 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to EdgeFedET: A Communication-Efficient Federated Class-Incremental Learning Framework Based on Enhanced Transformer
Jun 27, 2023Federated Learning (FL) has been widely concerned for it enables decentralized learning while ensuring data privacy. However, most existing methods unrealistically assume that the classes encountered by local clients are fixed over time. After learning new classes, this assumption will make the model's catastrophic forgetting of old classes significantly severe. Moreover, due to the limitation of communication cost, it is challenging to use large-scale models in FL, which will affect the prediction accuracy. To address these challenges, we propose a novel framework, Federated Enhanced Transformer (FedET), which simultaneously achieves high accuracy and low communication cost. Specifically, FedET uses Enhancer, a tiny module, to absorb and communicate new knowledge, and applies pre-trained Transformers combined with different Enhancers to ensure high precision on various tasks. To address local forgetting caused by new classes of new tasks and global forgetting brought by non-i.i.d (non-independent and identically distributed) class imbalance across different local clients, we proposed an Enhancer distillation method to modify the imbalance between old and new knowledge and repair the non-i.i.d. problem. Experimental results demonstrate that FedET's average accuracy on representative benchmark datasets is 14.1% higher than the state-of-the-art method, while FedET saves 90% of the communication cost compared to the previous method.
PyRCA: A Library for Metric-based Root Cause Analysis
Jun 20, 2023We introduce PyRCA, an open-source Python machine learning library of Root Cause Analysis (RCA) for Artificial Intelligence for IT Operations (AIOps). It provides a holistic framework to uncover the complicated metric causal dependencies and automatically locate root causes of incidents. It offers a unified interface for multiple commonly used RCA models, encompassing both graph construction and scoring tasks. This library aims to provide IT operations staff, data scientists, and researchers a one-step solution to rapid model development, model evaluation and deployment to online applications. In particular, our library includes various causal discovery methods to support causal graph construction, and multiple types of root cause scoring methods inspired by Bayesian analysis, graph analysis and causal analysis, etc. Our GUI dashboard offers practitioners an intuitive point-and-click interface, empowering them to easily inject expert knowledge through human interaction. With the ability to visualize causal graphs and the root cause of incidents, practitioners can quickly gain insights and improve their workflow efficiency. This technical report introduces PyRCA's architecture and major functionalities, while also presenting benchmark performance numbers in comparison to various baseline models. Additionally, we demonstrate PyRCA's capabilities through several example use cases.
OTW: Optimal Transport Warping for Time Series
Jun 01, 2023



Dynamic Time Warping (DTW) has become the pragmatic choice for measuring distance between time series. However, it suffers from unavoidable quadratic time complexity when the optimal alignment matrix needs to be computed exactly. This hinders its use in deep learning architectures, where layers involving DTW computations cause severe bottlenecks. To alleviate these issues, we introduce a new metric for time series data based on the Optimal Transport (OT) framework, called Optimal Transport Warping (OTW). OTW enjoys linear time/space complexity, is differentiable and can be parallelized. OTW enjoys a moderate sensitivity to time and shape distortions, making it ideal for time series. We show the efficacy and efficiency of OTW on 1-Nearest Neighbor Classification and Hierarchical Clustering, as well as in the case of using OTW instead of DTW in Deep Learning architectures.
AI for IT Operations on Cloud Platforms: Reviews, Opportunities and Challenges
Apr 10, 2023



Artificial Intelligence for IT operations (AIOps) aims to combine the power of AI with the big data generated by IT Operations processes, particularly in cloud infrastructures, to provide actionable insights with the primary goal of maximizing availability. There are a wide variety of problems to address, and multiple use-cases, where AI capabilities can be leveraged to enhance operational efficiency. Here we provide a review of the AIOps vision, trends challenges and opportunities, specifically focusing on the underlying AI techniques. We discuss in depth the key types of data emitted by IT Operations activities, the scale and challenges in analyzing them, and where they can be helpful. We categorize the key AIOps tasks as - incident detection, failure prediction, root cause analysis and automated actions. We discuss the problem formulation for each task, and then present a taxonomy of techniques to solve these problems. We also identify relatively under explored topics, especially those that could significantly benefit from advances in AI literature. We also provide insights into the trends in this field, and what are the key investment opportunities.
