 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to EdgeSPORTSQL: An Interactive System for Real-Time Sports Reasoning and Visualization
Aug 23, 2025We present a modular, interactive system, SPORTSQL, for natural language querying and visualization of dynamic sports data, with a focus on the English Premier League (EPL). The system translates user questions into executable SQL over a live, temporally indexed database constructed from real-time Fantasy Premier League (FPL) data. It supports both tabular and visual outputs, leveraging the symbolic reasoning capabilities of Large Language Models (LLMs) for query parsing, schema linking, and visualization selection. To evaluate system performance, we introduce the Dynamic Sport Question Answering benchmark (DSQABENCH), comprising 1,700+ queries annotated with SQL programs, gold answers, and database snapshots. Our demo highlights how non-expert users can seamlessly explore evolving sports statistics through a natural, conversational interface.
InFiConD: Interactive No-code Fine-tuning with Concept-based Knowledge Distillation
Jun 25, 2024



The emergence of large-scale pre-trained models has heightened their application in various downstream tasks, yet deployment is a challenge in environments with limited computational resources. Knowledge distillation has emerged as a solution in such scenarios, whereby knowledge from large teacher models is transferred into smaller student' models, but this is a non-trivial process that traditionally requires technical expertise in AI/ML. To address these challenges, this paper presents InFiConD, a novel framework that leverages visual concepts to implement the knowledge distillation process and enable subsequent no-code fine-tuning of student models. We develop a novel knowledge distillation pipeline based on extracting text-aligned visual concepts from a concept corpus using multimodal models, and construct highly interpretable linear student models based on visual concepts that mimic a teacher model in a response-based manner. InFiConD's interface allows users to interactively fine-tune the student model by manipulating concept influences directly in the user interface. We validate InFiConD via a robust usage scenario and user study. Our findings indicate that InFiConD's human-in-the-loop and visualization-driven approach enables users to effectively create and analyze student models, understand how knowledge is transferred, and efficiently perform fine-tuning operations. We discuss how this work highlights the potential of interactive and visual methods in making knowledge distillation and subsequent no-code fine-tuning more accessible and adaptable to a wider range of users with domain-specific demands.
ASAP: Interpretable Analysis and Summarization of AI-generated Image Patterns at Scale
Apr 03, 2024



Generative image models have emerged as a promising technology to produce realistic images. Despite potential benefits, concerns grow about its misuse, particularly in generating deceptive images that could raise significant ethical, legal, and societal issues. Consequently, there is growing demand to empower users to effectively discern and comprehend patterns of AI-generated images. To this end, we developed ASAP, an interactive visualization system that automatically extracts distinct patterns of AI-generated images and allows users to interactively explore them via various views. To uncover fake patterns, ASAP introduces a novel image encoder, adapted from CLIP, which transforms images into compact "distilled" representations, enriched with information for differentiating authentic and fake images. These representations generate gradients that propagate back to the attention maps of CLIP's transformer block. This process quantifies the relative importance of each pixel to image authenticity or fakeness, exposing key deceptive patterns. ASAP enables the at scale interactive analysis of these patterns through multiple, coordinated visualizations. This includes a representation overview with innovative cell glyphs to aid in the exploration and qualitative evaluation of fake patterns across a vast array of images, as well as a pattern view that displays authenticity-indicating patterns in images and quantifies their impact. ASAP supports the analysis of cutting-edge generative models with the latest architectures, including GAN-based models like proGAN and diffusion models like the latent diffusion model. We demonstrate ASAP's usefulness through two usage scenarios using multiple fake image detection benchmark datasets, revealing its ability to identify and understand hidden patterns in AI-generated images, especially in detecting fake human faces produced by diffusion-based techniques.
InterVLS: Interactive Model Understanding and Improvement with Vision-Language Surrogates
Nov 06, 2023



Deep learning models are widely used in critical applications, highlighting the need for pre-deployment model understanding and improvement. Visual concept-based methods, while increasingly used for this purpose, face challenges: (1) most concepts lack interpretability, (2) existing methods require model knowledge, often unavailable at run time. Additionally, (3) there lacks a no-code method for post-understanding model improvement. Addressing these, we present InterVLS. The system facilitates model understanding by discovering text-aligned concepts, measuring their influence with model-agnostic linear surrogates. Employing visual analytics, InterVLS offers concept-based explanations and performance insights. It enables users to adjust concept influences to update a model, facilitating no-code model improvement. We evaluate InterVLS in a user study, illustrating its functionality with two scenarios. Results indicates that InterVLS is effective to help users identify influential concepts to a model, gain insights and adjust concept influence to improve the model. We conclude with a discussion based on our study results.
