 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to EdgeUSTC-NELSLIP System Description for DIHARD-III Challenge
Mar 19, 2021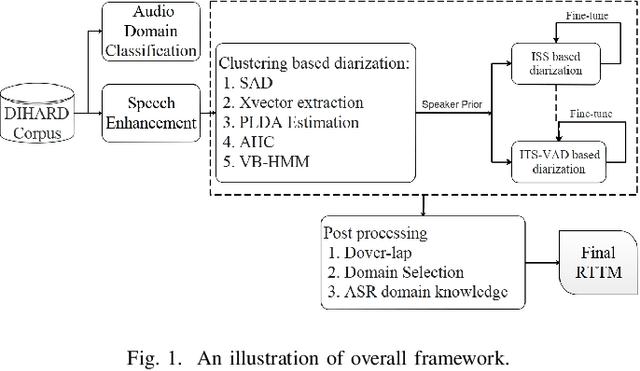
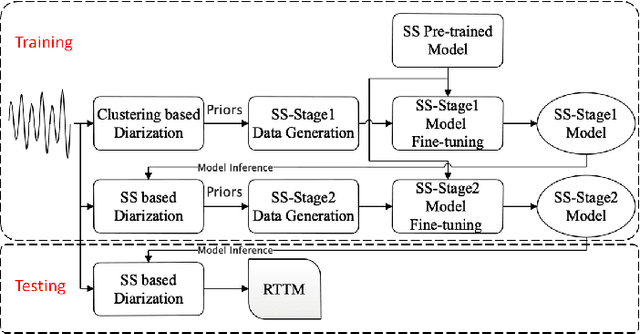
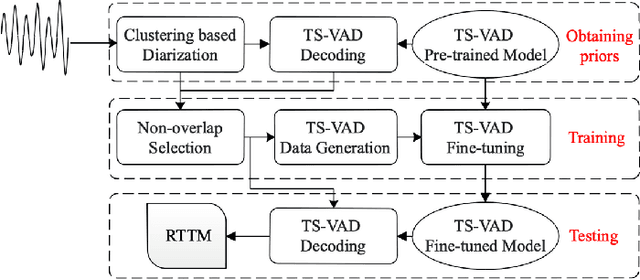
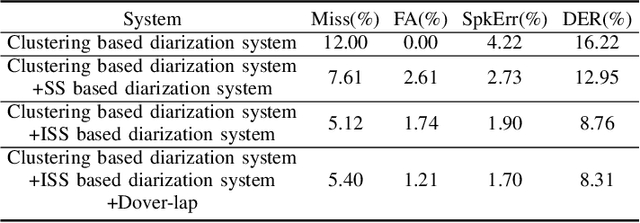
This system description describes our submission system to the Third DIHARD Speech Diarization Challenge. Besides the traditional clustering based system, the innovation of our system lies in the combination of various front-end techniques to solve the diarization problem, including speech separation and target-speaker based voice activity detection (TS-VAD), combined with iterative data purification. We also adopted audio domain classification to design domain-dependent processing. Finally, we performed post processing to do system fusion and selection. Our best system achieved DERs of 11.30% in track 1 and 16.78% in track 2 on evaluation set, respectively.
