 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to EdgeDynamic Encoder Transducer: A Flexible Solution For Trading Off Accuracy For Latency
Apr 05, 2021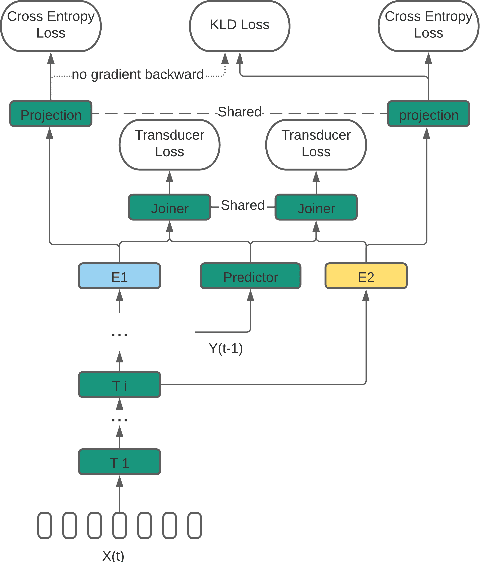
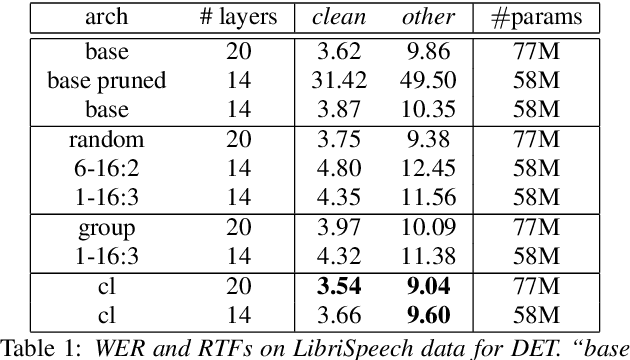
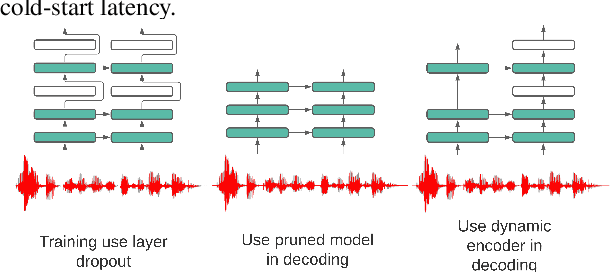
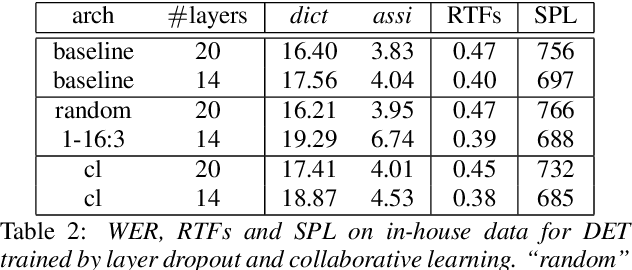
We propose a dynamic encoder transducer (DET) for on-device speech recognition. One DET model scales to multiple devices with different computation capacities without retraining or finetuning. To trading off accuracy and latency, DET assigns different encoders to decode different parts of an utterance. We apply and compare the layer dropout and the collaborative learning for DET training. The layer dropout method that randomly drops out encoder layers in the training phase, can do on-demand layer dropout in decoding. Collaborative learning jointly trains multiple encoders with different depths in one single model. Experiment results on Librispeech and in-house data show that DET provides a flexible accuracy and latency trade-off. Results on Librispeech show that the full-size encoder in DET relatively reduces the word error rate of the same size baseline by over 8%. The lightweight encoder in DET trained with collaborative learning reduces the model size by 25% but still gets similar WER as the full-size baseline. DET gets similar accuracy as a baseline model with better latency on a large in-house data set by assigning a lightweight encoder for the beginning part of one utterance and a full-size encoder for the rest.
Semantic Distance: A New Metric for ASR Performance Analysis Towards Spoken Language Understanding
Apr 05, 2021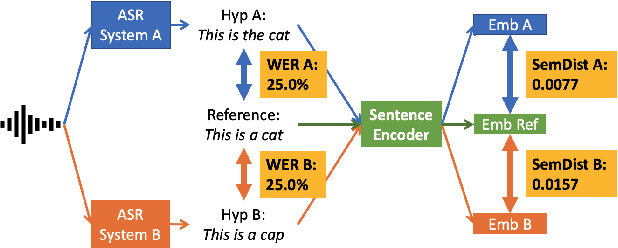

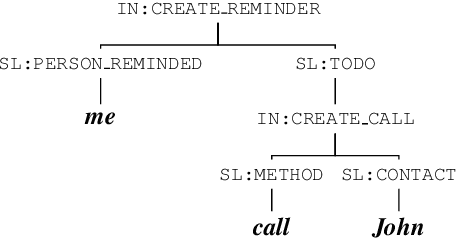

Word Error Rate (WER) has been the predominant metric used to evaluate the performance of automatic speech recognition (ASR) systems. However, WER is sometimes not a good indicator for downstream Natural Language Understanding (NLU) tasks, such as intent recognition, slot filling, and semantic parsing in task-oriented dialog systems. This is because WER takes into consideration only literal correctness instead of semantic correctness, the latter of which is typically more important for these downstream tasks. In this study, we propose a novel Semantic Distance (SemDist) measure as an alternative evaluation metric for ASR systems to address this issue. We define SemDist as the distance between a reference and hypothesis pair in a sentence-level embedding space. To represent the reference and hypothesis as a sentence embedding, we exploit RoBERTa, a state-of-the-art pre-trained deep contextualized language model based on the transformer architecture. We demonstrate the effectiveness of our proposed metric on various downstream tasks, including intent recognition, semantic parsing, and named entity recognition.
