 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to EdgeGarment Avatars: Realistic Cloth Driving using Pattern Registration
Jun 07, 2022

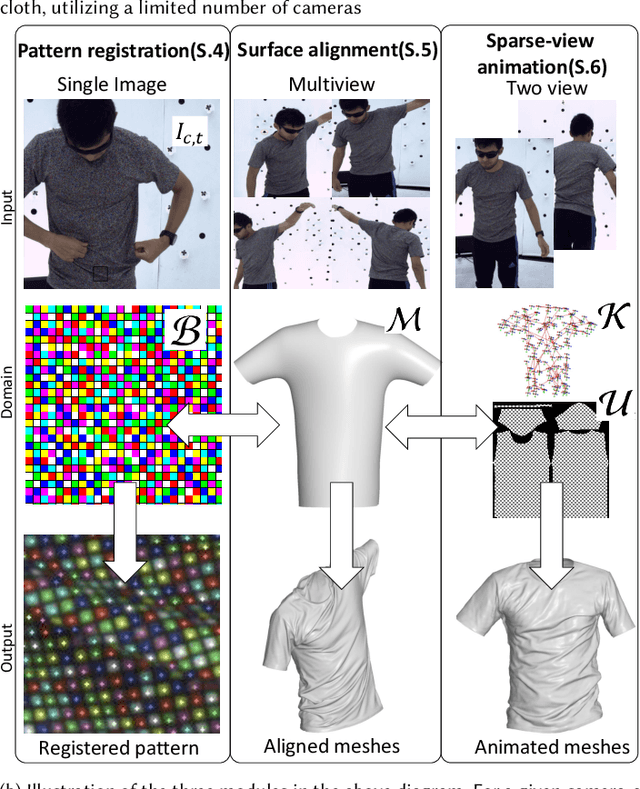

Virtual telepresence is the future of online communication. Clothing is an essential part of a person's identity and self-expression. Yet, ground truth data of registered clothes is currently unavailable in the required resolution and accuracy for training telepresence models for realistic cloth animation. Here, we propose an end-to-end pipeline for building drivable representations for clothing. The core of our approach is a multi-view patterned cloth tracking algorithm capable of capturing deformations with high accuracy. We further rely on the high-quality data produced by our tracking method to build a Garment Avatar: an expressive and fully-drivable geometry model for a piece of clothing. The resulting model can be animated using a sparse set of views and produces highly realistic reconstructions which are faithful to the driving signals. We demonstrate the efficacy of our pipeline on a realistic virtual telepresence application, where a garment is being reconstructed from two views, and a user can pick and swap garment design as they wish. In addition, we show a challenging scenario when driven exclusively with body pose, our drivable garment avatar is capable of producing realistic cloth geometry of significantly higher quality than the state-of-the-art.
Explicit Clothing Modeling for an Animatable Full-Body Avatar
Jun 30, 2021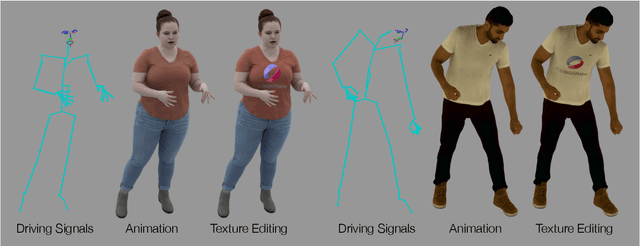
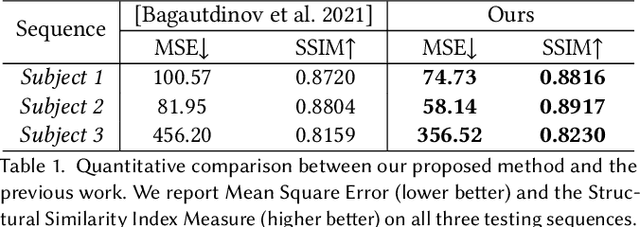

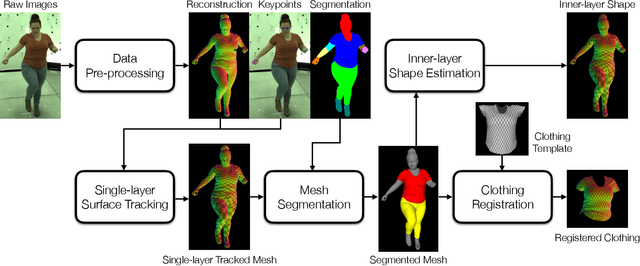
Recent work has shown great progress in building photorealistic animatable full-body codec avatars, but these avatars still face difficulties in generating high-fidelity animation of clothing. To address the difficulties, we propose a method to build an animatable clothed body avatar with an explicit representation of the clothing on the upper body from multi-view captured videos. We use a two-layer mesh representation to separately register the 3D scans with templates. In order to improve the photometric correspondence across different frames, texture alignment is then performed through inverse rendering of the clothing geometry and texture predicted by a variational autoencoder. We then train a new two-layer codec avatar with separate modeling of the upper clothing and the inner body layer. To learn the interaction between the body dynamics and clothing states, we use a temporal convolution network to predict the clothing latent code based on a sequence of input skeletal poses. We show photorealistic animation output for three different actors, and demonstrate the advantage of our clothed-body avatars over single-layer avatars in the previous work. We also show the benefit of an explicit clothing model which allows the clothing texture to be edited in the animation output.
