 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to EdgeChen Qin
Enhancing MR Image Segmentation with Realistic Adversarial Data Augmentation
Aug 07, 2021
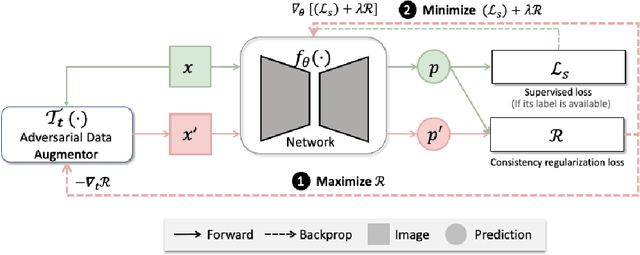

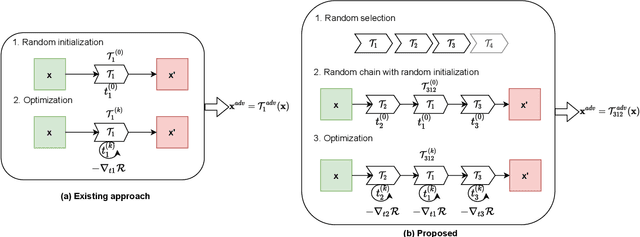
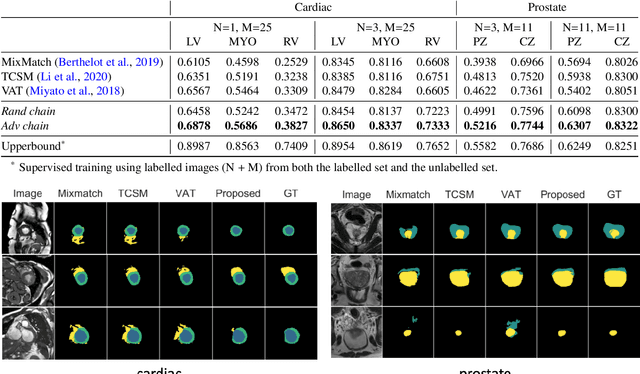
The success of neural networks on medical image segmentation tasks typically relies on large labeled datasets for model training. However, acquiring and manually labeling a large medical image set is resource-intensive, expensive, and sometimes impractical due to data sharing and privacy issues. To address this challenge, we propose an adversarial data augmentation approach to improve the efficiency in utilizing training data and to enlarge the dataset via simulated but realistic transformations. Specifically, we present a generic task-driven learning framework, which jointly optimizes a data augmentation model and a segmentation network during training, generating informative examples to enhance network generalizability for the downstream task. The data augmentation model utilizes a set of photometric and geometric image transformations and chains them to simulate realistic complex imaging variations that could exist in magnetic resonance (MR) imaging. The proposed adversarial data augmentation does not rely on generative networks and can be used as a plug-in module in general segmentation networks. It is computationally efficient and applicable for both supervised and semi-supervised learning. We analyze and evaluate the method on two MR image segmentation tasks: cardiac segmentation and prostate segmentation. Results show that the proposed approach can alleviate the need for labeled data while improving model generalization ability, indicating its practical value in medical imaging applications.
