. In this work we introduce a Multi-Resolution variant of such models (MRCNF), by characterizing the conditional distribution over the additional information required to generate a fine image that is consistent with the coarse image. We introduce a transformation between resolutions that allows for no change in the log likelihood. We show that this approach yields comparable likelihood values for various image datasets, with improved performance at higher resolutions, with fewer parameters, using only 1 GPU. Further, we examine the out-of-distribution properties of (Multi-Resolution) Continuous Normalizing Flows, and find that they are similar to those of other likelihood-based generative models.
Beyond Target Networks: Improving Deep $Q$-learning with Functional Regularization
Jun 07, 2021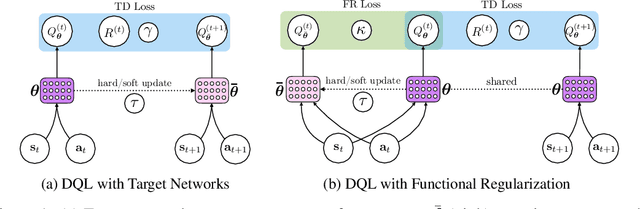
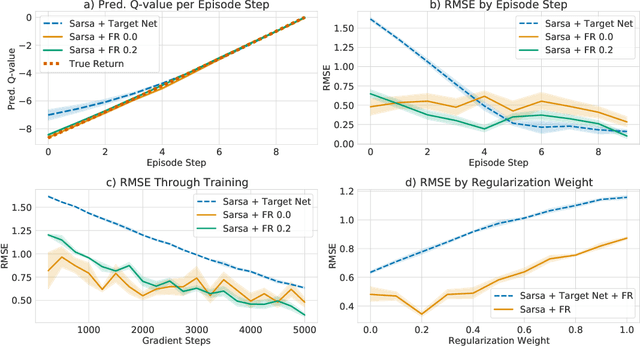

Target networks are at the core of recent success in Reinforcement Learning. They stabilize the training by using old parameters to estimate the $Q$-values, but this also limits the propagation of newly-encountered rewards which could ultimately slow down the training. In this work, we propose an alternative training method based on functional regularization which does not have this deficiency. Unlike target networks, our method uses up-to-date parameters to estimate the target $Q$-values, thereby speeding up training while maintaining stability. Surprisingly, in some cases, we can show that target networks are a special, restricted type of functional regularizers. Using this approach, we show empirical improvements in sample efficiency and performance across a range of Atari and simulated robotics environments.
Robust Motion In-betweening
Feb 09, 2021

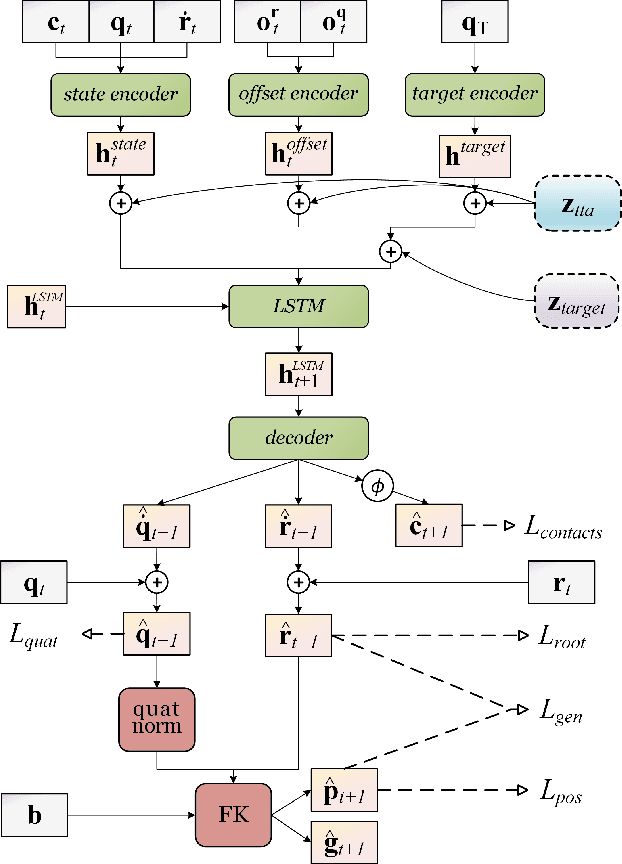
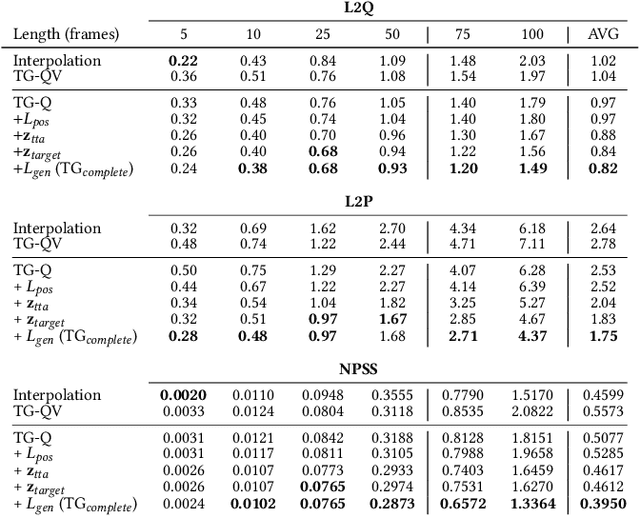
