 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to EdgeAdaptive Multi-band Modulation for Robust and Low-complexity Faster-than-Nyquist Non-Orthogonal FDM IM-DD System
Dec 06, 2023Faster-than-Nyquist non-orthogonal frequency-division multiplexing (FTN-NOFDM) is robust against the steep frequency roll-off by saving signal bandwidth. Among the FTN-NOFDM techniques, the non-orthogonal matrix precoding (NOM-p) based FTN has high compatibility with the conventional orthogonal frequency division multiplexing (OFDM), in terms of the advanced digital signal processing already used in OFDM. In this work, by dividing the single band into multiple sub-bands in the NOM-p-based FTN-NOFDM system, we propose a novel FTN-NOFDM scheme with adaptive multi-band modulation. The proposed scheme assigns different quadrature amplitude modulation (QAM) levels to different sub-bands, effectively utilizing the low-pass-like channel and reducing the complexity. The impacts of sub-band number and bandwidth compression factor on the bit-error-rate (BER) performance and implementation complexity are experimentally analyzed with a 32.23-Gb/s and 20-km intensity modulation-direct detection (IM-DD) optical transmission system. Results show that the proposed scheme with proper sub-band numbers can lower BER and greatly reduce the complexity compared to the conventional single-band way.
Computational Lower Bounds for Graphon Estimation via Low-degree Polynomials
Aug 30, 2023Graphon estimation has been one of the most fundamental problems in network analysis and has received considerable attention in the past decade. From the statistical perspective, the minimax error rate of graphon estimation has been established by Gao et al (2015) for both stochastic block model (SBM) and nonparametric graphon estimation. The statistical optimal estimators are based on constrained least squares and have computational complexity exponential in the dimension. From the computational perspective, the best-known polynomial-time estimator is based on universal singular value thresholding (USVT), but it can only achieve a much slower estimation error rate than the minimax one. It is natural to wonder if such a gap is essential. The computational optimality of the USVT or the existence of a computational barrier in graphon estimation has been a long-standing open problem. In this work, we take the first step towards it and provide rigorous evidence for the computational barrier in graphon estimation via low-degree polynomials. Specifically, in both SBM and nonparametric graphon estimation, we show that for low-degree polynomial estimators, their estimation error rates cannot be significantly better than that of the USVT under a wide range of parameter regimes. Our results are proved based on the recent development of low-degree polynomials by Schramm and Wein (2022), while we overcome a few key challenges in applying it to the general graphon estimation problem. By leveraging our main results, we also provide a computational lower bound on the clustering error for community detection in SBM with a growing number of communities and this yields a new piece of evidence for the conjectured Kesten-Stigum threshold for efficient community recovery.
Sequential Attention Source Identification Based on Feature Representation
Jun 28, 2023



Snapshot observation based source localization has been widely studied due to its accessibility and low cost. However, the interaction of users in existing methods does not be addressed in time-varying infection scenarios. So these methods have a decreased accuracy in heterogeneous interaction scenarios. To solve this critical issue, this paper proposes a sequence-to-sequence based localization framework called Temporal-sequence based Graph Attention Source Identification (TGASI) based on an inductive learning idea. More specifically, the encoder focuses on generating multiple features by estimating the influence probability between two users, and the decoder distinguishes the importance of prediction sources in different timestamps by a designed temporal attention mechanism. It's worth mentioning that the inductive learning idea ensures that TGASI can detect the sources in new scenarios without knowing other prior knowledge, which proves the scalability of TGASI. Comprehensive experiments with the SOTA methods demonstrate the higher detection performance and scalability in different scenarios of TGASI.
Iterative fluctuation ghost imaging
Apr 22, 2023We present a new technique, iterative fluctuation ghost imaging (IFGI) which dramatically enhances the resolution of ghost imaging (GI). It is shown that, by the fluctuation characteristics of the second-order correlation function, the imaging information with the narrower point spread function (PSF) than the original information can be got. The effects arising from the PSF and the iteration times also be discussed.
