 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to EdgeAn Experimental Study on Private Aggregation of Teacher Ensemble Learning for End-to-End Speech Recognition
Oct 13, 2022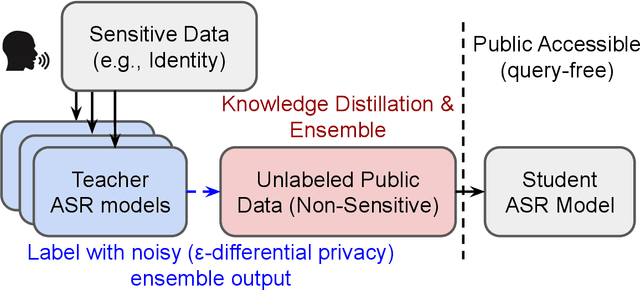
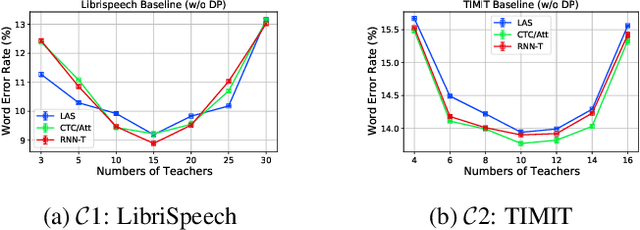
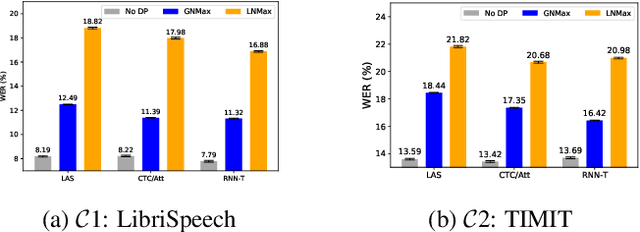
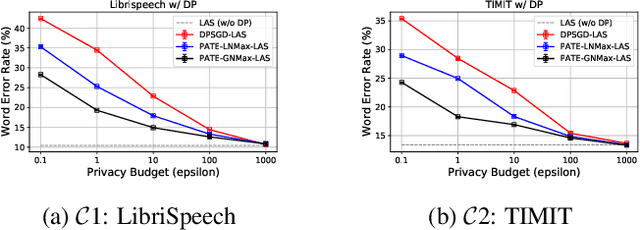
Differential privacy (DP) is one data protection avenue to safeguard user information used for training deep models by imposing noisy distortion on privacy data. Such a noise perturbation often results in a severe performance degradation in automatic speech recognition (ASR) in order to meet a privacy budget $\varepsilon$. Private aggregation of teacher ensemble (PATE) utilizes ensemble probabilities to improve ASR accuracy when dealing with the noise effects controlled by small values of $\varepsilon$. We extend PATE learning to work with dynamic patterns, namely speech utterances, and perform a first experimental demonstration that it prevents acoustic data leakage in ASR training. We evaluate three end-to-end deep models, including LAS, hybrid CTC/attention, and RNN transducer, on the open-source LibriSpeech and TIMIT corpora. PATE learning-enhanced ASR models outperform the benchmark DP-SGD mechanisms, especially under strict DP budgets, giving relative word error rate reductions between 26.2% and 27.5% for an RNN transducer model evaluated with LibriSpeech. We also introduce a DP-preserving ASR solution for pretraining on public speech corpora.
An Ensemble Teacher-Student Learning Approach with Poisson Sub-sampling to Differential Privacy Preserving Speech Recognition
Oct 12, 2022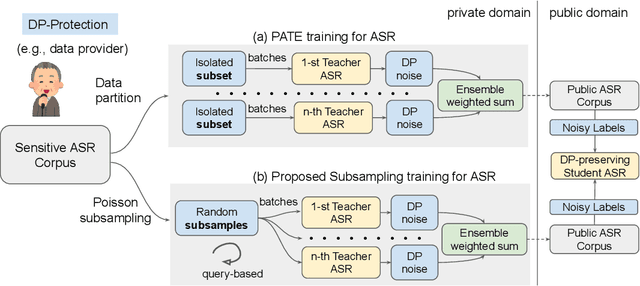


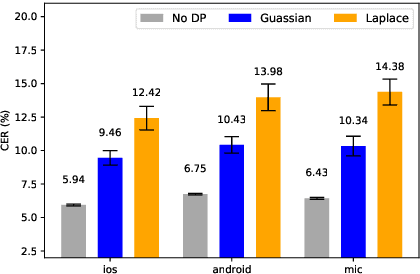
We propose an ensemble learning framework with Poisson sub-sampling to effectively train a collection of teacher models to issue some differential privacy (DP) guarantee for training data. Through boosting under DP, a student model derived from the training data suffers little model degradation from the models trained with no privacy protection. Our proposed solution leverages upon two mechanisms, namely: (i) a privacy budget amplification via Poisson sub-sampling to train a target prediction model that requires less noise to achieve a same level of privacy budget, and (ii) a combination of the sub-sampling technique and an ensemble teacher-student learning framework that introduces DP-preserving noise at the output of the teacher models and transfers DP-preserving properties via noisy labels. Privacy-preserving student models are then trained with the noisy labels to learn the knowledge with DP-protection from the teacher model ensemble. Experimental evidences on spoken command recognition and continuous speech recognition of Mandarin speech show that our proposed framework greatly outperforms existing DP-preserving algorithms in both speech processing tasks.
