 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to EdgeDistributed Bayesian Learning with Stochastic Natural-gradient Expectation Propagation and the Posterior Server
Sep 07, 2017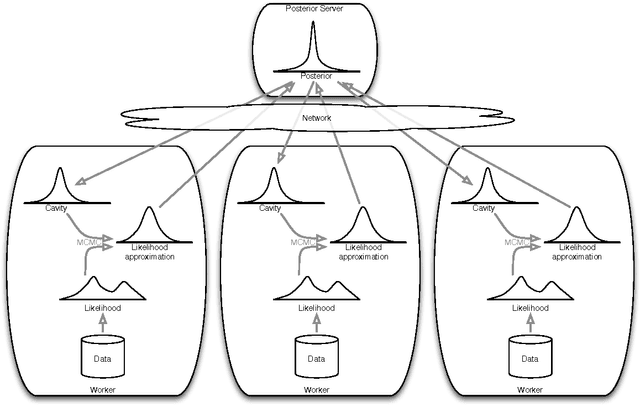
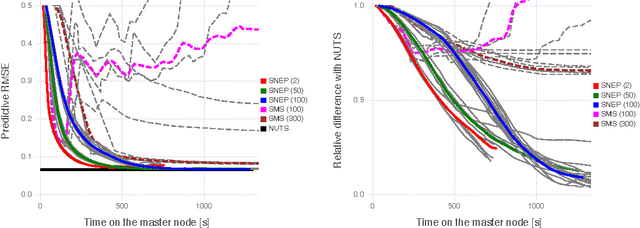
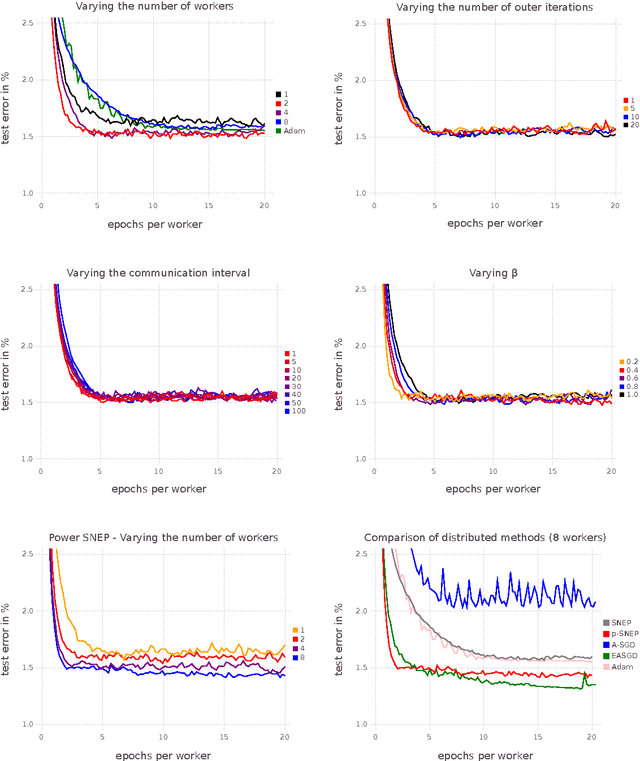
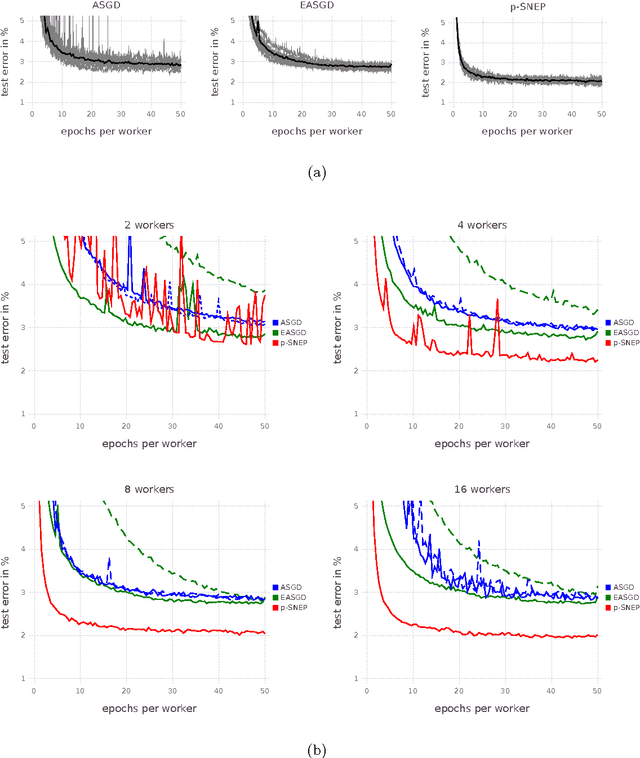
This paper makes two contributions to Bayesian machine learning algorithms. Firstly, we propose stochastic natural gradient expectation propagation (SNEP), a novel alternative to expectation propagation (EP), a popular variational inference algorithm. SNEP is a black box variational algorithm, in that it does not require any simplifying assumptions on the distribution of interest, beyond the existence of some Monte Carlo sampler for estimating the moments of the EP tilted distributions. Further, as opposed to EP which has no guarantee of convergence, SNEP can be shown to be convergent, even when using Monte Carlo moment estimates. Secondly, we propose a novel architecture for distributed Bayesian learning which we call the posterior server. The posterior server allows scalable and robust Bayesian learning in cases where a data set is stored in a distributed manner across a cluster, with each compute node containing a disjoint subset of data. An independent Monte Carlo sampler is run on each compute node, with direct access only to the local data subset, but which targets an approximation to the global posterior distribution given all data across the whole cluster. This is achieved by using a distributed asynchronous implementation of SNEP to pass messages across the cluster. We demonstrate SNEP and the posterior server on distributed Bayesian learning of logistic regression and neural networks. Keywords: Distributed Learning, Large Scale Learning, Deep Learning, Bayesian Learn- ing, Variational Inference, Expectation Propagation, Stochastic Approximation, Natural Gradient, Markov chain Monte Carlo, Parameter Server, Posterior Server.