Driving-Signal Aware Full-Body Avatars
May 21, 2021
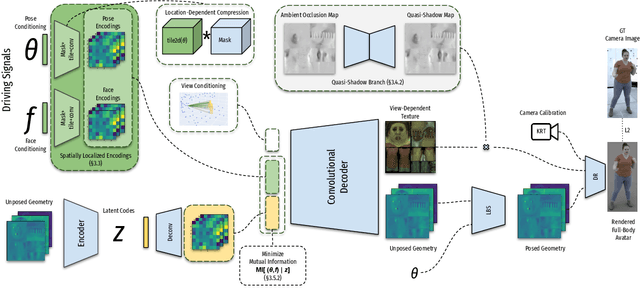
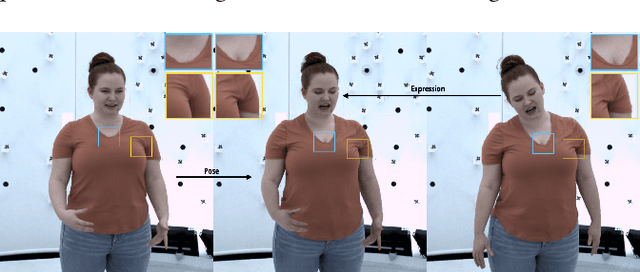
We present a learning-based method for building driving-signal aware full-body avatars. Our model is a conditional variational autoencoder that can be animated with incomplete driving signals, such as human pose and facial keypoints, and produces a high-quality representation of human geometry and view-dependent appearance. The core intuition behind our method is that better drivability and generalization can be achieved by disentangling the driving signals and remaining generative factors, which are not available during animation. To this end, we explicitly account for information deficiency in the driving signal by introducing a latent space that exclusively captures the remaining information, thus enabling the imputation of the missing factors required during full-body animation, while remaining faithful to the driving signal. We also propose a learnable localized compression for the driving signal which promotes better generalization, and helps minimize the influence of global chance-correlations often found in real datasets. For a given driving signal, the resulting variational model produces a compact space of uncertainty for missing factors that allows for an imputation strategy best suited to a particular application. We demonstrate the efficacy of our approach on the challenging problem of full-body animation for virtual telepresence with driving signals acquired from minimal sensors placed in the environment and mounted on a VR-headset.