A study on joint modeling and data augmentation of multi-modalities for audio-visual scene classification
Mar 31, 2022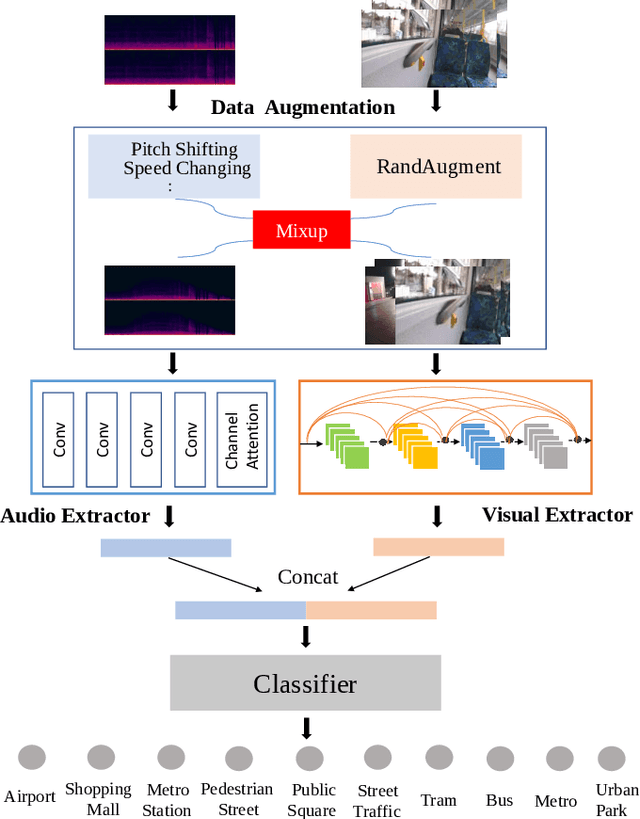
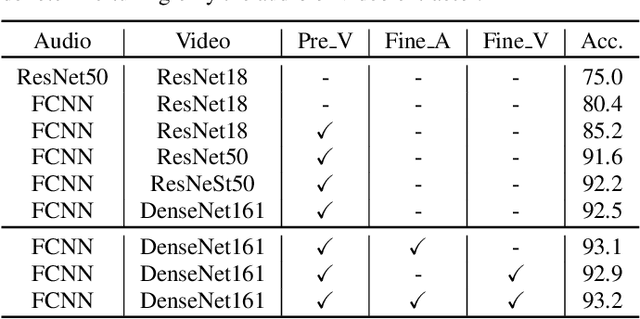
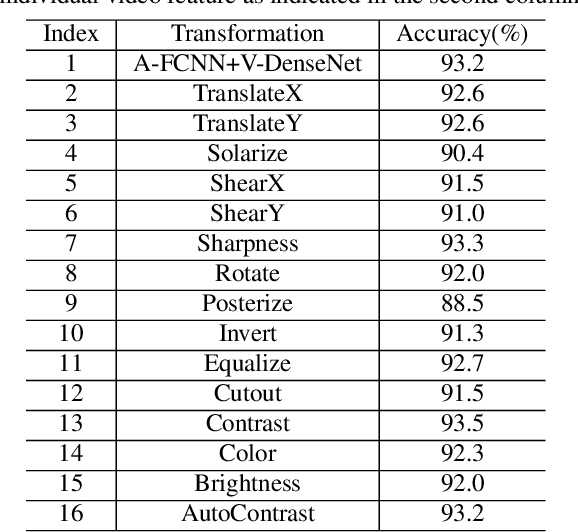
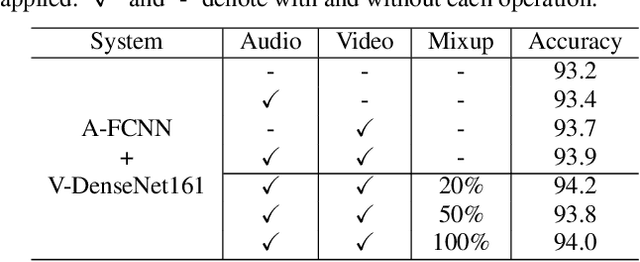
In this paper, we propose two techniques, namely joint modeling and data augmentation, to improve system performances for audio-visual scene classification (AVSC). We employ pre-trained networks trained only on image data sets to extract video embedding; whereas for audio embedding models, we decide to train them from scratch. We explore different neural network architectures for joint modeling to effectively combine the video and audio modalities. Moreover, data augmentation strategies are investigated to increase audio-visual training set size. For the video modality the effectiveness of several operations in RandAugment is verified. An audio-video joint mixup scheme is proposed to further improve AVSC performances. Evaluated on the development set of TAU Urban Audio Visual Scenes 2021, our final system can achieve the best accuracy of 94.2% among all single AVSC systems submitted to DCASE 2021 Task 1b.
A Study of Designing Compact Audio-Visual Wake Word Spotting System Based on Iterative Fine-Tuning in Neural Network Pruning
Feb 17, 2022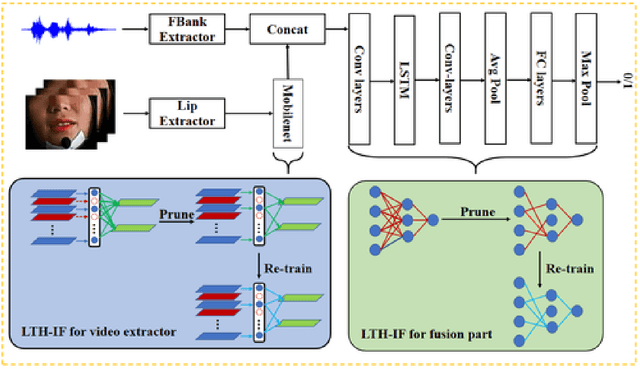