Minimax Signal Detection in Sparse Additive Models
Apr 19, 2023Sparse additive models are an attractive choice in circumstances calling for modelling flexibility in the face of high dimensionality. We study the signal detection problem and establish the minimax separation rate for the detection of a sparse additive signal. Our result is nonasymptotic and applicable to the general case where the univariate component functions belong to a generic reproducing kernel Hilbert space. Unlike the estimation theory, the minimax separation rate reveals a nontrivial interaction between sparsity and the choice of function space. We also investigate adaptation to sparsity and establish an adaptive testing rate for a generic function space; adaptation is possible in some spaces while others impose an unavoidable cost. Finally, adaptation to both sparsity and smoothness is studied in the setting of Sobolev space, and we correct some existing claims in the literature.
Uncertainty quantification in the Bradley-Terry-Luce model
Oct 08, 2021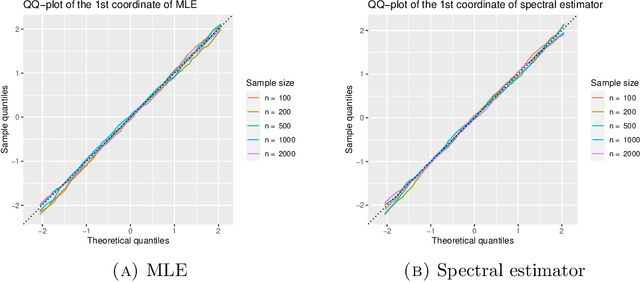
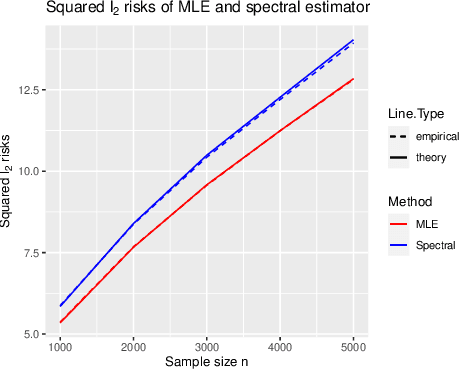
The Bradley-Terry-Luce (BTL) model is a benchmark model for pairwise comparisons between individuals. Despite recent progress on the first-order asymptotics of several popular procedures, the understanding of uncertainty quantification in the BTL model remains largely incomplete, especially when the underlying comparison graph is sparse. In this paper, we fill this gap by focusing on two estimators that have received much recent attention: the maximum likelihood estimator (MLE) and the spectral estimator. Using a unified proof strategy, we derive sharp and uniform non-asymptotic expansions for both estimators in the sparsest possible regime (up to some poly-logarithmic factors) of the underlying comparison graph. These expansions allow us to obtain: (i) finite-dimensional central limit theorems for both estimators; (ii) construction of confidence intervals for individual ranks; (iii) optimal constant of $\ell_2$ estimation, which is achieved by the MLE but not by the spectral estimator. Our proof is based on a self-consistent equation of the second-order remainder vector and a novel leave-two-out analysis.
Optimal Orthogonal Group Synchronization and Rotation Group Synchronization
Sep 28, 2021We study the statistical estimation problem of orthogonal group synchronization and rotation group synchronization. The model is $Y_{ij} = Z_i^* Z_j^{*T} + \sigma W_{ij}\in\mathbb{R}^{d\times d}$ where $W_{ij}$ is a Gaussian random matrix and $Z_i^*$ is either an orthogonal matrix or a rotation matrix, and each $Y_{ij}$ is observed independently with probability $p$. We analyze an iterative polar decomposition algorithm for the estimation of $Z^*$ and show it has an error of $(1+o(1))\frac{\sigma^2 d(d-1)}{2np}$ when initialized by spectral methods. A matching minimax lower bound is further established which leads to the optimality of the proposed algorithm as it achieves the exact minimax risk.