Contrastive Semi-supervised Learning for ASR
Mar 09, 2021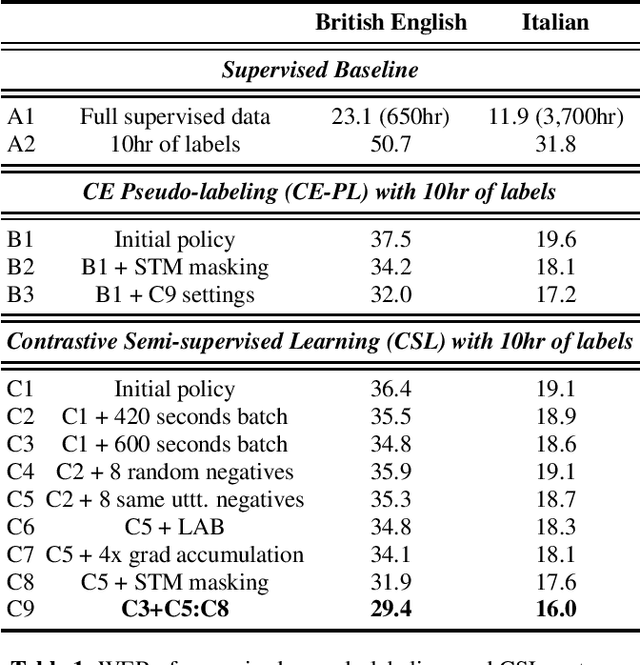
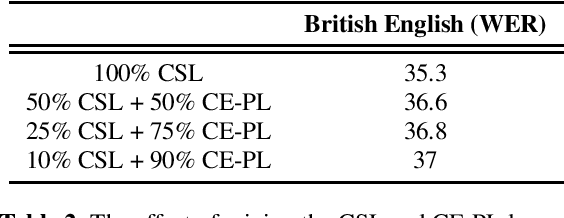
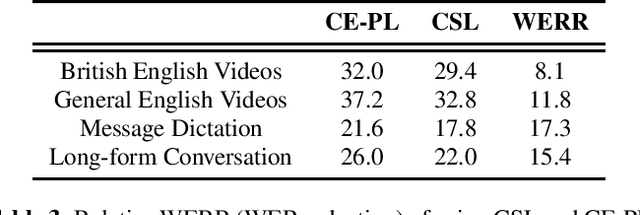
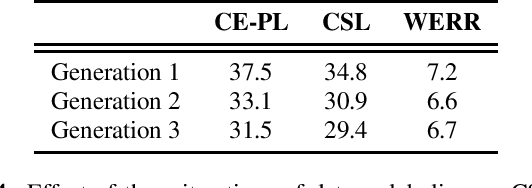
Pseudo-labeling is the most adopted method for pre-training automatic speech recognition (ASR) models. However, its performance suffers from the supervised teacher model's degrading quality in low-resource setups and under domain transfer. Inspired by the successes of contrastive representation learning for computer vision and speech applications, and more recently for supervised learning of visual objects, we propose Contrastive Semi-supervised Learning (CSL). CSL eschews directly predicting teacher-generated pseudo-labels in favor of utilizing them to select positive and negative examples. In the challenging task of transcribing public social media videos, using CSL reduces the WER by 8% compared to the standard Cross-Entropy pseudo-labeling (CE-PL) when 10hr of supervised data is used to annotate 75,000hr of videos. The WER reduction jumps to 19% under the ultra low-resource condition of using 1hr labels for teacher supervision. CSL generalizes much better in out-of-domain conditions, showing up to 17% WER reduction compared to the best CE-PL pre-trained model.
