 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to EdgeRegion-Aware Diffusion for Zero-shot Text-driven Image Editing
Feb 23, 2023Image manipulation under the guidance of textual descriptions has recently received a broad range of attention. In this study, we focus on the regional editing of images with the guidance of given text prompts. Different from current mask-based image editing methods, we propose a novel region-aware diffusion model (RDM) for entity-level image editing, which could automatically locate the region of interest and replace it following given text prompts. To strike a balance between image fidelity and inference speed, we design the intensive diffusion pipeline by combing latent space diffusion and enhanced directional guidance. In addition, to preserve image content in non-edited regions, we introduce regional-aware entity editing to modify the region of interest and preserve the out-of-interest region. We validate the proposed RDM beyond the baseline methods through extensive qualitative and quantitative experiments. The results show that RDM outperforms the previous approaches in terms of visual quality, overall harmonization, non-editing region content preservation, and text-image semantic consistency. The codes are available at https://github.com/haha-lisa/RDM-Region-Aware-Diffusion-Model.
GALIP: Generative Adversarial CLIPs for Text-to-Image Synthesis
Jan 30, 2023



Synthesizing high-fidelity complex images from text is challenging. Based on large pretraining, the autoregressive and diffusion models can synthesize photo-realistic images. Although these large models have shown notable progress, there remain three flaws. 1) These models require tremendous training data and parameters to achieve good performance. 2) The multi-step generation design slows the image synthesis process heavily. 3) The synthesized visual features are difficult to control and require delicately designed prompts. To enable high-quality, efficient, fast, and controllable text-to-image synthesis, we propose Generative Adversarial CLIPs, namely GALIP. GALIP leverages the powerful pretrained CLIP model both in the discriminator and generator. Specifically, we propose a CLIP-based discriminator. The complex scene understanding ability of CLIP enables the discriminator to accurately assess the image quality. Furthermore, we propose a CLIP-empowered generator that induces the visual concepts from CLIP through bridge features and prompts. The CLIP-integrated generator and discriminator boost training efficiency, and as a result, our model only requires about 3% training data and 6% learnable parameters, achieving comparable results to large pretrained autoregressive and diffusion models. Moreover, our model achieves 120 times faster synthesis speed and inherits the smooth latent space from GAN. The extensive experimental results demonstrate the excellent performance of our GALIP. Code is available at https://github.com/tobran/GALIP.
Unlearnable Clusters: Towards Label-agnostic Unlearnable Examples
Dec 31, 2022There is a growing interest in developing unlearnable examples (UEs) against visual privacy leaks on the Internet. UEs are training samples added with invisible but unlearnable noise, which have been found can prevent unauthorized training of machine learning models. UEs typically are generated via a bilevel optimization framework with a surrogate model to remove (minimize) errors from the original samples, and then applied to protect the data against unknown target models. However, existing UE generation methods all rely on an ideal assumption called label-consistency, where the hackers and protectors are assumed to hold the same label for a given sample. In this work, we propose and promote a more practical label-agnostic setting, where the hackers may exploit the protected data quite differently from the protectors. E.g., a m-class unlearnable dataset held by the protector may be exploited by the hacker as a n-class dataset. Existing UE generation methods are rendered ineffective in this challenging setting. To tackle this challenge, we present a novel technique called Unlearnable Clusters (UCs) to generate label-agnostic unlearnable examples with cluster-wise perturbations. Furthermore, we propose to leverage VisionandLanguage Pre-trained Models (VLPMs) like CLIP as the surrogate model to improve the transferability of the crafted UCs to diverse domains. We empirically verify the effectiveness of our proposed approach under a variety of settings with different datasets, target models, and even commercial platforms Microsoft Azure and Baidu PaddlePaddle.
