 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to EdgeExcitation Trajectory Optimization for Dynamic Parameter Identification Using Virtual Constraints in Hands-on Robotic System
Jan 29, 2024



This paper proposes a novel, more computationally efficient method for optimizing robot excitation trajectories for dynamic parameter identification, emphasizing self-collision avoidance. This addresses the system identification challenges for getting high-quality training data associated with co-manipulated robotic arms that can be equipped with a variety of tools, a common scenario in industrial but also clinical and research contexts. Utilizing the Unified Robotics Description Format (URDF) to implement a symbolic Python implementation of the Recursive Newton-Euler Algorithm (RNEA), the approach aids in dynamically estimating parameters such as inertia using regression analyses on data from real robots. The excitation trajectory was evaluated and achieved on par criteria when compared to state-of-the-art reported results which didn't consider self-collision and tool calibrations. Furthermore, physical Human-Robot Interaction (pHRI) admittance control experiments were conducted in a surgical context to evaluate the derived inverse dynamics model showing a 30.1\% workload reduction by the NASA TLX questionnaire.
Learning to Generate Parameters of ConvNets for Unseen Image Data
Oct 24, 2023



Typical Convolutional Neural Networks (ConvNets) depend heavily on large amounts of image data and resort to an iterative optimization algorithm (e.g., SGD or Adam) to learn network parameters, which makes training very time- and resource-intensive. In this paper, we propose a new training paradigm and formulate the parameter learning of ConvNets into a prediction task: given a ConvNet architecture, we observe there exists correlations between image datasets and their corresponding optimal network parameters, and explore if we can learn a hyper-mapping between them to capture the relations, such that we can directly predict the parameters of the network for an image dataset never seen during the training phase. To do this, we put forward a new hypernetwork based model, called PudNet, which intends to learn a mapping between datasets and their corresponding network parameters, and then predicts parameters for unseen data with only a single forward propagation. Moreover, our model benefits from a series of adaptive hyper recurrent units sharing weights to capture the dependencies of parameters among different network layers. Extensive experiments demonstrate that our proposed method achieves good efficacy for unseen image datasets on two kinds of settings: Intra-dataset prediction and Inter-dataset prediction. Our PudNet can also well scale up to large-scale datasets, e.g., ImageNet-1K. It takes 8967 GPU seconds to train ResNet-18 on the ImageNet-1K using GC from scratch and obtain a top-5 accuracy of 44.65 %. However, our PudNet costs only 3.89 GPU seconds to predict the network parameters of ResNet-18 achieving comparable performance (44.92 %), more than 2,300 times faster than the traditional training paradigm.
DREAM: Domain-free Reverse Engineering Attributes of Black-box Model
Jul 20, 2023



Deep learning models are usually black boxes when deployed on machine learning platforms. Prior works have shown that the attributes ($e.g.$, the number of convolutional layers) of a target black-box neural network can be exposed through a sequence of queries. There is a crucial limitation: these works assume the dataset used for training the target model to be known beforehand and leverage this dataset for model attribute attack. However, it is difficult to access the training dataset of the target black-box model in reality. Therefore, whether the attributes of a target black-box model could be still revealed in this case is doubtful. In this paper, we investigate a new problem of Domain-agnostic Reverse Engineering the Attributes of a black-box target Model, called DREAM, without requiring the availability of the target model's training dataset, and put forward a general and principled framework by casting this problem as an out of distribution (OOD) generalization problem. In this way, we can learn a domain-agnostic model to inversely infer the attributes of a target black-box model with unknown training data. This makes our method one of the kinds that can gracefully apply to an arbitrary domain for model attribute reverse engineering with strong generalization ability. Extensive experimental studies are conducted and the results validate the superiority of our proposed method over the baselines.
Shared Growth of Graph Neural Networks via Free-direction Knowledge Distillation
Jul 08, 2023Knowledge distillation (KD) has shown to be effective to boost the performance of graph neural networks (GNNs), where the typical objective is to distill knowledge from a deeper teacher GNN into a shallower student GNN. However, it is often quite challenging to train a satisfactory deeper GNN due to the well-known over-parametrized and over-smoothing issues, leading to invalid knowledge transfer in practical applications. In this paper, we propose the first Free-direction Knowledge Distillation framework via reinforcement learning for GNNs, called FreeKD, which is no longer required to provide a deeper well-optimized teacher GNN. Our core idea is to collaboratively learn two shallower GNNs in an effort to exchange knowledge between them via reinforcement learning in a hierarchical way. As we observe that one typical GNN model often exhibits better and worse performances at different nodes during training, we devise a dynamic and free-direction knowledge transfer strategy that involves two levels of actions: 1) node-level action determines the directions of knowledge transfer between the corresponding nodes of two networks; and then 2) structure-level action determines which of the local structures generated by the node-level actions to be propagated. Furthermore, considering the diverse knowledge present in different GNNs when dealing with multi-view inputs, we introduce FreeKD++ as a solution to enable free-direction knowledge transfer among multiple shallow GNNs operating on multi-view inputs. Extensive experiments on five benchmark datasets demonstrate our approaches outperform the base GNNs in a large margin, and shows their efficacy to various GNNs. More surprisingly, our FreeKD has comparable or even better performance than traditional KD algorithms that distill knowledge from a deeper and stronger teacher GNN.
Detecting Adversarial Data by Probing Multiple Perturbations Using Expected Perturbation Score
May 25, 2023