In this work we present a novel, robust transition generation technique that can serve as a new tool for 3D animators, based on adversarial recurrent neural networks. The system synthesizes high-quality motions that use temporally-sparse keyframes as animation constraints. This is reminiscent of the job of in-betweening in traditional animation pipelines, in which an animator draws motion frames between provided keyframes. We first show that a state-of-the-art motion prediction model cannot be easily converted into a robust transition generator when only adding conditioning information about future keyframes. To solve this problem, we then propose two novel additive embedding modifiers that are applied at each timestep to latent representations encoded inside the network's architecture. One modifier is a time-to-arrival embedding that allows variations of the transition length with a single model. The other is a scheduled target noise vector that allows the system to be robust to target distortions and to sample different transitions given fixed keyframes. To qualitatively evaluate our method, we present a custom MotionBuilder plugin that uses our trained model to perform in-betweening in production scenarios. To quantitatively evaluate performance on transitions and generalizations to longer time horizons, we present well-defined in-betweening benchmarks on a subset of the widely used Human3.6M dataset and on LaFAN1, a novel high quality motion capture dataset that is more appropriate for transition generation. We are releasing this new dataset along with this work, with accompanying code for reproducing our baseline results.
COVI-AgentSim: an Agent-based Model for Evaluating Methods of Digital Contact Tracing
Oct 30, 2020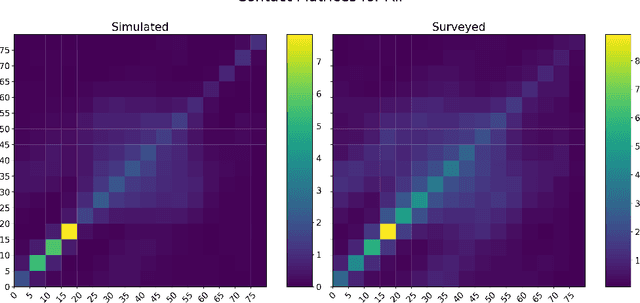
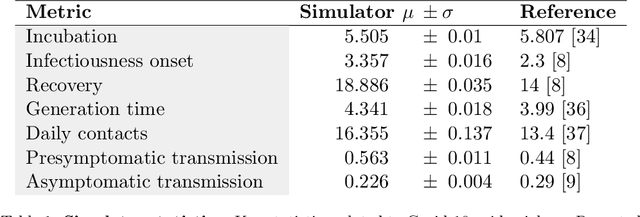
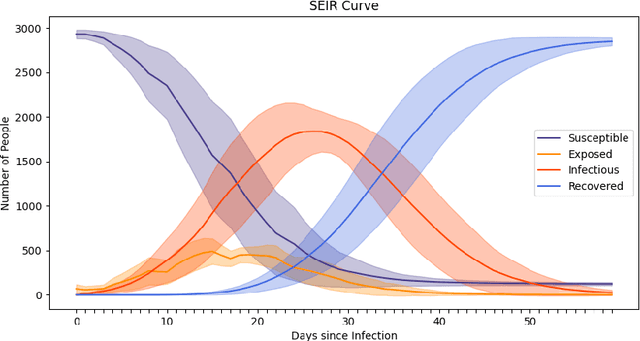
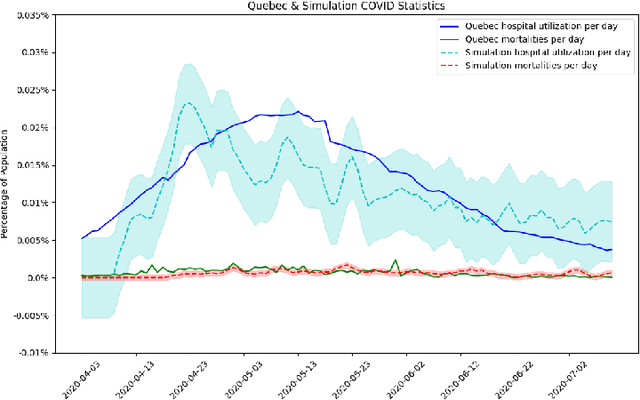
The rapid global spread of COVID-19 has led to an unprecedented demand for effective methods to mitigate the spread of the disease, and various digital contact tracing (DCT) methods have emerged as a component of the solution. In order to make informed public health choices, there is a need for tools which allow evaluation and comparison of DCT methods. We introduce an agent-based compartmental simulator we call COVI-AgentSim, integrating detailed consideration