Memory-efficient Speech Recognition on Smart Devices
Feb 23, 2021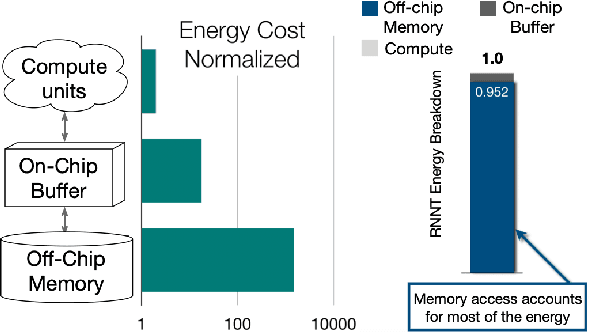
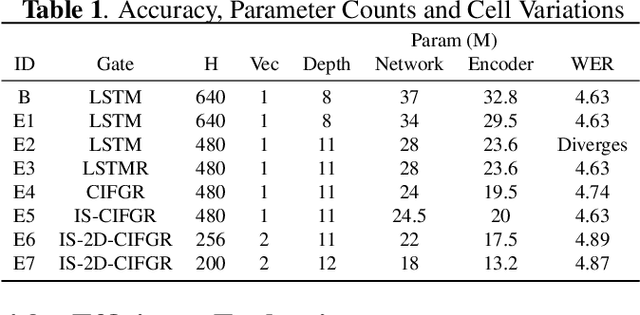
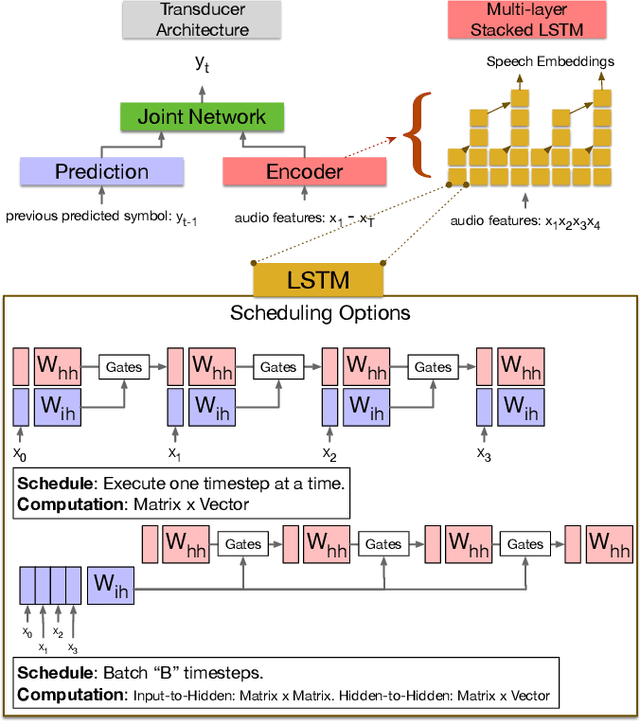
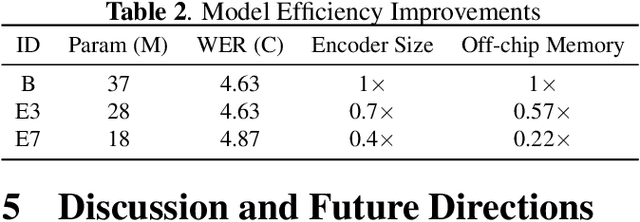
Recurrent transducer models have emerged as a promising solution for speech recognition on the current and next generation smart devices. The transducer models provide competitive accuracy within a reasonable memory footprint alleviating the memory capacity constraints in these devices. However, these models access parameters from off-chip memory for every input time step which adversely effects device battery life and limits their usability on low-power devices. We address transducer model's memory access concerns by optimizing their model architecture and designing novel recurrent cell designs. We demonstrate that i) model's energy cost is dominated by accessing model weights from off-chip memory, ii) transducer model architecture is pivotal in determining the number of accesses to off-chip memory and just model size is not a good proxy, iii) our transducer model optimizations and novel recurrent cell reduces off-chip memory accesses by 4.5x and model size by 2x with minimal accuracy impact.
Deep Shallow Fusion for RNN-T Personalization
Nov 16, 2020
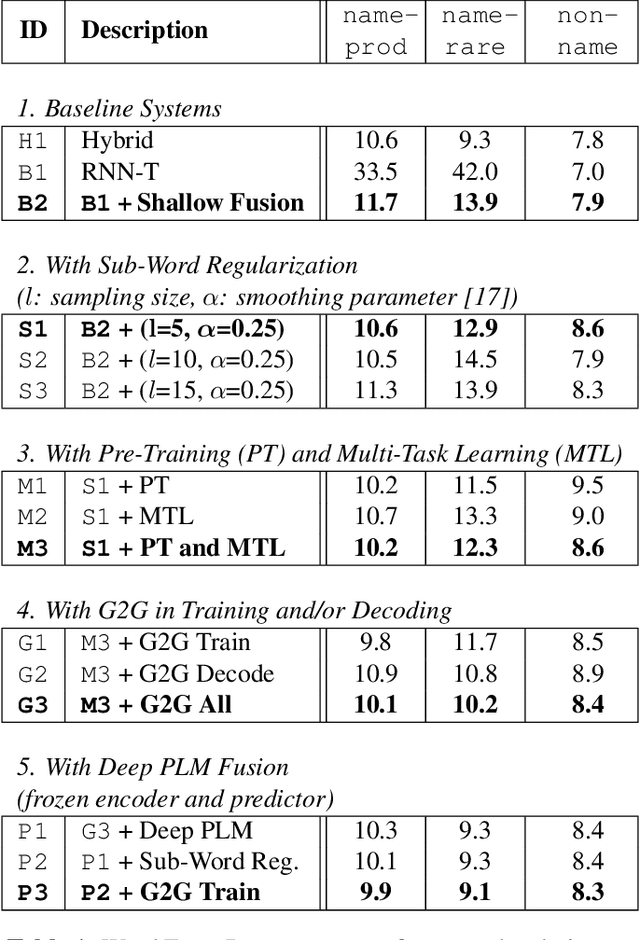
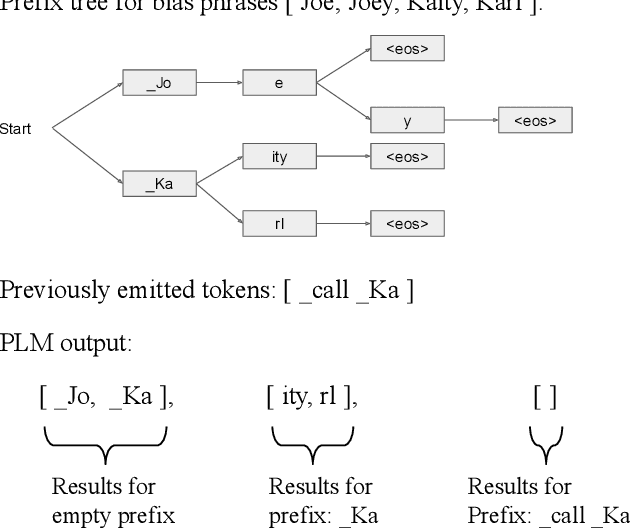
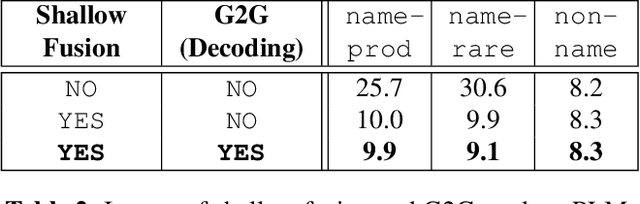
End-to-end models in general, and Recurrent Neural Network Transducer (RNN-T) in particular, have gained significant traction in the automatic speech recognition community in the last few years due to their simplicity, compactness, and excellent performance on generic transcription tasks. However, these models are more challenging to personalize compared to traditional hybrid systems due to the lack of external language models and difficulties in recognizing rare long-tail words, specifically entity names. In this work, we present novel techniques to improve RNN-T's ability to model rare WordPieces, infuse