 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to EdgeA Survey of Parameters Associated with the Quality of Benchmarks in NLP
Oct 14, 2022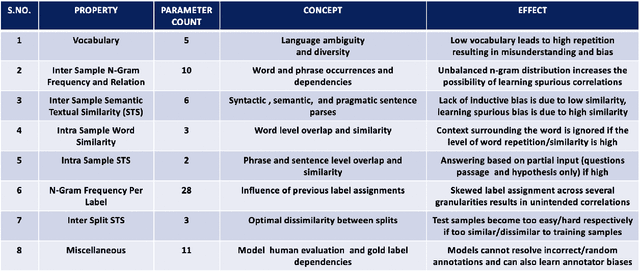
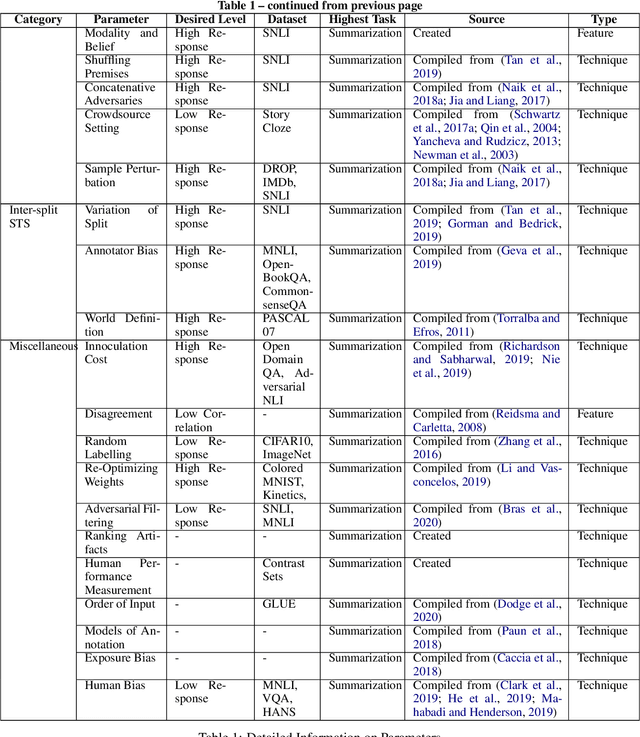
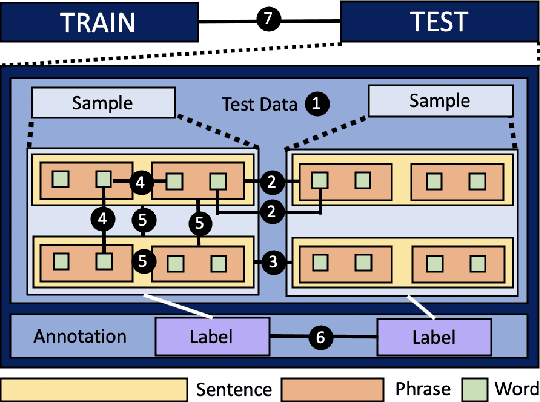
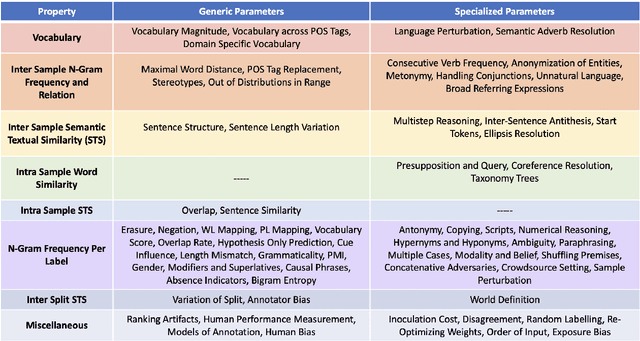
Several benchmarks have been built with heavy investment in resources to track our progress in NLP. Thousands of papers published in response to those benchmarks have competed to top leaderboards, with models often surpassing human performance. However, recent studies have shown that models triumph over several popular benchmarks just by overfitting on spurious biases, without truly learning the desired task. Despite this finding, benchmarking, while trying to tackle bias, still relies on workarounds, which do not fully utilize the resources invested in benchmark creation, due to the discarding of low quality data, and cover limited sets of bias. A potential solution to these issues -- a metric quantifying quality -- remains underexplored. Inspired by successful quality indices in several domains such as power, food, and water, we take the first step towards a metric by identifying certain language properties that can represent various possible interactions leading to biases in a benchmark. We look for bias related parameters which can potentially help pave our way towards the metric. We survey existing works and identify parameters capturing various properties of bias, their origins, types and impact on performance, generalization, and robustness. Our analysis spans over datasets and a hierarchy of tasks ranging from NLI to Summarization, ensuring that our parameters are generic and are not overfitted towards a specific task or dataset. We also develop certain parameters in this process.