LINGO : Visually Debiasing Natural Language Instructions to Support Task Diversity
Apr 12, 2023Cross-task generalization is a significant outcome that defines mastery in natural language understanding. Humans show a remarkable aptitude for this, and can solve many different types of tasks, given definitions in the form of textual instructions and a small set of examples. Recent work with pre-trained language models mimics this learning style: users can define and exemplify a task for the model to attempt as a series of natural language prompts or instructions. While prompting approaches have led to higher cross-task generalization compared to traditional supervised learning, analyzing 'bias' in the task instructions given to the model is a difficult problem, and has thus been relatively unexplored. For instance, are we truly modeling a task, or are we modeling a user's instructions? To help investigate this, we develop LINGO, a novel visual analytics interface that supports an effective, task-driven workflow to (1) help identify bias in natural language task instructions, (2) alter (or create) task instructions to reduce bias, and (3) evaluate pre-trained model performance on debiased task instructions. To robustly evaluate LINGO, we conduct a user study with both novice and expert instruction creators, over a dataset of 1,616 linguistic tasks and their natural language instructions, spanning 55 different languages. For both user groups, LINGO promotes the creation of more difficult tasks for pre-trained models, that contain higher linguistic diversity and lower instruction bias. We additionally discuss how the insights learned in developing and evaluating LINGO can aid in the design of future dashboards that aim to minimize the effort involved in prompt creation across multiple domains.
Real-Time Visual Feedback to Guide Benchmark Creation: A Human-and-Metric-in-the-Loop Workflow
