 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to EdgeNovel View Synthesis of Humans using Differentiable Rendering
Mar 28, 2023We present a new approach for synthesizing novel views of people in new poses. Our novel differentiable renderer enables the synthesis of highly realistic images from any viewpoint. Rather than operating over mesh-based structures, our renderer makes use of diffuse Gaussian primitives that directly represent the underlying skeletal structure of a human. Rendering these primitives gives results in a high-dimensional latent image, which is then transformed into an RGB image by a decoder network. The formulation gives rise to a fully differentiable framework that can be trained end-to-end. We demonstrate the effectiveness of our approach to image reconstruction on both the Human3.6M and Panoptic Studio datasets. We show how our approach can be used for motion transfer between individuals; novel view synthesis of individuals captured from just a single camera; to synthesize individuals from any virtual viewpoint; and to re-render people in novel poses. Code and video results are available at https://github.com/GuillaumeRochette/HumanViewSynthesis.
Efficient fair PCA for fair representation learning
Feb 26, 2023We revisit the problem of fair principal component analysis (PCA), where the goal is to learn the best low-rank linear approximation of the data that obfuscates demographic information. We propose a conceptually simple approach that allows for an analytic solution similar to standard PCA and can be kernelized. Our methods have the same complexity as standard PCA, or kernel PCA, and run much faster than existing methods for fair PCA based on semidefinite programming or manifold optimization, while achieving similar results.
The Unfairness of Fair Machine Learning: Levelling down and strict egalitarianism by default
Feb 20, 2023In recent years fairness in machine learning (ML) has emerged as a highly active area of research and development. Most define fairness in simple terms, where fairness means reducing gaps in performance or outcomes between demographic groups while preserving as much of the accuracy of the original system as possible. This oversimplification of equality through fairness measures is troubling. Many current fairness measures suffer from both fairness and performance degradation, or "levelling down," where fairness is achieved by making every group worse off, or by bringing better performing groups down to the level of the worst off. When fairness can only be achieved by making everyone worse off in material or relational terms through injuries of stigma, loss of solidarity, unequal concern, and missed opportunities for substantive equality, something would appear to have gone wrong in translating the vague concept of 'fairness' into practice. This paper examines the causes and prevalence of levelling down across fairML, and explore possible justifications and criticisms based on philosophical and legal theories of equality and distributive justice, as well as equality law jurisprudence. We find that fairML does not currently engage in the type of measurement, reporting, or analysis necessary to justify levelling down in practice. We propose a first step towards substantive equality in fairML: "levelling up" systems by design through enforcement of minimum acceptable harm thresholds, or "minimum rate constraints," as fairness constraints. We likewise propose an alternative harms-based framework to counter the oversimplified egalitarian framing currently dominant in the field and push future discussion more towards substantive equality opportunities and away from strict egalitarianism by default. N.B. Shortened abstract, see paper for full abstract.
Causal Triplet: An Open Challenge for Intervention-centric Causal Representation Learning
Jan 12, 2023



Recent years have seen a surge of interest in learning high-level causal representations from low-level image pairs under interventions. Yet, existing efforts are largely limited to simple synthetic settings that are far away from real-world problems. In this paper, we present Causal Triplet, a causal representation learning benchmark featuring not only visually more complex scenes, but also two crucial desiderata commonly overlooked in previous works: (i) an actionable counterfactual setting, where only certain object-level variables allow for counterfactual observations whereas others do not; (ii) an interventional downstream task with an emphasis on out-of-distribution robustness from the independent causal mechanisms principle. Through extensive experiments, we find that models built with the knowledge of disentangled or object-centric representations significantly outperform their distributed counterparts. However, recent causal representation learning methods still struggle to identify such latent structures, indicating substantial challenges and opportunities for future work. Our code and datasets will be available at https://sites.google.com/view/causaltriplet.