* 37 pages, 7 figures
Neural Episodic Control
Mar 06, 2017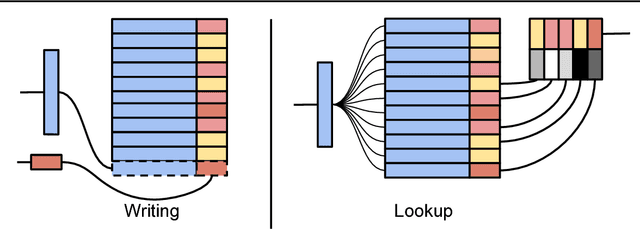
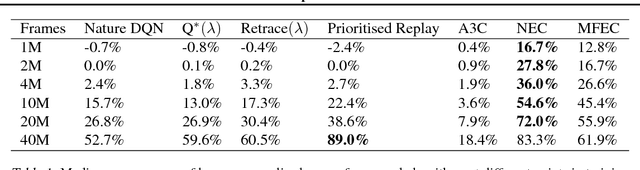
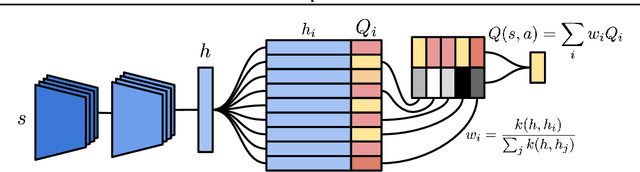
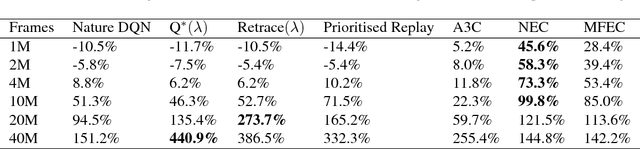
Deep reinforcement learning methods attain super-human performance in a wide range of environments. Such methods are grossly inefficient, often taking orders of magnitudes more data than humans to achieve reasonable performance. We propose Neural Episodic Control: a deep reinforcement learning agent that is able to rapidly assimilate new experiences and act upon them. Our agent uses a semi-tabular representation of the value function: a buffer of past experience containing slowly changing state representations and rapidly updated estimates of the value function. We show across a wide range of environments that our agent learns significantly faster than other state-of-the-art, general purpose deep reinforcement learning agents.