Model Cascading: Towards Jointly Improving Efficiency and Accuracy of NLP Systems
Oct 11, 2022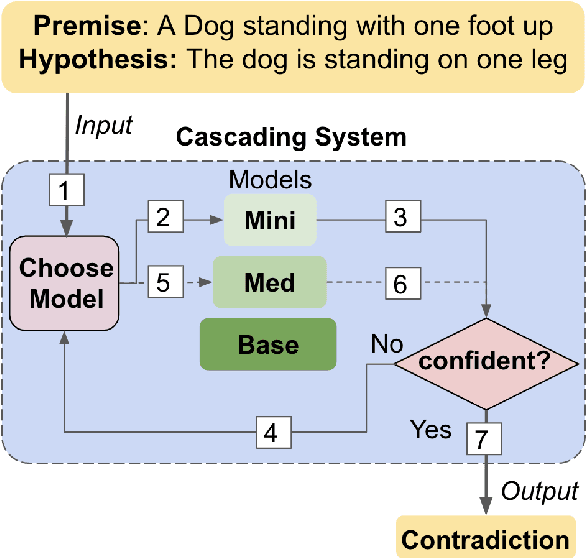
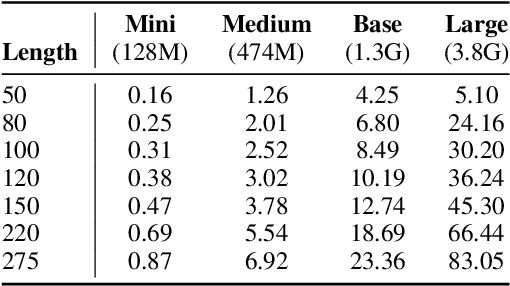
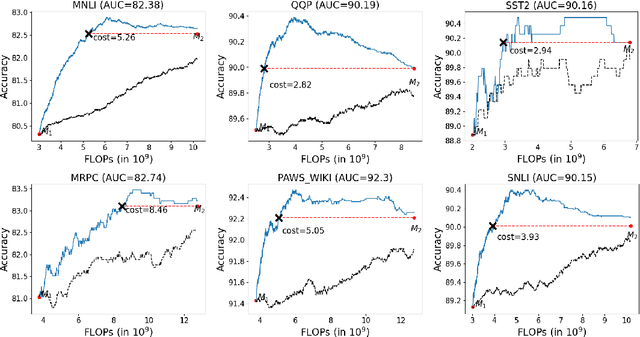
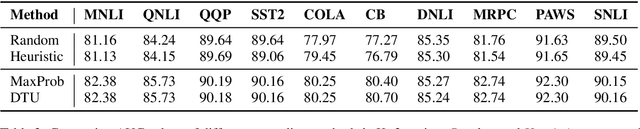
Do all instances need inference through the big models for a correct prediction? Perhaps not; some instances are easy and can be answered correctly by even small capacity models. This provides opportunities for improving the computational efficiency of systems. In this work, we present an explorative study on 'model cascading', a simple technique that utilizes a collection of models of varying capacities to accurately yet efficiently output predictions. Through comprehensive experiments in multiple task settings that differ in the number of models available for cascading (K value), we show that cascading improves both the computational efficiency and the prediction accuracy. For instance, in K=3 setting, cascading saves up to 88.93% computation cost and consistently achieves superior prediction accuracy with an improvement of up to 2.18%. We also study the impact of introducing additional models in the cascade and show that it further increases the efficiency improvements. Finally, we hope that our work will facilitate development of efficient NLP systems making their widespread adoption in real-world applications possible.
