 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to EdgeCausality-inspired Single-source Domain Generalization for Medical Image Segmentation
Dec 06, 2021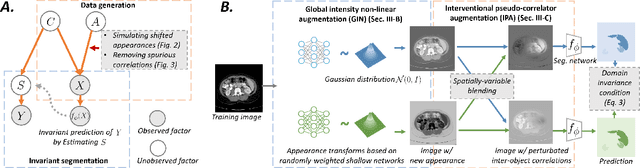
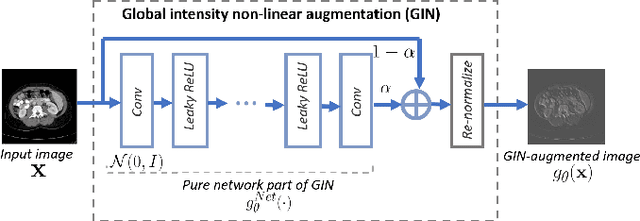
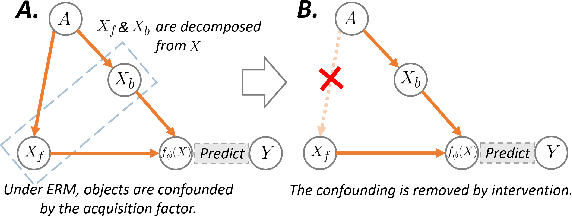
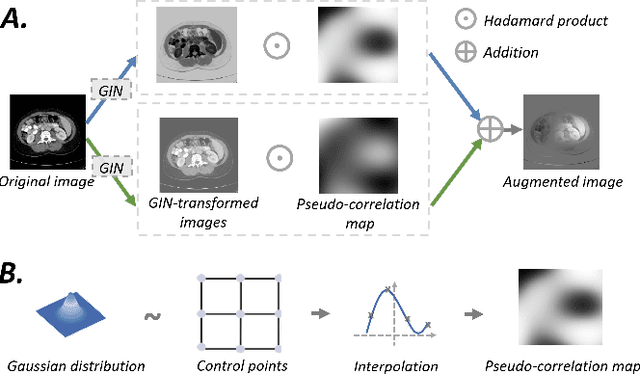
Deep learning models usually suffer from domain shift issues, where models trained on one source domain do not generalize well to other unseen domains. In this work, we investigate the single-source domain generalization problem: training a deep network that is robust to unseen domains, under the condition that training data is only available from one source domain, which is common in medical imaging applications. We tackle this problem in the context of cross-domain medical image segmentation. Under this scenario, domain shifts are mainly caused by different acquisition processes. We propose a simple causality-inspired data augmentation approach to expose a segmentation model to synthesized domain-shifted training examples. Specifically, 1) to make the deep model robust to discrepancies in image intensities and textures, we employ a family of randomly-weighted shallow networks. They augment training images using diverse appearance transformations. 2) Further we show that spurious correlations among objects in an image are detrimental to domain robustness. These correlations might be taken by the network as domain-specific clues for making predictions, and they may break on unseen domains. We remove these spurious correlations via causal intervention. This is achieved by resampling the appearances of potentially correlated objects independently. The proposed approach is validated on three cross-domain segmentation tasks: cross-modality (CT-MRI) abdominal image segmentation, cross-sequence (bSSFP-LGE) cardiac MRI segmentation, and cross-center prostate MRI segmentation. The proposed approach yields consistent performance gains compared with competitive methods when tested on unseen domains.