A Multi-modal and Multi-task Learning Method for Action Unit and Expression Recognition
Jul 15, 2021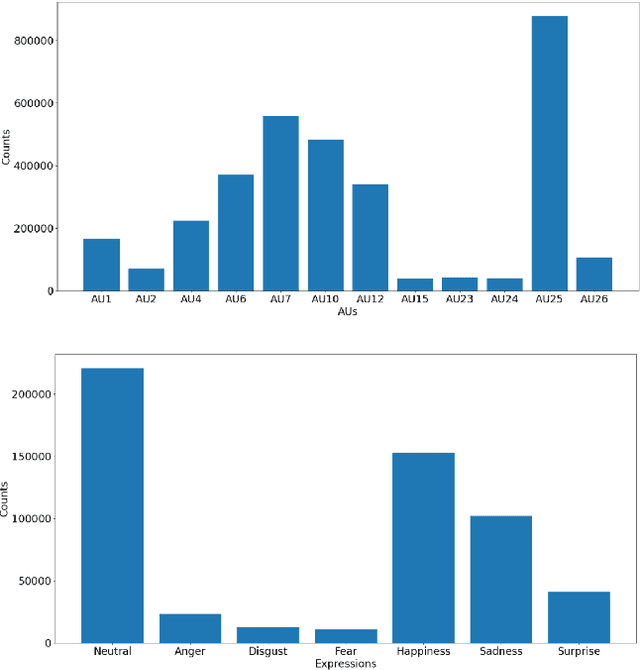

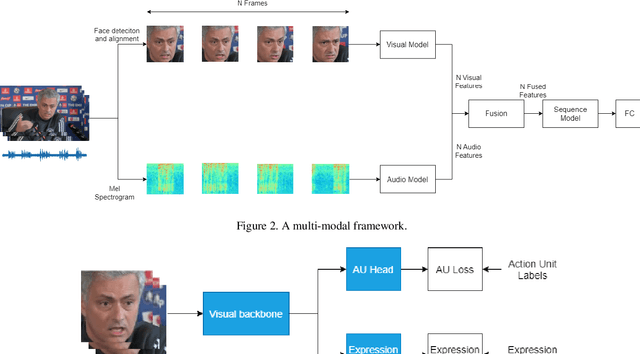
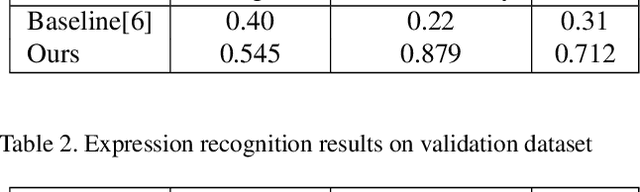
Analyzing human affect is vital for human-computer interaction systems. Most methods are developed in restricted scenarios which are not practical for in-the-wild settings. The Affective Behavior Analysis in-the-wild (ABAW) 2021 Contest provides a benchmark for this in-the-wild problem. In this paper, we introduce a multi-modal and multi-task learning method by using both visual and audio information. We use both AU and expression annotations to train the model and apply a sequence model to further extract associations between video frames. We achieve an AU score of 0.712 and an expression score of 0.477 on the validation set. These results demonstrate the effectiveness of our approach in improving model performance.