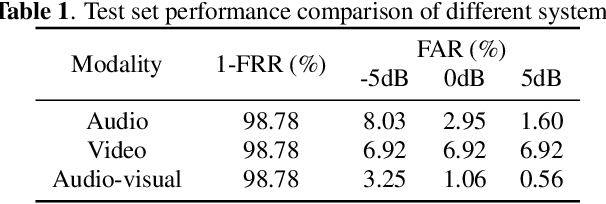
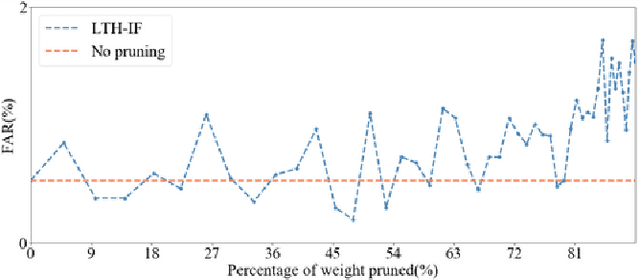
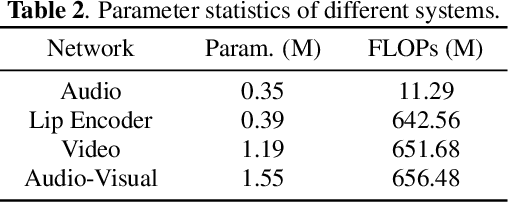
Audio-only-based wake word spotting (WWS) is challenging under noisy conditions due to environmental interference in signal transmission. In this paper, we investigate on designing a compact audio-visual WWS system by utilizing visual information to alleviate the degradation. Specifically, in order to use visual information, we first encode the detected lips to fixed-size vectors with MobileNet and concatenate them with acoustic features followed by the fusion network for WWS. However, the audio-visual model based on neural networks requires a large footprint and a high computational complexity. To meet the application requirements, we introduce a neural network pruning strategy via the lottery ticket hypothesis in an iterative fine-tuning manner (LTH-IF), to the single-modal and multi-modal models, respectively. Tested on our in-house corpus for audio-visual WWS in a home TV scene, the proposed audio-visual system achieves significant performance improvements over the single-modality (audio-only or video-only) system under different noisy conditions. Moreover, LTH-IF pruning can largely reduce the network parameters and computations with no degradation of WWS performance, leading to a potential product solution for the TV wake-up scenario.
