 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to EdgeLabel-Retrieval-Augmented Diffusion Models for Learning from Noisy Labels
May 31, 2023



Learning from noisy labels is an important and long-standing problem in machine learning for real applications. One of the main research lines focuses on learning a label corrector to purify potential noisy labels. However, these methods typically rely on strict assumptions and are limited to certain types of label noise. In this paper, we reformulate the label-noise problem from a generative-model perspective, $\textit{i.e.}$, labels are generated by gradually refining an initial random guess. This new perspective immediately enables existing powerful diffusion models to seamlessly learn the stochastic generative process. Once the generative uncertainty is modeled, we can perform classification inference using maximum likelihood estimation of labels. To mitigate the impact of noisy labels, we propose the $\textbf{L}$abel-$\textbf{R}$etrieval-$\textbf{A}$ugmented (LRA) diffusion model, which leverages neighbor consistency to effectively construct pseudo-clean labels for diffusion training. Our model is flexible and general, allowing easy incorporation of different types of conditional information, $\textit{e.g.}$, use of pre-trained models, to further boost model performance. Extensive experiments are conducted for evaluation. Our model achieves new state-of-the-art (SOTA) results on all the standard real-world benchmark datasets. Remarkably, by incorporating conditional information from the powerful CLIP model, our method can boost the current SOTA accuracy by 10-20 absolute points in many cases.
A Video Is Worth 4096 Tokens: Verbalize Story Videos To Understand Them In Zero Shot
May 23, 2023



Multimedia content, such as advertisements and story videos, exhibit a rich blend of creativity and multiple modalities. They incorporate elements like text, visuals, audio, and storytelling techniques, employing devices like emotions, symbolism, and slogans to convey meaning. While previous research in multimedia understanding has focused mainly on videos with specific actions like cooking, there is a dearth of large annotated training datasets, hindering the development of supervised learning models with satisfactory performance for real-world applications. However, the rise of large language models (LLMs) has witnessed remarkable zero-shot performance in various natural language processing (NLP) tasks, such as emotion classification, question-answering, and topic classification. To bridge this performance gap in multimedia understanding, we propose verbalizing story videos to generate their descriptions in natural language and then performing video-understanding tasks on the generated story as opposed to the original video. Through extensive experiments on five video-understanding tasks, we demonstrate that our method, despite being zero-shot, achieves significantly better results than supervised baselines for video understanding. Further, alleviating a lack of story understanding benchmarks, we publicly release the first dataset on a crucial task in computational social science, persuasion strategy identification.
Prompt Tuning based Adapter for Vision-Language Model Adaption
Mar 24, 2023Large pre-trained vision-language (VL) models have shown significant promise in adapting to various downstream tasks. However, fine-tuning the entire network is challenging due to the massive number of model parameters. To address this issue, efficient adaptation methods such as prompt tuning have been proposed. We explore the idea of prompt tuning with multi-task pre-trained initialization and find it can significantly improve model performance. Based on our findings, we introduce a new model, termed Prompt-Adapter, that combines pre-trained prompt tunning with an efficient adaptation network. Our approach beat the state-of-the-art methods in few-shot image classification on the public 11 datasets, especially in settings with limited data instances such as 1 shot, 2 shots, 4 shots, and 8 shots images. Our proposed method demonstrates the promise of combining prompt tuning and parameter-efficient networks for efficient vision-language model adaptation. The code is publicly available at: https://github.com/Jingchensun/prompt_adapter.
Understanding and Constructing Latent Modality Structures in Multi-modal Representation Learning
Mar 10, 2023



Contrastive loss has been increasingly used in learning representations from multiple modalities. In the limit, the nature of the contrastive loss encourages modalities to exactly match each other in the latent space. Yet it remains an open question how the modality alignment affects the downstream task performance. In this paper, based on an information-theoretic argument, we first prove that exact modality alignment is sub-optimal in general for downstream prediction tasks. Hence we advocate that the key of better performance lies in meaningful latent modality structures instead of perfect modality alignment. To this end, we propose three general approaches to construct latent modality structures. Specifically, we design 1) a deep feature separation loss for intra-modality regularization; 2) a Brownian-bridge loss for inter-modality regularization; and 3) a geometric consistency loss for both intra- and inter-modality regularization. Extensive experiments are conducted on two popular multi-modal representation learning frameworks: the CLIP-based two-tower model and the ALBEF-based fusion model. We test our model on a variety of tasks including zero/few-shot image classification, image-text retrieval, visual question answering, visual reasoning, and visual entailment. Our method achieves consistent improvements over existing methods, demonstrating the effectiveness and generalizability of our proposed approach on latent modality structure regularization.
AUC Maximization for Low-Resource Named Entity Recognition
Dec 16, 2022