MonoClothCap: Towards Temporally Coherent Clothing Capture from Monocular RGB Video
Sep 22, 2020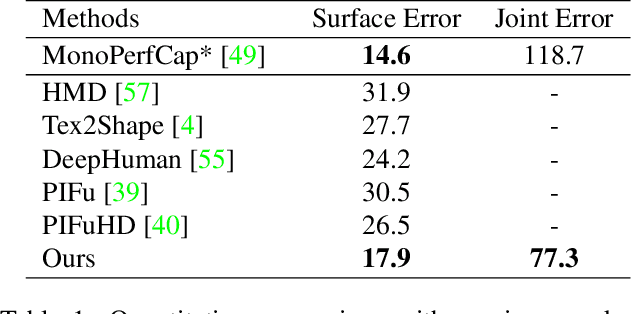
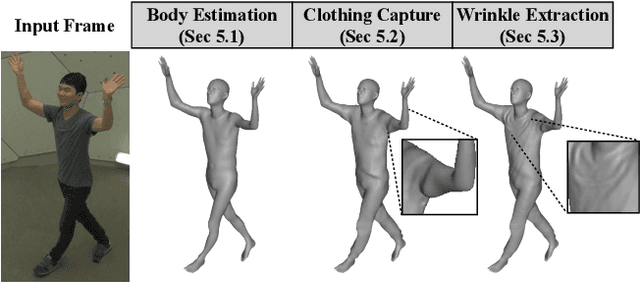
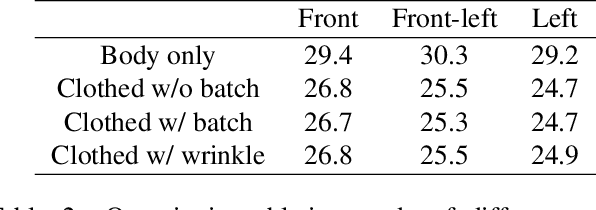
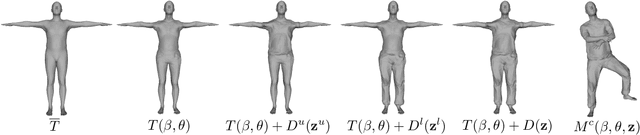
We present a method to capture temporally coherent dynamic clothing deformation from a monocular RGB video input. In contrast to the existing literature, our method does not require a pre-scanned personalized mesh template, and thus can be applied to in-the-wild videos. To constrain the output to a valid deformation space, we build statistical deformation models for three types of clothing: T-shirt, short pants and long pants. A differentiable renderer is utilized to align our captured shapes to the input frames by minimizing the difference in both silhouette and texture. We develop a UV texture growing method which expands the visible texture region of the clothing sequentially in order to minimize drift in deformation tracking. We also extract fine-grained wrinkle detail from the input videos by fitting the clothed surface to the normal maps estimated by a convolutional neural network. Our method produces temporally coherent reconstruction of body and clothing from monocular video. We demonstrate successful clothing capture results from a variety of challenging videos. Extensive quantitative experiments demonstrate the effectiveness of our method on metrics including body pose error and surface reconstruction error of the clothing.
Fully Convolutional Mesh Autoencoder using Efficient Spatially Varying Kernels
Jun 08, 2020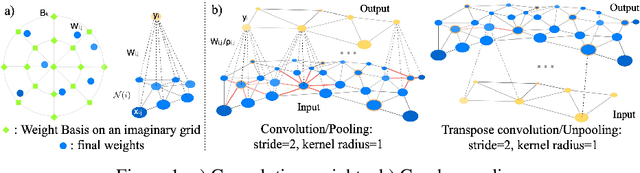
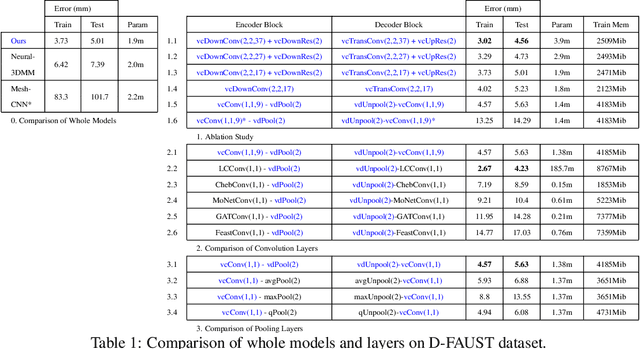
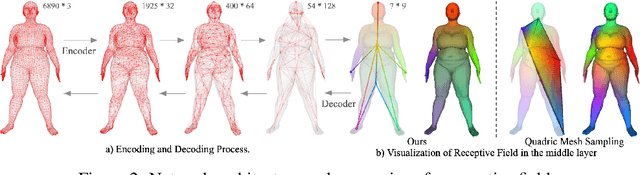
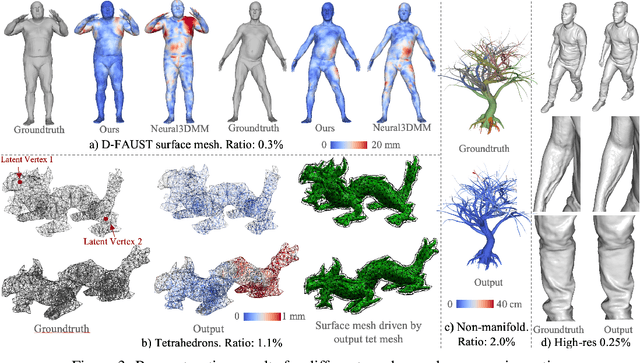
Learning latent representations of registered meshes is useful for many 3D tasks. Techniques have recently shifted to neural mesh autoencoders. Although they demonstrate higher precision than traditional methods, they remain unable to capture fine-grained deformations. Furthermore, these methods can only be applied to a template-specific surface mesh, and is not applicable to more general meshes, like tetrahedrons and non-manifold meshes. While more general graph convolution methods can be employed, they lack performance in reconstruction precision and require higher memory usage. In this paper, we propose a non-template-specific fully convolutional mesh autoencoder for arbitrary registered mesh data. It is enabled by our novel convolution and (un)pooling operators learned with globally shared weights and locally varying coefficients which can efficiently capture the spatially varying contents presented by irregular mesh connections. Our model outperforms state-of-the-art methods on reconstruction accuracy. In addition, the latent codes of our network are fully localized thanks to the fully convolutional structure, and thus have much higher interpolation capability than many traditional 3D mesh generation models.