of virology, disease progression, social contact networks, and mobility patterns, based on parameters derived from empirical research. We verify by comparing to real data that COVI-AgentSim is able to reproduce realistic COVID-19 spread dynamics, and perform a sensitivity analysis to verify that the relative performance of contact tracing methods are consistent across a range of settings. We use COVI-AgentSim to perform cost-benefit analyses comparing no DCT to: 1) standard binary contact tracing (BCT) that assigns binary recommendations based on binary test results; and 2) a rule-based method for feature-based contact tracing (FCT) that assigns a graded level of recommendation based on diverse individual features. We find all DCT methods consistently reduce the spread of the disease, and that the advantage of FCT over BCT is maintained over a wide range of adoption rates. Feature-based methods of contact tracing avert more disability-adjusted life years (DALYs) per socioeconomic cost (measured by productive hours lost). Our results suggest any DCT method can help save lives, support re-opening of economies, and prevent second-wave outbreaks, and that FCT methods are a promising direction for enriching BCT using self-reported symptoms, yielding earlier warning signals and a significantly reduced spread of the virus per socioeconomic cost.
Learning to Summarize Long Texts with Memory Compression and Transfer
Oct 21, 2020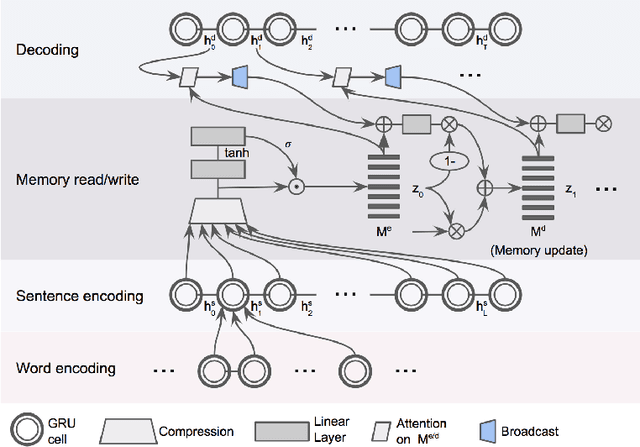
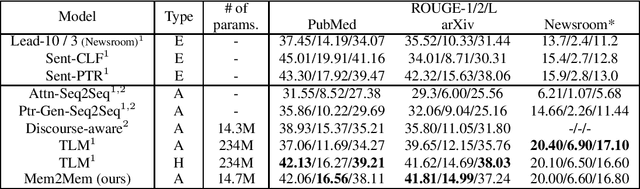
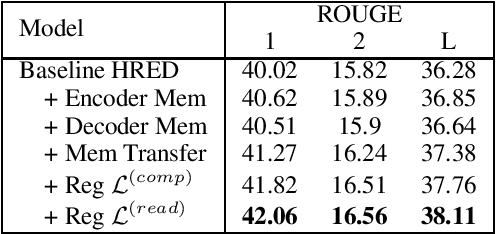
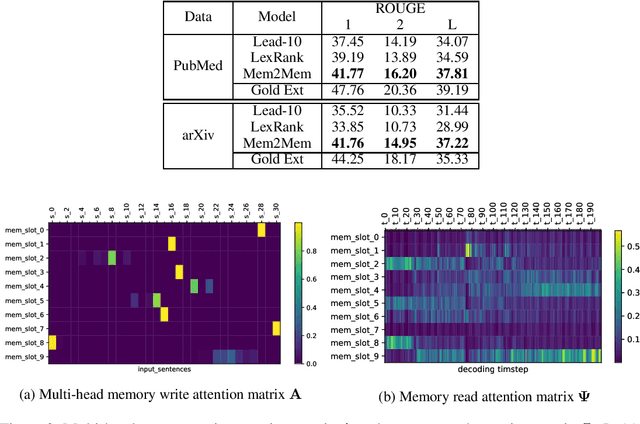
We introduce Mem2Mem, a memory-to-memory mechanism for hierarchical recurrent neural network based encoder decoder architectures and we explore its use for abstractive document summarization. Mem2Mem transfers "memories" via readable/writable external memory modules that augment both the encoder and decoder. Our memory regularization compresses an encoded input article into a more compact set of sentence representations. Most importantly, the memory compression step performs implicit