Current work in named entity recognition (NER) uses either cross entropy (CE) or conditional random fields (CRF) as the objective/loss functions to optimize the underlying NER model. Both of these traditional objective functions for the NER problem generally produce adequate performance when the data distribution is balanced and there are sufficient annotated training examples. But since NER is inherently an imbalanced tagging problem, the model performance under the low-resource settings could suffer using these standard objective functions. Based on recent advances in area under the ROC curve (AUC) maximization, we propose to optimize the NER model by maximizing the AUC score. We give evidence that by simply combining two binary-classifiers that maximize the AUC score, significant performance improvement over traditional loss functions is achieved under low-resource NER settings. We also conduct extensive experiments to demonstrate the advantages of our method under the low-resource and highly-imbalanced data distribution settings. To the best of our knowledge, this is the first work that brings AUC maximization to the NER setting. Furthermore, we show that our method is agnostic to different types of NER embeddings, models and domains. The code to replicate this work will be provided upon request.
Shifted Diffusion for Text-to-image Generation
Nov 24, 2022We present Corgi, a novel method for text-to-image generation. Corgi is based on our proposed shifted diffusion model, which achieves better image embedding generation from input text. Unlike the baseline diffusion model used in DALL-E 2, our method seamlessly encodes prior knowledge of the pre-trained CLIP model in its diffusion process by designing a new initialization distribution and a new transition step of the diffusion. Compared to the strong DALL-E 2 baseline, our method performs better in generating image embedding from the text in terms of both efficiency and effectiveness, resulting in better text-to-image generation. Extensive large-scale experiments are conducted and evaluated in terms of both quantitative measures and human evaluation, indicating a stronger generation ability of our method compared to existing ones. Furthermore, our model enables semi-supervised and language-free training for text-to-image generation, where only part or none of the images in the training dataset have an associated caption. Trained with only 1.7% of the images being captioned, our semi-supervised model obtains FID results comparable to DALL-E 2 on zero-shot text-to-image generation evaluated on MS-COCO. Corgi also achieves new state-of-the-art results across different datasets on downstream language-free text-to-image generation tasks, outperforming the previous method, Lafite, by a large margin.
Hardness-guided domain adaptation to recognise biomedical named entities under low-resource scenarios
Nov 11, 2022



Domain adaptation is an effective solution to data scarcity in low-resource scenarios. However, when applied to token-level tasks such as bioNER, domain adaptation methods often suffer from the challenging linguistic characteristics that clinical narratives possess, which leads to unsatisfactory performance. In this paper, we present a simple yet effective hardness-guided domain adaptation (HGDA) framework for bioNER tasks that can effectively leverage the domain hardness information to improve the adaptability of the learnt model in low-resource scenarios. Experimental results on biomedical datasets show that our model can achieve significant performance improvement over the recently published state-of-the-art (SOTA) MetaNER model
Lafite2: Few-shot Text-to-Image Generation
Oct 25, 2022