Adversarial detection aims to determine whether a given sample is an adversarial one based on the discrepancy between natural and adversarial distributions. Unfortunately, estimating or comparing two data distributions is extremely difficult, especially in high-dimension spaces. Recently, the gradient of log probability density (a.k.a., score) w.r.t. the sample is used as an alternative statistic to compute. However, we find that the score is sensitive in identifying adversarial samples due to insufficient information with one sample only. In this paper, we propose a new statistic called expected perturbation score (EPS), which is essentially the expected score of a sample after various perturbations. Specifically, to obtain adequate information regarding one sample, we perturb it by adding various noises to capture its multi-view observations. We theoretically prove that EPS is a proper statistic to compute the discrepancy between two samples under mild conditions. In practice, we can use a pre-trained diffusion model to estimate EPS for each sample. Last, we propose an EPS-based adversarial detection (EPS-AD) method, in which we develop EPS-based maximum mean discrepancy (MMD) as a metric to measure the discrepancy between the test sample and natural samples. We also prove that the EPS-based MMD between natural and adversarial samples is larger than that among natural samples. Extensive experiments show the superior adversarial detection performance of our EPS-AD.
Towards Open Temporal Graph Neural Networks
Mar 27, 2023Graph neural networks (GNNs) for temporal graphs have recently attracted increasing attentions, where a common assumption is that the class set for nodes is closed. However, in real-world scenarios, it often faces the open set problem with the dynamically increased class set as the time passes by. This will bring two big challenges to the existing dynamic GNN methods: (i) How to dynamically propagate appropriate information in an open temporal graph, where new class nodes are often linked to old class nodes. This case will lead to a sharp contradiction. This is because typical GNNs are prone to make the embeddings of connected nodes become similar, while we expect the embeddings of these two interactive nodes to be distinguishable since they belong to different classes. (ii) How to avoid catastrophic knowledge forgetting over old classes when learning new classes occurred in temporal graphs. In this paper, we propose a general and principled learning approach for open temporal graphs, called OTGNet, with the goal of addressing the above two challenges. We assume the knowledge of a node can be disentangled into class-relevant and class-agnostic one, and thus explore a new message passing mechanism by extending the information bottleneck principle to only propagate class-agnostic knowledge between nodes of different classes, avoiding aggregating conflictive information. Moreover, we devise a strategy to select both important and diverse triad sub-graph structures for effective class-incremental learning. Extensive experiments on three real-world datasets of different domains demonstrate the superiority of our method, compared to the baselines.
Robust Knowledge Adaptation for Dynamic Graph Neural Networks
Jul 22, 2022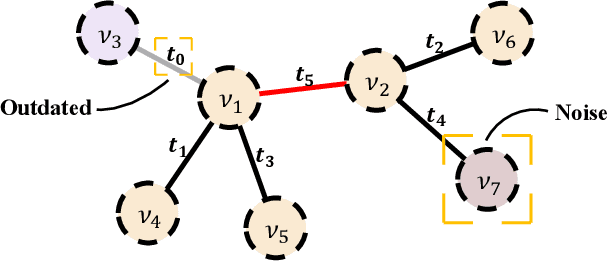