Learning Deep Nearest Neighbor Representations Using Differentiable Boundary Trees
Feb 28, 2017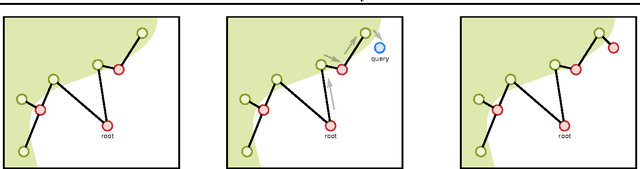
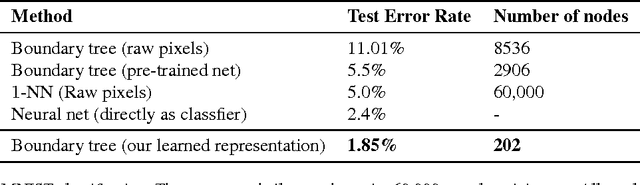
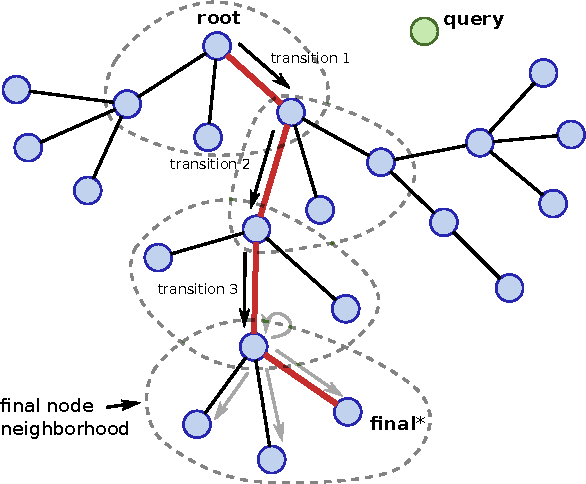
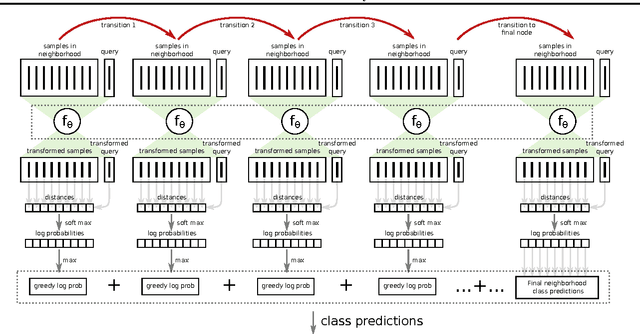
Nearest neighbor (kNN) methods have been gaining popularity in recent years in light of advances in hardware and efficiency of algorithms. There is a plethora of methods to choose from today, each with their own advantages and disadvantages. One requirement shared between all kNN based methods is the need for a good representation and distance measure between samples. We introduce a new method called differentiable boundary tree which allows for learning deep kNN representations. We build on the recently proposed boundary tree algorithm which allows for efficient nearest neighbor classification, regression and retrieval. By modelling traversals in the tree as stochastic events, we are able to form a differentiable cost function which is associated with the tree's predictions. Using a deep neural network to transform the data and back-propagating through the tree allows us to learn good representations for kNN methods. We demonstrate that our method is able to learn suitable representations allowing for very efficient trees with a clearly interpretable structure.
PathNet: Evolution Channels Gradient Descent in Super Neural Networks
Jan 30, 2017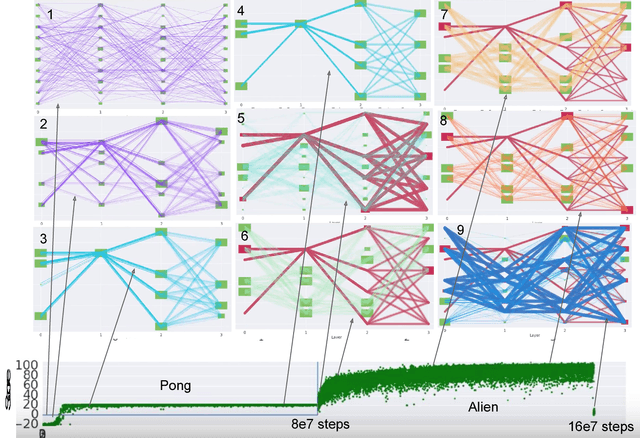
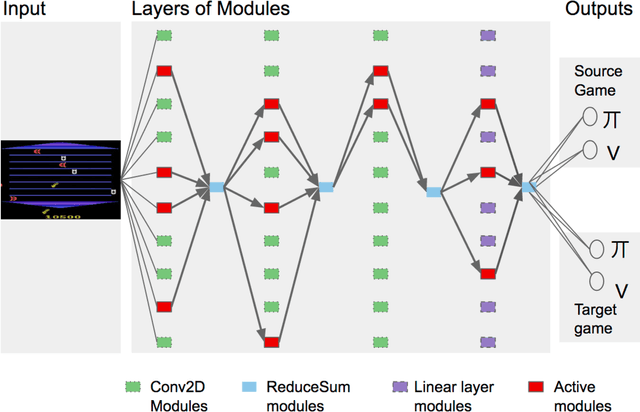
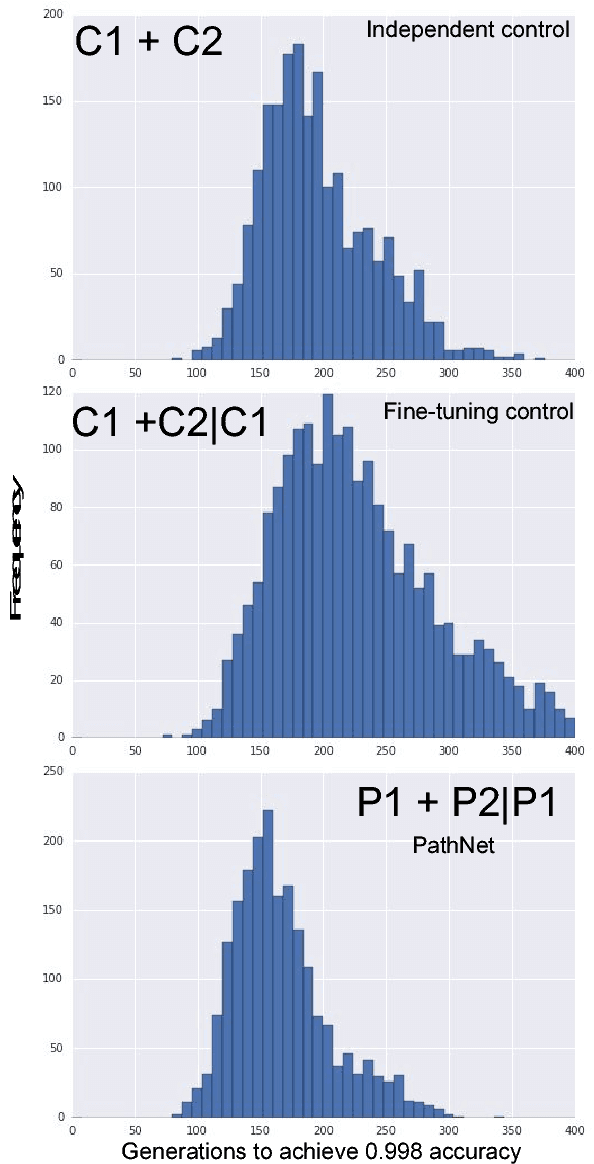
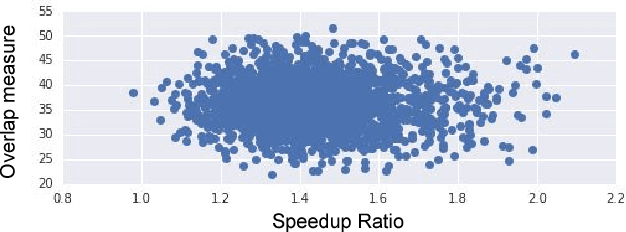