Investigating the Failure Modes of the AUC metric and Exploring Alternatives for Evaluating Systems in Safety Critical Applications
Oct 10, 2022
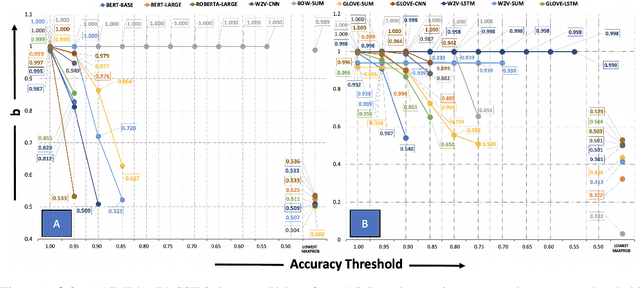
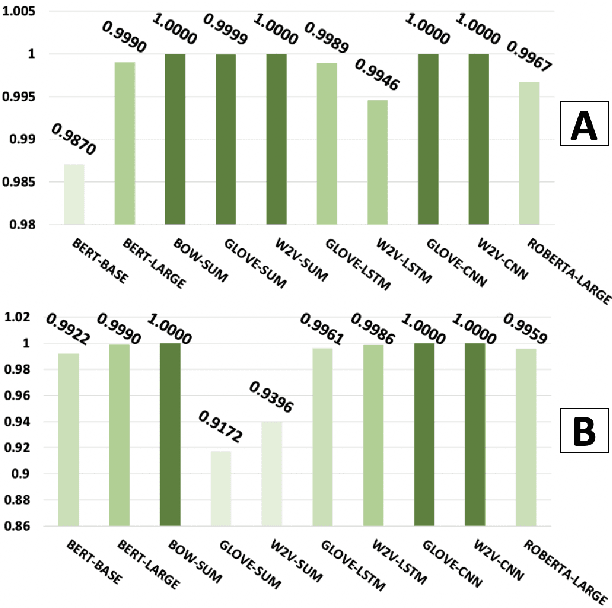

With the increasing importance of safety requirements associated with the use of black box models, evaluation of selective answering capability of models has been critical. Area under the curve (AUC) is used as a metric for this purpose. We find limitations in AUC; e.g., a model having higher AUC is not always better in performing selective answering. We propose three alternate metrics that fix the identified limitations. On experimenting with ten models, our results using the new metrics show that newer and larger pre-trained models do not necessarily show better performance in selective answering. We hope our insights will help develop better models tailored for safety-critical applications.
A Study on the Efficiency and Generalization of Light Hybrid Retrievers
Oct 04, 2022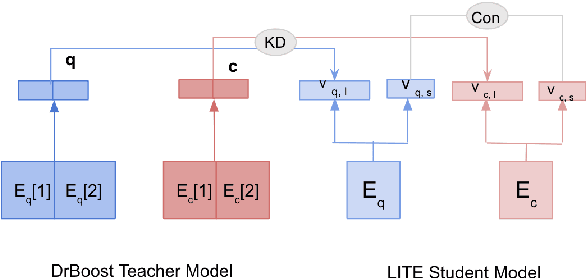
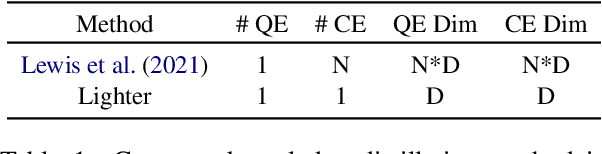
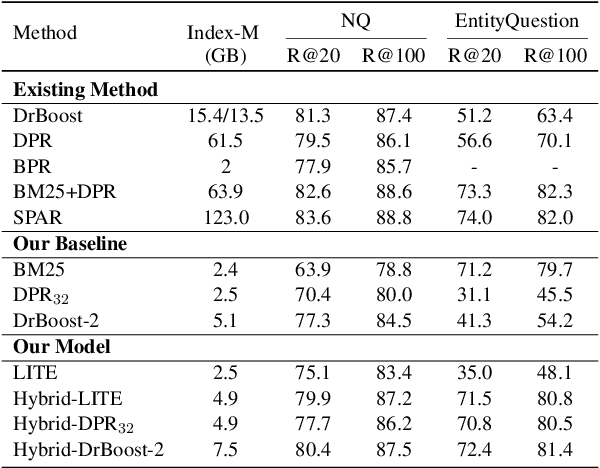
Existing hybrid retrievers which integrate sparse and dense retrievers, are indexing-heavy, limiting their applicability in real-world on-devices settings. We ask the question "Is it possible to reduce the indexing memory of hybrid retrievers without sacrificing performance?" Driven by this question, we leverage an indexing-efficient dense retriever (i.e. DrBoost) to obtain a light hybrid retriever. Moreover, to further reduce the memory, we introduce a lighter dense retriever (LITE) which is jointly trained on contrastive learning and knowledge distillation from DrBoost. Compared to previous heavy hybrid retrievers, our Hybrid-LITE retriever saves 13 memory while maintaining 98.0 performance. In addition, we study the generalization of light hybrid retrievers along two dimensions, out-of-domain (OOD) generalization and robustness against adversarial attacks. We evaluate models on two existing OOD benchmarks and create six adversarial attack sets for robustness evaluation. Experiments show that our light hybrid retrievers achieve better robustness performance than both sparse and dense retrievers. Nevertheless there is a large room to improve the robustness of retrievers, and our datasets can aid future research.