The Monocular Depth Estimation Challenge
Nov 22, 2022



This paper summarizes the results of the first Monocular Depth Estimation Challenge (MDEC) organized at WACV2023. This challenge evaluated the progress of self-supervised monocular depth estimation on the challenging SYNS-Patches dataset. The challenge was organized on CodaLab and received submissions from 4 valid teams. Participants were provided a devkit containing updated reference implementations for 16 State-of-the-Art algorithms and 4 novel techniques. The threshold for acceptance for novel techniques was to outperform every one of the 16 SotA baselines. All participants outperformed the baseline in traditional metrics such as MAE or AbsRel. However, pointcloud reconstruction metrics were challenging to improve upon. We found predictions were characterized by interpolation artefacts at object boundaries and errors in relative object positioning. We hope this challenge is a valuable contribution to the community and encourage authors to participate in future editions.
Deconstructing Self-Supervised Monocular Reconstruction: The Design Decisions that Matter
Aug 02, 2022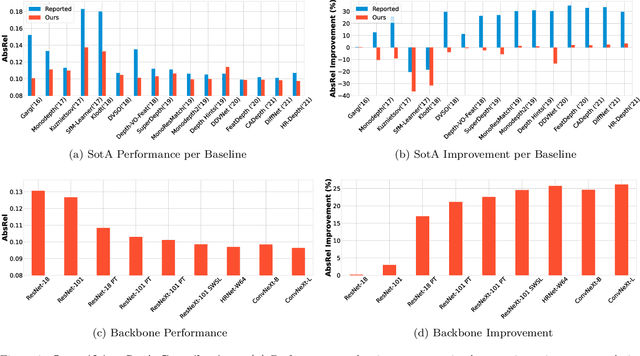


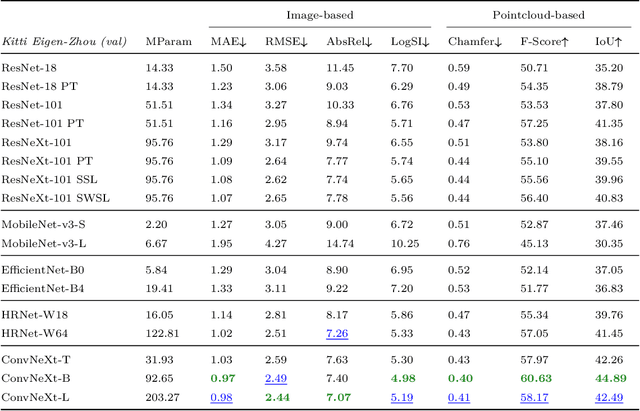
This paper presents an open and comprehensive framework to systematically evaluate state-of-the-art contributions to self-supervised monocular depth estimation. This includes pretraining, backbone, architectural design choices and loss functions. Many papers in this field claim novelty in either architecture design or loss formulation. However, simply updating the backbone of historical systems results in relative improvements of 25%, allowing them to outperform the majority of existing systems. A systematic evaluation of papers in this field was not straightforward. The need to compare like-with-like in previous papers means that longstanding errors in the evaluation protocol are ubiquitous in the field. It is likely that many papers were not only optimized for particular datasets, but also for errors in the data and evaluation criteria. To aid future research in this area, we release a modular codebase, allowing for easy evaluation of alternate design decisions against corrected data and evaluation criteria. We re-implement, validate and re-evaluate 16 state-of-the-art contributions and introduce a new dataset (SYNS-Patches) containing dense outdoor depth maps in a variety of both natural and urban scenes. This allows for the computation of informative metrics in complex regions such as depth boundaries.