The USTC-Ximalaya system for the ICASSP 2022 multi-channel multi-party meeting transcription challenge
Feb 10, 2022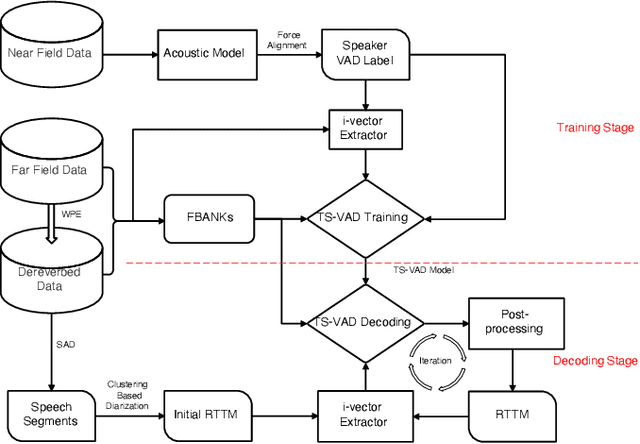
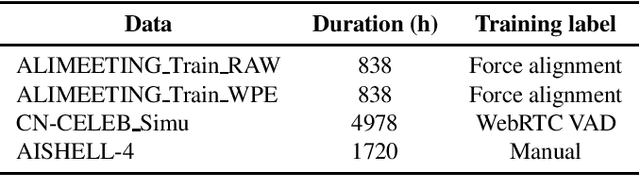
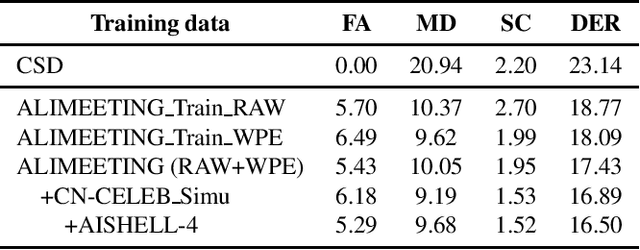
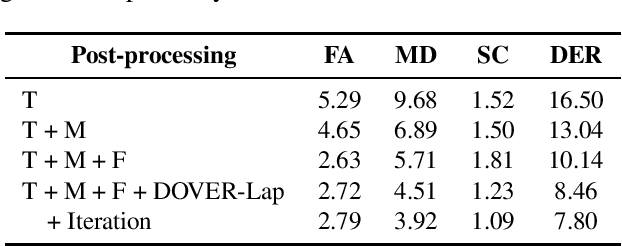
We propose two improvements to target-speaker voice activity detection (TS-VAD), the core component in our proposed speaker diarization system that was submitted to the 2022 Multi-Channel Multi-Party Meeting Transcription (M2MeT) challenge. These techniques are designed to handle multi-speaker conversations in real-world meeting scenarios with high speaker-overlap ratios and under heavy reverberant and noisy condition. First, for data preparation and augmentation in training TS-VAD models, speech data containing both real meetings and simulated indoor conversations are used. Second, in refining results obtained after TS-VAD based decoding, we perform a series of post-processing steps to improve the VAD results needed to reduce diarization error rates (DERs). Tested on the ALIMEETING corpus, the newly released Mandarin meeting dataset used in M2MeT, we demonstrate that our proposed system can decrease the DER by up to 66.55/60.59% relatively when compared with classical clustering based diarization on the Eval/Test set.
