 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to EdgeOn the Role of Long-tail Knowledge in Retrieval Augmented Large Language Models
Jun 24, 2024



Retrieval augmented generation (RAG) exhibits outstanding performance in promoting the knowledge capabilities of large language models (LLMs) with retrieved documents related to user queries. However, RAG only focuses on improving the response quality of LLMs via enhancing queries indiscriminately with retrieved information, paying little attention to what type of knowledge LLMs really need to answer original queries more accurately. In this paper, we suggest that long-tail knowledge is crucial for RAG as LLMs have already remembered common world knowledge during large-scale pre-training. Based on our observation, we propose a simple but effective long-tail knowledge detection method for LLMs. Specifically, the novel Generative Expected Calibration Error (GECE) metric is derived to measure the ``long-tailness'' of knowledge based on both statistics and semantics. Hence, we retrieve relevant documents and infuse them into the model for patching knowledge loopholes only when the input query relates to long-tail knowledge. Experiments show that, compared to existing RAG pipelines, our method achieves over 4x speedup in average inference time and consistent performance improvement in downstream tasks.
UniPSDA: Unsupervised Pseudo Semantic Data Augmentation for Zero-Shot Cross-Lingual Natural Language Understanding
Jun 24, 2024



Cross-lingual representation learning transfers knowledge from resource-rich data to resource-scarce ones to improve the semantic understanding abilities of different languages. However, previous works rely on shallow unsupervised data generated by token surface matching, regardless of the global context-aware semantics of the surrounding text tokens. In this paper, we propose an Unsupervised Pseudo Semantic Data Augmentation (UniPSDA) mechanism for cross-lingual natural language understanding to enrich the training data without human interventions. Specifically, to retrieve the tokens with similar meanings for the semantic data augmentation across different languages, we propose a sequential clustering process in 3 stages: within a single language, across multiple languages of a language family, and across languages from multiple language families. Meanwhile, considering the multi-lingual knowledge infusion with context-aware semantics while alleviating computation burden, we directly replace the key constituents of the sentences with the above-learned multi-lingual family knowledge, viewed as pseudo-semantic. The infusion process is further optimized via three de-biasing techniques without introducing any neural parameters. Extensive experiments demonstrate that our model consistently improves the performance on general zero-shot cross-lingual natural language understanding tasks, including sequence classification, information extraction, and question answering.
KEHRL: Learning Knowledge-Enhanced Language Representations with Hierarchical Reinforcement Learning
Jun 24, 2024



Knowledge-enhanced pre-trained language models (KEPLMs) leverage relation triples from knowledge graphs (KGs) and integrate these external data sources into language models via self-supervised learning. Previous works treat knowledge enhancement as two independent operations, i.e., knowledge injection and knowledge integration. In this paper, we propose to learn Knowledge-Enhanced language representations with Hierarchical Reinforcement Learning (KEHRL), which jointly addresses the problems of detecting positions for knowledge injection and integrating external knowledge into the model in order to avoid injecting inaccurate or irrelevant knowledge. Specifically, a high-level reinforcement learning (RL) agent utilizes both internal and prior knowledge to iteratively detect essential positions in texts for knowledge injection, which filters out less meaningful entities to avoid diverting the knowledge learning direction. Once the entity positions are selected, a relevant triple filtration module is triggered to perform low-level RL to dynamically refine the triples associated with polysemic entities through binary-valued actions. Experiments validate KEHRL's effectiveness in probing factual knowledge and enhancing the model's performance on various natural language understanding tasks.
DAFNet: Dynamic Auxiliary Fusion for Sequential Model Editing in Large Language Models
May 31, 2024



Recently, while large language models (LLMs) have demonstrated impressive results, they still suffer from hallucination, i.e., the generation of false information. Model editing is the task of fixing factual mistakes in LLMs; yet, most previous works treat it as a one-time task, paying little attention to ever-emerging mistakes generated by LLMs. We address the task of sequential model editing (SME) that aims to rectify mistakes continuously. A Dynamic Auxiliary Fusion Network (DAFNet) is designed to enhance the semantic interaction among the factual knowledge within the entire sequence, preventing catastrophic forgetting during the editing process of multiple knowledge triples. Specifically, (1) for semantic fusion within a relation triple, we aggregate the intra-editing attention flow into auto-regressive self-attention with token-level granularity in LLMs. We further leverage multi-layer diagonal inter-editing attention flow to update the weighted representations of the entire sequence-level granularity. (2) Considering that auxiliary parameters are required to store the knowledge for sequential editing, we construct a new dataset named \textbf{DAFSet}, fulfilling recent, popular, long-tail and robust properties to enhance the generality of sequential editing. Experiments show DAFNet significantly outperforms strong baselines in single-turn and sequential editing. The usage of DAFSet also consistently improves the performance of other auxiliary network-based methods in various scenarios
PTA: Enhancing Multimodal Sentiment Analysis through Pipelined Prediction and Translation-based Alignment
May 23, 2024