extraction without labels, sidestepping issues with suboptimal ground-truth data and exposure bias of hybrid extractive-abstractive summarization techniques. By allowing the decoder to read/write over the encoded input memory, the model learns to read salient information about the input article while keeping track of what has been generated. Our Mem2Mem approach yields results that are competitive with state of the art transformer based summarization methods, but with 16 times fewer parameters
Measuring Systematic Generalization in Neural Proof Generation with Transformers
Oct 20, 2020

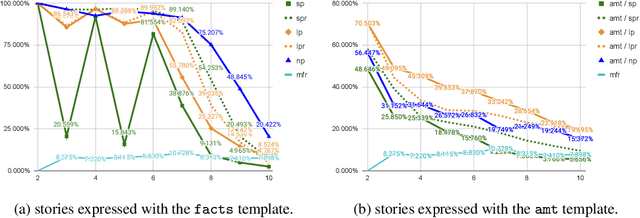
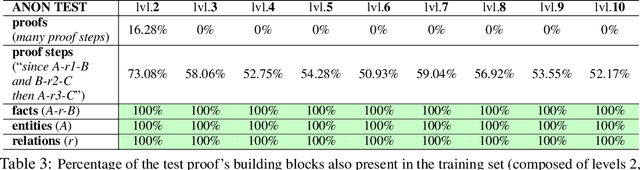
We are interested in understanding how well Transformer language models (TLMs) can perform reasoning tasks when trained on knowledge encoded in the form of natural language. We investigate their systematic generalization abilities on a logical reasoning task in natural language, which involves reasoning over relationships between entities grounded in first-order logical proofs. Specifically, we perform soft theorem-proving by leveraging TLMs to generate natural language proofs. We test the generated proofs for logical consistency, along with the accuracy of the final inference. We observe length-generalization issues when evaluated on longer-than-trained sequences. However, we observe TLMs improve their generalization performance after being exposed to longer, exhaustive proofs. In addition, we discover that TLMs are able to generalize better using backward-chaining proofs compared to their forward-chaining counterparts, while they find it easier to generate forward chaining proofs. We observe that models that are not trained to generate proofs are better at generalizing to problems based on longer proofs. This suggests that Transformers have efficient internal reasoning strategies that are harder to interpret. These results highlight the systematic generalization behavior of TLMs in the context of logical reasoning, and we believe this work motivates deeper inspection of their underlying reasoning strategies.