Enhancing MR Image Segmentation with Realistic Adversarial Data Augmentation
Aug 07, 2021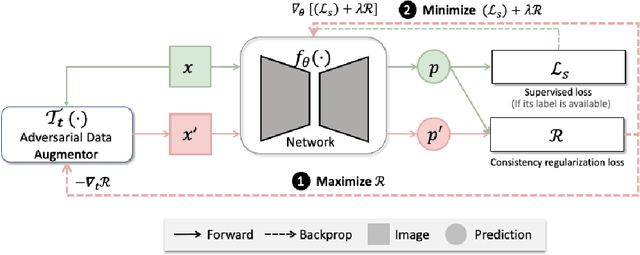

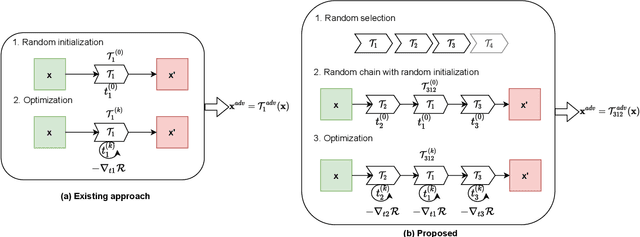
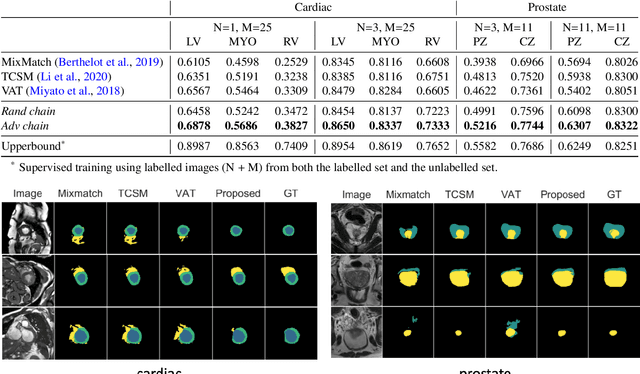
The success of neural networks on medical image segmentation tasks typically relies on large labeled datasets for model training. However, acquiring and manually labeling a large medical image set is resource-intensive, expensive, and sometimes impractical due to data sharing and privacy issues. To address this challenge, we propose an adversarial data augmentation approach to improve the efficiency in utilizing training data and to enlarge the dataset via simulated but realistic transformations. Specifically, we present a generic task-driven learning framework, which jointly optimizes a data augmentation model and a segmentation network during training, generating informative examples to enhance network generalizability for the downstream task. The data augmentation model utilizes a set of photometric and geometric image transformations and chains them to simulate realistic complex imaging variations that could exist in magnetic resonance (MR) imaging. The proposed adversarial data augmentation does not rely on generative networks and can be used as a plug-in module in general segmentation networks. It is computationally efficient and applicable for both supervised and semi-supervised learning. We analyze and evaluate the method on two MR image segmentation tasks: cardiac segmentation and prostate segmentation. Results show that the proposed approach can alleviate the need for labeled data while improving model generalization ability, indicating its practical value in medical imaging applications.
Cooperative Training and Latent Space Data Augmentation for Robust Medical Image Segmentation
Jul 02, 2021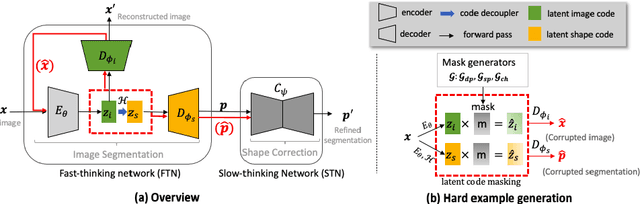
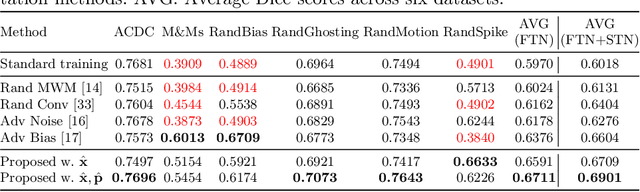
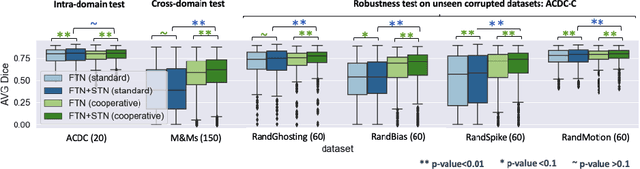
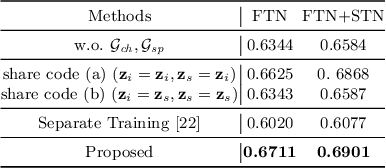
Deep learning-based segmentation methods are vulnerable to unforeseen data distribution shifts during deployment, e.g. change of image appearances or contrasts caused by different scanners, unexpected imaging artifacts etc. In this paper, we present a cooperative framework for training image segmentation models and a latent space augmentation method for generating hard examples. Both contributions improve model generalization and robustness with limited data. The cooperative training framework consists of a fast-thinking network (FTN) and a slow-thinking network (STN). The FTN learns decoupled image features and shape features for image reconstruction and segmentation tasks. The STN learns shape priors for segmentation correction and refinement. The two networks are trained in a cooperative manner. The latent space augmentation generates challenging examples for training by masking the decoupled latent space in both channel-wise and spatial-wise manners. We performed extensive experiments on public cardiac imaging datasets. Using only 10 subjects from a single site for training, we demonstrated improved cross-site segmentation performance and increased robustness against various unforeseen imaging artifacts compared to strong baseline methods. Particularly, cooperative training with latent space data augmentation yields 15% improvement in terms of average Dice score when compared to a standard training method.
