 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to EdgeSpatiotemporally Discriminative Video-Language Pre-Training with Text Grounding
Mar 28, 2023



Most of existing video-language pre-training methods focus on instance-level alignment between video clips and captions via global contrastive learning but neglect rich fine-grained local information, which is of importance to downstream tasks requiring temporal localization and semantic reasoning. In this work, we propose a simple yet effective video-language pre-training framework, namely G-ViLM, to learn discriminative spatiotemporal features. Two novel designs involving spatiotemporal grounding and temporal grouping promote learning local region-noun alignment and temporal-aware features simultaneously. Specifically, spatiotemporal grounding aggregates semantically similar video tokens and aligns them with noun phrases extracted from the caption to promote local region-noun correspondences. Moreover, temporal grouping leverages cut-and-paste to manually create temporal scene changes and then learns distinguishable features from different scenes. Comprehensive evaluations demonstrate that G-ViLM performs favorably against existing approaches on four representative downstream tasks, covering text-video retrieval, video question answering, video action recognition and temporal action localization. G-ViLM performs competitively on all evaluated tasks and in particular achieves R@10 of 65.1 on zero-shot MSR-VTT retrieval, over 9% higher than the state-of-the-art method.
Online Continuous Hyperparameter Optimization for Contextual Bandits
Feb 18, 2023



In stochastic contextual bandit problems, an agent sequentially makes actions from a time-dependent action set based on past experience to minimize the cumulative regret. Like many other machine learning algorithms, the performance of bandits heavily depends on their multiple hyperparameters, and theoretically derived parameter values may lead to unsatisfactory results in practice. Moreover, it is infeasible to use offline tuning methods like cross validation to choose hyperparameters under the bandit environment, as the decisions should be made in real time. To address this challenge, we propose the first online continuous hyperparameter tuning framework for contextual bandits to learn the optimal parameter configuration within a search space on the fly. Specifically, we use a double-layer bandit framework named CDT (Continuous Dynamic Tuning) and formulate the hyperparameter optimization as a non-stationary continuum-armed bandit, where each arm represents a combination of hyperparameters, and the corresponding reward is the algorithmic result. For the top layer, we propose the Zooming TS algorithm that utilizes Thompson Sampling (TS) for exploration and a restart technique to get around the switching environment. The proposed CDT framework can be easily used to tune contextual bandit algorithms without any pre-specified candidate set for hyperparameters. We further show that it could achieve sublinear regret in theory and performs consistently better on both synthetic and real datasets in practice.
Symbolic Discovery of Optimization Algorithms
Feb 17, 2023



We present a method to formulate algorithm discovery as program search, and apply it to discover optimization algorithms for deep neural network training. We leverage efficient search techniques to explore an infinite and sparse program space. To bridge the large generalization gap between proxy and target tasks, we also introduce program selection and simplification strategies. Our method discovers a simple and effective optimization algorithm, $\textbf{Lion}$ ($\textit{Evo$\textbf{L}$ved S$\textbf{i}$gn M$\textbf{o}$me$\textbf{n}$tum}$). It is more memory-efficient than Adam as it only keeps track of the momentum. Different from adaptive optimizers, its update has the same magnitude for each parameter calculated through the sign operation. We compare Lion with widely used optimizers, such as Adam and Adafactor, for training a variety of models on different tasks. On image classification, Lion boosts the accuracy of ViT by up to 2% on ImageNet and saves up to 5x the pre-training compute on JFT. On vision-language contrastive learning, we achieve 88.3% $\textit{zero-shot}$ and 91.1% $\textit{fine-tuning}$ accuracy on ImageNet, surpassing the previous best results by 2% and 0.1%, respectively. On diffusion models, Lion outperforms Adam by achieving a better FID score and reducing the training compute by up to 2.3x. For autoregressive, masked language modeling, and fine-tuning, Lion exhibits a similar or better performance compared to Adam. Our analysis of Lion reveals that its performance gain grows with the training batch size. It also requires a smaller learning rate than Adam due to the larger norm of the update produced by the sign function. Additionally, we examine the limitations of Lion and identify scenarios where its improvements are small or not statistically significant. The implementation of Lion is publicly available.
