 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to EdgeLexi: Self-Supervised Learning of the UI Language
Jan 23, 2023



Humans can learn to operate the user interface (UI) of an application by reading an instruction manual or how-to guide. Along with text, these resources include visual content such as UI screenshots and images of application icons referenced in the text. We explore how to leverage this data to learn generic visio-linguistic representations of UI screens and their components. These representations are useful in many real applications, such as accessibility, voice navigation, and task automation. Prior UI representation models rely on UI metadata (UI trees and accessibility labels), which is often missing, incompletely defined, or not accessible. We avoid such a dependency, and propose Lexi, a pre-trained vision and language model designed to handle the unique features of UI screens, including their text richness and context sensitivity. To train Lexi we curate the UICaption dataset consisting of 114k UI images paired with descriptions of their functionality. We evaluate Lexi on four tasks: UI action entailment, instruction-based UI image retrieval, grounding referring expressions, and UI entity recognition.
Benchmarking Spatial Relationships in Text-to-Image Generation
Dec 20, 2022



Spatial understanding is a fundamental aspect of computer vision and integral for human-level reasoning about images, making it an important component for grounded language understanding. While recent large-scale text-to-image synthesis (T2I) models have shown unprecedented improvements in photorealism, it is unclear whether they have reliable spatial understanding capabilities. We investigate the ability of T2I models to generate correct spatial relationships among objects and present VISOR, an evaluation metric that captures how accurately the spatial relationship described in text is generated in the image. To benchmark existing models, we introduce a large-scale challenge dataset SR2D that contains sentences describing two objects and the spatial relationship between them. We construct and harness an automated evaluation pipeline that employs computer vision to recognize objects and their spatial relationships, and we employ it in a large-scale evaluation of T2I models. Our experiments reveal a surprising finding that, although recent state-of-the-art T2I models exhibit high image quality, they are severely limited in their ability to generate multiple objects or the specified spatial relations such as left/right/above/below. Our analyses demonstrate several biases and artifacts of T2I models such as the difficulty with generating multiple objects, a bias towards generating the first object mentioned, spatially inconsistent outputs for equivalent relationships, and a correlation between object co-occurrence and spatial understanding capabilities. We conduct a human study that shows the alignment between VISOR and human judgment about spatial understanding. We offer the SR2D dataset and the VISOR metric to the community in support of T2I spatial reasoning research.
Learning Action-Effect Dynamics from Pairs of Scene-graphs
Dec 07, 2022



'Actions' play a vital role in how humans interact with the world. Thus, autonomous agents that would assist us in everyday tasks also require the capability to perform 'Reasoning about Actions & Change' (RAC). Recently, there has been growing interest in the study of RAC with visual and linguistic inputs. Graphs are often used to represent semantic structure of the visual content (i.e. objects, their attributes and relationships among objects), commonly referred to as scene-graphs. In this work, we propose a novel method that leverages scene-graph representation of images to reason about the effects of actions described in natural language. We experiment with existing CLEVR_HYP (Sampat et. al, 2021) dataset and show that our proposed approach is effective in terms of performance, data efficiency, and generalization capability compared to existing models.
Learning Action-Effect Dynamics for Hypothetical Vision-Language Reasoning Task
Dec 07, 2022



'Actions' play a vital role in how humans interact with the world. Thus, autonomous agents that would assist us in everyday tasks also require the capability to perform 'Reasoning about Actions & Change' (RAC). This has been an important research direction in Artificial Intelligence (AI) in general, but the study of RAC with visual and linguistic inputs is relatively recent. The CLEVR_HYP (Sampat et. al., 2021) is one such testbed for hypothetical vision-language reasoning with actions as the key focus. In this work, we propose a novel learning strategy that can improve reasoning about the effects of actions. We implement an encoder-decoder architecture to learn the representation of actions as vectors. We combine the aforementioned encoder-decoder architecture with existing modality parsers and a scene graph question answering model to evaluate our proposed system on the CLEVR_HYP dataset. We conduct thorough experiments to demonstrate the effectiveness of our proposed approach and discuss its advantages over previous baselines in terms of performance, data efficiency, and generalization capability.
Can Open-Domain QA Reader Utilize External Knowledge Efficiently like Humans?
Nov 23, 2022