Reinforcement Learning with Random Delays
Oct 08, 2020
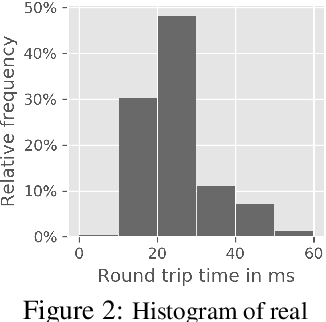

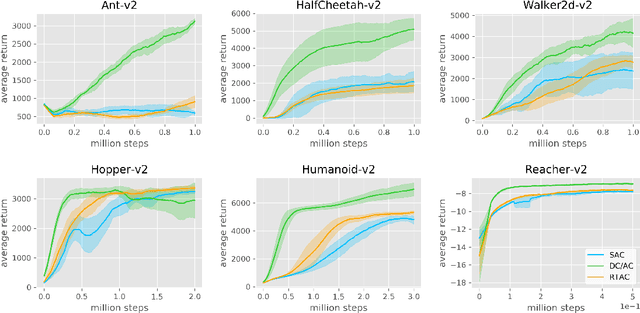
Action and observation delays commonly occur in many Reinforcement Learning applications, such as remote control scenarios. We study the anatomy of randomly delayed environments, and show that partially resampling trajectory fragments in hindsight allows for off-policy multi-step value estimation. We apply this principle to derive Delay-Correcting Actor-Critic (DCAC), an algorithm based on Soft Actor-Critic with significantly better performance in environments with delays. This is shown theoretically and also demonstrated practically on a delay-augmented version of the MuJoCo continuous control benchmark.
Conditionally Adaptive Multi-Task Learning: Improving Transfer Learning in NLP Using Fewer Parameters & Less Data
Sep 19, 2020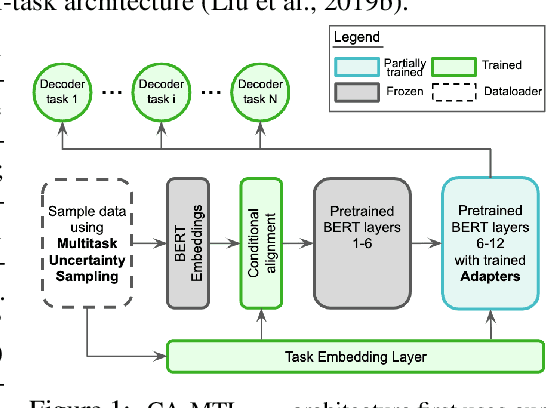
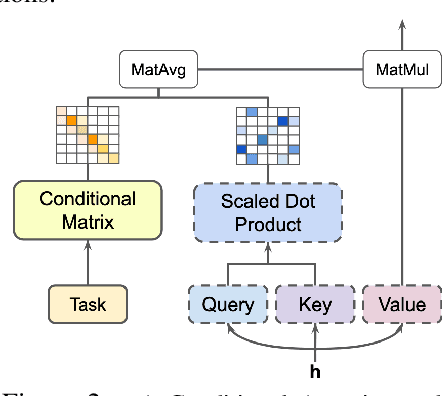
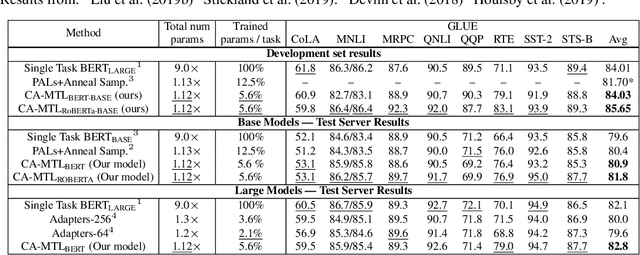
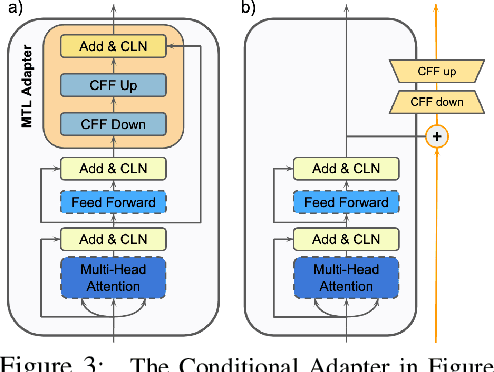
Multi-Task Learning (MTL) has emerged as a promising approach for transferring learned knowledge across different tasks. However, multi-task learning must deal with challenges such as: overfitting to low resource tasks, catastrophic forgetting, and negative task transfer, or learning interference. Additionally, in Natural Language Processing (NLP), MTL alone has typically not reached the performance level possible through per-task fine-tuning of pretrained models. However, many fine-tuning approaches are both parameter inefficient, e.g. potentially involving one new model per task, and highly susceptible to losing knowledge acquired during pretraining. We propose a novel transformer based architecture consisting of a new conditional attention mechanism as well as a set of task conditioned modules that facilitate weight sharing. Through this construction we achieve more efficient