Information Fusion in Attention Networks Using Adaptive and Multi-level Factorized Bilinear Pooling for Audio-visual Emotion Recognition
Nov 17, 2021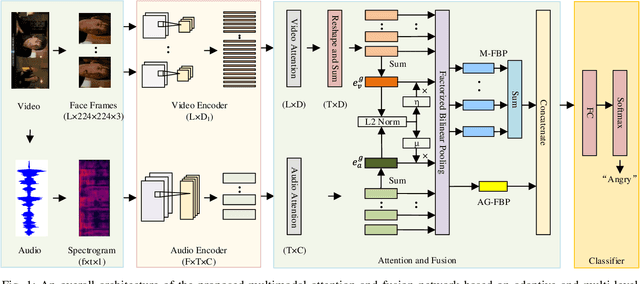
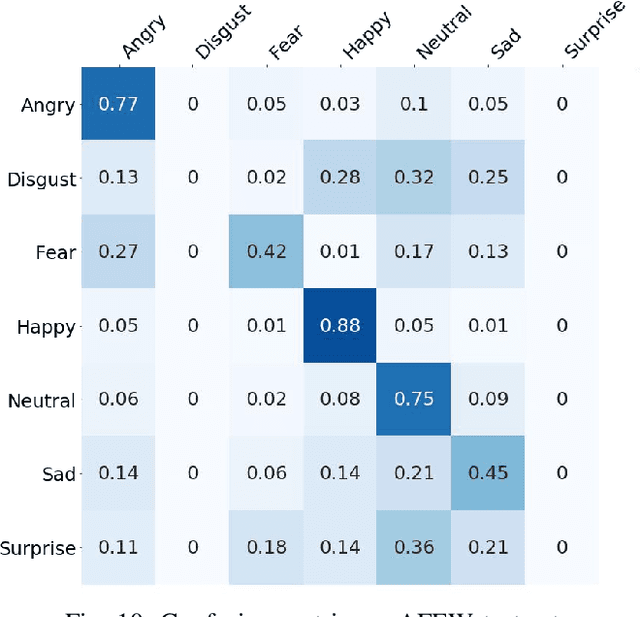
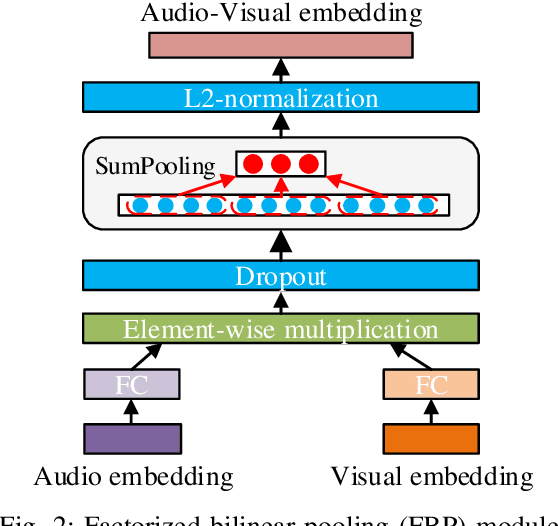

Multimodal emotion recognition is a challenging task in emotion computing as it is quite difficult to extract discriminative features to identify the subtle differences in human emotions with abstract concept and multiple expressions. Moreover, how to fully utilize both audio and visual information is still an open problem. In this paper, we propose a novel multimodal fusion attention network for audio-visual emotion recognition based on adaptive and multi-level factorized bilinear pooling (FBP). First, for the audio stream, a fully convolutional network (FCN) equipped with 1-D attention mechanism and local response normalization is designed for speech emotion recognition. Next, a global FBP (G-FBP) approach is presented to perform audio-visual information fusion by integrating selfattention based video stream with the proposed audio stream. To improve G-FBP, an adaptive strategy (AG-FBP) to dynamically calculate the fusion weight of two modalities is devised based on the emotion-related representation vectors from the attention mechanism of respective modalities. Finally, to fully utilize the local emotion information, adaptive and multi-level FBP (AMFBP) is introduced by combining both global-trunk and intratrunk data in one recording on top of AG-FBP. Tested on the IEMOCAP corpus for speech emotion recognition with only audio stream, the new FCN method outperforms the state-ofthe-art results with an accuracy of 71.40%. Moreover, validated on the AFEW database of EmotiW2019 sub-challenge and the IEMOCAP corpus for audio-visual emotion recognition, the proposed AM-FBP approach achieves the best accuracy of 63.09% and 75.49% respectively on the test set.