Reasoning about Actions over Visual and Linguistic Modalities: A Survey
Jul 15, 2022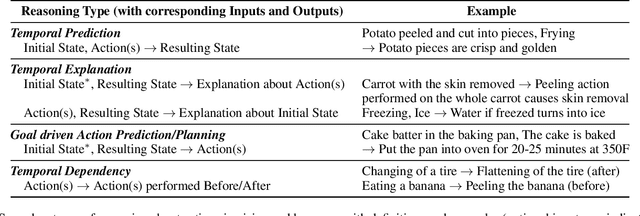


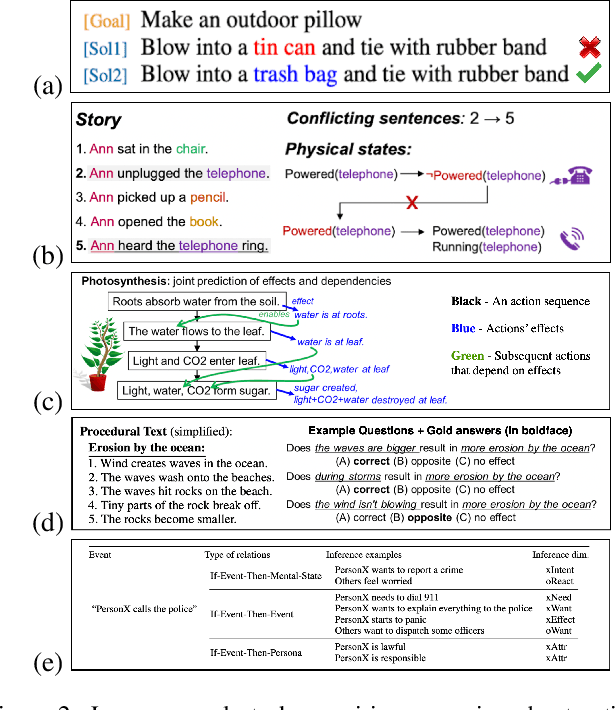
'Actions' play a vital role in how humans interact with the world and enable them to achieve desired goals. As a result, most common sense (CS) knowledge for humans revolves around actions. While 'Reasoning about Actions & Change' (RAC) has been widely studied in the Knowledge Representation community, it has recently piqued the interest of NLP and computer vision researchers. This paper surveys existing tasks, benchmark datasets, various techniques and models, and their respective performance concerning advancements in RAC in the vision and language domain. Towards the end, we summarize our key takeaways, discuss the present challenges facing this research area, and outline potential directions for future research.