Self-Supervision with Superpixels: Training Few-shot Medical Image Segmentation without Annotation
Jul 20, 2020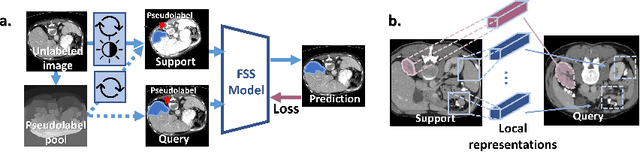
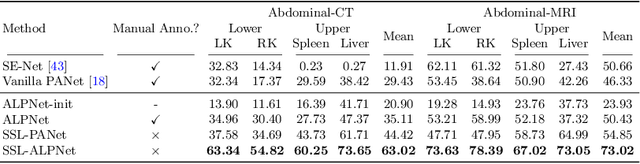
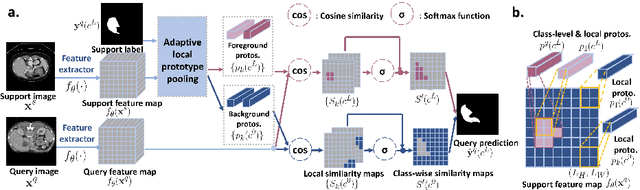
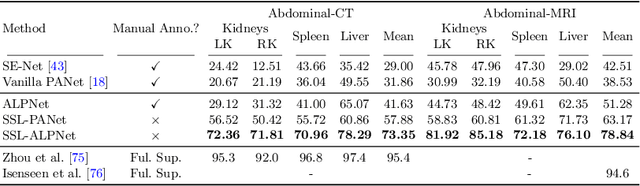
Few-shot semantic segmentation (FSS) has great potential for medical imaging applications. Most of the existing FSS techniques require abundant annotated semantic classes for training. However, these methods may not be applicable for medical images due to the lack of annotations. To address this problem we make several contributions: (1) A novel self-supervised FSS framework for medical images in order to eliminate the requirement for annotations during training. Additionally, superpixel-based pseudo-labels are generated to provide supervision; (2) An adaptive local prototype pooling module plugged into prototypical networks, to solve the common challenging foreground-background imbalance problem in medical image segmentation; (3) We demonstrate the general applicability of the proposed approach for medical images using three different tasks: abdominal organ segmentation for CT and MRI, as well as cardiac segmentation for MRI. Our results show that, for medical image segmentation, the proposed method outperforms conventional FSS methods which require manual annotations for training.