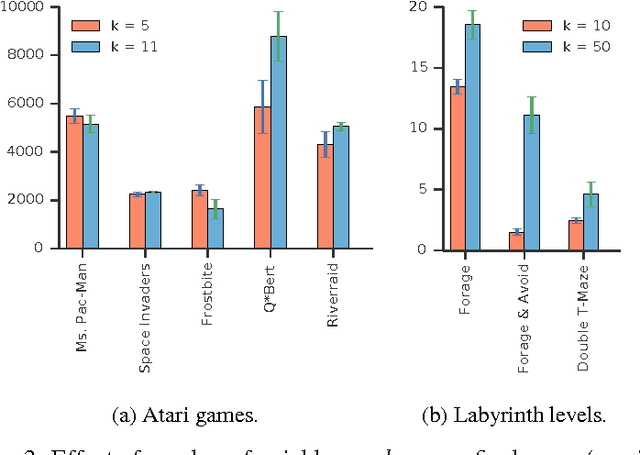
For artificial general intelligence (AGI) it would be efficient if multiple users trained the same giant neural network, permitting parameter reuse, without catastrophic forgetting. PathNet is a first step in this direction. It is a neural network algorithm that uses agents embedded in the neural network whose task is to discover which parts of the network to re-use for new tasks. Agents are pathways (views) through the network which determine the subset of parameters that are used and updated by the forwards and backwards passes of the backpropogation algorithm. During learning, a tournament selection genetic algorithm is used to select pathways through the neural network for replication and mutation. Pathway fitness is the performance of that pathway measured according to a cost function. We demonstrate successful transfer learning; fixing the parameters along a path learned on task A and re-evolving a new population of paths for task B, allows task B to be learned faster than it could be learned from scratch or after fine-tuning. Paths evolved on task B re-use parts of the optimal path evolved on task A. Positive transfer was demonstrated for binary MNIST, CIFAR, and SVHN supervised learning classification tasks, and a set of Atari and Labyrinth reinforcement learning tasks, suggesting PathNets have general applicability for neural network training. Finally, PathNet also significantly improves the robustness to hyperparameter choices of a parallel asynchronous reinforcement learning algorithm (A3C).