BioTABQA: Instruction Learning for Biomedical Table Question Answering
Jul 06, 2022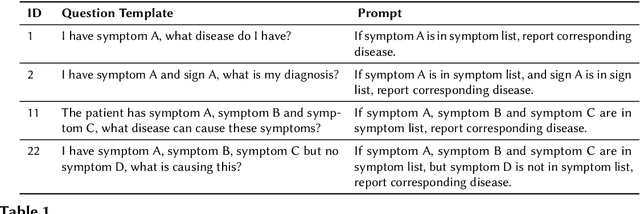
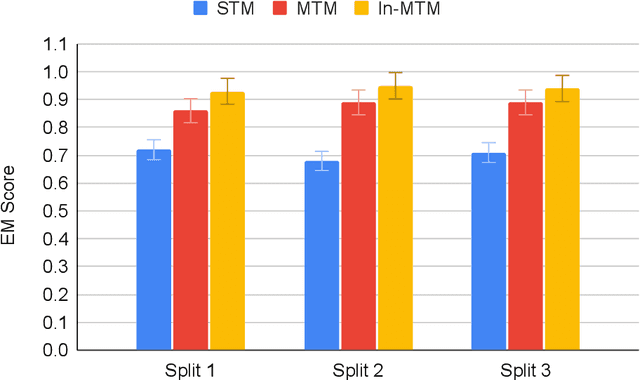
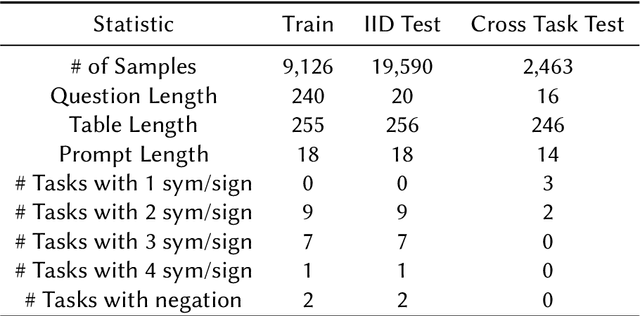
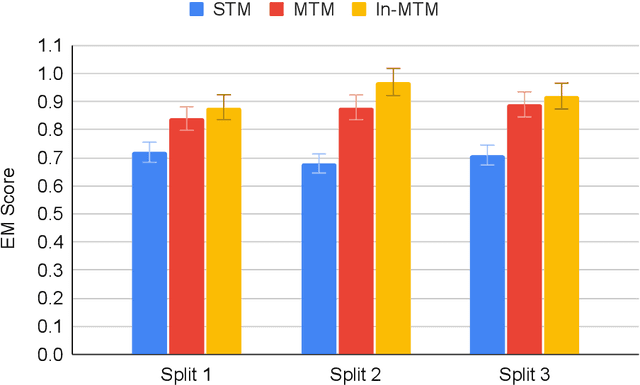
Table Question Answering (TQA) is an important but under-explored task. Most of the existing QA datasets are in unstructured text format and only few of them use tables as the context. To the best of our knowledge, none of TQA datasets exist in the biomedical domain where tables are frequently used to present information. In this paper, we first curate a table question answering dataset, BioTABQA, using 22 templates and the context from a biomedical textbook on differential diagnosis. BioTABQA can not only be used to teach a model how to answer questions from tables but also evaluate how a model generalizes to unseen questions, an important scenario for biomedical applications. To achieve the generalization evaluation, we divide the templates into 17 training and 5 cross-task evaluations. Then, we develop two baselines using single and multi-tasks learning on BioTABQA. Furthermore, we explore instructional learning, a recent technique showing impressive generalizing performance. Experimental results show that our instruction-tuned model outperforms single and multi-task baselines on an average by ~23% and ~6% across various evaluation settings, and more importantly, instruction-tuned model outperforms baselines by ~5% on cross-tasks.
Improving Diversity with Adversarially Learned Transformations for Domain Generalization
Jun 15, 2022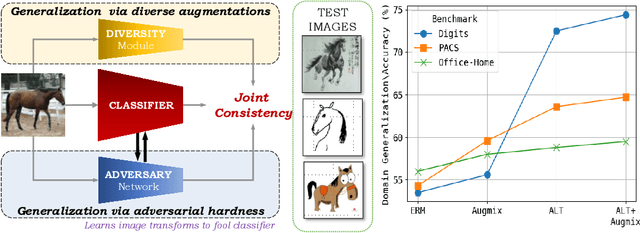
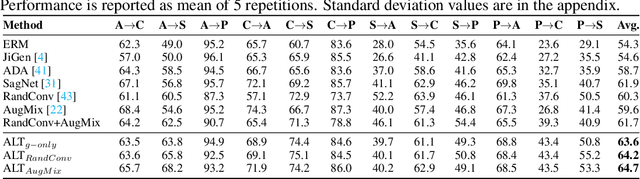
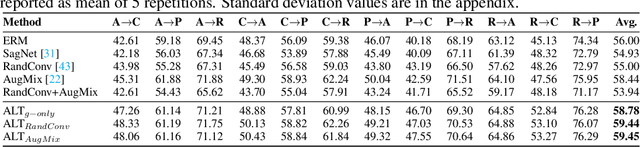
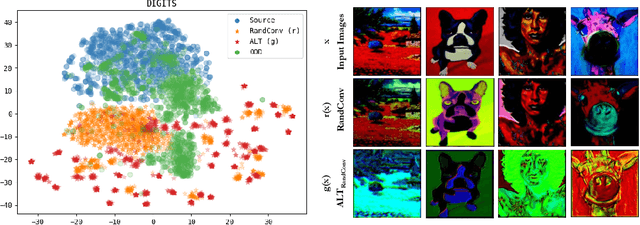
To be successful in single source domain generalization, maximizing diversity of synthesized domains has emerged as one of the most effective strategies. Many of the recent successes have come from methods that pre-specify the types of diversity that a model is exposed to during training, so that it can ultimately generalize well to new domains. However, na\"ive diversity based augmentations do not work effectively for domain generalization either because they cannot model large domain shift, or because the span of transforms that are pre-specified do not cover the types of shift commonly occurring in domain generalization. To address this issue, we present a novel framework that uses adversarially learned transformations (ALT) using a neural network to model plausible, yet hard image transformations that fool the