Realistic Adversarial Data Augmentation for MR Image Segmentation
Jun 23, 2020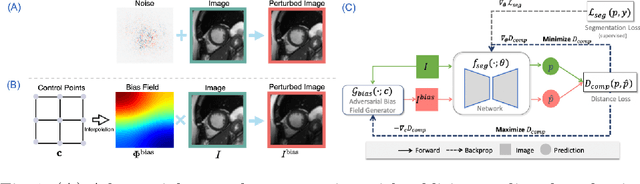
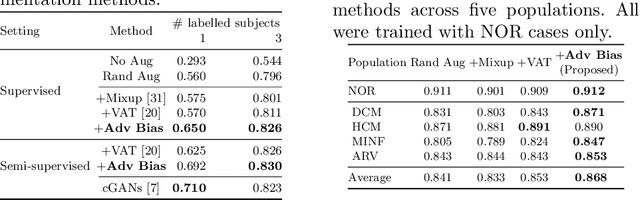
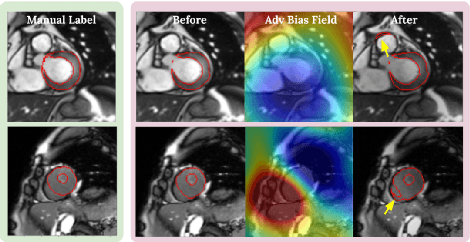
Neural network-based approaches can achieve high accuracy in various medical image segmentation tasks. However, they generally require large labelled datasets for supervised learning. Acquiring and manually labelling a large medical dataset is expensive and sometimes impractical due to data sharing and privacy issues. In this work, we propose an adversarial data augmentation method for training neural networks for medical image segmentation. Instead of generating pixel-wise adversarial attacks, our model generates plausible and realistic signal corruptions, which models the intensity inhomogeneities caused by a common type of artefacts in MR imaging: bias field. The proposed method does not rely on generative networks, and can be used as a plug-in module for general segmentation networks in both supervised and semi-supervised learning. Using cardiac MR imaging we show that such an approach can improve the generalization ability and robustness of models as well as provide significant improvements in low-data scenarios.
Cardiac Segmentation on Late Gadolinium Enhancement MRI: A Benchmark Study from Multi-Sequence Cardiac MR Segmentation Challenge
Jun 22, 2020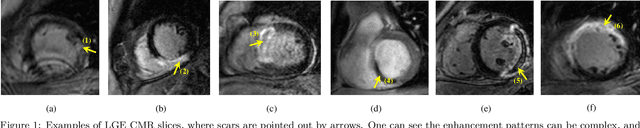
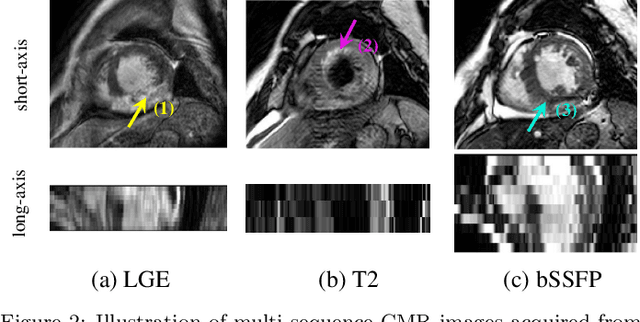

Accurate computing, analysis and modeling of the ventricles and myocardium from medical images are important, especially in the diagnosis and treatment management for patients suffering from myocardial infarction (MI). Late gadolinium enhancement (LGE) cardiac magnetic resonance (CMR) provides an important protocol to visualize MI. However, automated segmentation of LGE CMR is still challenging, due to the indistinguishable boundaries, heterogeneous intensity distribution and complex enhancement patterns of pathological myocardium from LGE CMR. Furthermore, compared with the other sequences LGE CMR images with gold standard labels are particularly limited, which represents another obstacle for developing novel algorithms for automatic segmentation of LGE CMR. This paper presents the selective results from the Multi-Sequence Cardiac MR (MS-CMR) Segmentation challenge, in conjunction with MICCAI 2019. The challenge offered a data set of paired MS-CMR images, including auxiliary CMR sequences as well as LGE CMR, from 45 patients who underwent cardiomyopathy. It was aimed to develop new algorithms, as well as benchmark existing ones for LGE CMR segmentation and compare them objectively. In addition, the paired MS-CMR images could enable algorithms to combine the complementary information from the other sequences for the segmentation of LGE CMR. Nine representative works were selected for evaluation and comparisons, among which three methods are unsupervised methods and the other six are supervised. The results showed that the average performance of the nine methods was comparable to the inter-observer variations. The success of these methods was mainly attributed to the inclusion of the auxiliary sequences from the MS-CMR images, which provide important label information for the training of deep neural networks.
