 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to EdgeVipDiff: Towards Coherent and Diverse Video Inpainting via Training-free Denoising Diffusion Models
Jan 21, 2025



Recent video inpainting methods have achieved encouraging improvements by leveraging optical flow to guide pixel propagation from reference frames either in the image space or feature space. However, they would produce severe artifacts in the mask center when the masked area is too large and no pixel correspondences can be found for the center. Recently, diffusion models have demonstrated impressive performance in generating diverse and high-quality images, and have been exploited in a number of works for image inpainting. These methods, however, cannot be applied directly to videos to produce temporal-coherent inpainting results. In this paper, we propose a training-free framework, named VipDiff, for conditioning diffusion model on the reverse diffusion process to produce temporal-coherent inpainting results without requiring any training data or fine-tuning the pre-trained diffusion models. VipDiff takes optical flow as guidance to extract valid pixels from reference frames to serve as constraints in optimizing the randomly sampled Gaussian noise, and uses the generated results for further pixel propagation and conditional generation. VipDiff also allows for generating diverse video inpainting results over different sampled noise. Experiments demonstrate that VipDiff can largely outperform state-of-the-art video inpainting methods in terms of both spatial-temporal coherence and fidelity.
Image Inpainting with Edge-guided Learnable Bidirectional Attention Maps
Apr 25, 2021
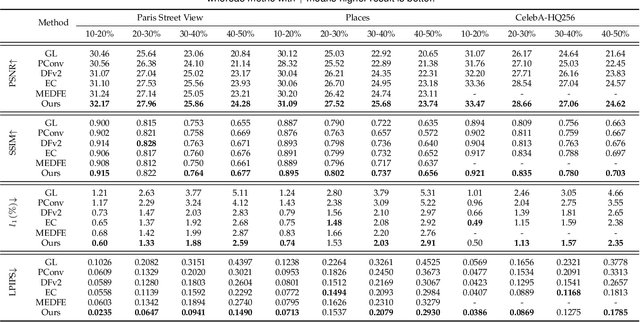

For image inpainting, the convolutional neural networks (CNN) in previous methods often adopt standard convolutional operator, which treats valid pixels and holes indistinguishably. As a result, they are limited in handling irregular holes and tend to produce color-discrepant and blurry inpainting result. Partial convolution (PConv) copes with this issue by conducting masked convolution and feature re-normalization conditioned only on valid pixels, but the mask-updating is handcrafted and independent with image structural information. In this paper, we present an edge-guided learnable bidirectional attention map (Edge-LBAM) for improving image inpainting of irregular holes with several distinct merits. Instead of using a hard 0-1 mask, a learnable attention map module is introduced for learning feature re-normalization and mask-updating in an end-to-end manner. Learnable reverse attention maps are further proposed in the decoder for emphasizing on filling in unknown pixels instead of reconstructing all pixels. Motivated by that the filling-in order is crucial to inpainting results and largely depends on image structures in exemplar-based methods, we further suggest a multi-scale edge completion network to predict coherent edges. Our Edge-LBAM method contains dual procedures,including structure-aware mask-updating guided by predict edges and attention maps generated by masks for feature re-normalization.Extensive experiments show that our Edge-LBAM is effective in generating coherent image structures and preventing color discrepancy and blurriness, and performs favorably against the state-of-the-art methods in terms of qualitative metrics and visual quality.
Learning Class-Agnostic Pseudo Mask Generation for Box-Supervised Semantic Segmentation
Mar 09, 2021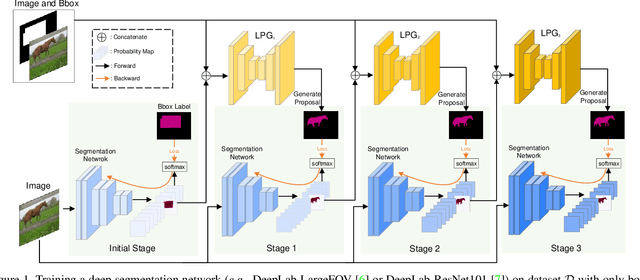