extra information into the encoder, enable the use of alternative graphemic pronunciations, and perform deep fusion with personalized language models for more robust biasing. We show that these combined techniques result in 15.4%-34.5% relative Word Error Rate improvement compared to a strong RNN-T baseline which uses shallow fusion and text-to-speech augmentation. Our work helps push the boundary of RNN-T personalization and close the gap with hybrid systems on use cases where biasing and entity recognition are crucial.
Alignment Restricted Streaming Recurrent Neural Network Transducer
Nov 05, 2020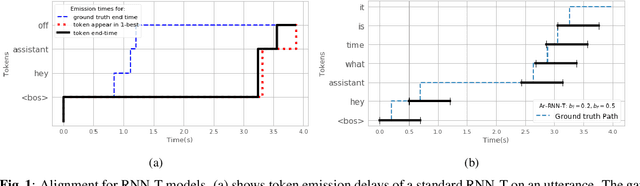
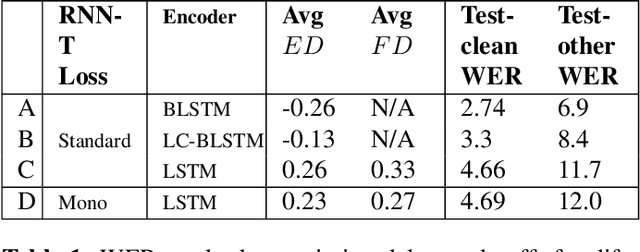
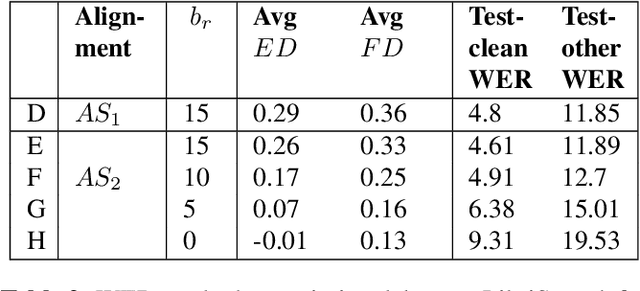
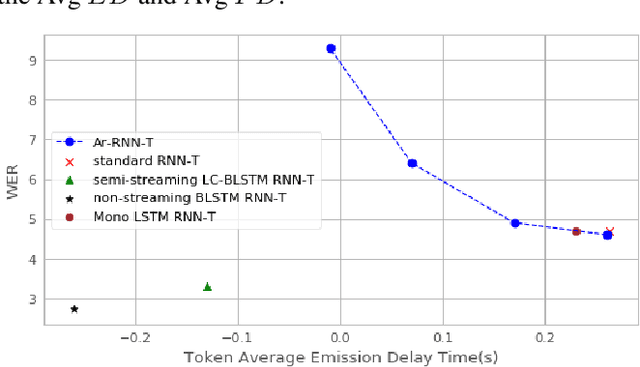
There is a growing interest in the speech community in developing Recurrent Neural Network Transducer (RNN-T) models for automatic speech recognition (ASR) applications. RNN-T is trained with a loss function that does not enforce temporal alignment of the training transcripts and audio. As a result, RNN-T models built with uni-directional long short term memory (LSTM) encoders tend to wait for longer spans of input audio, before streaming already decoded ASR tokens. In this work, we propose a modification to the RNN-T loss function and develop Alignment Restricted RNN-T (Ar-RNN-T) models, which utilize audio-text alignment information to guide the loss computation. We compare the proposed method with existing works, such as monotonic RNN-T, on LibriSpeech and in-house datasets. We show that the Ar-RNN-T loss provides a refined control to navigate the trade-offs between the token emission delays and the Word Error Rate (WER). The Ar-RNN-T models also improve downstream applications such as the ASR End-pointing by guaranteeing token emissions within any given range of latency. Moreover, the Ar-RNN-T loss allows for bigger batch sizes and 4 times higher throughput for our LSTM model architecture, enabling faster training and convergence on GPUs.