Data consistency networks for (calibration-less) accelerated parallel MR image reconstruction
Sep 25, 2019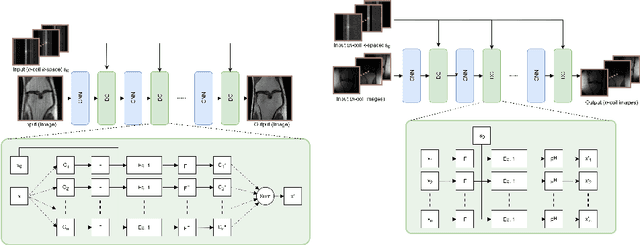
We present simple reconstruction networks for multi-coil data by extending deep cascade of CNN's and exploiting the data consistency layer. In particular, we propose two variants, where one is inspired by POCSENSE and the other is calibration-less. We show that the proposed approaches are competitive relative to the state of the art both quantitatively and qualitatively.
Unsupervised Multi-modal Style Transfer for Cardiac MR Segmentation
Aug 21, 2019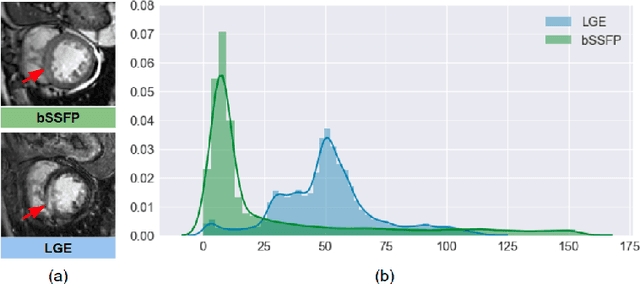
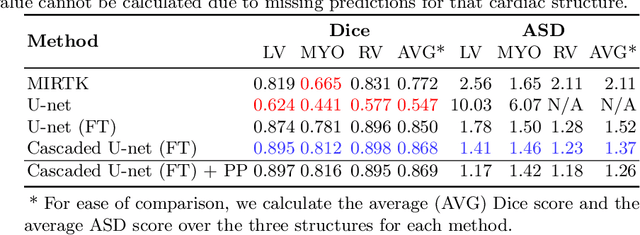
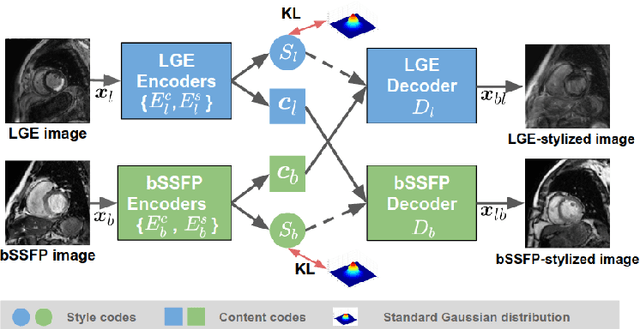
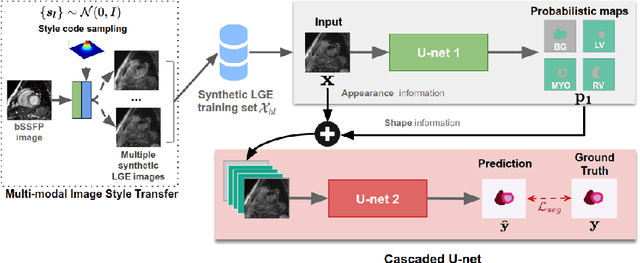
In this work, we present a fully automatic method to segment cardiac structures from late-gadolinium enhanced (LGE) images without using labelled LGE data for training, but instead by transferring the anatomical knowledge and features learned on annotated balanced steady-state free precession (bSSFP) images, which are easier to acquire. Our framework mainly consists of two neural networks: a multi-modal image translation network for style transfer and a cascaded segmentation network for image segmentation. The multi-modal image translation network generates realistic and diverse synthetic LGE images conditioned on a single annotated bSSFP image, forming a synthetic LGE training set. This set is then utilized to fine-tune the segmentation network pre-trained on labelled bSSFP images, achieving the goal of unsupervised LGE image segmentation. In particular, the proposed cascaded segmentation network is able to produce accurate segmentation by taking both shape prior and image appearance into account, achieving an average Dice score of 0.92 for the left ventricle, 0.83 for the myocardium, and 0.88 for the right ventricle on the test set.