Effective Robustness against Natural Distribution Shifts for Models with Different Training Data
Feb 02, 2023



``Effective robustness'' measures the extra out-of-distribution (OOD) robustness beyond what can be predicted from the in-distribution (ID) performance. Existing effective robustness evaluations typically use a single test set such as ImageNet to evaluate ID accuracy. This becomes problematic when evaluating models trained on different data distributions, e.g., comparing models trained on ImageNet vs. zero-shot language-image pre-trained models trained on LAION. In this paper, we propose a new effective robustness evaluation metric to compare the effective robustness of models trained on different data distributions. To do this we control for the accuracy on multiple ID test sets that cover the training distributions for all the evaluated models. Our new evaluation metric provides a better estimate of the effectiveness robustness and explains the surprising effective robustness gains of zero-shot CLIP-like models exhibited when considering only one ID dataset, while the gains diminish under our evaluation.
Scaling Up Dataset Distillation to ImageNet-1K with Constant Memory
Nov 19, 2022Dataset distillation methods aim to compress a large dataset into a small set of synthetic samples, such that when being trained on, competitive performances can be achieved compared to regular training on the entire dataset. Among recently proposed methods, Matching Training Trajectories (MTT) achieves state-of-the-art performance on CIFAR-10/100, while having difficulty scaling to ImageNet-1k dataset due to the large memory requirement when performing unrolled gradient computation through back-propagation. Surprisingly, we show that there exists a procedure to exactly calculate the gradient of the trajectory matching loss with constant GPU memory requirement (irrelevant to the number of unrolled steps). With this finding, the proposed memory-efficient trajectory matching method can easily scale to ImageNet-1K with 6x memory reduction while introducing only around 2% runtime overhead than original MTT. Further, we find that assigning soft labels for synthetic images is crucial for the performance when scaling to larger number of categories (e.g., 1,000) and propose a novel soft label version of trajectory matching that facilities better aligning of model training trajectories on large datasets. The proposed algorithm not only surpasses previous SOTA on ImageNet-1K under extremely low IPCs (Images Per Class), but also for the first time enables us to scale up to 50 IPCs on ImageNet-1K. Our method (TESLA) achieves 27.9% testing accuracy, a remarkable +18.2% margin over prior arts.
Are AlphaZero-like Agents Robust to Adversarial Perturbations?
Nov 07, 2022



The success of AlphaZero (AZ) has demonstrated that neural-network-based Go AIs can surpass human performance by a large margin. Given that the state space of Go is extremely large and a human player can play the game from any legal state, we ask whether adversarial states exist for Go AIs that may lead them to play surprisingly wrong actions. In this paper, we first extend the concept of adversarial examples to the game of Go: we generate perturbed states that are ``semantically'' equivalent to the original state by adding meaningless moves to the game, and an adversarial state is a perturbed state leading to an undoubtedly inferior action that is obvious even for Go beginners. However, searching the adversarial state is challenging due to the large, discrete, and non-differentiable search space. To tackle this challenge, we develop the first adversarial attack on Go AIs that can efficiently search for adversarial states by strategically reducing the search space. This method can also be extended to other board games such as NoGo. Experimentally, we show that the actions taken by both Policy-Value neural network (PV-NN) and Monte Carlo tree search (MCTS) can be misled by adding one or two meaningless stones; for example, on 58\% of the AlphaGo Zero self-play games, our method can make the widely used KataGo agent with 50 simulations of MCTS plays a losing action by adding two meaningless stones. We additionally evaluated the adversarial examples found by our algorithm with amateur human Go players and 90\% of examples indeed lead the Go agent to play an obviously inferior action. Our code is available at \url{https://PaperCode.cc/GoAttack}.