Unsupervised Brain Tumor Segmentation with Image-based Prompts
Apr 04, 2023



Automated brain tumor segmentation based on deep learning (DL) has achieved promising performance. However, it generally relies on annotated images for model training, which is not always feasible in clinical settings. Therefore, the development of unsupervised DL-based brain tumor segmentation approaches without expert annotations is desired. Motivated by the success of prompt learning (PL) in natural language processing, we propose an approach to unsupervised brain tumor segmentation by designing image-based prompts that allow indication of brain tumors, and this approach is dubbed as PL-based Brain Tumor Segmentation (PL-BTS). Specifically, instead of directly training a model for brain tumor segmentation with a large amount of annotated data, we seek to train a model that can answer the question: is a voxel in the input image associated with tumor-like hyper-/hypo-intensity? Such a model can be trained by artificially generating tumor-like hyper-/hypo-intensity on images without tumors with hand-crafted designs. Since the hand-crafted designs may be too simplistic to represent all kinds of real tumors, the trained model may overfit the simplistic hand-crafted task rather than actually answer the question of abnormality. To address this problem, we propose the use of a validation task, where we generate a different hand-crafted task to monitor overfitting. In addition, we propose PL-BTS+ that further improves PL-BTS by exploiting unannotated images with brain tumors. Compared with competing unsupervised methods, the proposed method has achieved marked improvements on both public and in-house datasets, and we have also demonstrated its possible extension to other brain lesion segmentation tasks.
HINormer: Representation Learning On Heterogeneous Information Networks with Graph Transformer
Mar 03, 2023



Recent studies have highlighted the limitations of message-passing based graph neural networks (GNNs), e.g., limited model expressiveness, over-smoothing, over-squashing, etc. To alleviate these issues, Graph Transformers (GTs) have been proposed which work in the paradigm that allows message passing to a larger coverage even across the whole graph. Hinging on the global range attention mechanism, GTs have shown a superpower for representation learning on homogeneous graphs. However, the investigation of GTs on heterogeneous information networks (HINs) is still under-exploited. In particular, on account of the existence of heterogeneity, HINs show distinct data characteristics and thus require different treatment. To bridge this gap, in this paper we investigate the representation learning on HINs with Graph Transformer, and propose a novel model named HINormer, which capitalizes on a larger-range aggregation mechanism for node representation learning. In particular, assisted by two major modules, i.e., a local structure encoder and a heterogeneous relation encoder, HINormer can capture both the structural and heterogeneous information of nodes on HINs for comprehensive node representations. We conduct extensive experiments on four HIN benchmark datasets, which demonstrate that our proposed model can outperform the state-of-the-art.
LogAI: A Library for Log Analytics and Intelligence
Jan 31, 2023



Software and System logs record runtime information about processes executing within a system. These logs have become the most critical and ubiquitous forms of observability data that help developers understand system behavior, monitor system health and resolve issues. However, the volume of logs generated can be humongous (of the order of petabytes per day) especially for complex distributed systems, such as cloud, search engine, social media, etc. This has propelled a lot of research on developing AI-based log based analytics and intelligence solutions that can process huge volume of raw logs and generate insights. In order to enable users to perform multiple types of AI-based log analysis tasks in a uniform manner, we introduce LogAI (https://github.com/salesforce/logai), a one-stop open source library for log analytics and intelligence. LogAI supports tasks such as log summarization, log clustering and log anomaly detection. It adopts the OpenTelemetry data model, to enable compatibility with different log management platforms. LogAI provides a unified model interface and provides popular time-series, statistical learning and deep learning models. Alongside this, LogAI also provides an out-of-the-box GUI for users to conduct interactive analysis. With LogAI, we can also easily benchmark popular deep learning algorithms for log anomaly detection without putting in redundant effort to process the logs. We have opensourced LogAI to cater to a wide range of applications benefiting both academic research and industrial prototyping.