classifier. This network is randomly initialized for each batch and trained for a fixed number of steps to maximize classification error. Further, we enforce consistency between the classifier's predictions on the clean and transformed images. With extensive empirical analysis, we find that this new form of adversarial transformations achieve both objectives of diversity and hardness simultaneously, outperforming all existing techniques on competitive benchmarks for single source domain generalization. We also show that ALT can naturally work with existing diversity modules to produce highly distinct, and large transformations of the source domain leading to state-of-the-art performance.
Beyond the Imitation Game: Quantifying and extrapolating the capabilities of language models
Jun 10, 2022Language models demonstrate both quantitative improvement and new qualitative capabilities with increasing scale. Despite their potentially transformative impact, these new capabilities are as yet poorly characterized. In order to inform future research, prepare for disruptive new model capabilities, and ameliorate socially harmful effects, it is vital that we understand the present and near-future capabilities and limitations of language models. To address this challenge, we introduce the Beyond the Imitation Game benchmark (BIG-bench). BIG-bench currently consists of 204 tasks, contributed by 442 authors across 132 institutions. Task topics are diverse, drawing problems from linguistics, childhood development, math, common-sense reasoning, biology, physics, social bias, software development, and beyond. BIG-bench focuses on tasks that are believed to be beyond the capabilities of current language models. We evaluate the behavior of OpenAI's GPT models, Google-internal dense transformer architectures, and Switch-style sparse transformers on BIG-bench, across model sizes spanning millions to hundreds of billions of parameters. In addition, a team of human expert raters performed all tasks in order to provide a strong baseline. Findings include: model performance and calibration both improve with scale, but are poor in absolute terms (and when compared with rater performance); performance is remarkably similar across model classes, though with benefits from sparsity; tasks that improve gradually and predictably commonly involve a large knowledge or memorization component, whereas tasks that exhibit "breakthrough" behavior at a critical scale often involve multiple steps or components, or brittle metrics; social bias typically increases with scale in settings with ambiguous context, but this can be improved with prompting.