Learning to reinforcement learn
Jan 23, 2017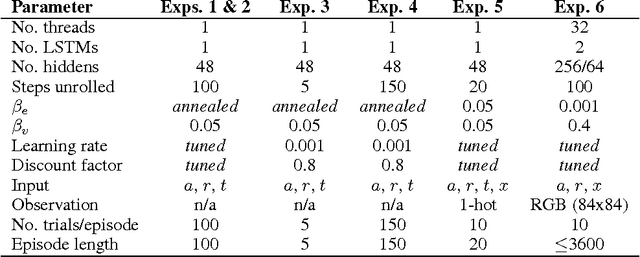
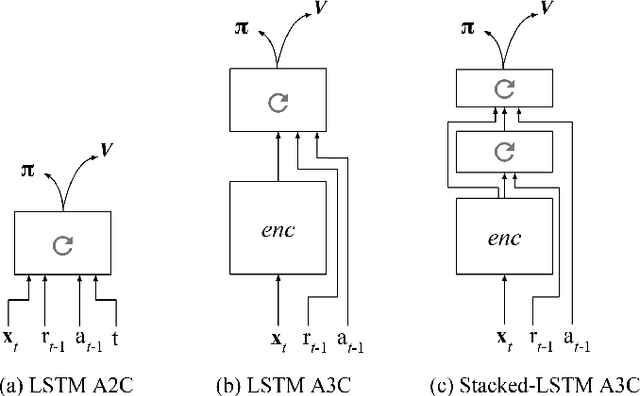
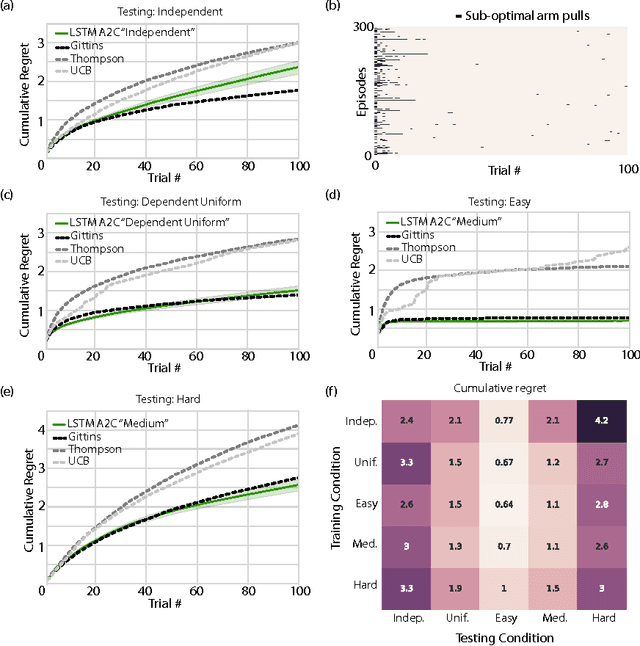
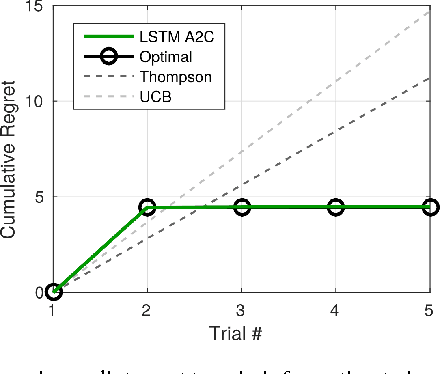
In recent years deep reinforcement learning (RL) systems have attained superhuman performance in a number of challenging task domains. However, a major limitation of such applications is their demand for massive amounts of training data. A critical present objective is thus to develop deep RL methods that can adapt rapidly to new tasks. In the present work we introduce a novel approach to this challenge, which we refer to as deep meta-reinforcement learning. Previous work has shown that recurrent networks can support meta-learning in a fully supervised context. We extend this approach to the RL setting. What emerges is a system that is trained using one RL algorithm, but whose recurrent dynamics implement a second, quite separate RL procedure. This second, learned RL algorithm can differ from the original one in arbitrary ways. Importantly, because it is learned, it is configured to exploit structure in the training domain. We unpack these points in a series of seven proof-of-concept experiments, each of which examines a key aspect of deep meta-RL. We consider prospects for extending and scaling up the approach, and also point out some potentially important implications for neuroscience.