Data Efficient Unsupervised Domain Adaptation for Cross-Modality Image Segmentation
Aug 12, 2019
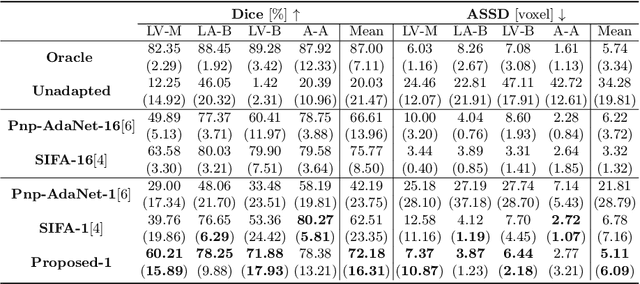
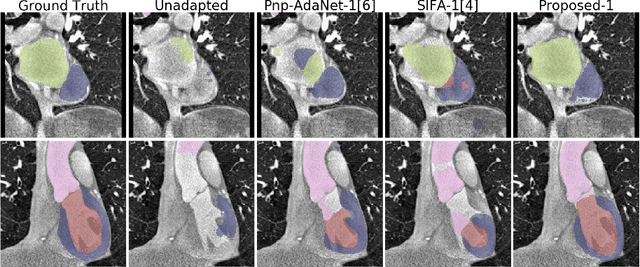
Deep learning models trained on medical images from a source domain (e.g. imaging modality) often fail when deployed on images from a different target domain, despite imaging common anatomical structures. Deep unsupervised domain adaptation (UDA) aims to improve the performance of a deep neural network model on a target domain, using solely unlabelled target domain data and labelled source domain data. However, current state-of-the-art methods exhibit reduced performance when target data is scarce. In this work, we introduce a new data efficient UDA method for multi-domain medical image segmentation. The proposed method combines a novel VAE-based feature prior matching, which is data-efficient, and domain adversarial training to learn a shared domain-invariant latent space which is exploited during segmentation. Our method is evaluated on a public multi-modality cardiac image segmentation dataset by adapting from the labelled source domain (3D MRI) to the unlabelled target domain (3D CT). We show that by using only one single unlabelled 3D CT scan, the proposed architecture outperforms the state-of-the-art in the same setting. Finally, we perform ablation studies on prior matching and domain adversarial training to shed light on the theoretical grounding of the proposed method.