Multimodal aspect-based sentiment analysis (MABSA) aims to understand opinions in a granular manner, advancing human-computer interaction and other fields. Traditionally, MABSA methods use a joint prediction approach to identify aspects and sentiments simultaneously. However, we argue that joint models are not always superior. Our analysis shows that joint models struggle to align relevant text tokens with image patches, leading to misalignment and ineffective image utilization. In contrast, a pipeline framework first identifies aspects through MATE (Multimodal Aspect Term Extraction) and then aligns these aspects with image patches for sentiment classification (MASC: Multimodal Aspect-Oriented Sentiment Classification). This method is better suited for multimodal scenarios where effective image use is crucial. We present three key observations: (a) MATE and MASC have different feature requirements, with MATE focusing on token-level features and MASC on sequence-level features; (b) the aspect identified by MATE is crucial for effective image utilization; and (c) images play a trivial role in previous MABSA methods due to high noise. Based on these observations, we propose a pipeline framework that first predicts the aspect and then uses translation-based alignment (TBA) to enhance multimodal semantic consistency for better image utilization. Our method achieves state-of-the-art (SOTA) performance on widely used MABSA datasets Twitter-15 and Twitter-17. This demonstrates the effectiveness of the pipeline approach and its potential to provide valuable insights for future MABSA research. For reproducibility, the code and checkpoint will be released.
Distilling Instruction-following Abilities of Large Language Models with Task-aware Curriculum Planning
May 22, 2024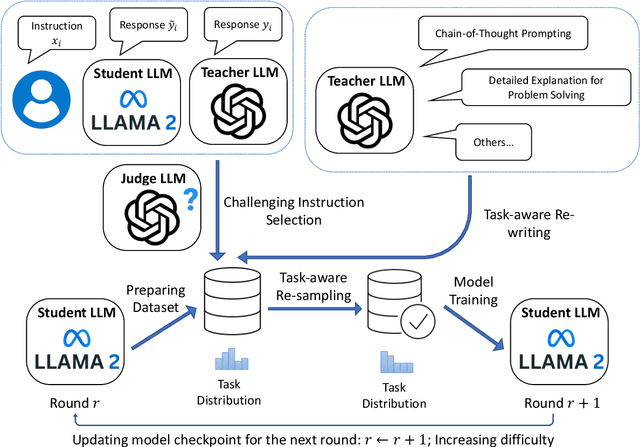

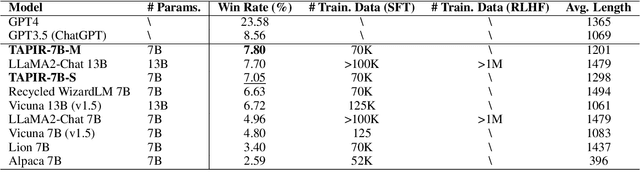
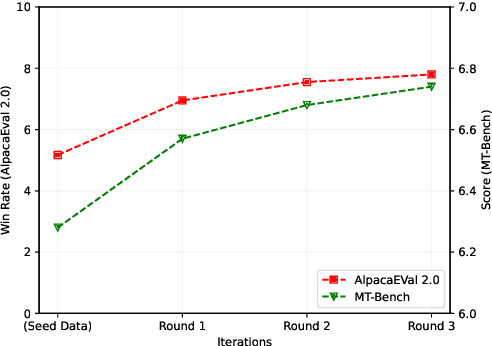
The process of instruction tuning aligns pre-trained large language models (LLMs) with open-domain instructions and human-preferred responses. While several studies have explored autonomous approaches to distilling and annotating instructions from more powerful proprietary LLMs, such as ChatGPT, they often neglect the impact of task distributions and the varying difficulty of instructions of the training sets. This oversight can lead to imbalanced knowledge capabilities and poor generalization powers of small student LLMs. To address this challenge, we introduce Task-Aware Curriculum Planning for Instruction Refinement (TAPIR), a multi-round distillation framework with balanced task distributions and dynamic difficulty adjustment. This approach utilizes an oracle LLM to select instructions that are difficult for a student LLM to follow and distill instructions with balanced task distributions. By incorporating curriculum planning, our approach systematically escalates the difficulty levels, progressively enhancing the student LLM's capabilities. We rigorously evaluate TAPIR using two widely recognized benchmarks, including AlpacaEval 2.0 and MT-Bench. The empirical results demonstrate that the student LLMs, trained with our method and less training data, outperform larger instruction-tuned models and strong distillation baselines. The improvement is particularly notable in complex tasks, such as logical reasoning and code generation.
Lifelong Knowledge Editing for LLMs with Retrieval-Augmented Continuous Prompt Learning
May 08, 2024