SgVA-CLIP: Semantic-guided Visual Adapting of Vision-Language Models for Few-shot Image Classification
Nov 28, 2022



Although significant progress has been made in few-shot learning, most of existing few-shot learning methods require supervised pre-training on a large amount of samples of base classes, which limits their generalization ability in real world application. Recently, large-scale self-supervised vision-language models (e.g., CLIP) have provided a new paradigm for transferable visual representation learning. However, the pre-trained VLPs may neglect detailed visual information that is difficult to describe by language sentences, but important for learning an effective classifier in few-shot classification. To address the above problem, we propose a new framework, named Semantic-guided Visual Adapting (SgVA), which can effectively extend vision-language pre-trained models to produce discriminative task-specific visual features by comprehensively using a vision-specific contrastive loss, a cross-modal contrastive loss, and an implicit knowledge distillation. The implicit knowledge distillation is designed to transfer the fine-grained cross-modal knowledge to guide the updating of the vision adapter. State-of-the-art results on 13 datasets demonstrate that the adapted visual features can well complement the cross-modal features to improve few-shot image classification.
Inversion-Based Creativity Transfer with Diffusion Models
Nov 23, 2022In this paper, we introduce the task of "Creativity Transfer". The artistic creativity within a painting is the means of expression, which includes not only the painting material, colors, and brushstrokes, but also the high-level attributes including semantic elements, object shape, etc. Previous arbitrary example-guided artistic image generation methods (e.g., style transfer) often fail to control shape changes or convey semantic elements. The pre-trained text-to-image synthesis diffusion probabilistic models have achieved remarkable quality, but they often require extensive textual descriptions to accurately portray attributes of a particular painting. We believe that the uniqueness of an artwork lies precisely in the fact that it cannot be adequately explained with normal language. Our key idea is to learn artistic creativity directly from a single painting and then guide the synthesis without providing complex textual descriptions. Specifically, we assume creativity as a learnable textual description of a painting. We propose an attention-based inversion method, which can efficiently and accurately learn the holistic and detailed information of an image, thus capturing the complete artistic creativity of a painting. We demonstrate the quality and efficiency of our method on numerous paintings of various artists and styles. Code and models are available at https://github.com/zyxElsa/creativity-transfer.
DiffStyler: Controllable Dual Diffusion for Text-Driven Image Stylization
Nov 19, 2022Despite the impressive results of arbitrary image-guided style transfer methods, text-driven image stylization has recently been proposed for transferring a natural image into the stylized one according to textual descriptions of the target style provided by the user. Unlike previous image-to-image transfer approaches, text-guided stylization progress provides users with a more precise and intuitive way to express the desired style. However, the huge discrepancy between cross-modal inputs/outputs makes it challenging to conduct text-driven image stylization in a typical feed-forward CNN pipeline. In this paper, we present DiffStyler on the basis of diffusion models. The cross-modal style information can be easily integrated as guidance during the diffusion progress step-by-step. In particular, we use a dual diffusion processing architecture to control the balance between the content and style of the diffused results. Furthermore, we propose a content image-based learnable noise on which the reverse denoising process is based, enabling the stylization results to better preserve the structure information of the content image. We validate the proposed DiffStyler beyond the baseline methods through extensive qualitative and quantitative experiments.
Understanding and Mitigating Overfitting in Prompt Tuning for Vision-Language Models
Nov 14, 2022Pre-trained Vision-Language Models (VLMs) such as CLIP have shown impressive generalization capability in downstream vision tasks with appropriate text prompts. Instead of designing prompts manually, Context Optimization (CoOp) has been recently proposed to learn continuous prompts using task-specific training data. Despite the performance improvements on downstream tasks, several studies have reported that CoOp suffers from the overfitting issue in two aspects: (i) the test accuracy on base classes first gets better and then gets worse during training; (ii) the test accuracy on novel classes keeps decreasing. However, none of the existing studies can understand and mitigate such overfitting problem effectively. In this paper, we first explore the cause of overfitting by analyzing the gradient flow. Comparative experiments reveal that CoOp favors generalizable and spurious features in the early and later training stages respectively, leading to the non-overfitting and overfitting phenomenon. Given those observations, we propose Subspace Prompt Tuning (SubPT) to project the gradients in back-propagation onto the low-rank subspace spanned by the early-stage gradient flow eigenvectors during the entire training process, and successfully eliminate the overfitting problem. Besides, we equip CoOp with Novel Feature Learner (NFL) to enhance the generalization ability of the learned prompts onto novel categories beyond the training set, needless of image training data. Extensive experiments on 11 classification datasets demonstrate that SubPT+NFL consistently boost the performance of CoOp and outperform the state-of-the-art approach CoCoOp. Experiments on more challenging vision downstream tasks including open-vocabulary object detection and zero-shot semantic segmentation also verify the effectiveness of the proposed method. Codes can be found at https://tinyurl.com/mpe64f89.