A Variational Bayesian Approach to Learning Latent Variables for Acoustic Knowledge Transfer
Oct 16, 2021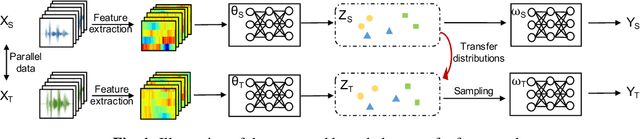
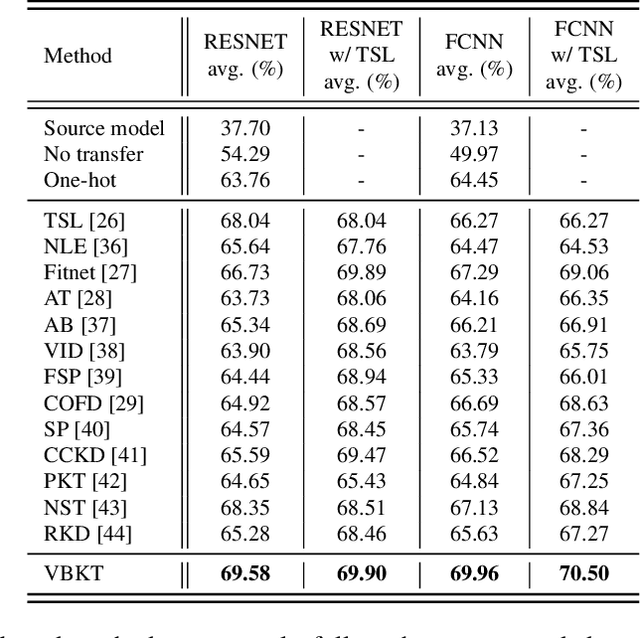
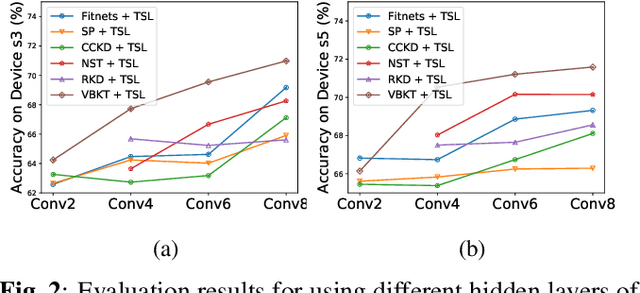
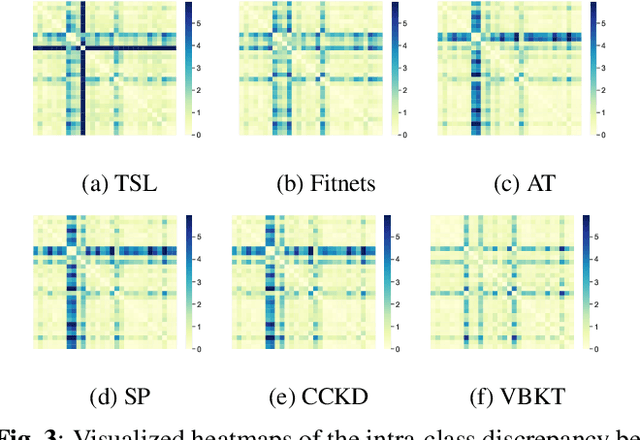
We propose a variational Bayesian (VB) approach to learning distributions of latent variables in deep neural network (DNN) models for cross-domain knowledge transfer, to address acoustic mismatches between training and testing conditions. Instead of carrying out point estimation in conventional maximum a posteriori estimation with a risk of having a curse of dimensionality in estimating a huge number of model parameters, we focus our attention on estimating a manageable number of latent variables of DNNs via a VB inference framework. To accomplish model transfer, knowledge learnt from a source domain is encoded in prior distributions of latent variables and optimally combined, in a Bayesian sense, with a small set of adaptation data from a target domain to approximate the corresponding posterior distributions. Experimental results on device adaptation in acoustic scene classification show that our proposed VB approach can obtain good improvements on target devices, and consistently outperforms 13 state-of-the-art knowledge transfer algorithms.