Joint Motion Correction and Super Resolution for Cardiac Segmentation via Latent Optimisation
Jul 08, 2021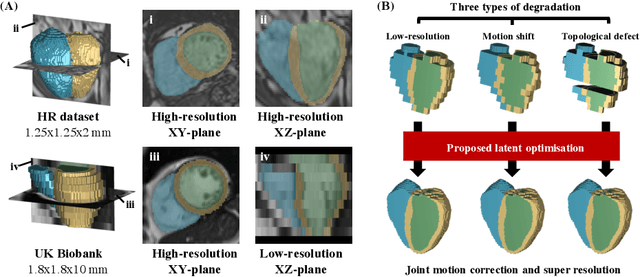

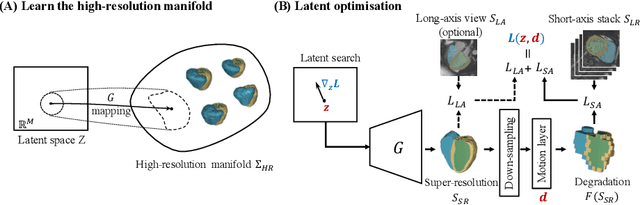
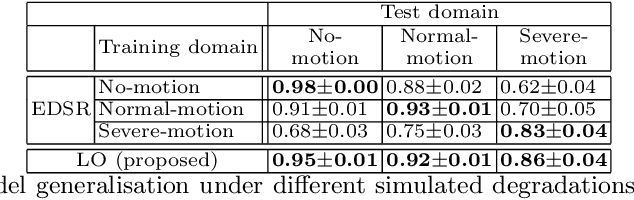
In cardiac magnetic resonance (CMR) imaging, a 3D high-resolution segmentation of the heart is essential for detailed description of its anatomical structures. However, due to the limit of acquisition duration and respiratory/cardiac motion, stacks of multi-slice 2D images are acquired in clinical routine. The segmentation of these images provides a low-resolution representation of cardiac anatomy, which may contain artefacts caused by motion. Here we propose a novel latent optimisation framework that jointly performs motion correction and super resolution for cardiac image segmentations. Given a low-resolution segmentation as input, the framework accounts for inter-slice motion in cardiac MR imaging and super-resolves the input into a high-resolution segmentation consistent with input. A multi-view loss is incorporated to leverage information from both short-axis view and long-axis view of cardiac imaging. To solve the inverse problem, iterative optimisation is performed in a latent space, which ensures the anatomical plausibility. This alleviates the need of paired low-resolution and high-resolution images for supervised learning. Experiments on two cardiac MR datasets show that the proposed framework achieves high performance, comparable to state-of-the-art super-resolution approaches and with better cross-domain generalisability and anatomical plausibility.
Cooperative Training and Latent Space Data Augmentation for Robust Medical Image Segmentation
Jul 02, 2021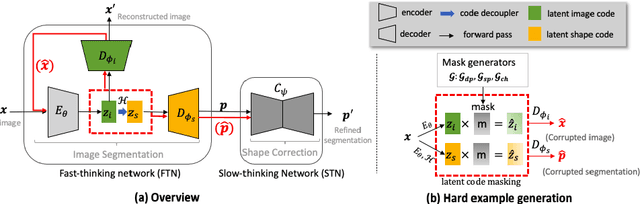
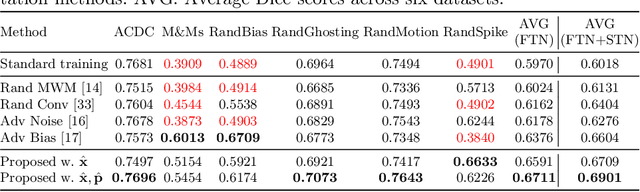
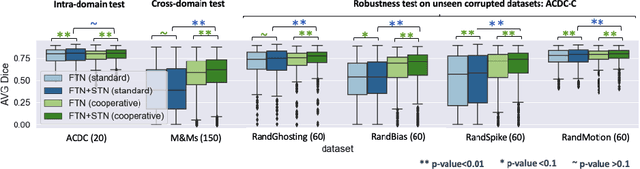
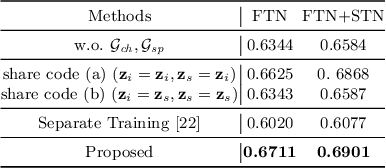
Deep learning-based segmentation methods are vulnerable to unforeseen data distribution shifts during deployment, e.g. change of image appearances or contrasts caused by different scanners, unexpected imaging artifacts etc. In this paper, we present a cooperative framework for training image segmentation models and a latent space augmentation method for generating hard examples. Both contributions improve model generalization and robustness with limited data. The cooperative training framework consists of a fast-thinking network (FTN) and a slow-thinking network (STN). The FTN learns decoupled image features and shape features for image reconstruction and segmentation tasks. The STN learns shape priors for segmentation correction and refinement. The two networks are trained in a cooperative manner. The latent space augmentation generates challenging examples for training by masking the decoupled latent space in both channel-wise and spatial-wise manners. We performed extensive experiments on public cardiac imaging datasets. Using only 10 subjects from a single site for training, we demonstrated improved cross-site segmentation performance and increased robustness against various unforeseen imaging artifacts compared to strong baseline methods. Particularly, cooperative training with latent space data augmentation yields 15% improvement in terms of average Dice score when compared to a standard training method.