Draw Your Art Dream: Diverse Digital Art Synthesis with Multimodal Guided Diffusion
Sep 28, 2022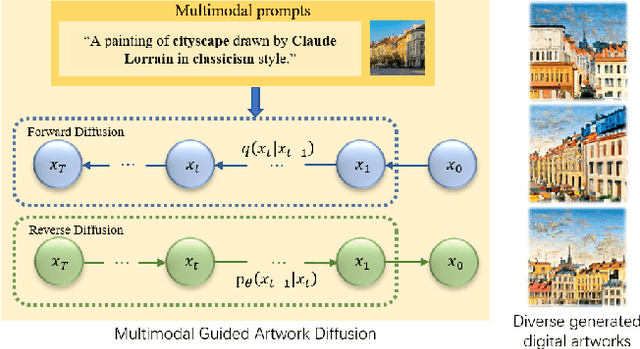



Digital art synthesis is receiving increasing attention in the multimedia community because of engaging the public with art effectively. Current digital art synthesis methods usually use single-modality inputs as guidance, thereby limiting the expressiveness of the model and the diversity of generated results. To solve this problem, we propose the multimodal guided artwork diffusion (MGAD) model, which is a diffusion-based digital artwork generation approach that utilizes multimodal prompts as guidance to control the classifier-free diffusion model. Additionally, the contrastive language-image pretraining (CLIP) model is used to unify text and image modalities. Extensive experimental results on the quality and quantity of the generated digital art paintings confirm the effectiveness of the combination of the diffusion model and multimodal guidance. Code is available at https://github.com/haha-lisa/MGAD-multimodal-guided-artwork-diffusion.
Learning Muti-expert Distribution Calibration for Long-tailed Video Classification
May 22, 2022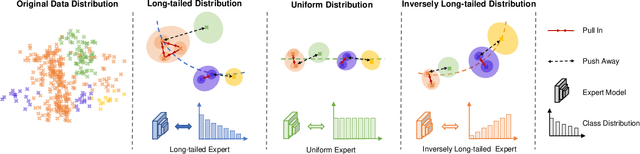
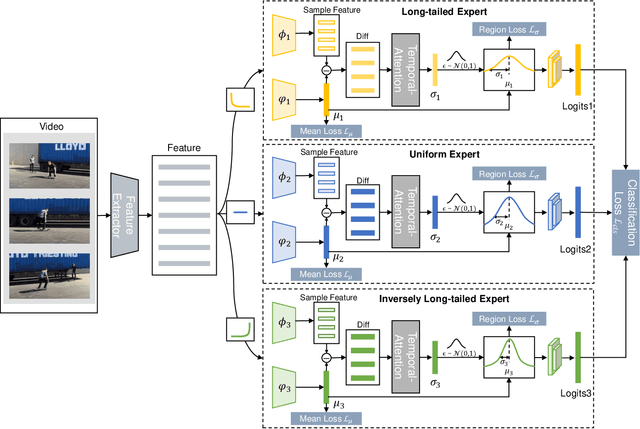

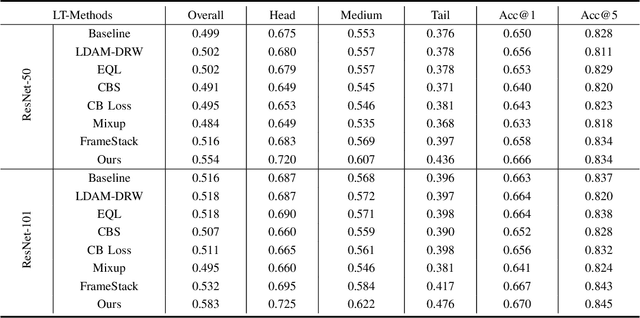
Most existing state-of-the-art video classification methods assume the training data obey a uniform distribution. However, video data in the real world typically exhibit long-tail class distribution and imbalance, which extensively results in a model bias towards head class and leads to relatively low performance on tail class. While the current long-tail classification methods usually focus on image classification, adapting it to video data is not a trivial extension. We propose an end-to-end multi-experts distribution calibration method based on two-level distribution information to address these challenges. The method jointly considers the distribution of samples in each class (intra-class distribution) and the diverse distributions of overall data (inter-class distribution) to solve the problem of imbalanced data under long-tailed distribution. By modeling this two-level distribution information, the model can consider the head classes and the tail classes and significantly transfer the knowledge from the head classes to improve the performance of the tail classes. Extensive experiments verify that our method achieves state-of-the-art performance on the long-tailed video classification task.