A Four-Stage Data Augmentation Approach to ResNet-Conformer Based Acoustic Modeling for Sound Event Localization and Detection
Jan 08, 2021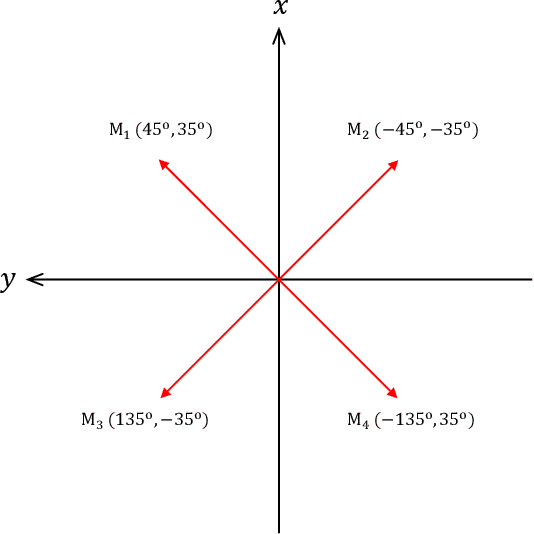
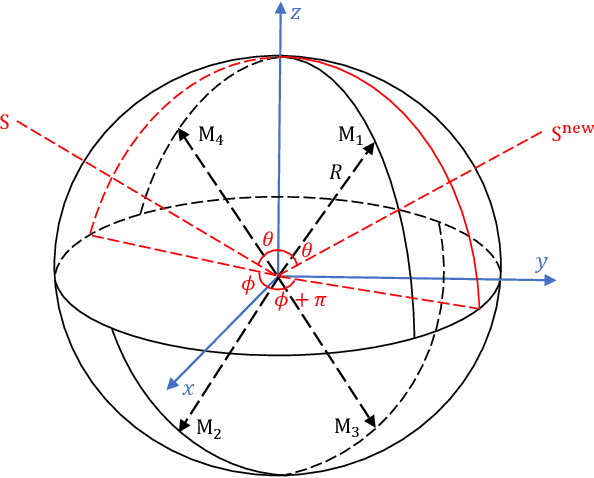
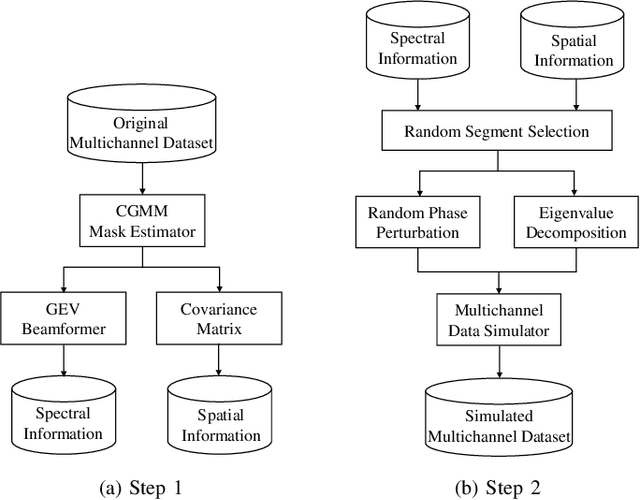
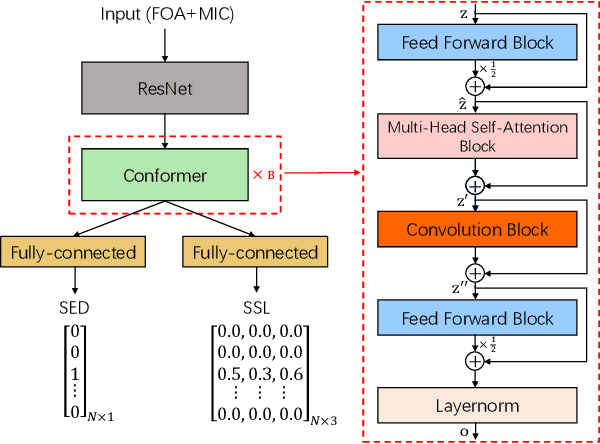
In this paper, we propose a novel four-stage data augmentation approach to ResNet-Conformer based acoustic modeling for sound event localization and detection (SELD). First, we explore two spatial augmentation techniques, namely audio channel swapping (ACS) and multi-channel simulation (MCS), to deal with data sparsity in SELD. ACS and MDS focus on augmenting the limited training data with expanding direction of arrival (DOA) representations such that the acoustic models trained with the augmented data are robust to localization variations of acoustic sources. Next, time-domain mixing (TDM) and time-frequency masking (TFM) are also investigated to deal with overlapping sound events and data diversity. Finally, ACS, MCS, TDM and TFM are combined in a step-by-step manner to form an effective four-stage data augmentation scheme. Tested on the Detection and Classification of Acoustic Scenes and Events (DCASE) 2020 data sets, our proposed augmentation approach greatly improves the system performance, ranking our submitted system in the first place in the SELD task of DCASE 2020 Challenge. Furthermore, we employ a ResNet-Conformer architecture to model both global and local context dependencies of an audio sequence to yield further gains over those architectures used in the DCASE 2020 SELD evaluations.