Complementary Time-Frequency Domain Networks for Dynamic Parallel MR Image Reconstruction
Dec 22, 2020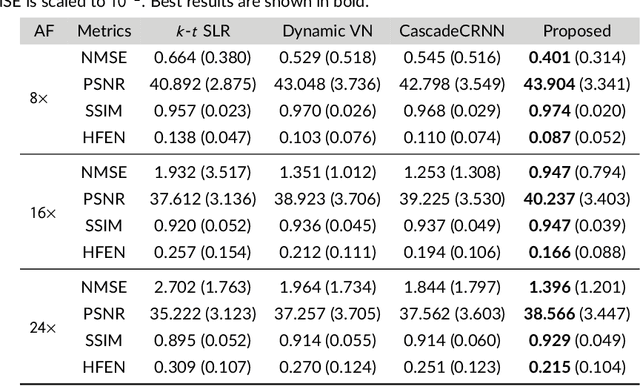
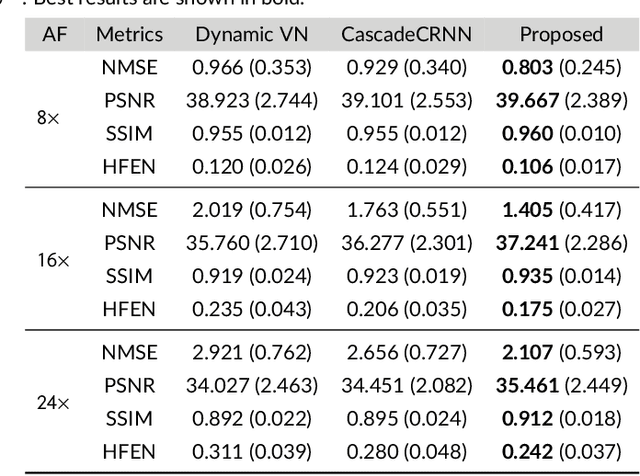
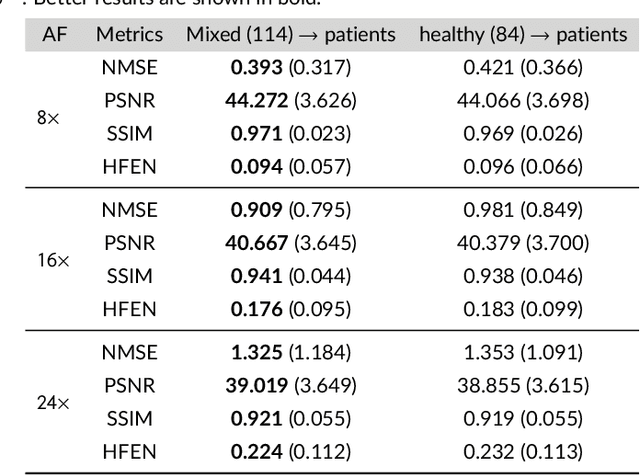
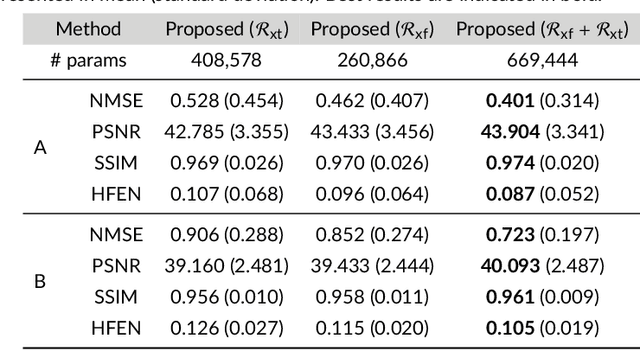
Purpose: To introduce a novel deep learning based approach for fast and high-quality dynamic multi-coil MR reconstruction by learning a complementary time-frequency domain network that exploits spatio-temporal correlations simultaneously from complementary domains. Theory and Methods: Dynamic parallel MR image reconstruction is formulated as a multi-variable minimisation problem, where the data is regularised in combined temporal Fourier and spatial (x-f) domain as well as in spatio-temporal image (x-t) domain. An iterative algorithm based on variable splitting technique is derived, which alternates among signal de-aliasing steps in x-f and x-t spaces, a closed-form point-wise data consistency step and a weighted coupling step. The iterative model is embedded into a deep recurrent neural network which learns to recover the image via exploiting spatio-temporal redundancies in complementary domains. Results: Experiments were performed on two datasets of highly undersampled multi-coil short-axis cardiac cine MRI scans. Results demonstrate that our proposed method outperforms the current state-of-the-art approaches both quantitatively and qualitatively. The proposed model can also generalise well to data acquired from a different scanner and data with pathologies that were not seen in the training set. Conclusion: The work shows the benefit of reconstructing dynamic parallel MRI in complementary time-frequency domains with deep neural networks. The method can effectively and robustly reconstruct high-quality images from highly undersampled dynamic multi-coil data ($16 \times$ and $24 \times$ yielding 15s and 10s scan times respectively) with fast reconstruction speed (2.8s). This could potentially facilitate achieving fast single-breath-hold clinical 2D cardiac cine imaging.