Recent state-of-the-art open-domain QA models are typically based on a two stage retriever-reader approach in which the retriever first finds the relevant knowledge/passages and the reader then leverages that to predict the answer. Prior work has shown that the performance of the reader usually tends to improve with the increase in the number of these passages. Thus, state-of-the-art models use a large number of passages (e.g. 100) for inference. While the reader in this approach achieves high prediction performance, its inference is computationally very expensive. We humans, on the other hand, use a more efficient strategy while answering: firstly, if we can confidently answer the question using our already acquired knowledge then we do not even use the external knowledge, and in the case when we do require external knowledge, we don't read the entire knowledge at once, instead, we only read that much knowledge that is sufficient to find the answer. Motivated by this procedure, we ask a research question "Can the open-domain QA reader utilize external knowledge efficiently like humans without sacrificing the prediction performance?" Driven by this question, we explore an approach that utilizes both 'closed-book' (leveraging knowledge already present in the model parameters) and 'open-book' inference (leveraging external knowledge). Furthermore, instead of using a large fixed number of passages for open-book inference, we dynamically read the external knowledge in multiple 'knowledge iterations'. Through comprehensive experiments on NQ and TriviaQA datasets, we demonstrate that this dynamic reading approach improves both the 'inference efficiency' and the 'prediction accuracy' of the reader. Comparing with the FiD reader, this approach matches its accuracy by utilizing just 18.32% of its reader inference cost and also outperforms it by achieving up to 55.10% accuracy on NQ Open.
CRIPP-VQA: Counterfactual Reasoning about Implicit Physical Properties via Video Question Answering
Nov 07, 2022