Lip-reading with Hierarchical Pyramidal Convolution and Self-Attention
Dec 28, 2020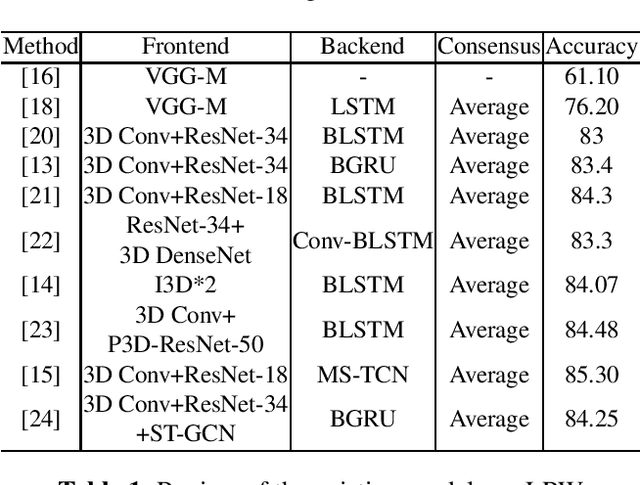
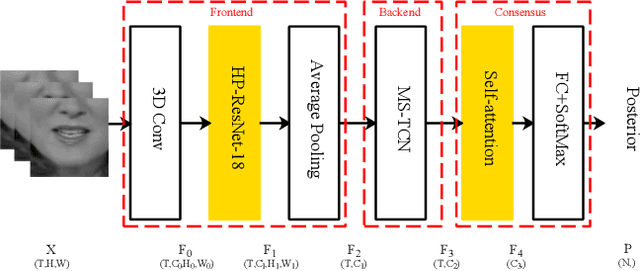
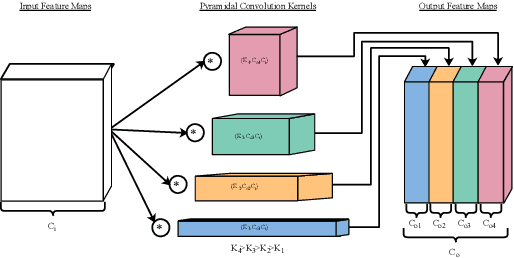
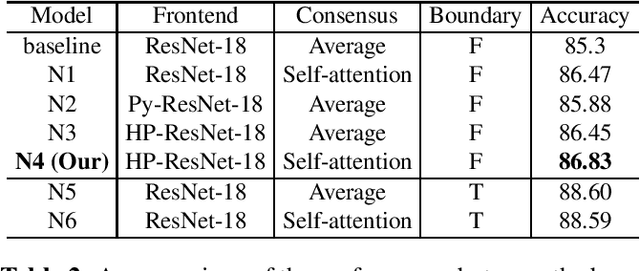
In this paper, we propose a novel deep learning architecture to improving word-level lip-reading. On the one hand, we first introduce the multi-scale processing into the spatial feature extraction for lip-reading. Specially, we proposed hierarchical pyramidal convolution (HPConv) to replace the standard convolution in original module, leading to improvements over the model's ability to discover fine-grained lip movements. On the other hand, we merge information in all time steps of the sequence by utilizing self-attention, to make the model pay more attention to the relevant frames. These two advantages are combined together to further enhance the model's classification power. Experiments on the Lip Reading in the Wild (LRW) dataset show that our proposed model has achieved 86.83% accuracy, yielding 1.53% absolute improvement over the current state-of-the-art. We also conducted extensive experiments to better understand the behavior of the proposed model.