Domain Enhanced Arbitrary Image Style Transfer via Contrastive Learning
May 20, 2022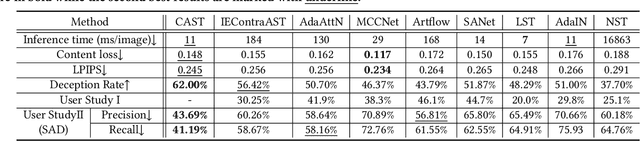

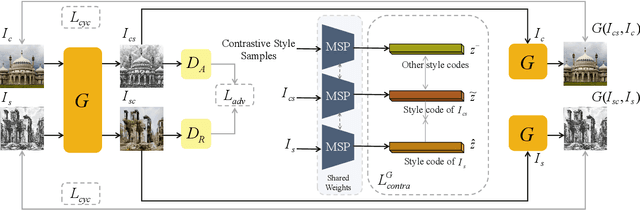
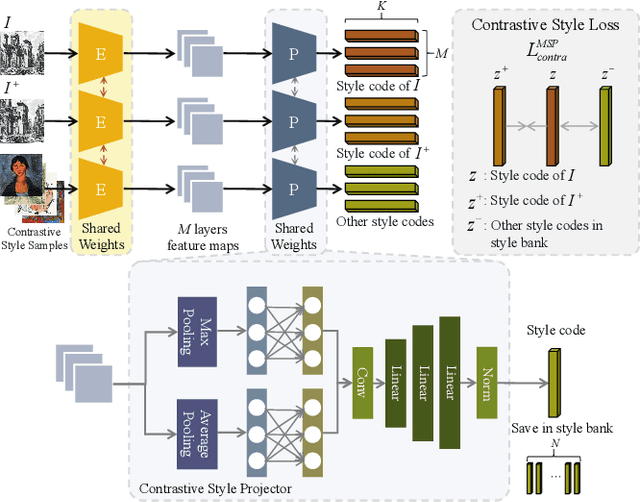
In this work, we tackle the challenging problem of arbitrary image style transfer using a novel style feature representation learning method. A suitable style representation, as a key component in image stylization tasks, is essential to achieve satisfactory results. Existing deep neural network based approaches achieve reasonable results with the guidance from second-order statistics such as Gram matrix of content features. However, they do not leverage sufficient style information, which results in artifacts such as local distortions and style inconsistency. To address these issues, we propose to learn style representation directly from image features instead of their second-order statistics, by analyzing the similarities and differences between multiple styles and considering the style distribution. Specifically, we present Contrastive Arbitrary Style Transfer (CAST), which is a new style representation learning and style transfer method via contrastive learning. Our framework consists of three key components, i.e., a multi-layer style projector for style code encoding, a domain enhancement module for effective learning of style distribution, and a generative network for image style transfer. We conduct qualitative and quantitative evaluations comprehensively to demonstrate that our approach achieves significantly better results compared to those obtained via state-of-the-art methods. Code and models are available at https://github.com/zyxElsa/CAST_pytorch