Feb 09, 2023Recent research has shown that language models exploit `artifacts' in benchmarks to solve tasks, rather than truly learning them, leading to inflated model performance. In pursuit of creating better benchmarks, we propose VAIDA, a novel benchmark creation paradigm for NLP, that focuses on guiding crowdworkers, an under-explored facet of addressing benchmark idiosyncrasies. VAIDA facilitates sample correction by providing realtime visual feedback and recommendations to improve sample quality. Our approach is domain, model, task, and metric agnostic, and constitutes a paradigm shift for robust, validated, and dynamic benchmark creation via human-and-metric-in-the-loop workflows. We evaluate via expert review and a user study with NASA TLX. We find that VAIDA decreases effort, frustration, mental, and temporal demands of crowdworkers and analysts, simultaneously increasing the performance of both user groups with a 45.8% decrease in the level of artifacts in created samples. As a by product of our user study, we observe that created samples are adversarial across models, leading to decreases of 31.3% (BERT), 22.5% (RoBERTa), 14.98% (GPT-3 fewshot) in performance.
A Survey of Parameters Associated with the Quality of Benchmarks in NLP
Oct 14, 2022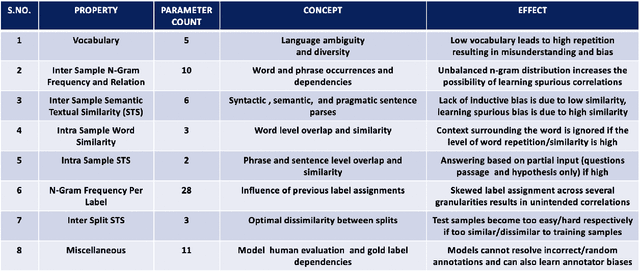
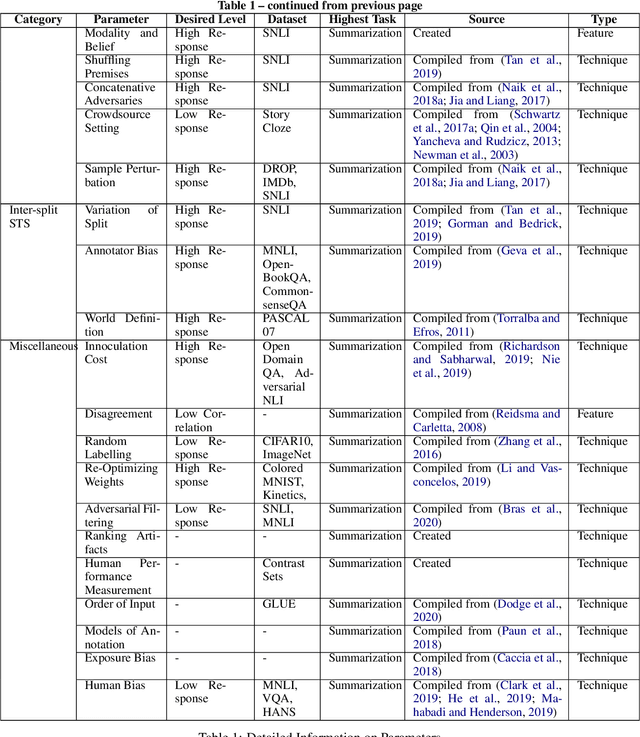
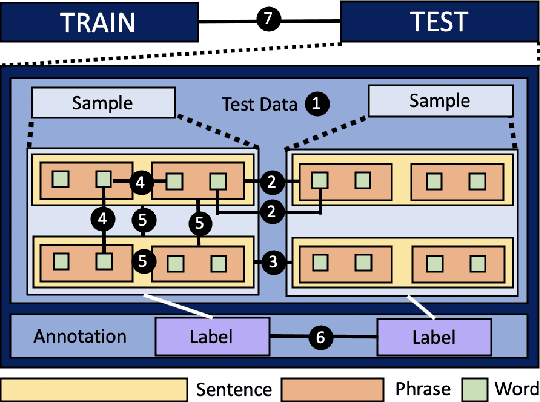
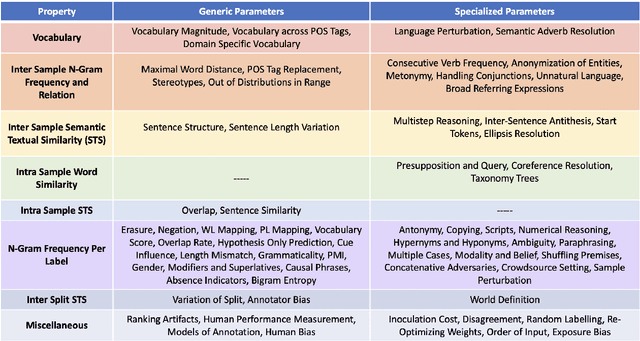
Several benchmarks have been built with heavy investment in resources to track our progress in NLP. Thousands of papers published in response to those benchmarks have competed to top leaderboards, with models often surpassing human performance. However, recent studies have shown that models triumph over several popular benchmarks just by overfitting on spurious biases, without truly learning the desired task. Despite this finding, benchmarking, while trying to tackle bias, still relies on