Let the Model Decide its Curriculum for Multitask Learning
May 27, 2022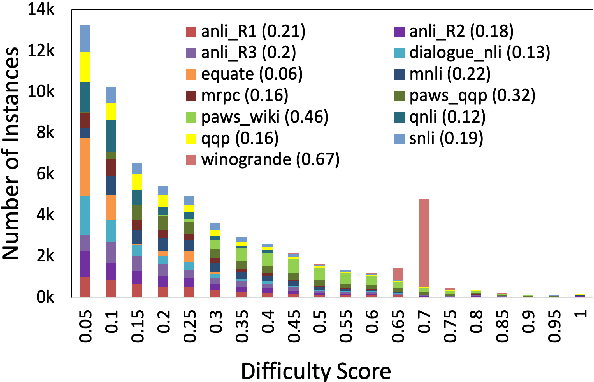
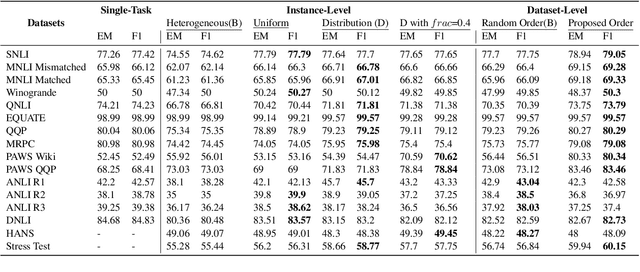
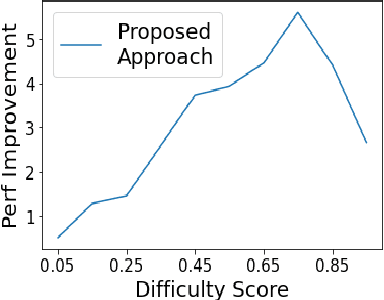
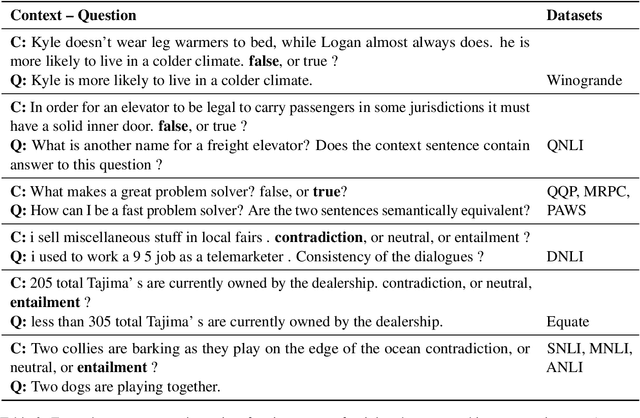
Curriculum learning strategies in prior multi-task learning approaches arrange datasets in a difficulty hierarchy either based on human perception or by exhaustively searching the optimal arrangement. However, human perception of difficulty may not always correlate well with machine interpretation leading to poor performance and exhaustive search is computationally expensive. Addressing these concerns, we propose two classes of techniques to arrange training instances into a learning curriculum based on difficulty scores computed via model-based approaches. The two classes i.e Dataset-level and Instance-level differ in granularity of arrangement. Through comprehensive experiments with 12 datasets, we show that instance-level and dataset-level techniques result in strong representations as they lead to an average performance improvement of 4.17% and 3.15% over their respective baselines. Furthermore, we find that most of this improvement comes from correctly answering the difficult instances, implying a greater efficacy of our techniques on difficult tasks.
Is a Question Decomposition Unit All We Need?
May 25, 2022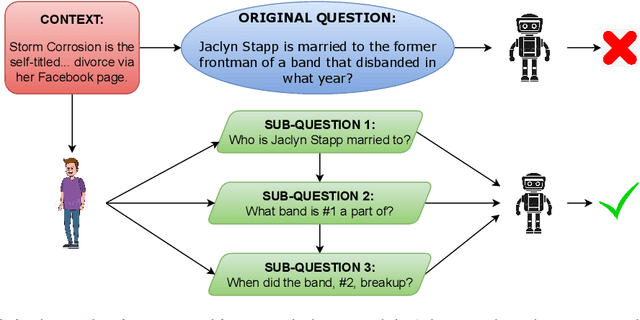

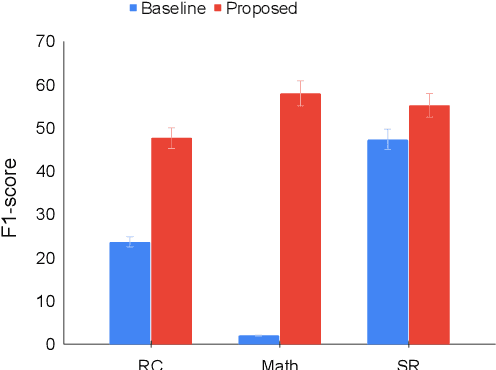

Large Language Models (LMs) have achieved state-of-the-art performance on many Natural Language Processing (NLP) benchmarks. With the growing number of new benchmarks, we build bigger and more complex LMs. However, building new LMs may not be an ideal option owing to the cost, time and environmental impact associated with it. We explore an alternative route: can we modify data by expressing it in terms of the model's strengths, so that a question becomes easier for models to answer? We investigate if humans can decompose a hard question into a set of simpler questions that are relatively easier for models to solve. We analyze a range of datasets involving various forms of reasoning and find that it is indeed possible to significantly improve model performance (24% for GPT3 and 29% for RoBERTa-SQuAD along with a symbolic calculator) via decomposition. Our approach provides a viable option to involve people in NLP research in a meaningful way. Our findings indicate that Human-in-the-loop Question Decomposition (HQD) can potentially provide an alternate path to building large LMs.