Assaying Out-Of-Distribution Generalization in Transfer Learning
Jul 19, 2022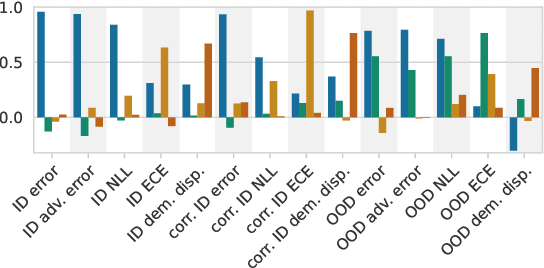
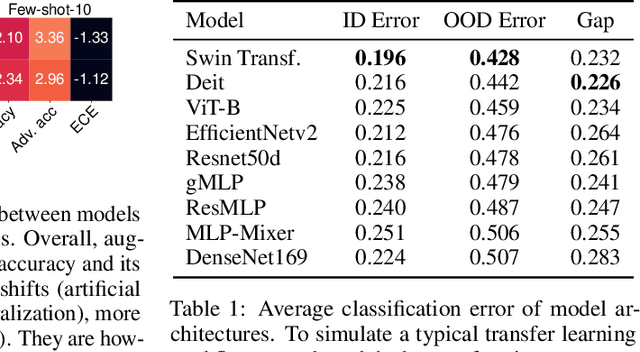
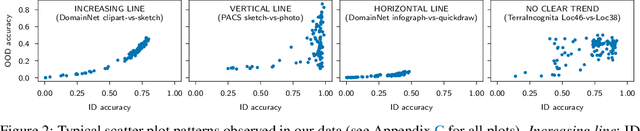
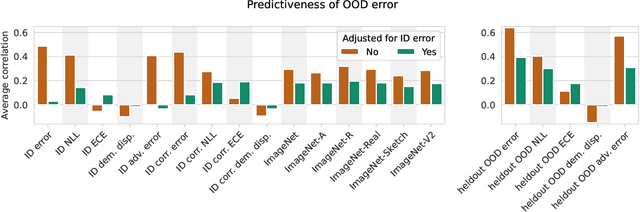
Since out-of-distribution generalization is a generally ill-posed problem, various proxy targets (e.g., calibration, adversarial robustness, algorithmic corruptions, invariance across shifts) were studied across different research programs resulting in different recommendations. While sharing the same aspirational goal, these approaches have never been tested under the same experimental conditions on real data. In this paper, we take a unified view of previous work, highlighting message discrepancies that we address empirically, and providing recommendations on how to measure the robustness of a model and how to improve it. To this end, we collect 172 publicly available dataset pairs for training and out-of-distribution evaluation of accuracy, calibration error, adversarial attacks, environment invariance, and synthetic corruptions. We fine-tune over 31k networks, from nine different architectures in the many- and few-shot setting. Our findings confirm that in- and out-of-distribution accuracies tend to increase jointly, but show that their relation is largely dataset-dependent, and in general more nuanced and more complex than posited by previous, smaller scale studies.
Pixel-level Correspondence for Self-Supervised Learning from Video
Jul 08, 2022
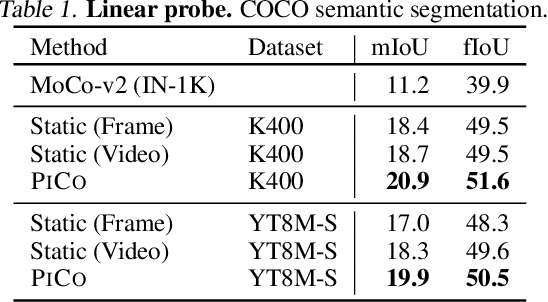


While self-supervised learning has enabled effective representation learning in the absence of labels, for vision, video remains a relatively untapped source of supervision. To address this, we propose Pixel-level Correspondence (PiCo), a method for dense contrastive learning from video. By tracking points with optical flow, we obtain a correspondence map which can be used to match local features at different points in time. We validate PiCo on standard benchmarks, outperforming self-supervised baselines on multiple dense prediction tasks, without compromising performance on image classification.