parameter sharing and mitigate forgetting by keeping half of the weights of a pretrained model fixed. We also use a new multi-task data sampling strategy to mitigate the negative effects of data imbalance across tasks. Using this approach we are able to surpass single-task fine-tuning methods while being parameter and data efficient. With our base model, we attain 2.2% higher performance compared to a full fine-tuned BERT large model on the GLUE benchmark, adding only 5.6% more trained parameters per task (whereas naive fine-tuning potentially adds 100% of the trained parameters per task) and needing only 64.6% of the data. We show that a larger variant of our single multi-task model approach performs competitively across 26 NLP tasks and yields state-of-the-art results on a number of test and development sets.
Action-Based Representation Learning for Autonomous Driving
Aug 21, 2020
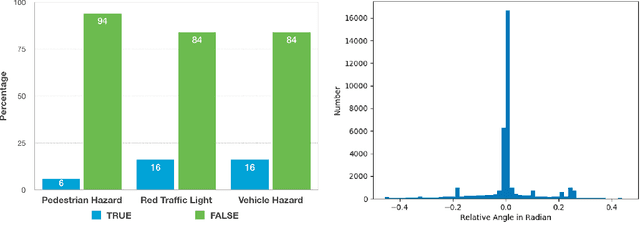
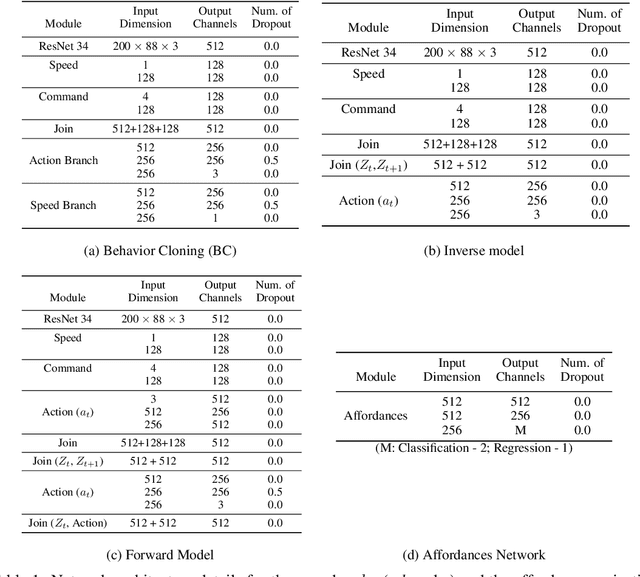
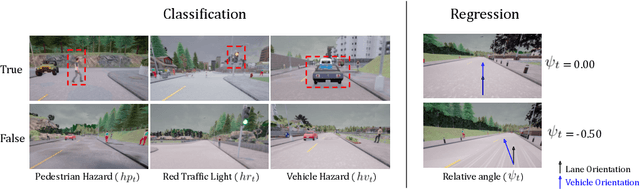
Human drivers produce a vast amount of data which could, in principle, be used to improve autonomous driving systems. Unfortunately, seemingly straightforward approaches for creating end-to-end driving models that map sensor data directly into driving actions are problematic in terms of interpretability, and typically have significant difficulty dealing with spurious correlations. Alternatively, we propose to use this kind of action-based driving data for learning representations. Our experiments show that an affordance-based driving model pre-trained with this approach can leverage a relatively small amount of weakly annotated imagery and outperform pure end-to-end driving models, while being more interpretable. Further, we demonstrate how this strategy outperforms previous methods based on learning inverse dynamics models as well as other methods based on heavy human supervision (ImageNet).