Early Visual Concept Learning with Unsupervised Deep Learning
Sep 20, 2016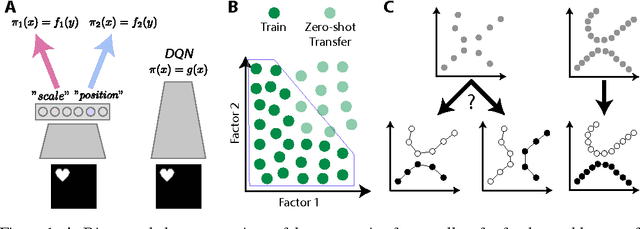
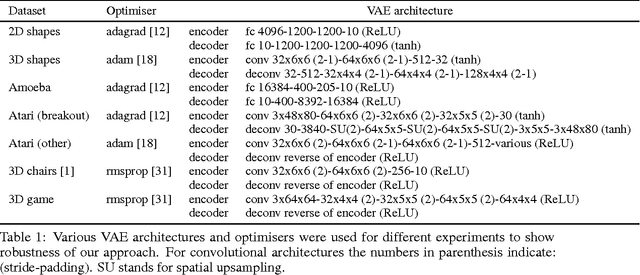
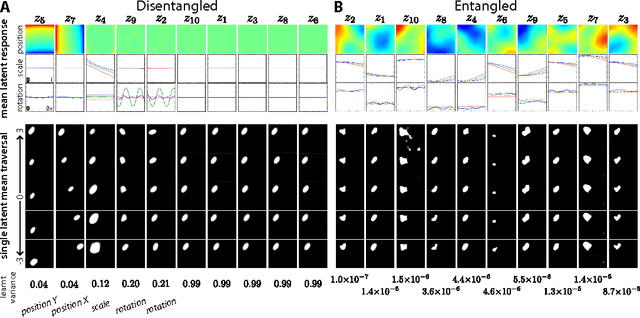

Automated discovery of early visual concepts from raw image data is a major open challenge in AI research. Addressing this problem, we propose an unsupervised approach for learning disentangled representations of the underlying factors of variation. We draw inspiration from neuroscience, and show how this can be achieved in an unsupervised generative model by applying the same learning pressures as have been suggested to act in the ventral visual stream in the brain. By enforcing redundancy reduction, encouraging statistical independence, and exposure to data with transform continuities analogous to those to which human infants are exposed, we obtain a variational autoencoder (VAE) framework capable of learning disentangled factors. Our approach makes few assumptions and works well across a wide variety of datasets. Furthermore, our solution has useful emergent properties, such as zero-shot inference and an intuitive understanding of "objectness".
Deep Exploration via Bootstrapped DQN
Jul 04, 2016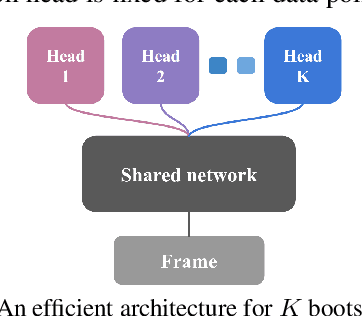
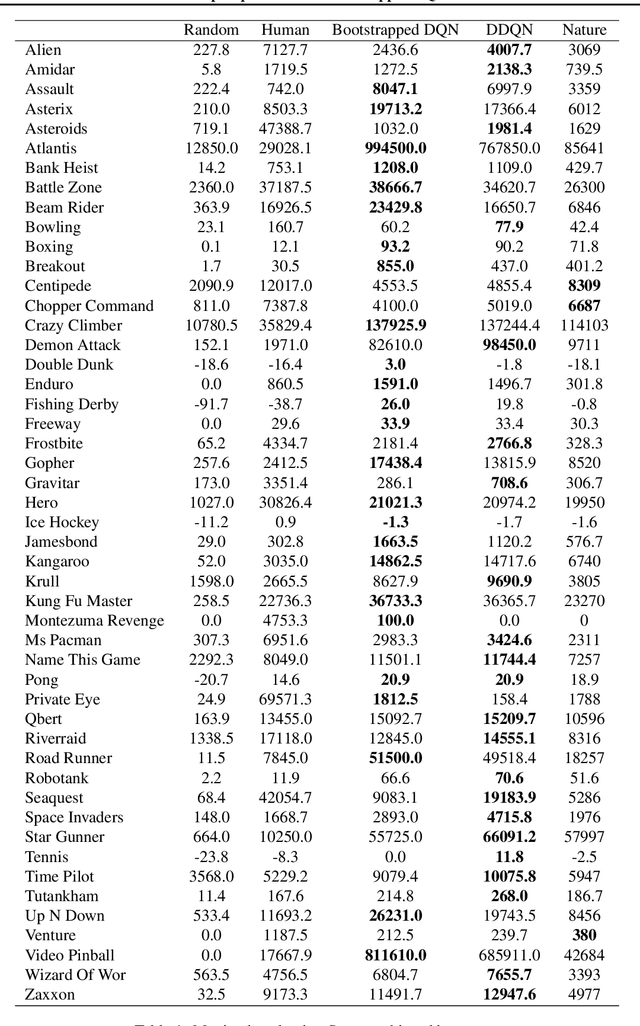
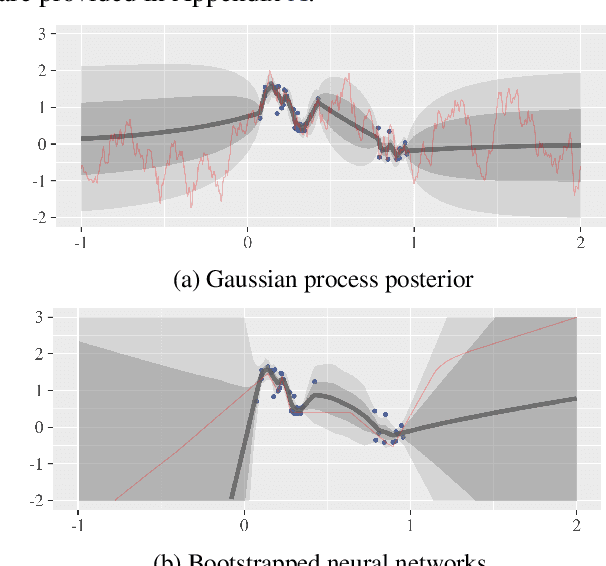
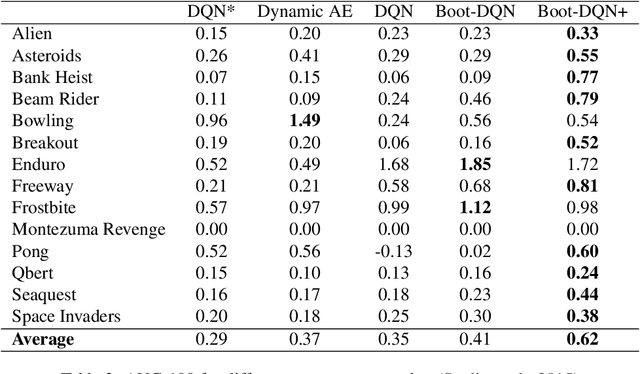