workarounds, which do not fully utilize the resources invested in benchmark creation, due to the discarding of low quality data, and cover limited sets of bias. A potential solution to these issues -- a metric quantifying quality -- remains underexplored. Inspired by successful quality indices in several domains such as power, food, and water, we take the first step towards a metric by identifying certain language properties that can represent various possible interactions leading to biases in a benchmark. We look for bias related parameters which can potentially help pave our way towards the metric. We survey existing works and identify parameters capturing various properties of bias, their origins, types and impact on performance, generalization, and robustness. Our analysis spans over datasets and a hierarchy of tasks ranging from NLI to Summarization, ensuring that our parameters are generic and are not overfitted towards a specific task or dataset. We also develop certain parameters in this process.
Hardness of Samples Need to be Quantified for a Reliable Evaluation System: Exploring Potential Opportunities with a New Task
Oct 14, 2022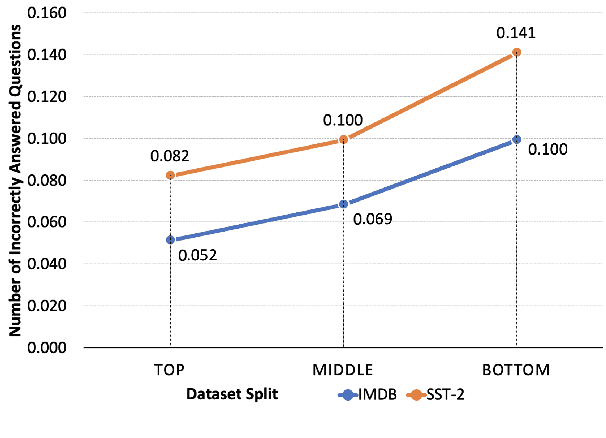
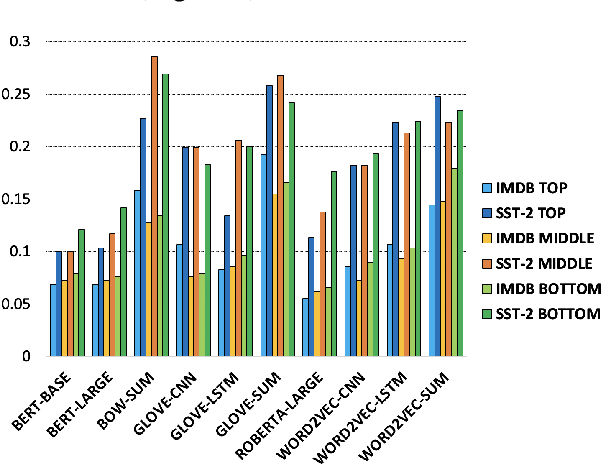
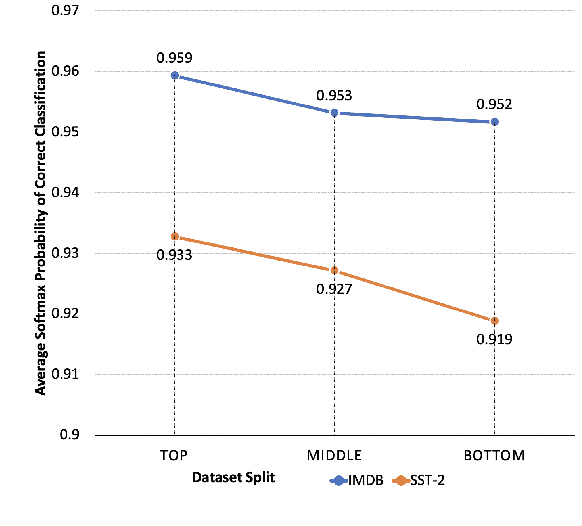
Evaluation of models on benchmarks is unreliable without knowing the degree of sample hardness; this subsequently overestimates the capability of AI systems and limits their adoption in real world applications. We propose a Data Scoring task that requires assignment of each unannotated sample in a benchmark a score between 0 to 1, where 0 signifies easy and 1 signifies hard. Use of unannotated samples in our task design is inspired from humans who can determine a question difficulty without knowing its correct answer. This also rules out the use of methods involving model based supervision (since they require sample annotations to get