A Two-Stage Approach to Device-Robust Acoustic Scene Classification
Nov 03, 2020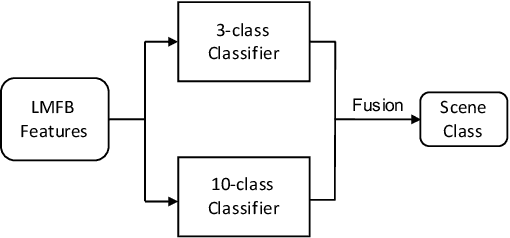

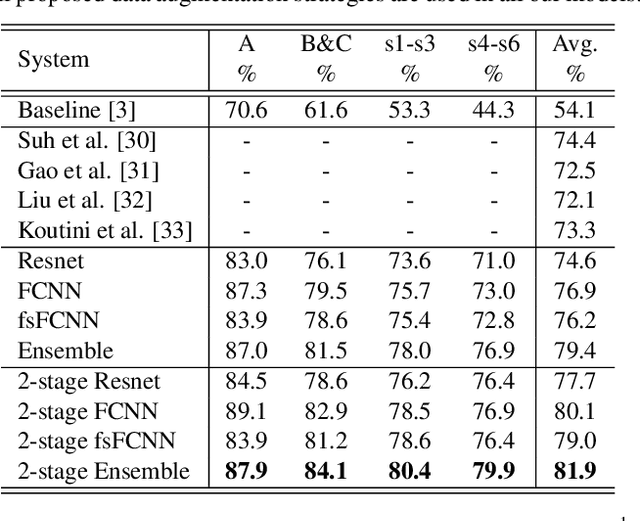
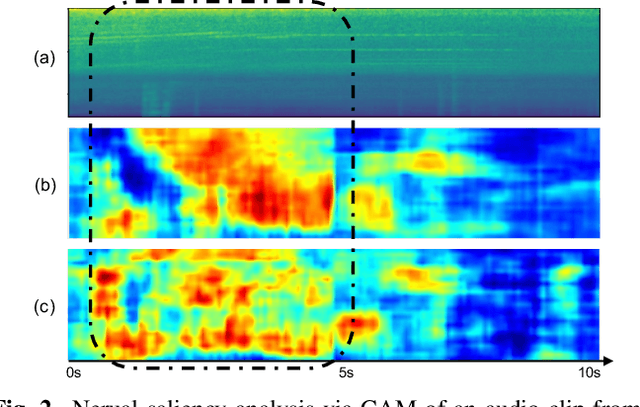
To improve device robustness, a highly desirable key feature of a competitive data-driven acoustic scene classification (ASC) system, a novel two-stage system based on fully convolutional neural networks (CNNs) is proposed. Our two-stage system leverages on an ad-hoc score combination based on two CNN classifiers: (i) the first CNN classifies acoustic inputs into one of three broad classes, and (ii) the second CNN classifies the same inputs into one of ten finer-grained classes. Three different CNN architectures are explored to implement the two-stage classifiers, and a frequency sub-sampling scheme is investigated. Moreover, novel data augmentation schemes for ASC are also investigated. Evaluated on DCASE 2020 Task 1a, our results show that the proposed ASC system attains a state-of-the-art accuracy on the development set, where our best system, a two-stage fusion of CNN ensembles, delivers a 81.9% average accuracy among multi-device test data, and it obtains a significant improvement on unseen devices. Finally, neural saliency analysis with class activation mapping (CAM) gives new insights on the patterns learnt by our models.
Decentralizing Feature Extraction with Quantum Convolutional Neural Network for Automatic Speech Recognition
Oct 26, 2020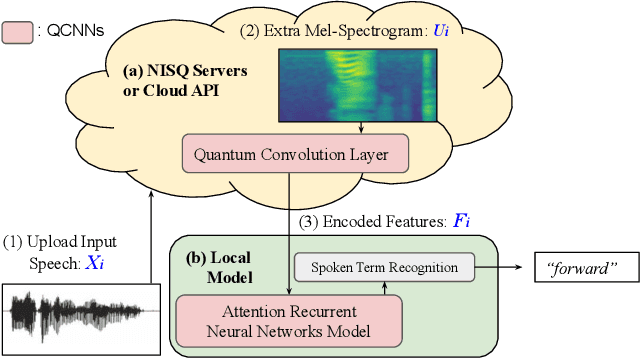

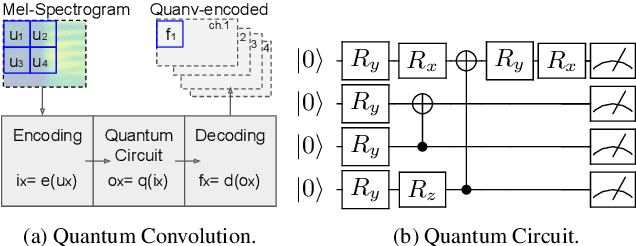
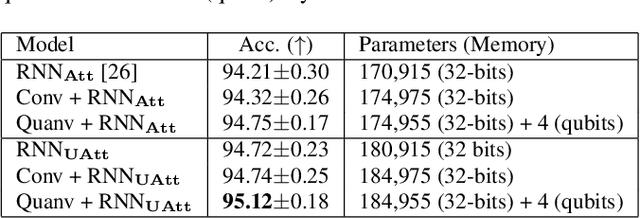
We propose a novel decentralized feature extraction approach in federated learning to address privacy-preservation issues for speech recognition. It is built upon a quantum convolutional neural network (QCNN) composed of a quantum circuit encoder for feature extraction, and a recurrent neural network (RNN) based end-to-end acoustic model (AM). To enhance model parameter protection in a decentralized architecture, an input speech is first up-streamed to a quantum computing server to extract Mel-spectrogram, and the corresponding convolutional features are encoded using a quantum circuit algorithm with random parameters. The encoded features are then down-streamed to the local RNN model for the final recognition. The proposed decentralized framework takes advantage of the quantum learning progress to secure models and to avoid privacy leakage attacks. Testing on the Google Speech Commands Dataset, the proposed QCNN encoder attains a competitive accuracy of 95.12\% in a decentralized model, which is better than the previous architectures using centralized RNN models with convolutional features. We also conduct an in-depth study of different quantum circuit encoder architectures to provide insights into designing QCNN-based feature extractors. Finally, neural saliency analyses demonstrate a high correlation between the proposed QCNN features, class activation maps, and the input Mel-spectrogram.