Improved Neural Language Model Fusion for Streaming Recurrent Neural Network Transducer
Oct 26, 2020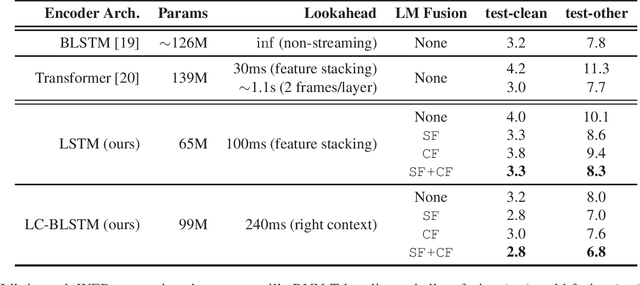
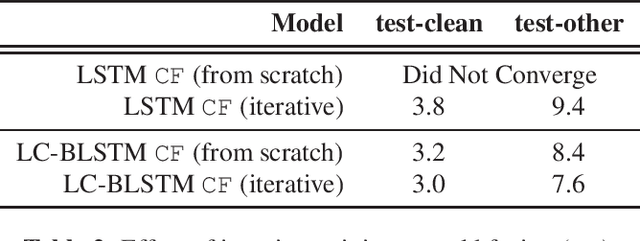
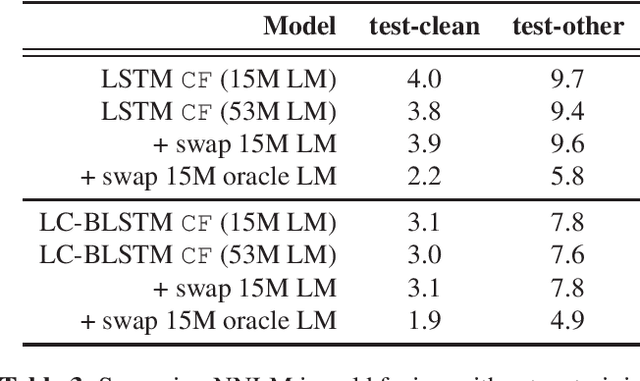
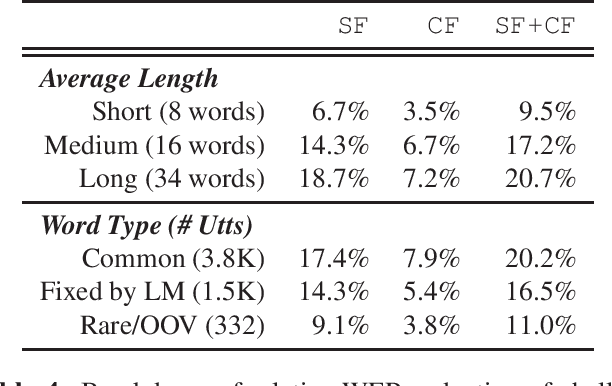
Recurrent Neural Network Transducer (RNN-T), like most end-to-end speech recognition model architectures, has an implicit neural network language model (NNLM) and cannot easily leverage unpaired text data during training. Previous work has proposed various fusion methods to incorporate external NNLMs into end-to-end ASR to address this weakness. In this paper, we propose extensions to these techniques that allow RNN-T to exploit external NNLMs during both training and inference time, resulting in 13-18% relative Word Error Rate improvement on Librispeech compared to strong baselines. Furthermore, our methods do not incur extra algorithmic latency and allow for flexible plug-and-play of different NNLMs without re-training. We also share in-depth analysis to better understand the benefits of the different NNLM fusion methods. Our work provides a reliable technique for leveraging unpaired text data to significantly improve RNN-T while keeping the system streamable, flexible, and lightweight.