Salesforce CausalAI Library: A Fast and Scalable Framework for Causal Analysis of Time Series and Tabular Data
Jan 25, 2023



We introduce the Salesforce CausalAI Library, an open-source library for causal analysis using observational data. It supports causal discovery and causal inference for tabular and time series data, of both discrete and continuous types. This library includes algorithms that handle linear and non-linear causal relationships between variables, and uses multi-processing for speed-up. We also include a data generator capable of generating synthetic data with specified structural equation model for both the aforementioned data formats and types, that helps users control the ground-truth causal process while investigating various algorithms. Finally, we provide a user interface (UI) that allows users to perform causal analysis on data without coding. The goal of this library is to provide a fast and flexible solution for a variety of problems in the domain of causality. This technical report describes the Salesforce CausalAI API along with its capabilities, the implementations of the supported algorithms, and experiments demonstrating their performance and speed. Our library is available at \url{https://github.com/salesforce/causalai}.
Continual Learning: Fast and Slow
Sep 06, 2022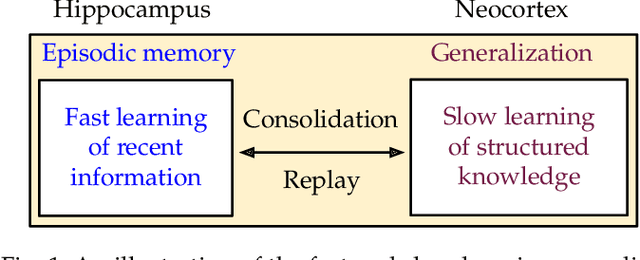
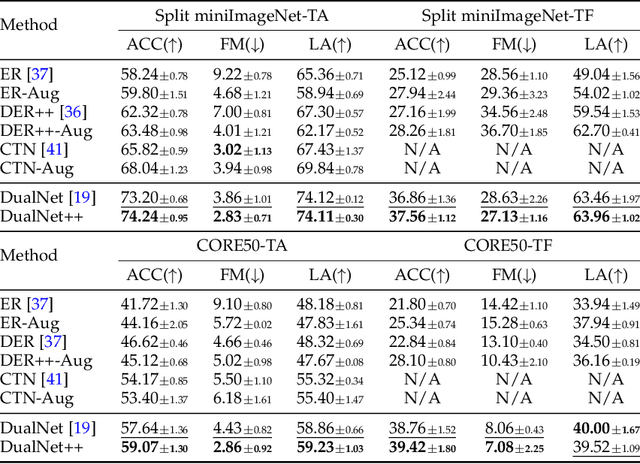
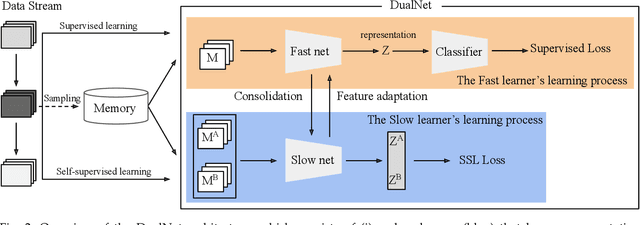
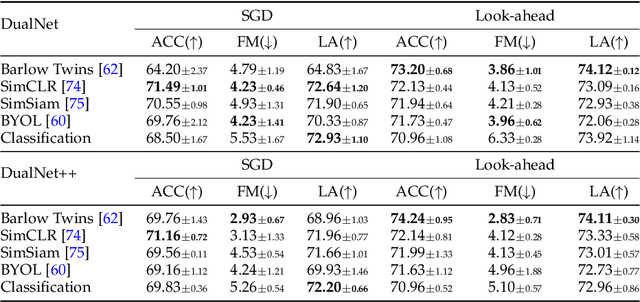
According to the Complementary Learning Systems (CLS) theory~\cite{mcclelland1995there} in neuroscience, humans do effective \emph{continual learning} through two complementary systems: a fast learning system centered on the hippocampus for rapid learning of the specifics, individual experiences; and a slow learning system located in the neocortex for the gradual acquisition of structured knowledge about the environment. Motivated by this theory, we propose \emph{DualNets} (for Dual Networks), a general continual learning framework comprising a fast learning system for supervised learning of pattern-separated representation from specific tasks and a slow learning system for representation learning of task-agnostic general representation via Self-Supervised Learning (SSL). DualNets can seamlessly incorporate both representation types into a holistic framework to facilitate better continual learning in deep neural networks. Via extensive experiments, we demonstrate the promising results of DualNets on a wide range of continual learning protocols, ranging from the standard offline, task-aware setting to the challenging online, task-free scenario. Notably, on the CTrL~\cite{veniat2020efficient} benchmark that has unrelated tasks with vastly different visual images, DualNets can achieve competitive performance with existing state-of-the-art dynamic architecture strategies~\cite{ostapenko2021continual}. Furthermore, we conduct comprehensive ablation studies to validate DualNets efficacy, robustness, and scalability. Code is publicly available at \url{https://github.com/phquang/DualNet}.