Separation Guided Speaker Diarization in Realistic Mismatched Conditions
Jul 06, 2021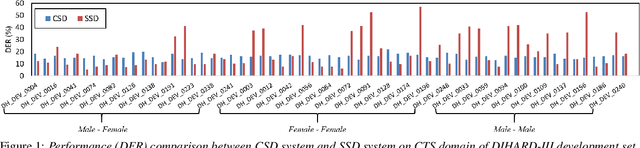
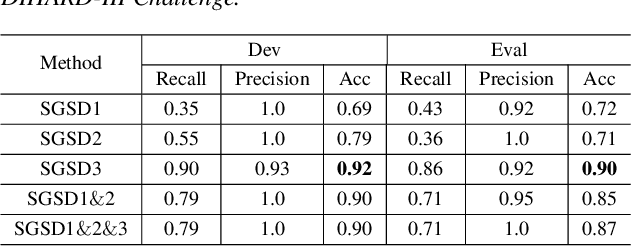
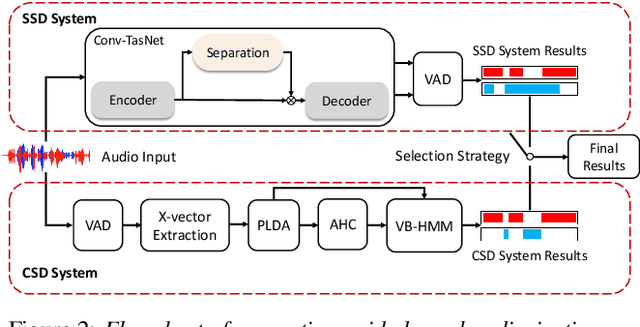
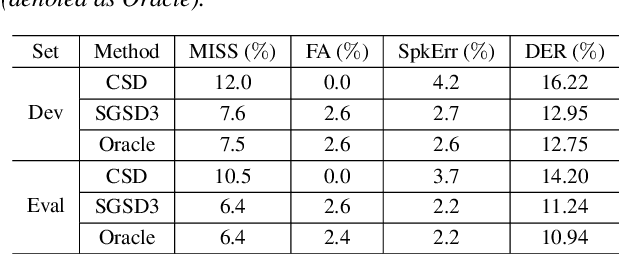
We propose a separation guided speaker diarization (SGSD) approach by fully utilizing a complementarity of speech separation and speaker clustering. Since the conventional clustering-based speaker diarization (CSD) approach cannot well handle overlapping speech segments, we investigate, in this study, separation-based speaker diarization (SSD) which inherently has the potential to handle the speaker overlap regions. Our preliminary analysis shows that the state-of-the-art Conv-TasNet based speech separation, which works quite well on the simulation data, is unstable in realistic conversational speech due to the high mismatch speaking styles in simulated training speech and read speech. In doing so, separation-based processing can assist CSD in handling the overlapping speech segments under the realistic mismatched conditions. Specifically, several strategies are designed to select between the results of SSD and CSD systems based on an analysis of the instability of the SSD system performances. Experiments on the conversational telephone speech (CTS) data from DIHARD-III Challenge show that the proposed SGSD system can significantly improve the performance of state-of-the-art CSD systems, yielding relative diarization error rate reductions of 20.2% and 20.8% on the development set and evaluation set, respectively.
A Lottery Ticket Hypothesis Framework for Low-Complexity Device-Robust Neural Acoustic Scene Classification
Jul 03, 2021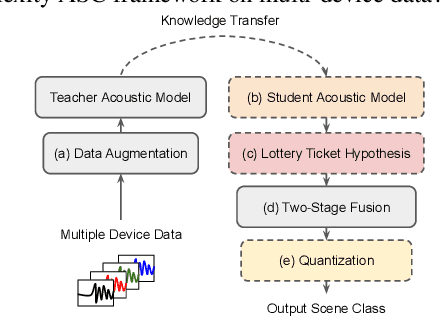
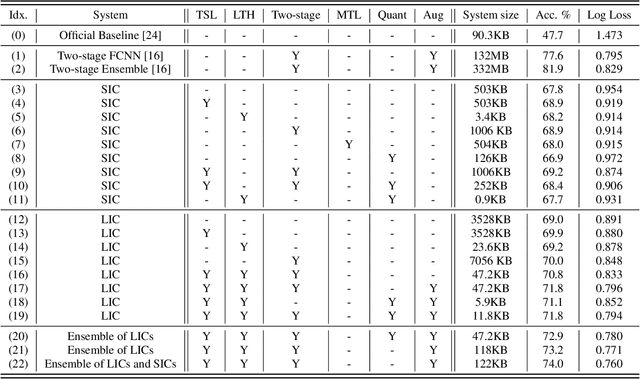
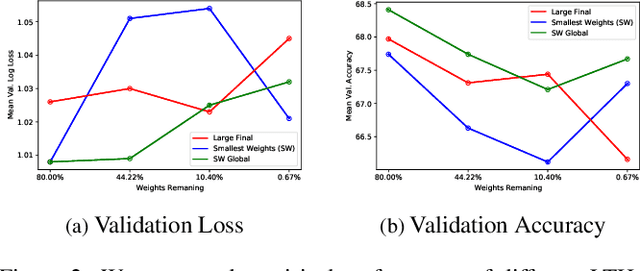

We propose a novel neural model compression strategy combining data augmentation, knowledge transfer, pruning, and quantization for device-robust acoustic scene classification (ASC). Specifically, we tackle the ASC task in a low-resource environment leveraging a recently proposed advanced neural network pruning mechanism, namely Lottery Ticket Hypothesis (LTH), to find a sub-network neural model associated with a small amount non-zero model parameters. The effectiveness of LTH for low-complexity acoustic modeling is assessed by investigating various data augmentation and compression schemes, and we report an efficient joint framework for low-complexity multi-device ASC, called Acoustic Lottery. Acoustic Lottery could compress an ASC model over $1/10^{4}$ and attain a superior performance (validation accuracy of 74.01% and Log loss of 0.76) compared to its not compressed seed model. All results reported in this work are based on a joint effort of four groups, namely GT-USTC-UKE-Tencent, aiming to address the "Low-Complexity Acoustic Scene Classification (ASC) with Multiple Devices" in the DCASE 2021 Challenge Task 1a.
