 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to EdgeNeuroClaw Technical Report
Apr 27, 2026Agentic artificial intelligence systems promise to accelerate scientific workflows, but neuroimaging poses unique challenges: heterogeneous modalities (sMRI, fMRI, dMRI, EEG), long multi-stage pipelines, and persistent reproducibility risks. To address this gap, we present NeuroClaw, a domain-specialized multi-agent research assistant for executable and reproducible neuroimaging research. NeuroClaw operates directly on raw neuroimaging data across formats and modalities, grounding decisions in dataset semantics and BIDS metadata so users need not prepare curated inputs or bespoke model code. The platform combines harness engineering with end-to-end environment management, including pinned Python environments, Docker support, automated installers for common neuroimaging tools, and GPU configuration. In practice, this layer emphasizes checkpointing, post-execution verification, structured audit traces, and controlled runtime setup, making toolchains more transparent while improving reproducibility and auditability. A three-tier skill/agent hierarchy separates user-facing interaction, high-level orchestration, and low-level tool skills to decompose complex workflows into safe, reusable units. Alongside the NeuroClaw framework, we introduce NeuroBench, a system-level benchmark for executability, artifact validity, and reproducibility readiness. Across multiple multimodal LLMs, NeuroClaw-enabled runs yield consistent and substantial score improvements compared with direct agent invocation. Project homepage: https://cuhk-aim-group.github.io/NeuroClaw/index.html
Dual-level Adaptation for Multi-Object Tracking: Building Test-Time Calibration from Experience and Intuition
Mar 23, 2026Multiple Object Tracking (MOT) has long been a fundamental task in computer vision, with broad applications in various real-world scenarios. However, due to distribution shifts in appearance, motion pattern, and catagory between the training and testing data, model performance degrades considerably during online inference in MOT. Test-Time Adaptation (TTA) has emerged as a promising paradigm to alleviate such distribution shifts. However, existing TTA methods often fail to deliver satisfactory results in MOT, as they primarily focus solely on frame-level adaptation while neglecting temporal consistency and identity association across frames and videos. Inspired by human decision-making process, this paper propose a Test-time Calibration from Experience and Intuition (TCEI) framework. In this framework, the Intuitive system utilizes transient memory to recall recently observed objects for rapid predictions, while the Experiential system leverages the accumulated experience from prior test videos to reassess and calibrate these intuitive predictions. Furthermore, both confident and uncertain objects during online testing are exploited as historical priors and reflective cases, respectively, enabling the model to adapt to the testing environment and alleviate performance degradation. Extensive experiments demonstrate that the proposed TCEI framework consistently achieves superior performance across multiple benchmark datasets and significantly enhances the model's adaptability under distribution shifts. The code will be released at https://github.com/1941Zpf/TCEI.
Learning Muti-expert Distribution Calibration for Long-tailed Video Classification
May 22, 2022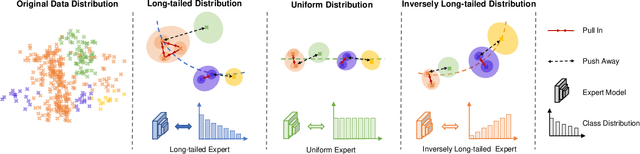
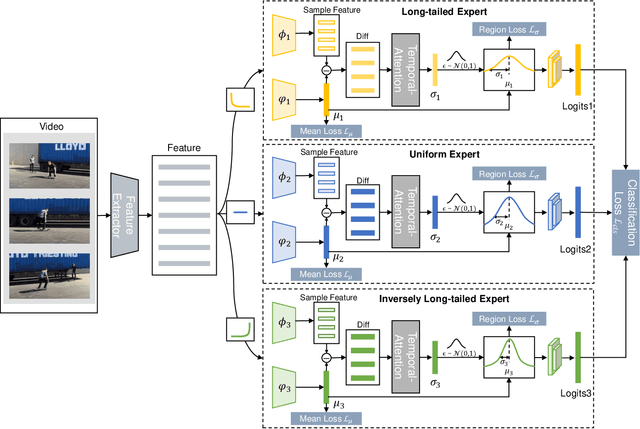

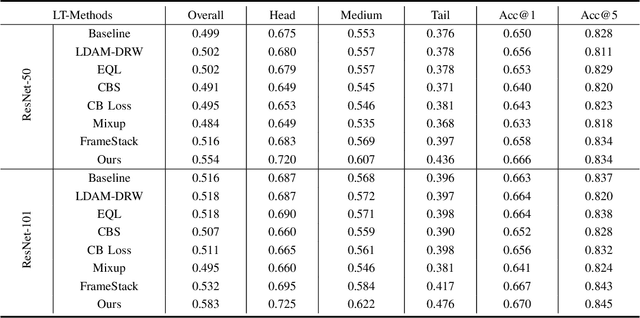
Most existing state-of-the-art video classification methods assume the training data obey a uniform distribution. However, video data in the real world typically exhibit long-tail class distribution and imbalance, which extensively results in a model bias towards head class and leads to relatively low performance on tail class. While the current long-tail classification methods usually focus on image classification, adapting it to video data is not a trivial extension. We propose an end-to-end multi-experts distribution calibration method based on two-level distribution information to address these challenges. The method jointly considers the distribution of samples in each class (intra-class distribution) and the diverse distributions of overall data (inter-class distribution) to solve the problem of imbalanced data under long-tailed distribution. By modeling this two-level distribution information, the model can consider the head classes and the tail classes and significantly transfer the knowledge from the head classes to improve the performance of the tail classes. Extensive experiments verify that our method achieves state-of-the-art performance on the long-tailed video classification task.