Adversarial Feature Alignment: Avoid Catastrophic Forgetting in Incremental Task Lifelong Learning
Oct 24, 2019Human beings are able to master a variety of knowledge and skills with ongoing learning. By contrast, dramatic performance degradation is observed when new tasks are added to an existing neural network model. This phenomenon, termed as \emph{Catastrophic Forgetting}, is one of the major roadblocks that prevent deep neural networks from achieving human-level artificial intelligence. Several research efforts, e.g. \emph{Lifelong} or \emph{Continual} learning algorithms, have been proposed to tackle this problem. However, they either suffer from an accumulating drop in performance as the task sequence grows longer, or require to store an excessive amount of model parameters for historical memory, or cannot obtain competitive performance on the new tasks. In this paper, we focus on the incremental multi-task image classification scenario. Inspired by the learning process of human students, where they usually decompose complex tasks into easier goals, we propose an adversarial feature alignment method to avoid catastrophic forgetting. In our design, both the low-level visual features and high-level semantic features serve as soft targets and guide the training process in multiple stages, which provide sufficient supervised information of the old tasks and help to reduce forgetting. Due to the knowledge distillation and regularization phenomenons, the proposed method gains even better performance than finetuning on the new tasks, which makes it stand out from other methods. Extensive experiments in several typical lifelong learning scenarios demonstrate that our method outperforms the state-of-the-art methods in both accuracies on new tasks and performance preservation on old tasks.
Federated Learning with Additional Mechanisms on Clients to Reduce Communication Costs
Sep 01, 2019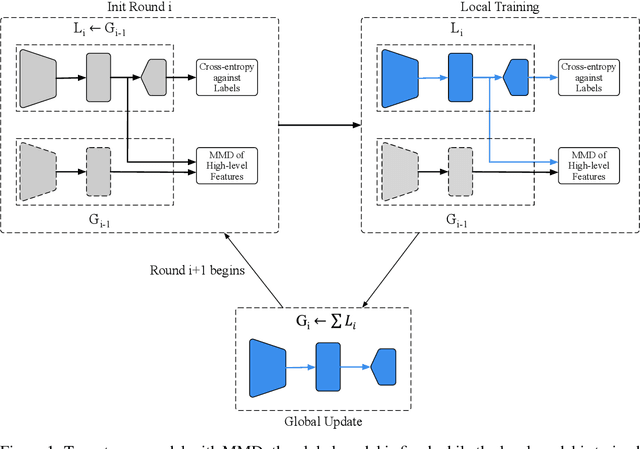
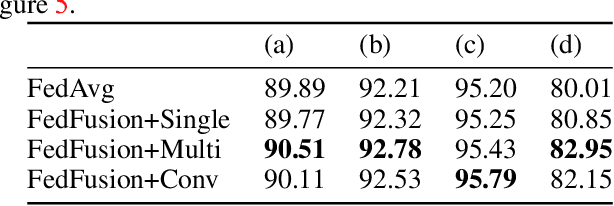
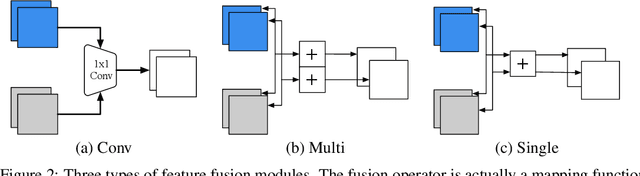
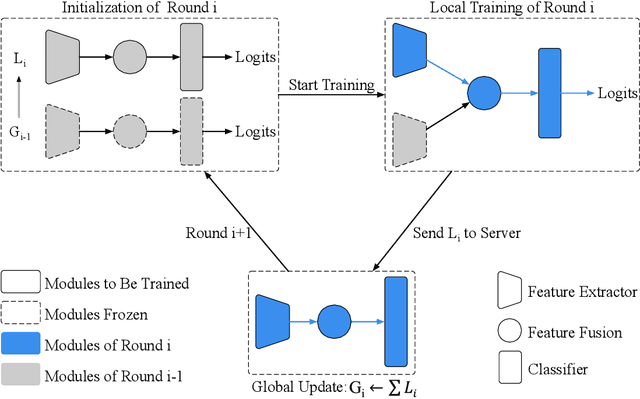