Bi-Classifier Determinacy Maximization for Unsupervised Domain Adaptation
Dec 13, 2020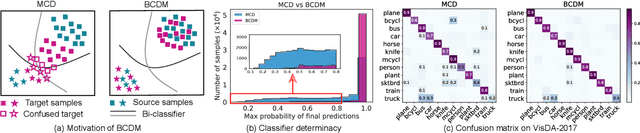
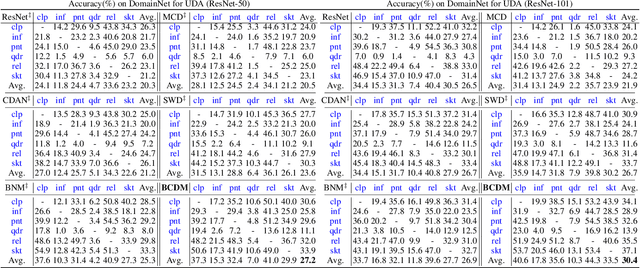
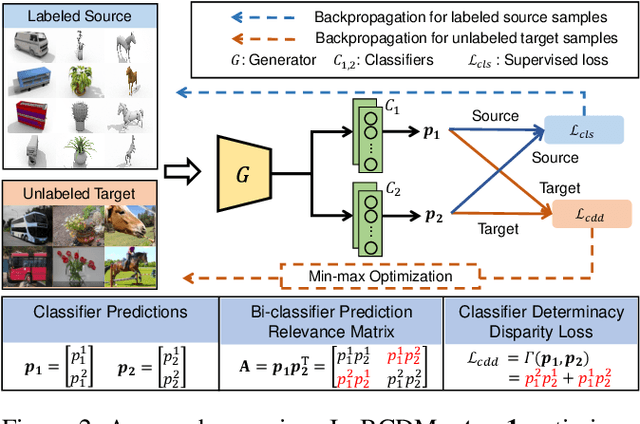
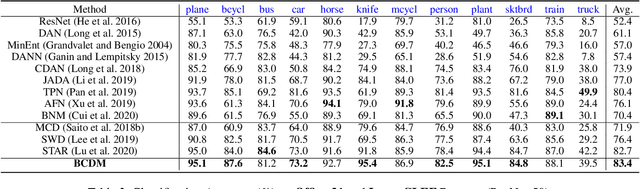
Unsupervised domain adaptation challenges the problem of transferring knowledge from a well-labelled source domain to an unlabelled target domain. Recently,adversarial learning with bi-classifier has been proven effective in pushing cross-domain distributions close. Prior approaches typically leverage the disagreement between bi-classifier to learn transferable representations, however, they often neglect the classifier determinacy in the target domain, which could result in a lack of feature discriminability. In this paper, we present a simple yet effective method, namely Bi-Classifier Determinacy Maximization(BCDM), to tackle this problem. Motivated by the observation that target samples cannot always be separated distinctly by the decision boundary, here in the proposed BCDM, we design a novel classifier determinacy disparity (CDD) metric, which formulates classifier discrepancy as the class relevance of distinct target predictions and implicitly introduces constraint on the target feature discriminability. To this end, the BCDM can generate discriminative representations by encouraging target predictive outputs to be consistent and determined, meanwhile, preserve the diversity of predictions in an adversarial manner. Furthermore, the properties of CDD as well as the theoretical guarantees of BCDM's generalization bound are both elaborated. Extensive experiments show that BCDM compares favorably against the existing state-of-the-art domain adaptation methods.