Improving Adversarial Robustness to Sensitivity and Invariance Attacks with Deep Metric Learning
Nov 04, 2022Intentionally crafted adversarial samples have effectively exploited weaknesses in deep neural networks. A standard method in adversarial robustness assumes a framework to defend against samples crafted by minimally perturbing a sample such that its corresponding model output changes. These sensitivity attacks exploit the model's sensitivity toward task-irrelevant features. Another form of adversarial sample can be crafted via invariance attacks, which exploit the model underestimating the importance of relevant features. Previous literature has indicated a tradeoff in defending against both attack types within a strictly L_p bounded defense. To promote robustness toward both types of attacks beyond Euclidean distance metrics, we use metric learning to frame adversarial regularization as an optimal transport problem. Our preliminary results indicate that regularizing over invariant perturbations in our framework improves both invariant and sensitivity defense.
Preserving In-Context Learning ability in Large Language Model Fine-tuning
Nov 01, 2022Pretrained large language models (LLMs) are strong in-context learners that are able to perform few-shot learning without changing model parameters. However, as we show, fine-tuning an LLM on any specific task generally destroys its in-context ability. We discover an important cause of this loss, format specialization, where the model overfits to the format of the fine-tuned task and is unable to output anything beyond this format. We further show that format specialization happens at the beginning of fine-tuning. To solve this problem, we propose Prompt Tuning with MOdel Tuning (ProMoT), a simple yet effective two-stage fine-tuning framework that preserves in-context abilities of the pretrained model. ProMoT first trains a soft prompt for the fine-tuning target task, and then fine-tunes the model itself with this soft prompt attached. ProMoT offloads task-specific formats into the soft prompt that can be removed when doing other in-context tasks. We fine-tune mT5 XXL with ProMoT on natural language inference (NLI) and English-French translation and evaluate the in-context abilities of the resulting models on 8 different NLP tasks. ProMoT achieves similar performance on the fine-tuned tasks compared with vanilla fine-tuning, but with much less reduction of in-context learning performances across the board. More importantly, ProMoT shows remarkable generalization ability on tasks that have different formats, e.g. fine-tuning on a NLI binary classification task improves the model's in-context ability to do summarization (+0.53 Rouge-2 score compared to the pretrained model), making ProMoT a promising method to build general purpose capabilities such as grounding and reasoning into LLMs with small but high quality datasets. When extended to sequential or multi-task training, ProMoT can achieve even better out-of-domain generalization performance.
Uncertainty in Extreme Multi-label Classification
Oct 18, 2022
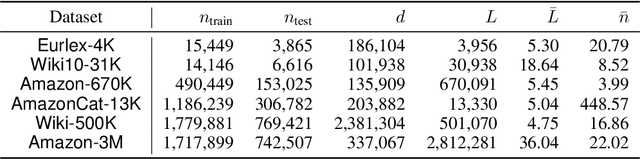
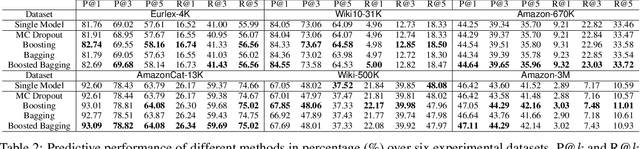
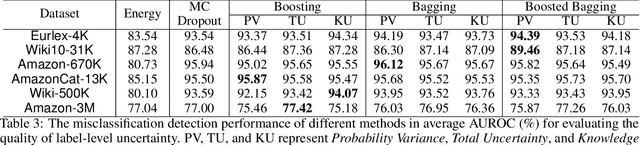
Uncertainty quantification is one of the most crucial tasks to obtain trustworthy and reliable machine learning models for decision making. However, most research in this domain has only focused on problems with small label spaces and ignored eXtreme Multi-label Classification (XMC), which is an essential task in the era of big data for web-scale machine learning applications. Moreover, enormous label spaces could also lead to noisy retrieval results and intractable computational challenges for uncertainty quantification. In this paper, we aim to investigate general uncertainty quantification approaches for tree-based XMC models with a probabilistic ensemble-based framework. In particular, we analyze label-level and instance-level uncertainty in XMC, and propose a general approximation framework based on beam search to efficiently estimate the uncertainty with a theoretical guarantee under long-tail XMC predictions. Empirical studies on six large-scale real-world datasets show that our framework not only outperforms single models in predictive performance, but also can serve as strong uncertainty-based baselines for label misclassification and out-of-distribution detection, with significant speedup. Besides, our framework can further yield better state-of-the-art results based on deep XMC models with uncertainty quantification.