Text-to-image generation models have progressed considerably in recent years, which can now generate impressive realistic images from arbitrary text. Most of such models are trained on web-scale image-text paired datasets, which may not be affordable for many researchers. In this paper, we propose a novel method for pre-training text-to-image generation model on image-only datasets. It considers a retrieval-then-optimization procedure to synthesize pseudo text features: for a given image, relevant pseudo text features are first retrieved, then optimized for better alignment. The low requirement of the proposed method yields high flexibility and usability: it can be beneficial to a wide range of settings, including the few-shot, semi-supervised and fully-supervised learning; it can be applied on different models including generative adversarial networks (GANs) and diffusion models. Extensive experiments illustrate the effectiveness of the proposed method. On MS-COCO dataset, our GAN model obtains Fr\'echet Inception Distance (FID) of 6.78 which is the new state-of-the-art (SoTA) of GANs under fully-supervised setting. Our diffusion model obtains FID of 8.42 and 4.28 on zero-shot and supervised setting respectively, which are competitive to SoTA diffusion models with a much smaller model size.
Fed-CBS: A Heterogeneity-Aware Client Sampling Mechanism for Federated Learning via Class-Imbalance Reduction
Sep 30, 2022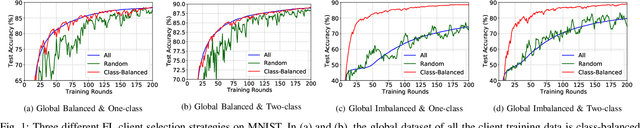
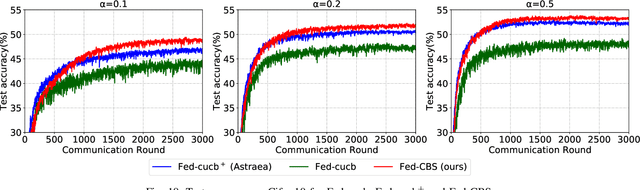
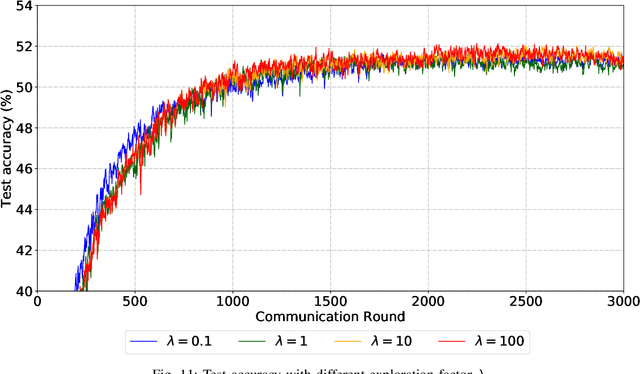
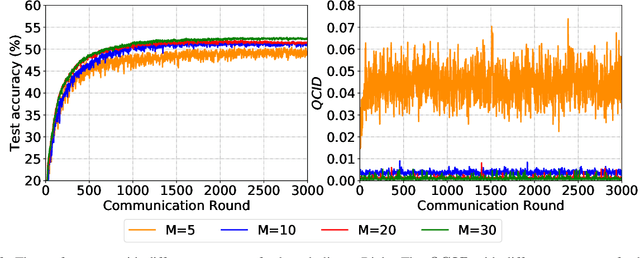
Due to limited communication capacities of edge devices, most existing federated learning (FL) methods randomly select only a subset of devices to participate in training for each communication round. Compared with engaging all the available clients, the random-selection mechanism can lead to significant performance degradation on non-IID (independent and identically distributed) data. In this paper, we show our key observation that the essential reason resulting in such performance degradation is the class-imbalance of the grouped data from randomly selected clients. Based on our key observation, we design an efficient heterogeneity-aware client sampling mechanism, i.e., Federated Class-balanced Sampling (Fed-CBS), which can effectively reduce class-imbalance of the group dataset from the intentionally selected clients. In particular, we propose a measure of class-imbalance and then employ homomorphic encryption to derive this measure in a privacy-preserving way. Based on this measure, we also design a computation-efficient client sampling strategy, such that the actively selected clients will generate a more class-balanced grouped dataset with theoretical guarantees. Extensive experimental results demonstrate Fed-CBS outperforms the status quo approaches. Furthermore, it achieves comparable or even better performance than the ideal setting where all the available clients participate in the FL training.
Persuasion Strategies in Advertisements: Dataset, Modeling, and Baselines
Aug 20, 2022
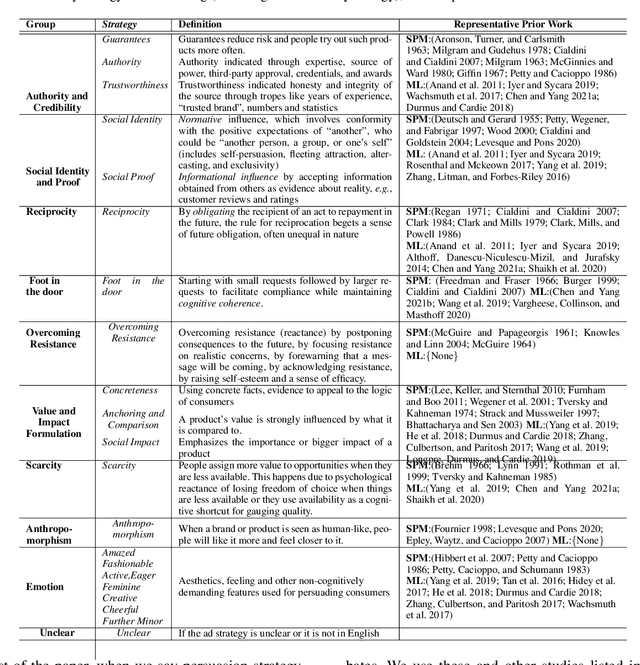
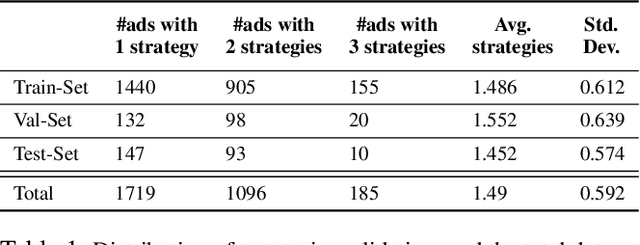

Modeling what makes an advertisement persuasive, i.e., eliciting the desired response from consumer, is critical to the study of propaganda, social psychology, and marketing. Despite its importance, computational modeling of persuasion in computer vision is still in its infancy, primarily due to the lack of benchmark datasets that can provide persuasion-strategy labels associated with ads. Motivated by persuasion literature in social psychology and marketing, we introduce an extensive vocabulary of persuasion strategies and build the first ad image corpus annotated with persuasion strategies. We then formulate the task of persuasion strategy prediction with multi-modal learning, where we design a multi-task attention fusion model that can leverage other ad-understanding tasks to predict persuasion strategies. Further, we conduct a real-world case study on 1600 advertising campaigns of 30 Fortune-500 companies where we use our model's predictions to analyze which strategies work with different demographics (age and gender). The dataset also provides image segmentation masks, which labels persuasion strategies in the corresponding ad images on the test split. We publicly release our code and dataset https://midas-research.github.io/persuasion-advertisements/.