Efficient exploration in complex environments remains a major challenge for reinforcement learning. We propose bootstrapped DQN, a simple algorithm that explores in a computationally and statistically efficient manner through use of randomized value functions. Unlike dithering strategies such as epsilon-greedy exploration, bootstrapped DQN carries out temporally-extended (or deep) exploration; this can lead to exponentially faster learning. We demonstrate these benefits in complex stochastic MDPs and in the large-scale Arcade Learning Environment. Bootstrapped DQN substantially improves learning times and performance across most Atari games.
Model-Free Episodic Control
Jun 14, 2016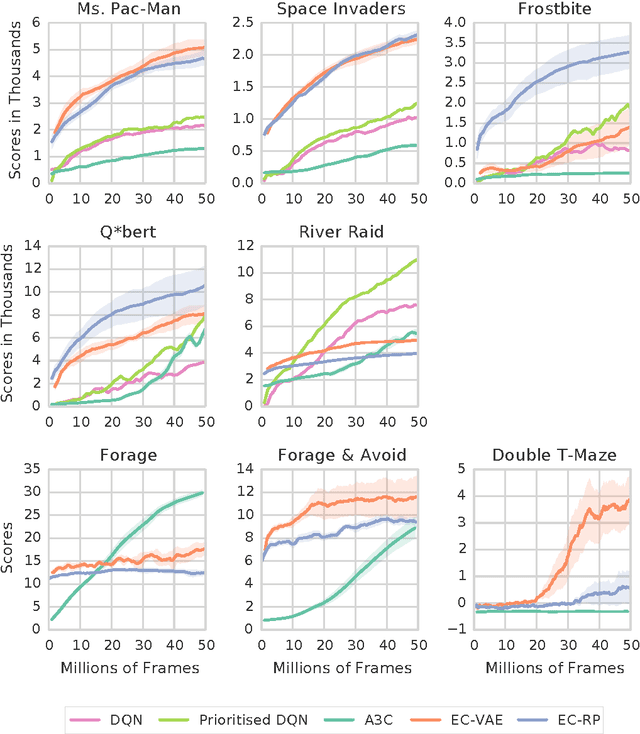

State of the art deep reinforcement learning algorithms take many millions of interactions to attain human-level performance. Humans, on the other hand, can very quickly exploit highly rewarding nuances of an environment upon first discovery. In the brain, such rapid learning is thought to depend on the hippocampus and its capacity for episodic memory. Here we investigate whether a simple model of hippocampal episodic control can learn to solve difficult sequential decision-making tasks. We demonstrate that it not only attains a highly rewarding strategy significantly faster than state-of-the-art deep reinforcement learning algorithms, but also achieves a higher overall reward on some of the more challenging domains.