Model editing aims to correct outdated or erroneous knowledge in large language models (LLMs) without the need for costly retraining. Lifelong model editing is the most challenging task that caters to the continuous editing requirements of LLMs. Prior works primarily focus on single or batch editing; nevertheless, these methods fall short in lifelong editing scenarios due to catastrophic knowledge forgetting and the degradation of model performance. Although retrieval-based methods alleviate these issues, they are impeded by slow and cumbersome processes of integrating the retrieved knowledge into the model. In this work, we introduce RECIPE, a RetriEval-augmented ContInuous Prompt lEarning method, to boost editing efficacy and inference efficiency in lifelong learning. RECIPE first converts knowledge statements into short and informative continuous prompts, prefixed to the LLM's input query embedding, to efficiently refine the response grounded on the knowledge. It further integrates the Knowledge Sentinel (KS) that acts as an intermediary to calculate a dynamic threshold, determining whether the retrieval repository contains relevant knowledge. Our retriever and prompt encoder are jointly trained to achieve editing properties, i.e., reliability, generality, and locality. In our experiments, RECIPE is assessed extensively across multiple LLMs and editing datasets, where it achieves superior editing performance. RECIPE also demonstrates its capability to maintain the overall performance of LLMs alongside showcasing fast editing and inference speed.
R4: Reinforced Retriever-Reorder-Responder for Retrieval-Augmented Large Language Models
May 04, 2024Retrieval-augmented large language models (LLMs) leverage relevant content retrieved by information retrieval systems to generate correct responses, aiming to alleviate the hallucination problem. However, existing retriever-responder methods typically append relevant documents to the prompt of LLMs to perform text generation tasks without considering the interaction of fine-grained structural semantics between the retrieved documents and the LLMs. This issue is particularly important for accurate response generation as LLMs tend to ``lose in the middle'' when dealing with input prompts augmented with lengthy documents. In this work, we propose a new pipeline named ``Reinforced Retriever-Reorder-Responder'' (R$^4$) to learn document orderings for retrieval-augmented LLMs, thereby further enhancing their generation abilities while the large numbers of parameters of LLMs remain frozen. The reordering learning process is divided into two steps according to the quality of the generated responses: document order adjustment and document representation enhancement. Specifically, document order adjustment aims to organize retrieved document orderings into beginning, middle, and end positions based on graph attention learning, which maximizes the reinforced reward of response quality. Document representation enhancement further refines the representations of retrieved documents for responses of poor quality via document-level gradient adversarial learning. Extensive experiments demonstrate that our proposed pipeline achieves better factual question-answering performance on knowledge-intensive tasks compared to strong baselines across various public datasets. The source codes and trained models will be released upon paper acceptance.
DWE+: Dual-Way Matching Enhanced Framework for Multimodal Entity Linking
Apr 07, 2024Multimodal entity linking (MEL) aims to utilize multimodal information (usually textual and visual information) to link ambiguous mentions to unambiguous entities in knowledge base. Current methods facing main issues: (1)treating the entire image as input may contain redundant information. (2)the insufficient utilization of entity-related information, such as attributes in images. (3)semantic inconsistency between the entity in knowledge base and its representation. To this end, we propose DWE+ for multimodal entity linking. DWE+ could capture finer semantics and dynamically maintain semantic consistency with entities. This is achieved by three aspects: (a)we introduce a method for extracting fine-grained image features by partitioning the image into multiple local objects. Then, hierarchical contrastive learning is used to further align semantics between coarse-grained information(text and image) and fine-grained (mention and visual objects). (b)we explore ways to extract visual attributes from images to enhance fusion feature such as facial features and identity. (c)we leverage Wikipedia and ChatGPT to capture the entity representation, achieving semantic enrichment from both static and dynamic perspectives, which better reflects the real-world entity semantics. Experiments on Wikimel, Richpedia, and Wikidiverse datasets demonstrate the effectiveness of DWE+ in improving MEL performance. Specifically, we optimize these datasets and achieve state-of-the-art performance on the enhanced datasets. The code and enhanced datasets are released on https://github.com/season1blue/DWET
TRELM: Towards Robust and Efficient Pre-training for Knowledge-Enhanced Language Models
Mar 17, 2024



KEPLMs are pre-trained models that utilize external knowledge to enhance language understanding. Previous language models facilitated knowledge acquisition by incorporating knowledge-related pre-training tasks learned from relation triples in knowledge graphs. However, these models do not prioritize learning embeddings for entity-related tokens. Moreover, updating the entire set of parameters in KEPLMs is computationally demanding. This paper introduces TRELM, a Robust and Efficient Pre-training framework for Knowledge-Enhanced Language Models. We observe that entities in text corpora usually follow the long-tail distribution, where the representations of some entities are suboptimally optimized and hinder the pre-training process for KEPLMs. To tackle this, we employ a robust approach to inject knowledge triples and employ a knowledge-augmented memory bank to capture valuable information. Furthermore, updating a small subset of neurons in the feed-forward networks (FFNs) that store factual knowledge is both sufficient and efficient. Specifically, we utilize dynamic knowledge routing to identify knowledge paths in FFNs and selectively update parameters during pre-training. Experimental results show that TRELM reduces pre-training time by at least 50% and outperforms other KEPLMs in knowledge probing tasks and multiple knowledge-aware language understanding tasks.