Deep Network Interpolation for Accelerated Parallel MR Image Reconstruction
Jul 12, 2020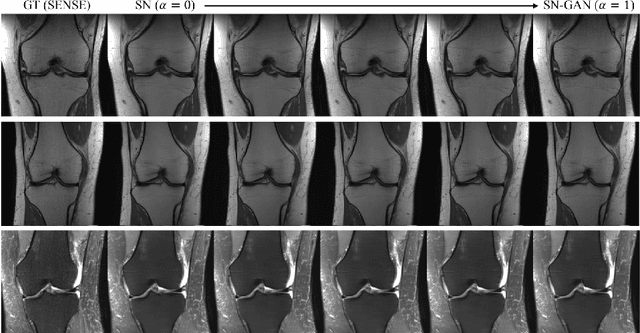
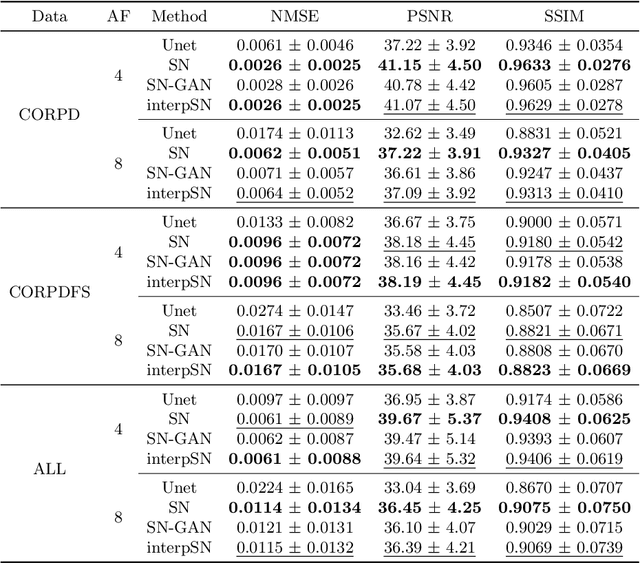
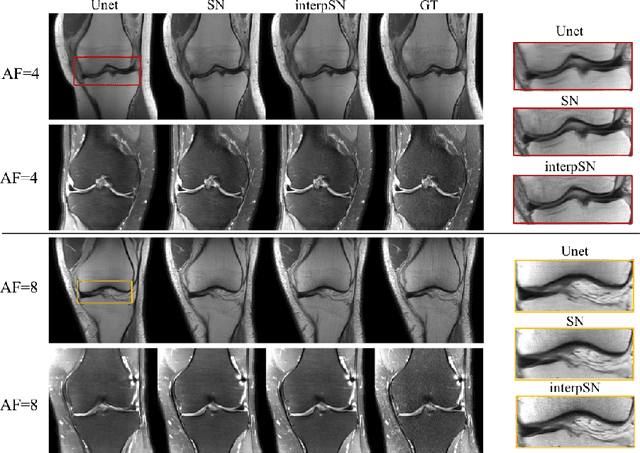
We present a deep network interpolation strategy for accelerated parallel MR image reconstruction. In particular, we examine the network interpolation in parameter space between a source model that is formulated in an unrolled scheme with L1 and SSIM losses and its counterpart that is trained with an adversarial loss. We show that by interpolating between the two different models of the same network structure, the new interpolated network can model a trade-off between perceptual quality and fidelity.