Correlating Subword Articulation with Lip Shapes for Embedding Aware Audio-Visual Speech Enhancement
Sep 21, 2020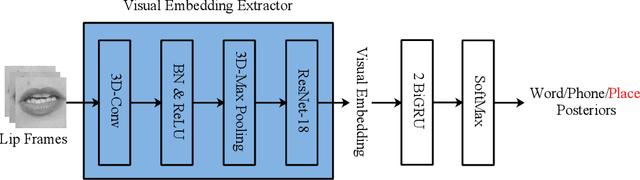
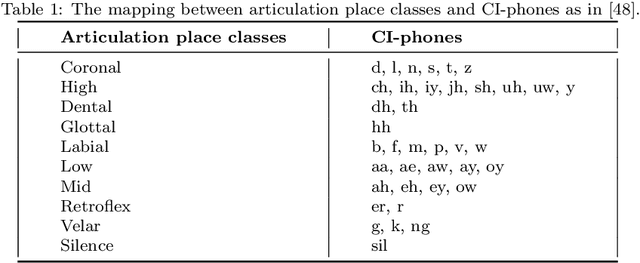

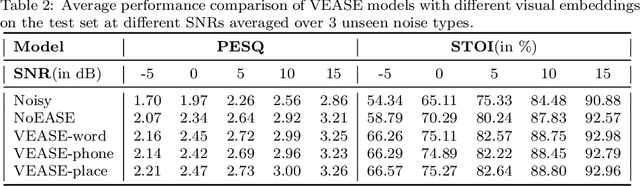
In this paper, we propose a visual embedding approach to improving embedding aware speech enhancement (EASE) by synchronizing visual lip frames at the phone and place of articulation levels. We first extract visual embedding from lip frames using a pre-trained phone or articulation place recognizer for visual-only EASE (VEASE). Next, we extract audio-visual embedding from noisy speech and lip videos in an information intersection manner, utilizing a complementarity of audio and visual features for multi-modal EASE (MEASE). Experiments on the TCD-TIMIT corpus corrupted by simulated additive noises show that our proposed subword based VEASE approach is more effective than conventional embedding at the word level. Moreover, visual embedding at the articulation place level, leveraging upon a high correlation between place of articulation and lip shapes, shows an even better performance than that at the phone level. Finally the proposed MEASE framework, incorporating both audio and visual embedding, yields significantly better speech quality and intelligibility than those obtained with the best visual-only and audio-only EASE systems.