trained), eliminating potential biases associated with models in deciding sample difficulty. We propose a method based on Semantic Textual Similarity (STS) for this task; we validate our method by showing that existing models are more accurate with respect to the easier sample-chunks than with respect to the harder sample-chunks. Finally we demonstrate five novel applications.
DQI: A Guide to Benchmark Evaluation
Aug 10, 2020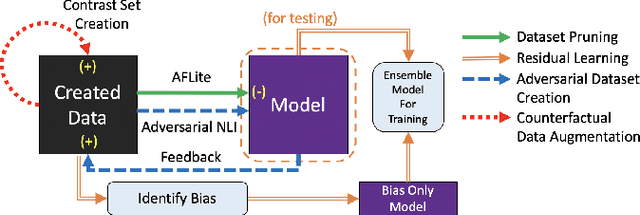


A `state of the art' model A surpasses humans in a benchmark B, but fails on similar benchmarks C, D, and E. What does B have that the other benchmarks do not? Recent research provides the answer: spurious bias. However, developing A to solve benchmarks B through E does not guarantee that it will solve future benchmarks. To progress towards a model that `truly learns' an underlying task, we need to quantify the differences between successive benchmarks, as opposed to existing binary and black-box approaches. We propose a novel approach to solve this underexplored task of quantifying benchmark quality by debuting a data quality metric: DQI.
Our Evaluation Metric Needs an Update to Encourage Generalization
Jul 14, 2020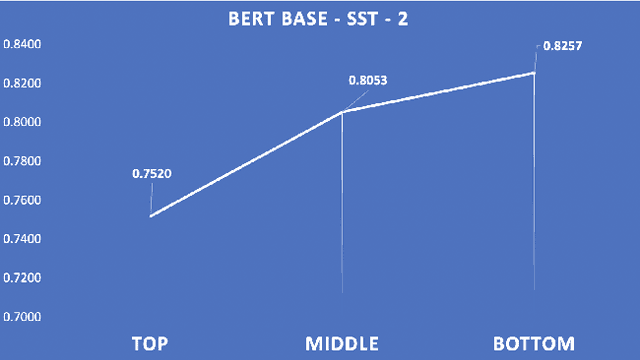
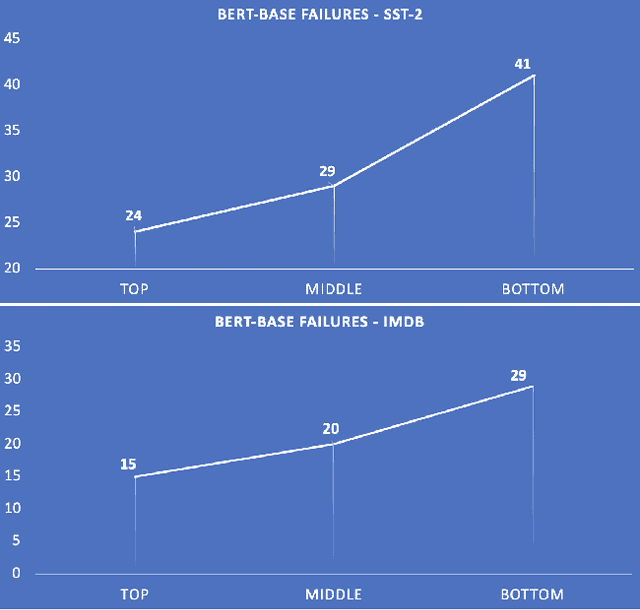
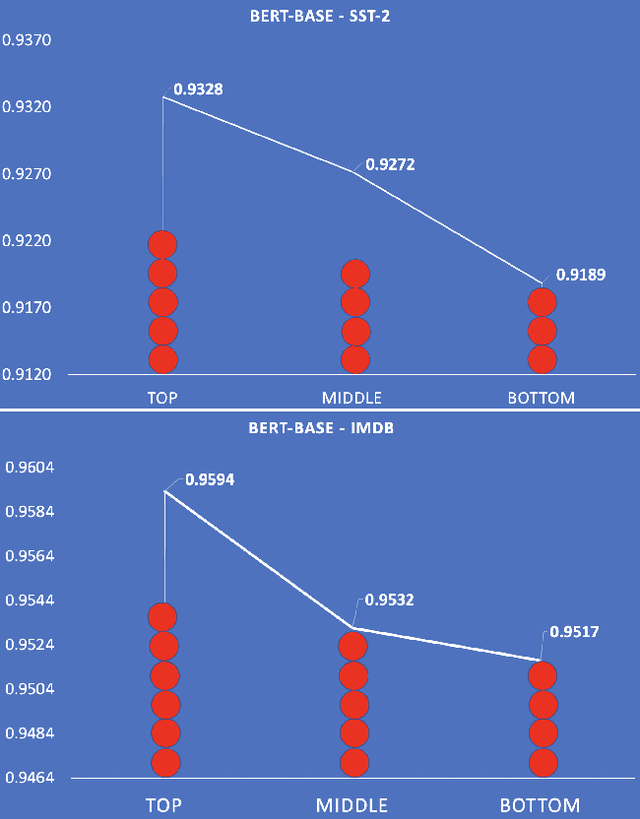
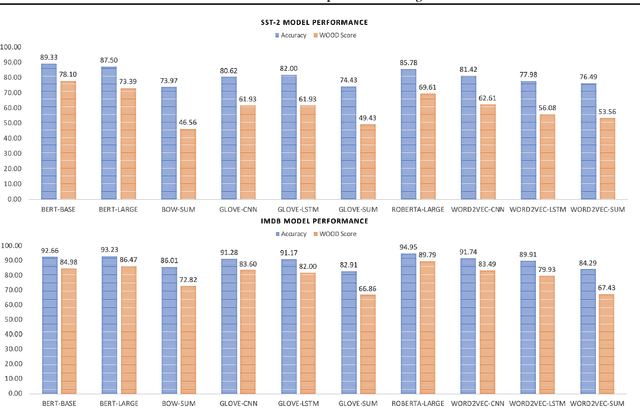
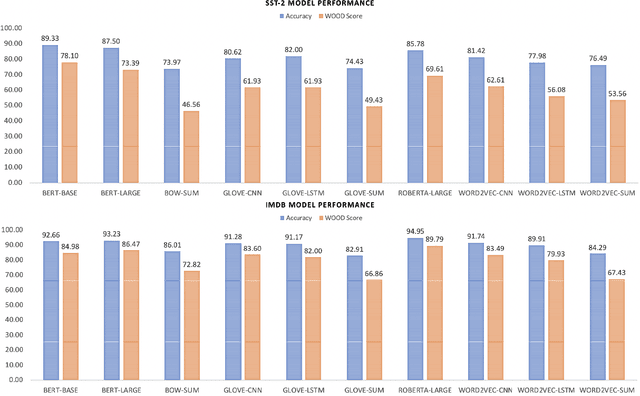
Models that surpass human performance on several popular benchmarks display significant degradation in performance on exposure to Out of Distribution (OOD) data. Recent research has shown that models overfit to spurious biases and `hack' datasets, in lieu of learning generalizable features like humans. In order to stop the inflation in model performance -- and thus overestimation in AI systems' capabilities -- we propose a simple and novel evaluation metric, WOOD Score, that encourages generalization during evaluation.