Videos often capture objects, their visible properties, their motion, and the interactions between different objects. Objects also have physical properties such as mass, which the imaging pipeline is unable to directly capture. However, these properties can be estimated by utilizing cues from relative object motion and the dynamics introduced by collisions. In this paper, we introduce CRIPP-VQA, a new video question answering dataset for reasoning about the implicit physical properties of objects in a scene. CRIPP-VQA contains videos of objects in motion, annotated with questions that involve counterfactual reasoning about the effect of actions, questions about planning in order to reach a goal, and descriptive questions about visible properties of objects. The CRIPP-VQA test set enables evaluation under several out-of-distribution settings -- videos with objects with masses, coefficients of friction, and initial velocities that are not observed in the training distribution. Our experiments reveal a surprising and significant performance gap in terms of answering questions about implicit properties (the focus of this paper) and explicit properties of objects (the focus of prior work).
Lila: A Unified Benchmark for Mathematical Reasoning
Oct 31, 2022Mathematical reasoning skills are essential for general-purpose intelligent systems to perform tasks from grocery shopping to climate modeling. Towards evaluating and improving AI systems in this domain, we propose LILA, a unified mathematical reasoning benchmark consisting of 23 diverse tasks along four dimensions: (i) mathematical abilities e.g., arithmetic, calculus (ii) language format e.g., question-answering, fill-in-the-blanks (iii) language diversity e.g., no language, simple language (iv) external knowledge e.g., commonsense, physics. We construct our benchmark by extending 20 datasets benchmark by collecting task instructions and solutions in the form of Python programs, thereby obtaining explainable solutions in addition to the correct answer. We additionally introduce two evaluation datasets to measure out-of-distribution performance and robustness to language perturbation. Finally, we introduce BHASKARA, a general-purpose mathematical reasoning model trained on LILA. Importantly, we find that multi-tasking leads to significant improvements (average relative improvement of 21.83% F1 score vs. single-task models), while the best performing model only obtains 60.40%, indicating the room for improvement in general mathematical reasoning and understanding.
Pretrained Transformers Do not Always Improve Robustness
Oct 14, 2022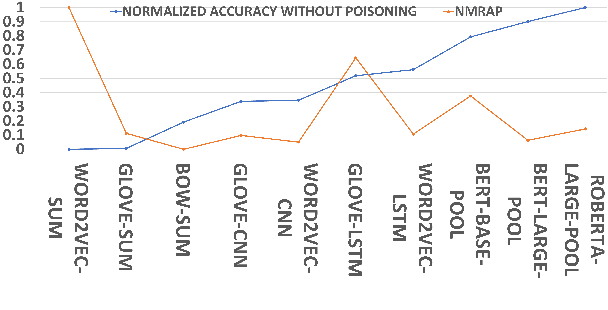
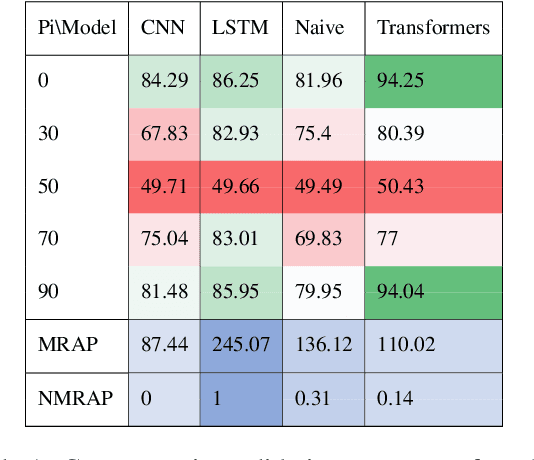
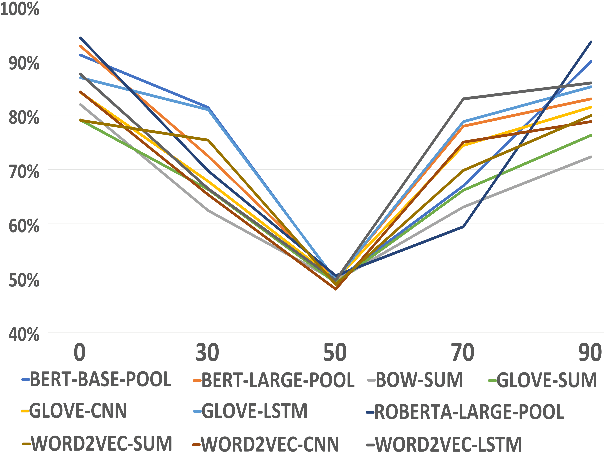
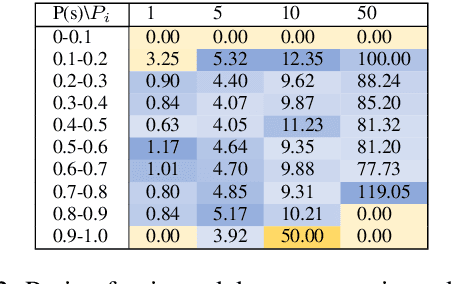
Pretrained Transformers (PT) have been shown to improve Out of Distribution (OOD) robustness than traditional models such as Bag of Words (BOW), LSTMs, Convolutional Neural Networks (CNN) powered by Word2Vec and Glove embeddings. How does the robustness comparison hold in a real world setting where some part of the dataset can be noisy? Do PT also provide more robust representation than traditional models on exposure to noisy data? We perform a comparative study on 10 models and find an empirical evidence that PT provide less robust representation than traditional models on exposure to noisy data. We investigate further and augment PT with an adversarial filtering (AF) mechanism that has been shown to improve OOD generalization. However, increase in generalization does not necessarily increase robustness, as we find that noisy data fools the AF method powered by PT.
"John is 50 years old, can his son be 65?" Evaluating NLP Models' Understanding of Feasibility
Oct 14, 2022
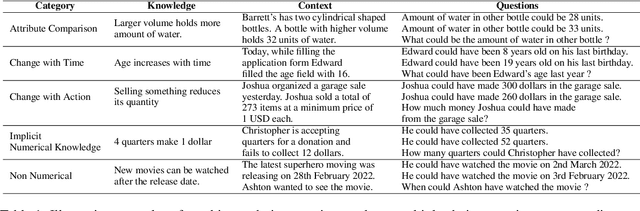
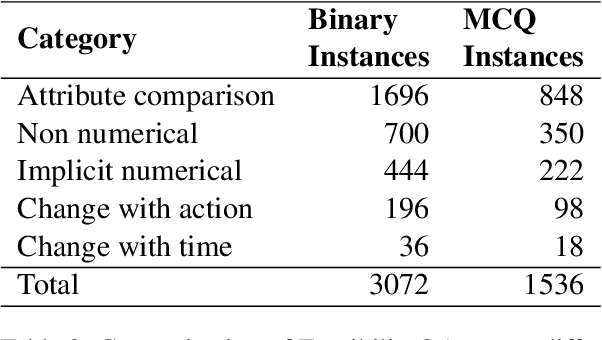