Device-Robust Acoustic Scene Classification Based on Two-Stage Categorization and Data Augmentation
Aug 27, 2020
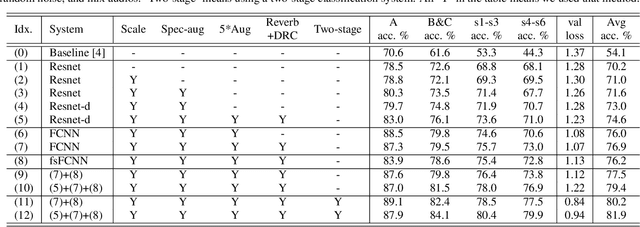
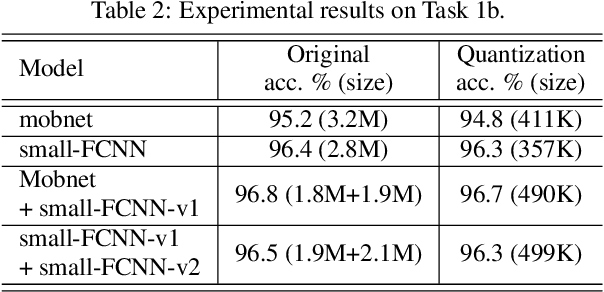
In this technical report, we present a joint effort of four groups, namely GT, USTC, Tencent, and UKE, to tackle Task 1 - Acoustic Scene Classification (ASC) in the DCASE 2020 Challenge. Task 1 comprises two different sub-tasks: (i) Task 1a focuses on ASC of audio signals recorded with multiple (real and simulated) devices into ten different fine-grained classes, and (ii) Task 1b concerns with classification of data into three higher-level classes using low-complexity solutions. For Task 1a, we propose a novel two-stage ASC system leveraging upon ad-hoc score combination of two convolutional neural networks (CNNs), classifying the acoustic input according to three classes, and then ten classes, respectively. Four different CNN-based architectures are explored to implement the two-stage classifiers, and several data augmentation techniques are also investigated. For Task 1b, we leverage upon a quantization method to reduce the complexity of two of our top-accuracy three-classes CNN-based architectures. On Task 1a development data set, an ASC accuracy of 76.9\% is attained using our best single classifier and data augmentation. An accuracy of 81.9\% is then attained by a final model fusion of our two-stage ASC classifiers. On Task 1b development data set, we achieve an accuracy of 96.7\% with a model size smaller than 500KB. Code is available: https://github.com/MihawkHu/DCASE2020_task1.
On Mean Absolute Error for Deep Neural Network Based Vector-to-Vector Regression
Aug 12, 2020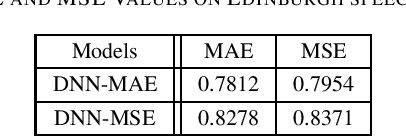
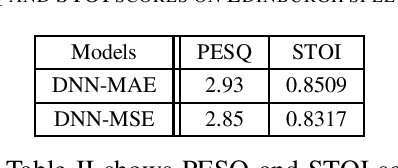
In this paper, we exploit the properties of mean absolute error (MAE) as a loss function for the deep neural network (DNN) based vector-to-vector regression. The goal of this work is two-fold: (i) presenting performance bounds of MAE, and (ii) demonstrating new properties of MAE that make it more appropriate than mean squared error (MSE) as a loss function for DNN based vector-to-vector regression. First, we show that a generalized upper-bound for DNN-based vector- to-vector regression can be ensured by leveraging the known Lipschitz continuity property of MAE. Next, we derive a new generalized upper bound in the presence of additive noise. Finally, in contrast to conventional MSE commonly adopted to approximate Gaussian errors for regression, we show that MAE can be interpreted as an error modeled by Laplacian distribution. Speech enhancement experiments are conducted to corroborate our proposed theorems and validate the performance advantages of MAE over MSE for DNN based regression.
Analyzing Upper Bounds on Mean Absolute Errors for Deep Neural Network Based Vector-to-Vector Regression
Aug 04, 2020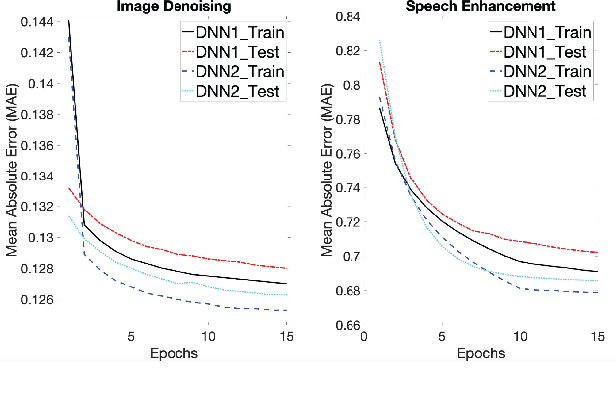
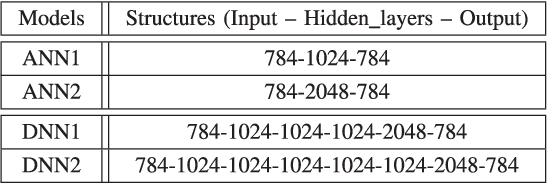
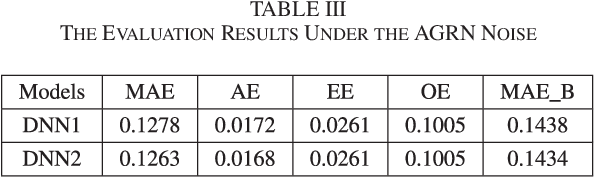

In this paper, we show that, in vector-to-vector regression utilizing deep neural networks (DNNs), a generalized loss of mean absolute error (MAE) between the predicted and expected feature vectors is upper bounded by the sum of an approximation error, an estimation error, and an optimization error. Leveraging upon error decomposition techniques in statistical learning theory and non-convex optimization theory, we derive upper bounds for each of the three aforementioned errors and impose necessary constraints on DNN models. Moreover, we assess our theoretical results through a set of image de-noising and speech enhancement experiments. Our proposed upper bounds of MAE for DNN based vector-to-vector regression are corroborated by the experimental results and the upper bounds are valid with and without the "over-parametrization" technique.