End-to-End Learning to Index and Search in Large Output Spaces
Oct 16, 2022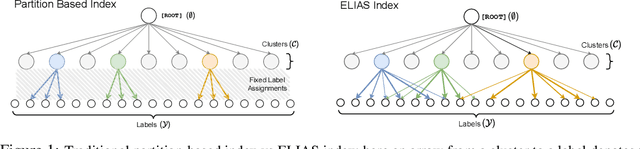
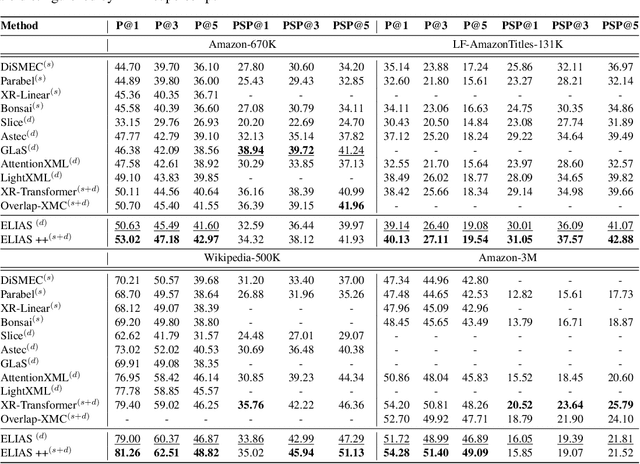
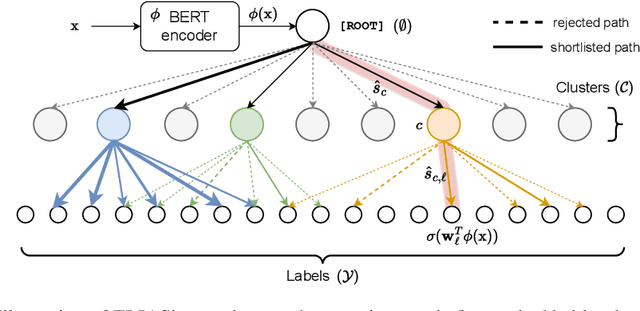
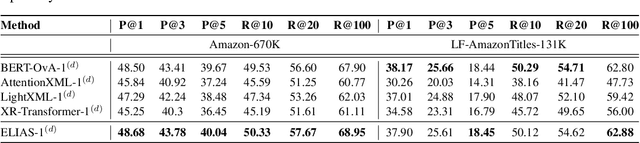
Extreme multi-label classification (XMC) is a popular framework for solving many real-world problems that require accurate prediction from a very large number of potential output choices. A popular approach for dealing with the large label space is to arrange the labels into a shallow tree-based index and then learn an ML model to efficiently search this index via beam search. Existing methods initialize the tree index by clustering the label space into a few mutually exclusive clusters based on pre-defined features and keep it fixed throughout the training procedure. This approach results in a sub-optimal indexing structure over the label space and limits the search performance to the quality of choices made during the initialization of the index. In this paper, we propose a novel method ELIAS which relaxes the tree-based index to a specialized weighted graph-based index which is learned end-to-end with the final task objective. More specifically, ELIAS models the discrete cluster-to-label assignments in the existing tree-based index as soft learnable parameters that are learned jointly with the rest of the ML model. ELIAS achieves state-of-the-art performance on several large-scale extreme classification benchmarks with millions of labels. In particular, ELIAS can be up to 2.5% better at precision@1 and up to 4% better at recall@100 than existing XMC methods. A PyTorch implementation of ELIAS along with other resources is available at https://github.com/nilesh2797/ELIAS.