Asymptotic analysis of V-BLAST MIMO for coherent optical wireless communications in Gamma-Gamma turbulence
Jul 12, 2021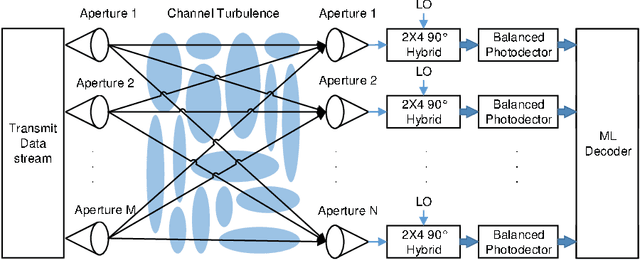
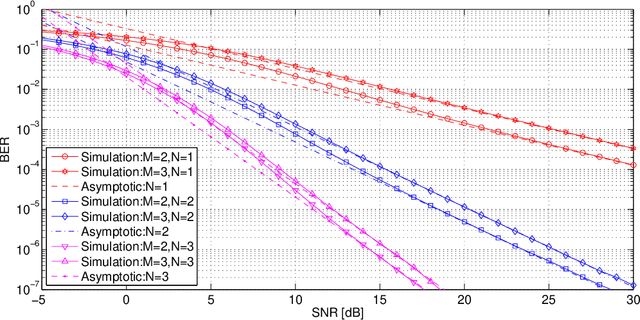
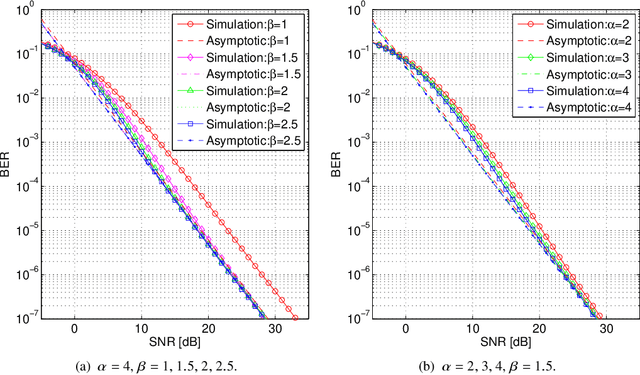
This paper investigates the asymptotic BER performance of coherent optical wireless communication systems in Gamma-Gamma turbulence when applying the V-BLAST MIMO scheme. A new method is proposed to quantify the performance of the system and mathematical solutions for asymptotic BER performance are derived. Counterintuitive results are shown since the diversity gain of the V-BLAST MIMO system is equal to the number of the receivers. As a consequence, it is shown that when applying the V-BLAST MIMO scheme, the symbol rate per transmission can be equal to the number of transmitters with some cost to diversity gain. This means that we can simultaneously exploit the spatial multiplexing and diversity properties of the MIMO system to achieve a higher data rate than existing schemes in a channel that displays severe turbulence and moderate attenuation.
On AO*, Proof Number Search and Minimax Search
Mar 30, 2021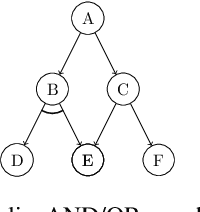
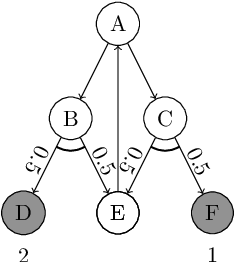
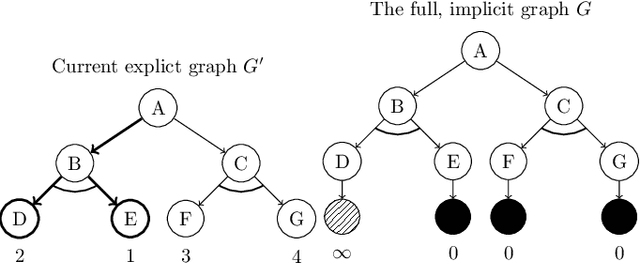
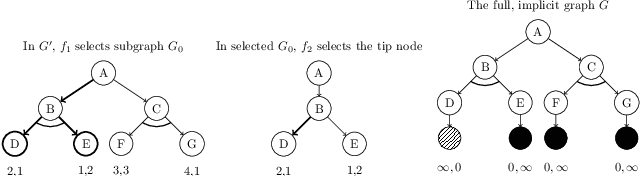
We discuss the interconnections between AO*, adversarial game-searching algorithms, e.g., proof number search and minimax search. The former was developed in the context of a general AND/OR graph model, while the latter were mostly presented in game-trees which are sometimes modeled using AND/OR trees. It is thus worth investigating to what extent these algorithms are related and how they are connected. In this paper, we explicate the interconnections between these search paradigms. We argue that generalized proof number search might be regarded as a more informed replacement of AO* for solving arbitrary AND/OR graphs, and the minimax principle might also extended to use dual heuristics.