Weak-Attention Suppression For Transformer Based Speech Recognition
May 18, 2020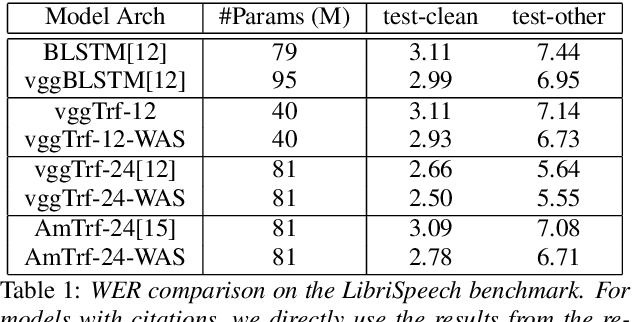
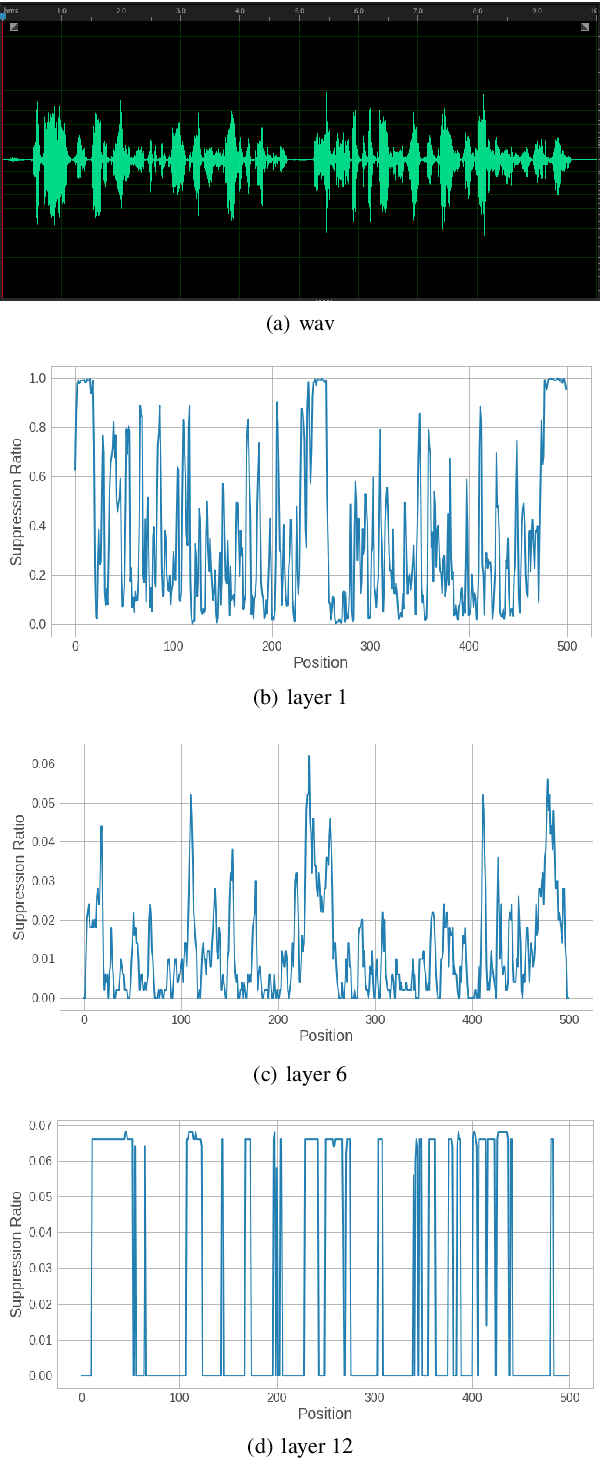
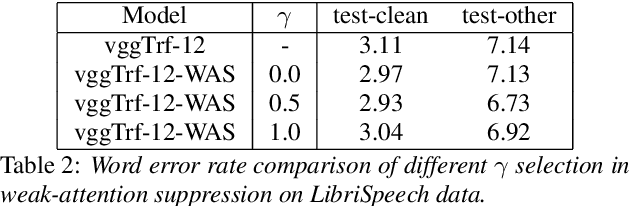
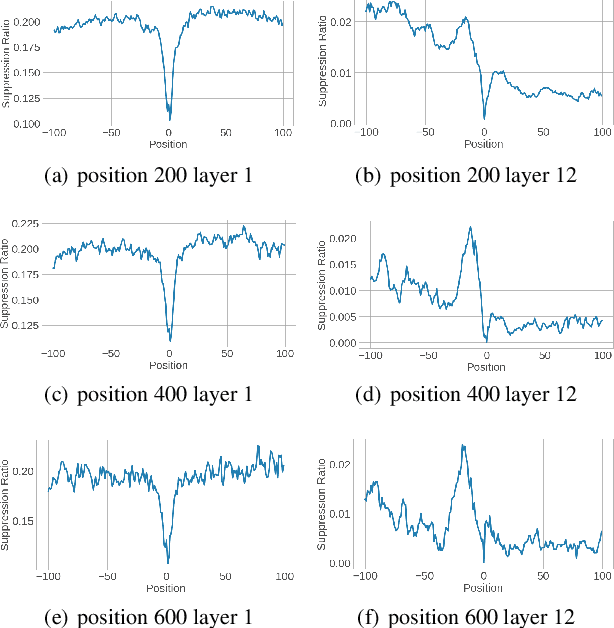
Transformers, originally proposed for natural language processing (NLP) tasks, have recently achieved great success in automatic speech recognition (ASR). However, adjacent acoustic units (i.e., frames) are highly correlated, and long-distance dependencies between them are weak, unlike text units. It suggests that ASR will likely benefit from sparse and localized attention. In this paper, we propose Weak-Attention Suppression (WAS), a method that dynamically induces sparsity in attention probabilities. We demonstrate that WAS leads to consistent Word Error Rate (WER) improvement over strong transformer baselines. On the widely used LibriSpeech benchmark, our proposed method reduced WER by 10%$ on test-clean and 5% on test-other for streamable transformers, resulting in a new state-of-the-art among streaming models. Further analysis shows that WAS learns to suppress attention of non-critical and redundant continuous acoustic frames, and is more likely to suppress past frames rather than future ones. It indicates the importance of lookahead in attention-based ASR models.