Weight Uncertainty in Neural Networks
May 21, 2015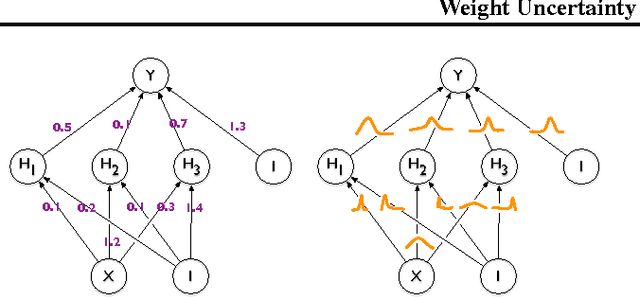
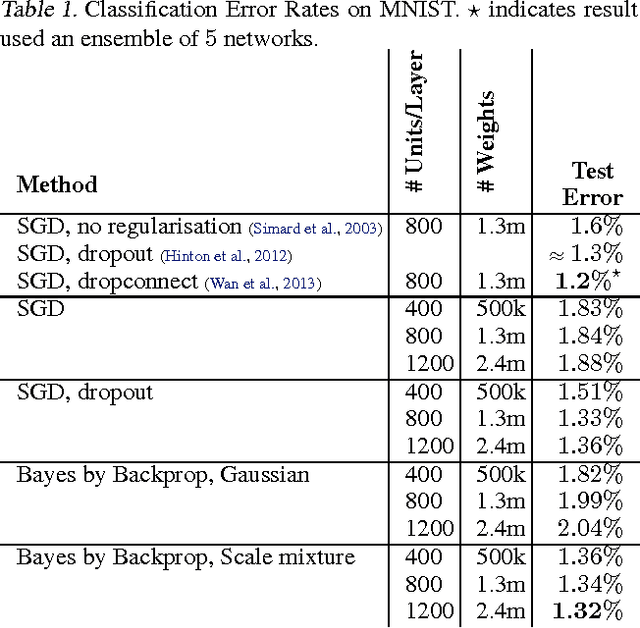
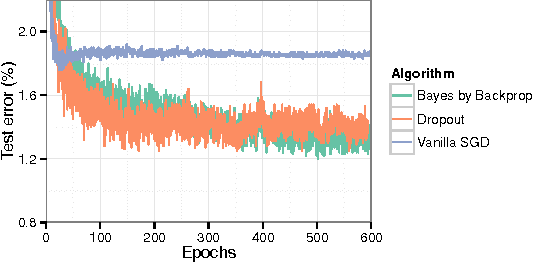

We introduce a new, efficient, principled and backpropagation-compatible algorithm for learning a probability distribution on the weights of a neural network, called Bayes by Backprop. It regularises the weights by minimising a compression cost, known as the variational free energy or the expected lower bound on the marginal likelihood. We show that this principled kind of regularisation yields comparable performance to dropout on MNIST classification. We then demonstrate how the learnt uncertainty in the weights can be used to improve generalisation in non-linear regression problems, and how this weight uncertainty can be used to drive the exploration-exploitation trade-off in reinforcement learning.
The Bayesian Echo Chamber: Modeling Social Influence via Linguistic Accommodation
Jan 27, 2015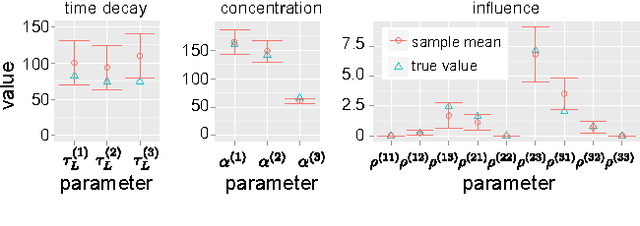

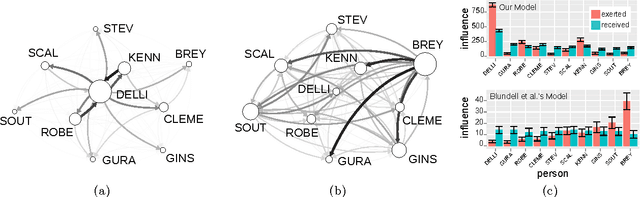
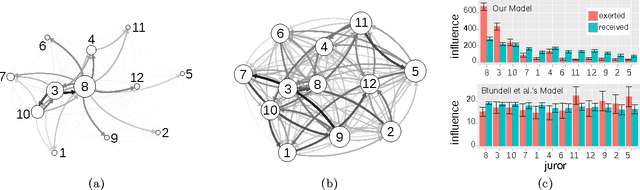
We present the Bayesian Echo Chamber, a new Bayesian generative model for social interaction data. By modeling the evolution of people's language usage over time, this model discovers latent influence relationships between them. Unlike previous work on inferring influence, which has primarily focused on simple temporal dynamics evidenced via turn-taking behavior, our model captures more nuanced influence relationships, evidenced via linguistic accommodation patterns in interaction content. The model, which is based on a discrete analog of the multivariate Hawkes process, permits a fully Bayesian inference algorithm. We validate our model's ability to discover latent influence patterns using transcripts of arguments heard by the US Supreme Court and the movie "12 Angry Men." We showcase our model's capabilities by using it to infer latent influence patterns from Federal Open Market Committee meeting transcripts, demonstrating state-of-the-art performance at uncovering social dynamics in group discussions.