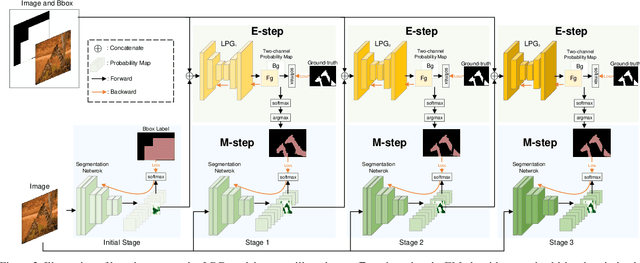
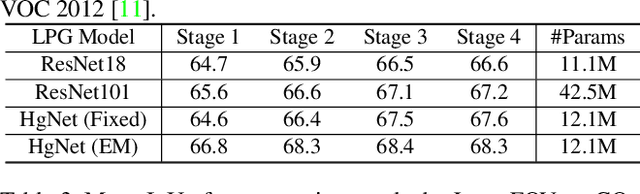
Recently, several weakly supervised learning methods have been devoted to utilize bounding box supervision for training deep semantic segmentation models. Most existing methods usually leverage the generic proposal generators (\eg, dense CRF and MCG) to produce enhanced segmentation masks for further training segmentation models. These proposal generators, however, are generic and not specifically designed for box-supervised semantic segmentation, thereby leaving some leeway for improving segmentation performance. In this paper, we aim at seeking for a more accurate learning-based class-agnostic pseudo mask generator tailored to box-supervised semantic segmentation. To this end, we resort to a pixel-level annotated auxiliary dataset where the class labels are non-overlapped with those of the box-annotated dataset. For learning pseudo mask generator from the auxiliary dataset, we present a bi-level optimization formulation. In particular, the lower subproblem is used to learn box-supervised semantic segmentation, while the upper subproblem is used to learn an optimal class-agnostic pseudo mask generator. The learned pseudo segmentation mask generator can then be deployed to the box-annotated dataset for improving weakly supervised semantic segmentation. Experiments on PASCAL VOC 2012 dataset show that the learned pseudo mask generator is effective in boosting segmentation performance, and our method can further close the performance gap between box-supervised and fully-supervised models. Our code will be made publicly available at https://github.com/Vious/LPG_BBox_Segmentation .
Image Inpainting with Learnable Bidirectional Attention Maps
Sep 05, 2019
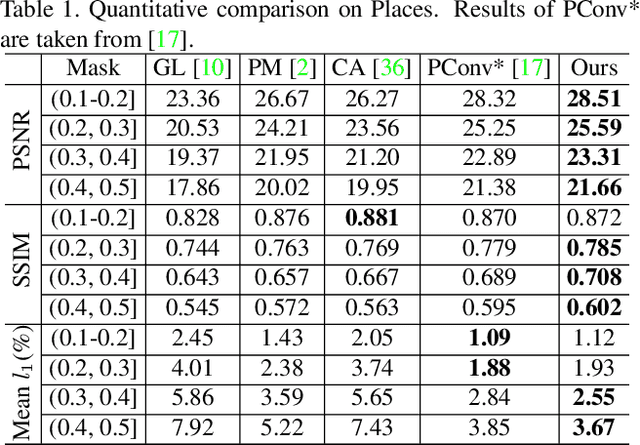
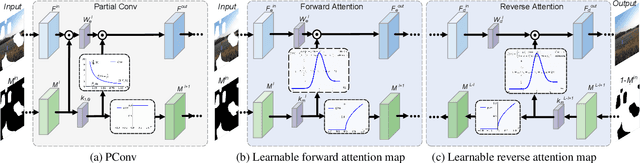

Most convolutional network (CNN)-based inpainting methods adopt standard convolution to indistinguishably treat valid pixels and holes, making them limited in handling irregular holes and more likely to generate inpainting results with color discrepancy and blurriness. Partial convolution has been suggested to address this issue, but it adopts handcrafted feature re-normalization, and only considers forward mask-updating. In this paper, we present a learnable attention map module for learning feature renormalization and mask-updating in an end-to-end manner, which is effective in adapting to irregular holes and propagation of convolution layers. Furthermore, learnable reverse attention maps are introduced to allow the decoder of U-Net to concentrate on filling in irregular holes instead of reconstructing both holes and known regions, resulting in our learnable bidirectional attention maps. Qualitative and quantitative experiments show that our method performs favorably against state-of-the-arts in generating sharper, more coherent and visually plausible inpainting results. The source code and pre-trained models will be available.