Large scale weakly and semi-supervised learning for low-resource video ASR
May 16, 2020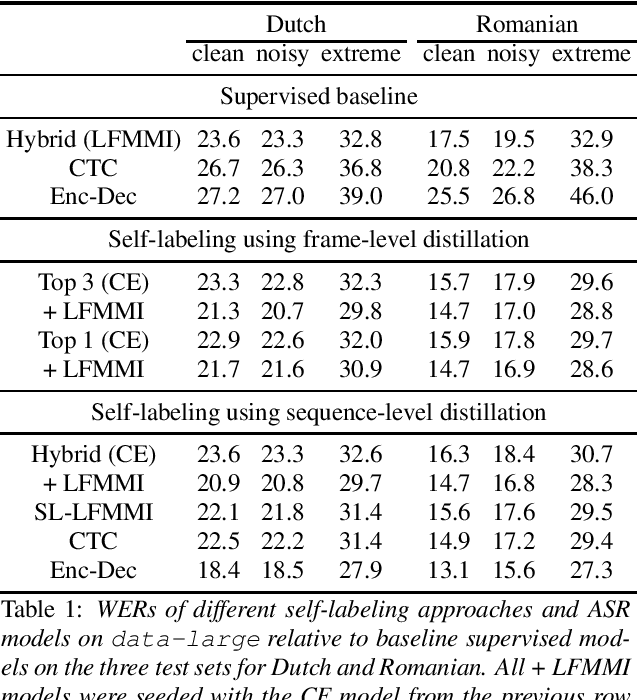
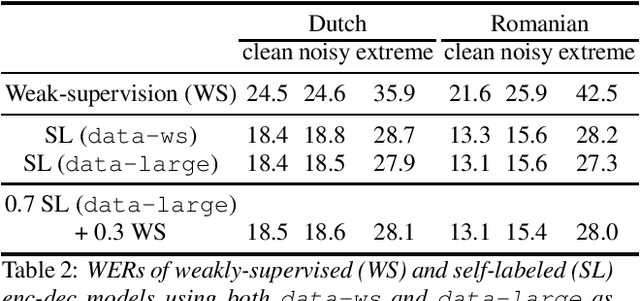
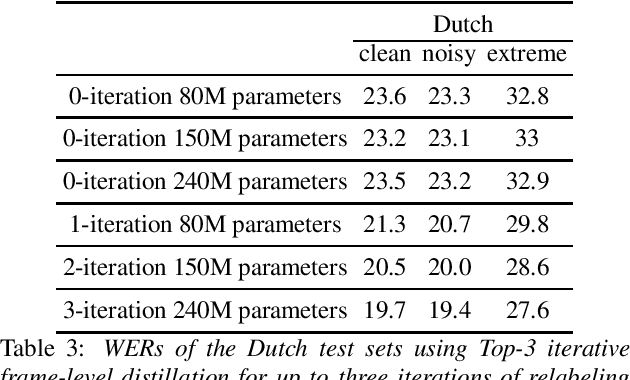
Many semi- and weakly-supervised approaches have been investigated for overcoming the labeling cost of building high quality speech recognition systems. On the challenging task of transcribing social media videos in low-resource conditions, we conduct a large scale systematic comparison between two self-labeling methods on one hand, and weakly-supervised pretraining using contextual metadata on the other. We investigate distillation methods at the frame level and the sequence level for hybrid, encoder-only CTC-based, and encoder-decoder speech recognition systems on Dutch and Romanian languages using 27,000 and 58,000 hours of unlabeled audio respectively. Although all approaches improved upon their respective baseline WERs by more than 8%, sequence-level distillation for encoder-decoder models provided the largest relative WER reduction of 20% compared to the strongest data-augmented supervised baseline.