VS-Net: Variable splitting network for accelerated parallel MRI reconstruction
Jul 19, 2019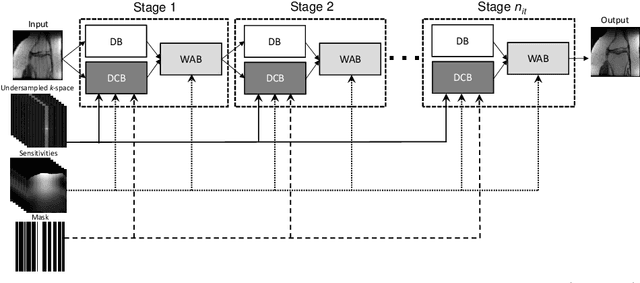
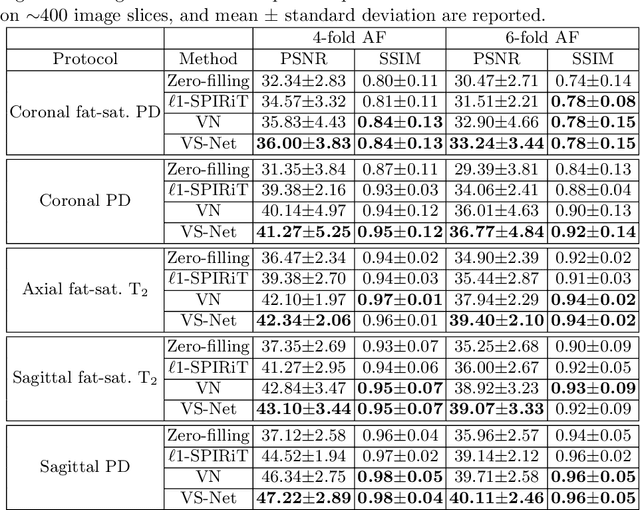
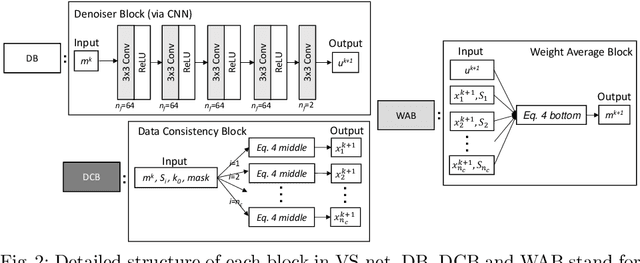
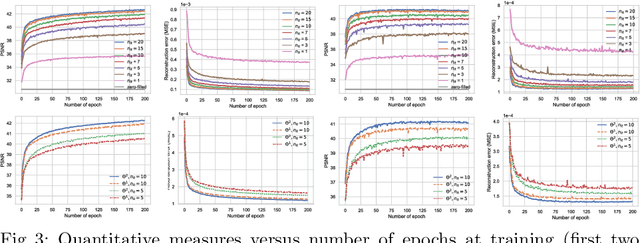
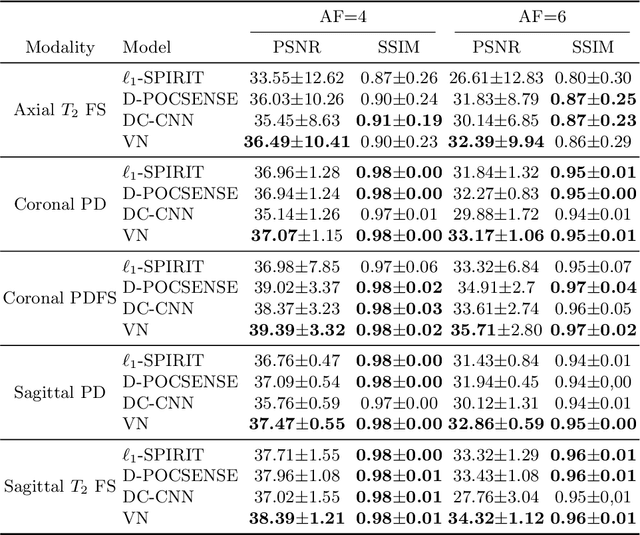
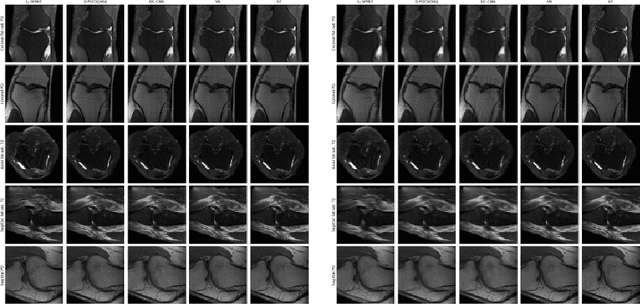
In this work, we propose a deep learning approach for parallel magnetic resonance imaging (MRI) reconstruction, termed a variable splitting network (VS-Net), for an efficient, high-quality reconstruction of undersampled multi-coil MR data. We formulate the generalized parallel compressed sensing reconstruction as an energy minimization problem, for which a variable splitting optimization method is derived. Based on this formulation we propose a novel, end-to-end trainable deep neural network architecture by unrolling the resulting iterative process of such variable splitting scheme. VS-Net is evaluated on complex valued multi-coil knee images for 4-fold and 6-fold acceleration factors. We show that VS-Net outperforms state-of-the-art deep learning reconstruction algorithms, in terms of reconstruction accuracy and perceptual quality. Our code is publicly available at https://github.com/j-duan/VS-Net.