 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to EdgeGrounded Compositional and Diverse Text-to-3D with Pretrained Multi-View Diffusion Model
Apr 28, 2024



In this paper, we propose an effective two-stage approach named Grounded-Dreamer to generate 3D assets that can accurately follow complex, compositional text prompts while achieving high fidelity by using a pre-trained multi-view diffusion model. Multi-view diffusion models, such as MVDream, have shown to generate high-fidelity 3D assets using score distillation sampling (SDS). However, applied naively, these methods often fail to comprehend compositional text prompts, and may often entirely omit certain subjects or parts. To address this issue, we first advocate leveraging text-guided 4-view images as the bottleneck in the text-to-3D pipeline. We then introduce an attention refocusing mechanism to encourage text-aligned 4-view image generation, without the necessity to re-train the multi-view diffusion model or craft a high-quality compositional 3D dataset. We further propose a hybrid optimization strategy to encourage synergy between the SDS loss and the sparse RGB reference images. Our method consistently outperforms previous state-of-the-art (SOTA) methods in generating compositional 3D assets, excelling in both quality and accuracy, and enabling diverse 3D from the same text prompt.
A Quantitative Evaluation of Score Distillation Sampling Based Text-to-3D
Feb 29, 2024The development of generative models that create 3D content from a text prompt has made considerable strides thanks to the use of the score distillation sampling (SDS) method on pre-trained diffusion models for image generation. However, the SDS method is also the source of several artifacts, such as the Janus problem, the misalignment between the text prompt and the generated 3D model, and 3D model inaccuracies. While existing methods heavily rely on the qualitative assessment of these artifacts through visual inspection of a limited set of samples, in this work we propose more objective quantitative evaluation metrics, which we cross-validate via human ratings, and show analysis of the failure cases of the SDS technique. We demonstrate the effectiveness of this analysis by designing a novel computationally efficient baseline model that achieves state-of-the-art performance on the proposed metrics while addressing all the above-mentioned artifacts.
Towards Visual Foundational Models of Physical Scenes
Jun 06, 2023



We describe a first step towards learning general-purpose visual representations of physical scenes using only image prediction as a training criterion. To do so, we first define "physical scene" and show that, even though different agents may maintain different representations of the same scene, the underlying physical scene that can be inferred is unique. Then, we show that NeRFs cannot represent the physical scene, as they lack extrapolation mechanisms. Those, however, could be provided by Diffusion Models, at least in theory. To test this hypothesis empirically, NeRFs can be combined with Diffusion Models, a process we refer to as NeRF Diffusion, used as unsupervised representations of the physical scene. Our analysis is limited to visual data, without external grounding mechanisms that can be provided by independent sensory modalities.
Event-based Moving Object Detection and Tracking
Jul 23, 2018
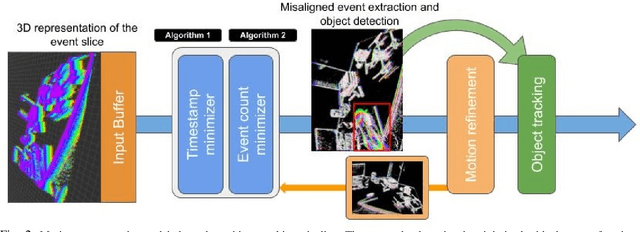


Event-based vision sensors, such as the Dynamic Vision Sensor (DVS), are ideally suited for real-time motion analysis. The unique properties encompassed in the readings of such sensors provide high temporal resolution, superior sensitivity to light and low latency. These properties provide the grounds to estimate motion extremely reliably in the most sophisticated scenarios but they come at a price - modern event-based vision sensors have extremely low resolution and produce a lot of noise. Moreover, the asynchronous nature of the event stream calls for novel algorithms. This paper presents a new, efficient approach to object tracking with asynchronous cameras. We present a novel event stream representation which enables us to utilize information about the dynamic (temporal) component of the event stream, and not only the spatial component, at every moment of time. This is done by approximating the 3D geometry of the event stream with a parametric model; as a result, the algorithm is capable of producing the motion-compensated event stream (effectively approximating egomotion), and without using any form of external sensors in extremely low-light and noisy conditions without any form of feature tracking or explicit optical flow computation. We demonstrate our framework on the task of independent motion detection and tracking, where we use the temporal model inconsistencies to locate differently moving objects in challenging situations of very fast motion.