Federated learning (FL) enables on-device training over distributed networks consisting of a massive amount of modern smart devices, such as smartphones and IoT (Internet of Things) devices. However, the leading optimization algorithm in such settings, i.e., federated averaging (FedAvg), suffers from heavy communication costs and the inevitable performance drop, especially when the local data is distributed in a non-IID way. To alleviate this problem, we propose two potential solutions by introducing additional mechanisms to the on-device training. The first (FedMMD) is adopting a two-stream model with the MMD (Maximum Mean Discrepancy) constraint instead of a single model in vanilla FedAvg to be trained on devices. Experiments show that the proposed method outperforms baselines, especially in non-IID FL settings, with a reduction of more than 20% in required communication rounds. The second is FL with feature fusion (FedFusion). By aggregating the features from both the local and global models, we achieve higher accuracy at fewer communication costs. Furthermore, the feature fusion modules offer better initialization for newly incoming clients and thus speed up the process of convergence. Experiments in popular FL scenarios show that our FedFusion outperforms baselines in both accuracy and generalization ability while reducing the number of required communication rounds by more than 60%.
Comyco: Quality-Aware Adaptive Video Streaming via Imitation Learning
Aug 06, 2019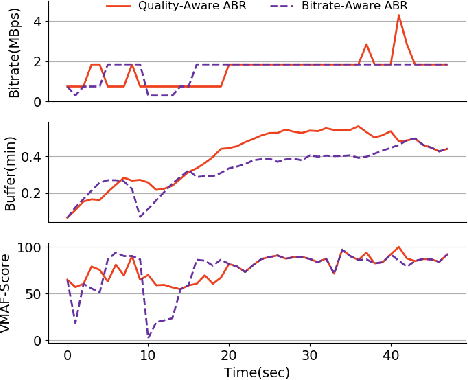


Learning-based Adaptive Bit Rate~(ABR) method, aiming to learn outstanding strategies without any presumptions, has become one of the research hotspots for adaptive streaming. However, it is still suffering from several issues, i.e., low sample efficiency and lack of awareness of the video quality information. In this paper, we propose Comyco, a video quality-aware ABR approach that enormously improves the learning-based methods by tackling the above issues. Comyco trains the policy via imitating expert trajectories given by the instant solver, which can not only avoid redundant exploration but also make better use of the collected samples. Meanwhile, Comyco attempts to pick the chunk with higher perceptual video qualities rather than video bitrates. To achieve this, we construct Comyco's neural network architecture, video datasets and QoE metrics with video quality features. Using trace-driven and real-world experiments, we demonstrate significant improvements of Comyco's sample efficiency in comparison to prior work, with 1700x improvements in terms of the number of samples required and 16x improvements on training time required. Moreover, results illustrate that Comyco outperforms previously proposed methods, with the improvements on average QoE of 7.5% - 16.79%. Especially, Comyco also surpasses state-of-the-art approach Pensieve by 7.37% on average video quality under the same rebuffering time.