Libri-Light: A Benchmark for ASR with Limited or No Supervision
Dec 17, 2019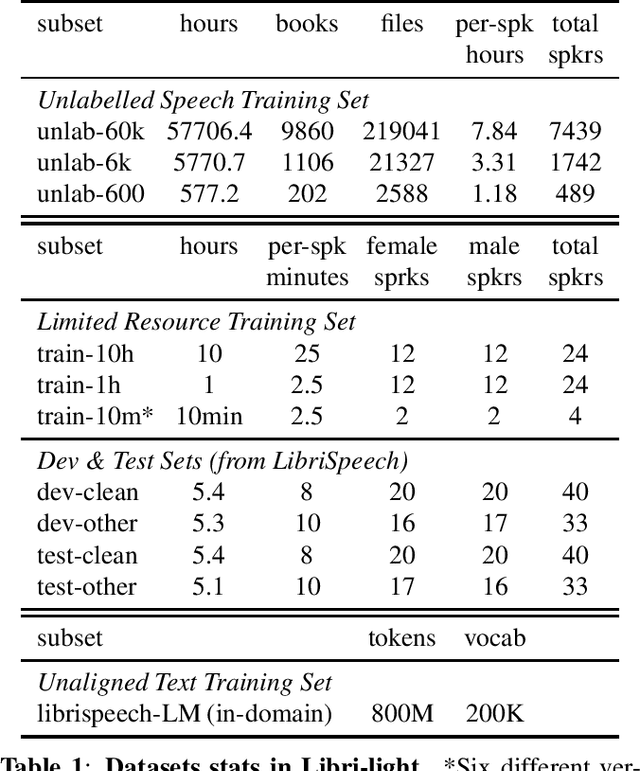
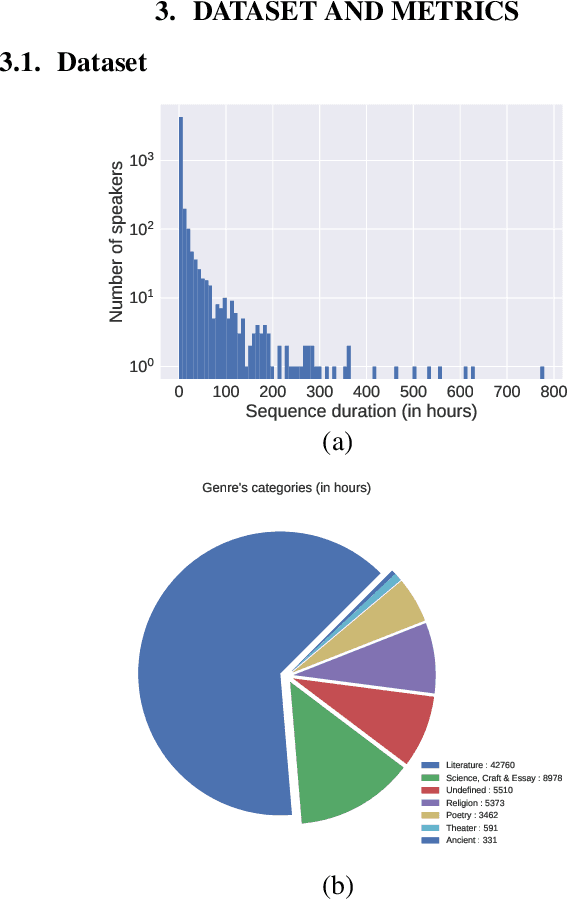
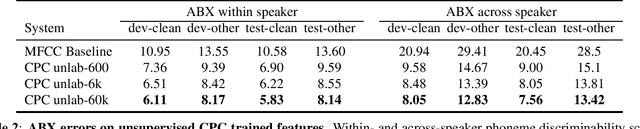
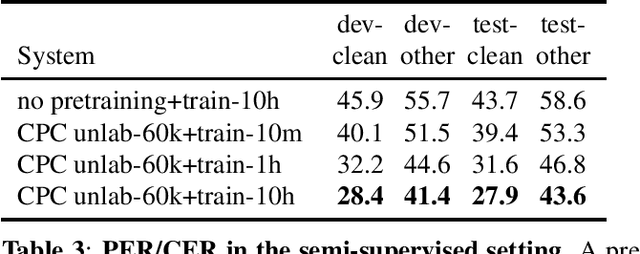
We introduce a new collection of spoken English audio suitable for training speech recognition systems under limited or no supervision. It is derived from open-source audio books from the LibriVox project. It contains over 60K hours of audio, which is, to our knowledge, the largest freely-available corpus of speech. The audio has been segmented using voice activity detection and is tagged with SNR, speaker ID and genre descriptions. Additionally, we provide baseline systems and evaluation metrics working under three settings: (1) the zero resource/unsupervised setting (ABX), (2) the semi-supervised setting (PER, CER) and (3) the distant supervision setting (WER). Settings (2) and (3) use limited textual resources (10 minutes to 10 hours) aligned with the speech. Setting (3) uses large amounts of unaligned text. They are evaluated on the standard LibriSpeech dev and test sets for comparison with the supervised state-of-the-art.