Biomechanics-informed Neural Networks for Myocardial Motion Tracking in MRI
Jul 04, 2020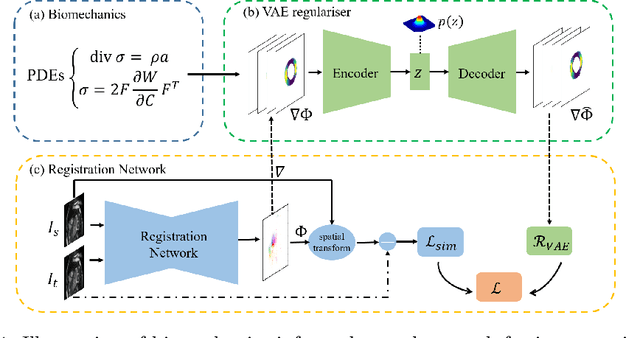
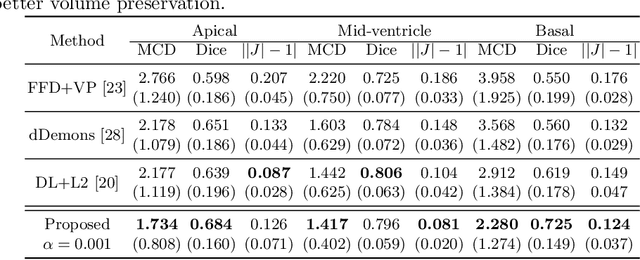
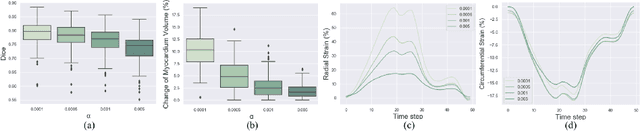
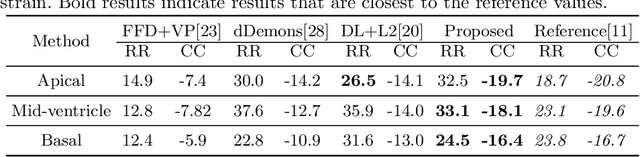
Image registration is an ill-posed inverse problem which often requires regularisation on the solution space. In contrast to most of the current approaches which impose explicit regularisation terms such as smoothness, in this paper we propose a novel method that can implicitly learn biomechanics-informed regularisation. Such an approach can incorporate application-specific prior knowledge into deep learning based registration. Particularly, the proposed biomechanics-informed regularisation leverages a variational autoencoder (VAE) to learn a manifold for biomechanically plausible deformations and to implicitly capture their underlying properties via reconstructing biomechanical simulations. The learnt VAE regulariser then can be coupled with any deep learning based registration network to regularise the solution space to be biomechanically plausible. The proposed method is validated in the context of myocardial motion tracking on 2D stacks of cardiac MRI data from two different datasets. The results show that it can achieve better performance against other competing methods in terms of motion tracking accuracy and has the ability to learn biomechanical properties such as incompressibility and strains. The method has also been shown to have better generalisability to unseen domains compared with commonly used L2 regularisation schemes.