* 5 figures. DCASE 2021. The project started in November 2020
PATE-AAE: Incorporating Adversarial Autoencoder into Private Aggregation of Teacher Ensembles for Spoken Command Classification
Apr 02, 2021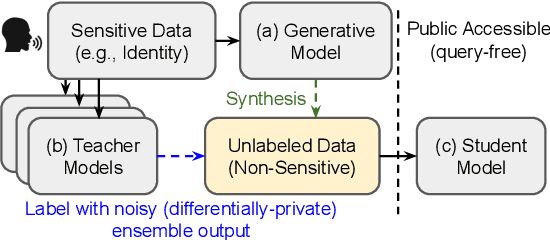
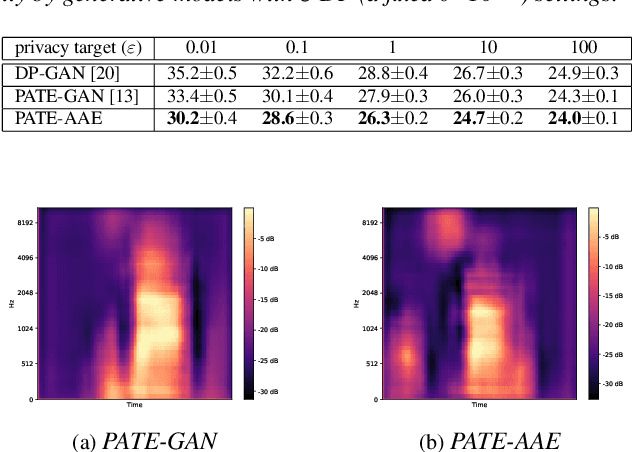
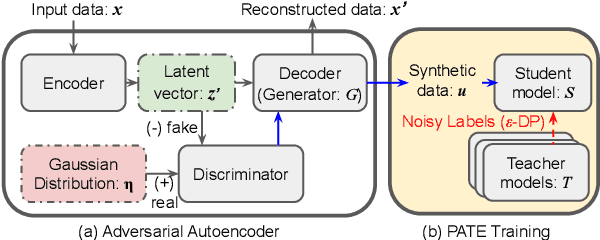
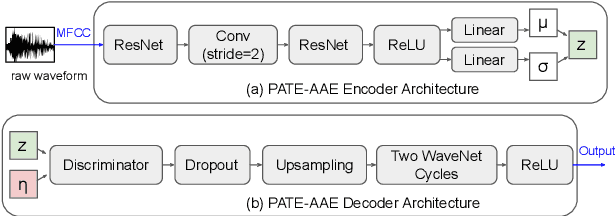
We propose using an adversarial autoencoder (AAE) to replace generative adversarial network (GAN) in the private aggregation of teacher ensembles (PATE), a solution for ensuring differential privacy in speech applications. The AAE architecture allows us to obtain good synthetic speech leveraging upon a discriminative training of latent vectors. Such synthetic speech is used to build a privacy-preserving classifier when non-sensitive data is not sufficiently available in the public domain. This classifier follows the PATE scheme that uses an ensemble of noisy outputs to label the synthetic samples and guarantee $\varepsilon$-differential privacy (DP) on its derived classifiers. Our proposed framework thus consists of an AAE-based generator and a PATE-based classifier (PATE-AAE). Evaluated on the Google Speech Commands Dataset Version II, the proposed PATE-AAE improves the average classification accuracy by +$2.11\%$ and +$6.60\%$, respectively, when compared with alternative privacy-preserving solutions, namely PATE-GAN and DP-GAN, while maintaining a strong level of privacy target at $\varepsilon$=0.01 with a fixed $\delta$=10$^{-5}$.