Exploring Deep Hybrid Tensor-to-Vector Network Architectures for Regression Based Speech Enhancement
Aug 03, 2020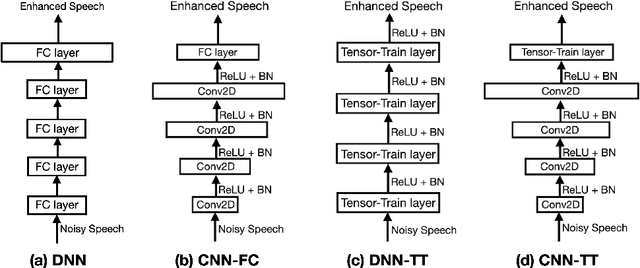
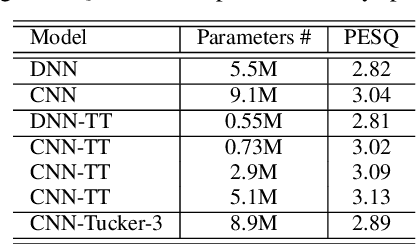
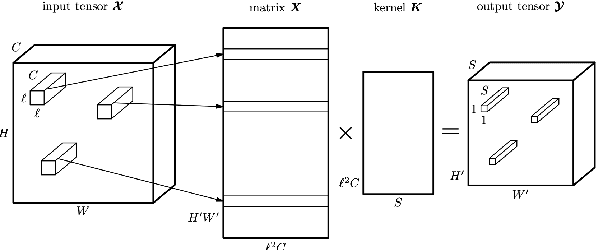
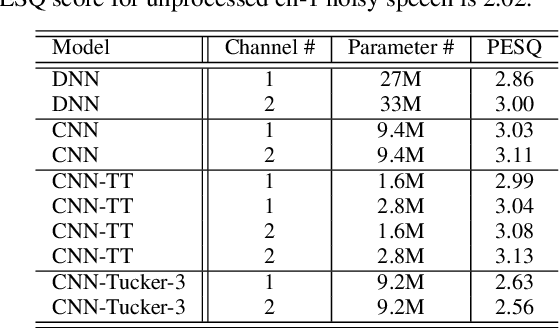
This paper investigates different trade-offs between the number of model parameters and enhanced speech qualities by employing several deep tensor-to-vector regression models for speech enhancement. We find that a hybrid architecture, namely CNN-TT, is capable of maintaining a good quality performance with a reduced model parameter size. CNN-TT is composed of several convolutional layers at the bottom for feature extraction to improve speech quality and a tensor-train (TT) output layer on the top to reduce model parameters. We first derive a new upper bound on the generalization power of the convolutional neural network (CNN) based vector-to-vector regression models. Then, we provide experimental evidence on the Edinburgh noisy speech corpus to demonstrate that, in single-channel speech enhancement, CNN outperforms DNN at the expense of a small increment of model sizes. Besides, CNN-TT slightly outperforms the CNN counterpart by utilizing only 32\% of the CNN model parameters. Besides, further performance improvement can be attained if the number of CNN-TT parameters is increased to 44\% of the CNN model size. Finally, our experiments of multi-channel speech enhancement on a simulated noisy WSJ0 corpus demonstrate that our proposed hybrid CNN-TT architecture achieves better results than both DNN and CNN models in terms of better-enhanced speech qualities and smaller parameter sizes.