Deep Generative Model-based Quality Control for Cardiac MRI Segmentation
Jun 23, 2020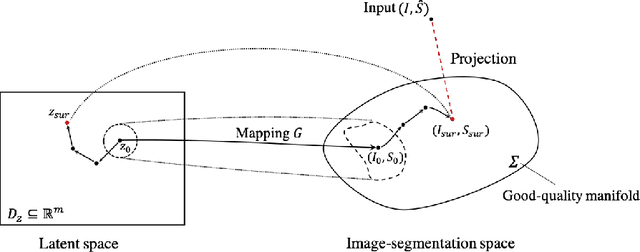
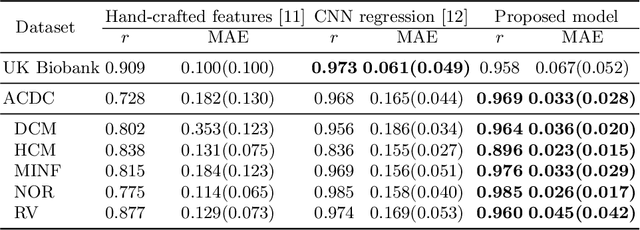
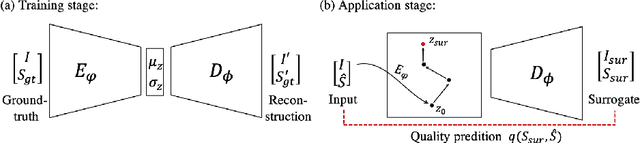
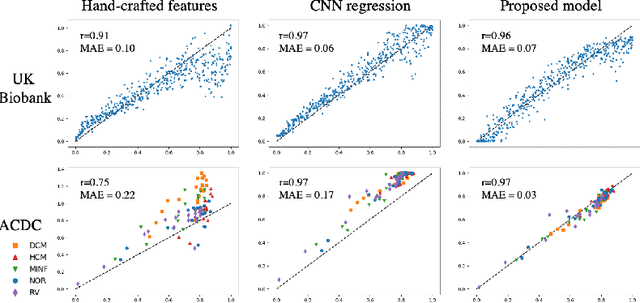
In recent years, convolutional neural networks have demonstrated promising performance in a variety of medical image segmentation tasks. However, when a trained segmentation model is deployed into the real clinical world, the model may not perform optimally. A major challenge is the potential poor-quality segmentations generated due to degraded image quality or domain shift issues. There is a timely need to develop an automated quality control method that can detect poor segmentations and feedback to clinicians. Here we propose a novel deep generative model-based framework for quality control of cardiac MRI segmentation. It first learns a manifold of good-quality image-segmentation pairs using a generative model. The quality of a given test segmentation is then assessed by evaluating the difference from its projection onto the good-quality manifold. In particular, the projection is refined through iterative search in the latent space. The proposed method achieves high prediction accuracy on two publicly available cardiac MRI datasets. Moreover, it shows better generalisation ability than traditional regression-based methods. Our approach provides a real-time and model-agnostic quality control for cardiac MRI segmentation, which has the potential to be integrated into clinical image analysis workflows.
Realistic Adversarial Data Augmentation for MR Image Segmentation
Jun 23, 2020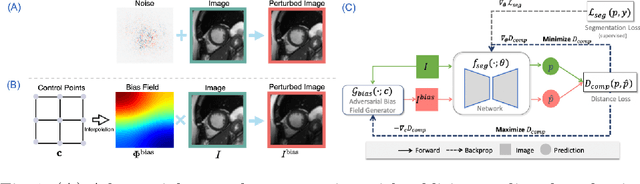
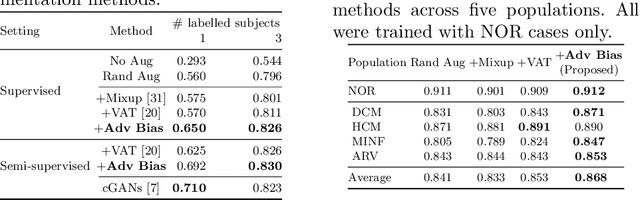
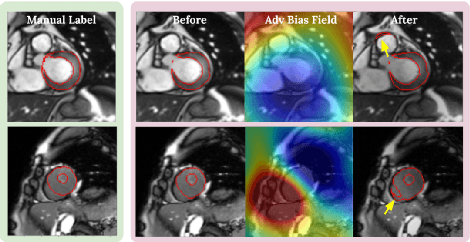
Neural network-based approaches can achieve high accuracy in various medical image segmentation tasks. However, they generally require large labelled datasets for supervised learning. Acquiring and manually labelling a large medical dataset is expensive and sometimes impractical due to data sharing and privacy issues. In this work, we propose an adversarial data augmentation method for training neural networks for medical image segmentation. Instead of generating pixel-wise adversarial attacks, our model generates plausible and realistic signal corruptions, which models the intensity inhomogeneities caused by a common type of artefacts in MR imaging: bias field. The proposed method does not rely on generative networks, and can be used as a plug-in module for general segmentation networks in both supervised and semi-supervised learning. Using cardiac MR imaging we show that such an approach can improve the generalization ability and robustness of models as well as provide significant improvements in low-data scenarios.