In current NLP research, large-scale language models and their abilities are widely being discussed. Some recent works have also found notable failures of these models. Often these failure examples involve complex reasoning abilities. This work focuses on a simple commonsense ability, reasoning about when an action (or its effect) is feasible. We introduce FeasibilityQA, a question-answering dataset involving binary classification (BCQ) and multi-choice multi-correct questions (MCQ) that test understanding of feasibility. We show that even state-of-the-art models such as GPT-3 struggle to answer the feasibility questions correctly. Specifically, on (MCQ, BCQ) questions, GPT-3 achieves accuracy of just (19%, 62%) and (25%, 64%) in zero-shot and few-shot settings, respectively. We also evaluate models by providing relevant knowledge statements required to answer the question and find that the additional knowledge leads to a 7% gain in performance, but the overall performance still remains low. These results make one wonder how much commonsense knowledge about action feasibility is encoded in GPT-3 and how well the model can reason about it.
Hardness of Samples Need to be Quantified for a Reliable Evaluation System: Exploring Potential Opportunities with a New Task
Oct 14, 2022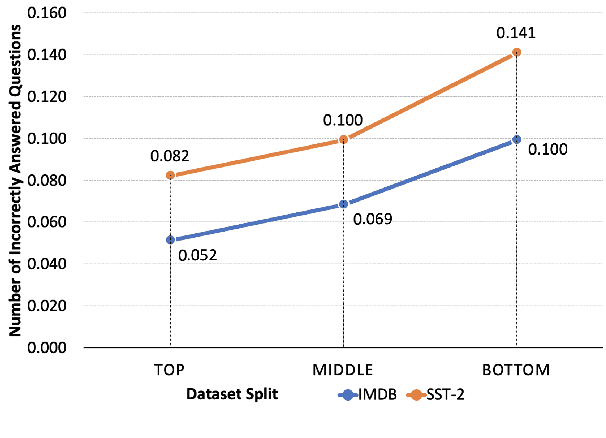
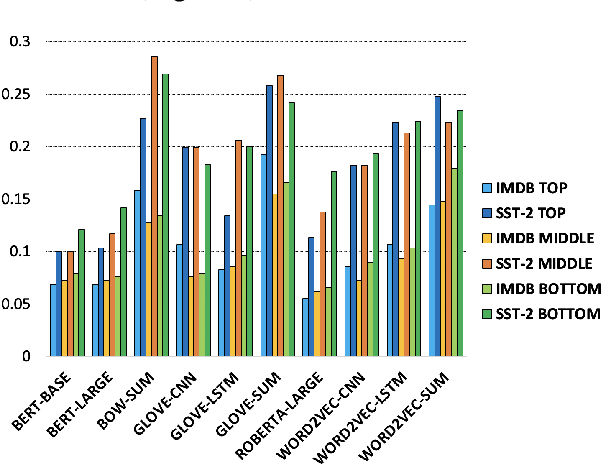
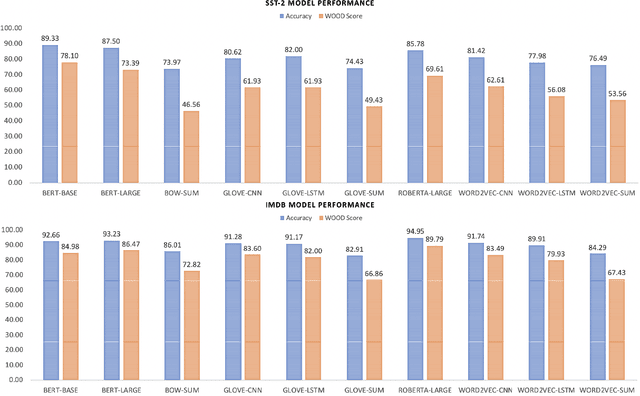
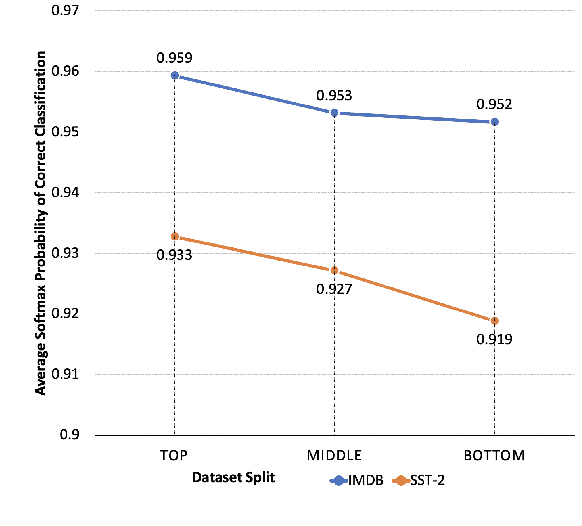
Evaluation of models on benchmarks is unreliable without knowing the degree of sample hardness; this subsequently overestimates the capability of AI systems and limits their adoption in real world applications. We propose a Data Scoring task that requires assignment of each unannotated sample in a benchmark a score between 0 to 1, where 0 signifies easy and 1 signifies hard. Use of unannotated samples in our task design is inspired from humans who can determine a question difficulty without knowing its correct answer. This also rules out the use of methods involving model based supervision (since they require sample annotations to get trained), eliminating potential biases associated with models in deciding sample difficulty. We propose a method based on Semantic Textual Similarity (STS) for this task; we validate our method by showing that existing models are more accurate with respect to the easier sample-chunks than with respect to the harder sample-chunks. Finally we demonstrate five novel applications.