Are Two Heads the Same as One? Identifying Disparate Treatment in Fair Neural Networks
Apr 09, 2022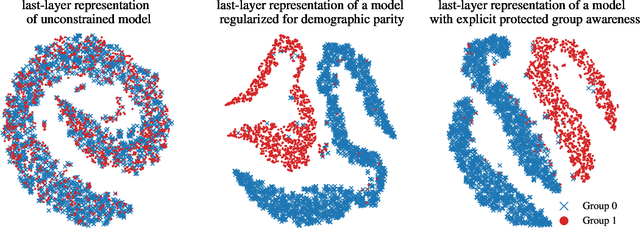
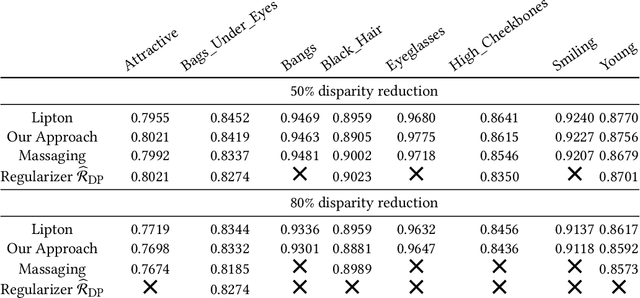
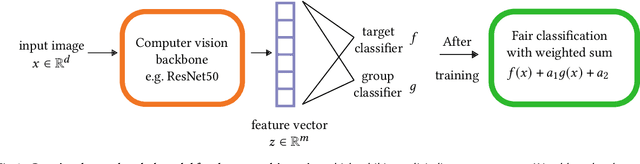
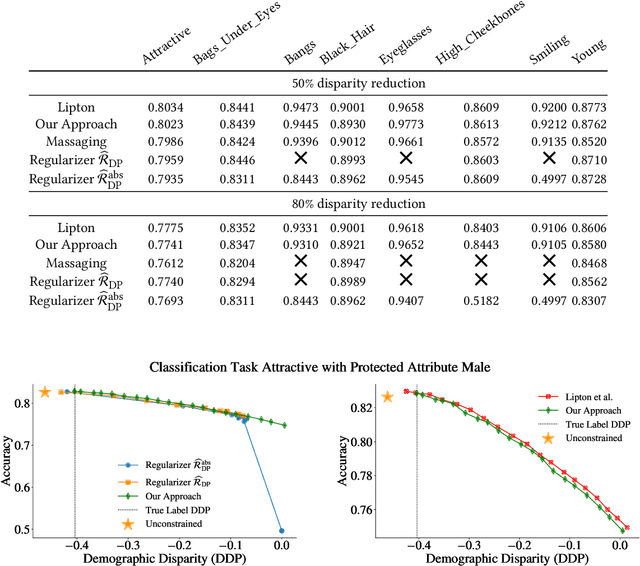
We show that deep neural networks that satisfy demographic parity do so through a form of race or gender awareness, and that the more we force a network to be fair, the more accurately we can recover race or gender from the internal state of the network. Based on this observation, we propose a simple two-stage solution for enforcing fairness. First, we train a two-headed network to predict the protected attribute (such as race or gender) alongside the original task, and second, we enforce demographic parity by taking a weighted sum of the heads. In the end, this approach creates a single-headed network with the same backbone architecture as the original network. Our approach has near identical performance compared to existing regularization-based or preprocessing methods, but has greater stability and higher accuracy where near exact demographic parity is required. To cement the relationship between these two approaches, we show that an unfair and optimally accurate classifier can be recovered by taking a weighted sum of a fair classifier and a classifier predicting the protected attribute. We use this to argue that both the fairness approaches and our explicit formulation demonstrate disparate treatment and that, consequentially, they are likely to be unlawful in a wide range of scenarios under the US law.
"The Pedestrian next to the Lamppost" Adaptive Object Graphs for Better Instantaneous Mapping
Apr 06, 2022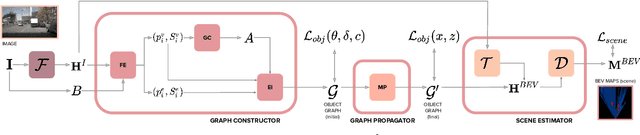


Estimating a semantically segmented bird's-eye-view (BEV) map from a single image has become a popular technique for autonomous control and navigation. However, they show an increase in localization error with distance from the camera. While such an increase in error is entirely expected - localization is harder at distance - much of the drop in performance can be attributed to the cues used by current texture-based models, in particular, they make heavy use of object-ground intersections (such as shadows), which become increasingly sparse and uncertain for distant objects. In this work, we address these shortcomings in BEV-mapping by learning the spatial relationship between objects in a scene. We propose a graph neural network which predicts BEV objects from a monocular image by spatially reasoning about an object within the context of other objects. Our approach sets a new state-of-the-art in BEV estimation from monocular images across three large-scale datasets, including a 50% relative improvement for objects on nuScenes.