DeepTIMe: Deep Time-Index Meta-Learning for Non-Stationary Time-Series Forecasting
Jul 14, 2022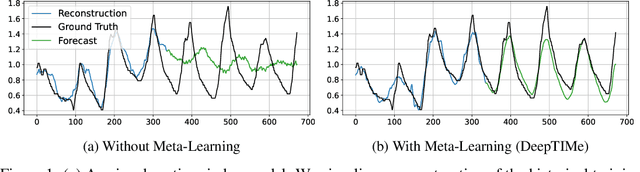
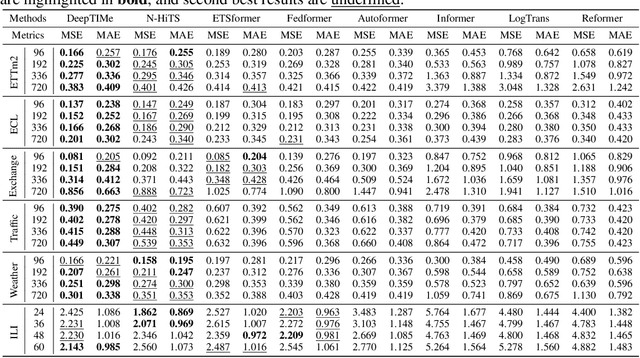
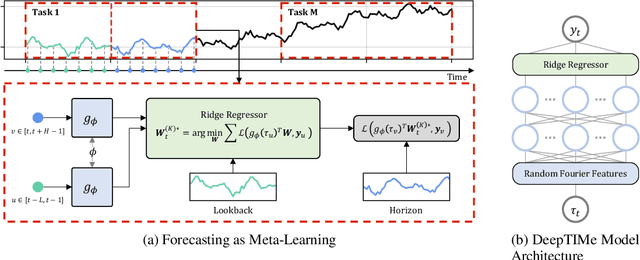
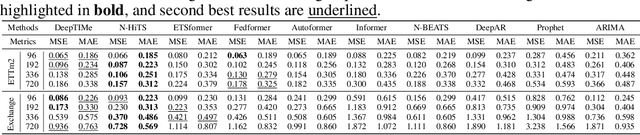
Deep learning has been actively applied to time-series forecasting, leading to a deluge of new autoregressive model architectures. Yet, despite the attractive properties of time-index based models, such as being a continuous signal function over time leading to smooth representations, little attention has been given to them. Indeed, while naive deep time-index based models are far more expressive than the manually predefined function representations of classical time-index based models, they are inadequate for forecasting due to the lack of inductive biases, and the non-stationarity of time-series. In this paper, we propose DeepTIMe, a deep time-index based model trained via a meta-learning formulation which overcomes these limitations, yielding an efficient and accurate forecasting model. Extensive experiments on real world datasets demonstrate that our approach achieves competitive results with state-of-the-art methods, and is highly efficient. Code is available at https://github.com/salesforce/DeepTIMe.