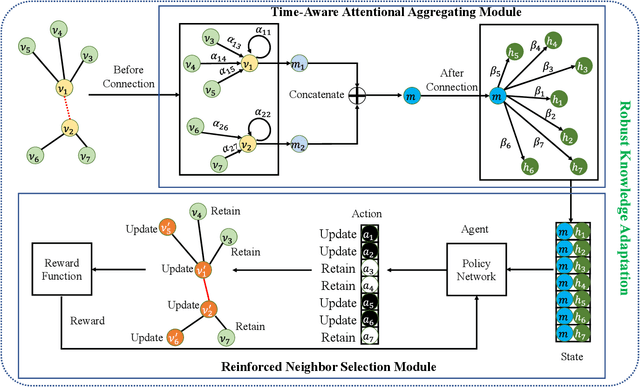
Graph structured data often possess dynamic characters in nature, e.g., the addition of links and nodes, in many real-world applications. Recent years have witnessed the increasing attentions paid to dynamic graph neural networks for modelling such graph data, where almost all the existing approaches assume that when a new link is built, the embeddings of the neighbor nodes should be updated by learning the temporal dynamics to propagate new information. However, such approaches suffer from the limitation that if the node introduced by a new connection contains noisy information, propagating its knowledge to other nodes is not reliable and even leads to the collapse of the model. In this paper, we propose AdaNet: a robust knowledge Adaptation framework via reinforcement learning for dynamic graph neural Networks. In contrast to previous approaches immediately updating the embeddings of the neighbor nodes once adding a new link, AdaNet attempts to adaptively determine which nodes should be updated because of the new link involved. Considering that the decision whether to update the embedding of one neighbor node will have great impact on other neighbor nodes, we thus formulate the selection of node update as a sequence decision problem, and address this problem via reinforcement learning. By this means, we can adaptively propagate knowledge to other nodes for learning robust node embedding representations. To the best of our knowledge, our approach constitutes the first attempt to explore robust knowledge adaptation via reinforcement learning for dynamic graph neural networks. Extensive experiments on three benchmark datasets demonstrate that AdaNet achieves the state-of-the-art performance. In addition, we perform the experiments by adding different degrees of noise into the dataset, quantitatively and qualitatively illustrating the robustness of AdaNet.
Multi-Prior Learning via Neural Architecture Search for Blind Face Restoration
Jun 28, 2022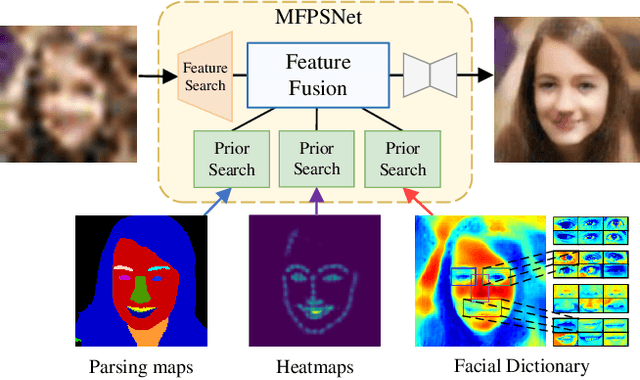
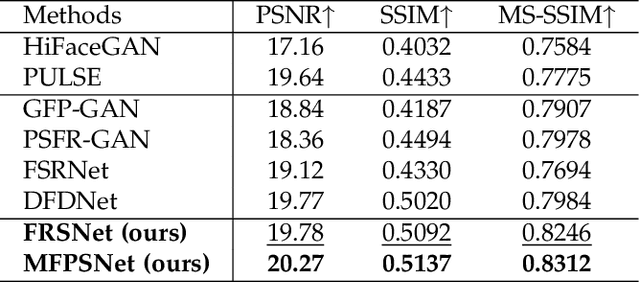
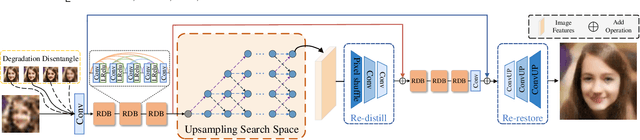
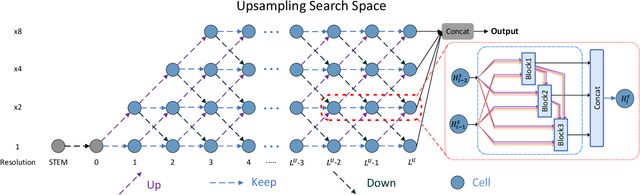
Blind Face Restoration (BFR) aims to recover high-quality face images from low-quality ones and usually resorts to facial priors for improving restoration performance. However, current methods still suffer from two major difficulties: 1) how to derive a powerful network architecture without extensive hand tuning; 2) how to capture complementary information from multiple facial priors in one network to improve restoration performance. To this end, we propose a Face Restoration Searching Network (FRSNet) to adaptively search the suitable feature extraction architecture within our specified search space, which can directly contribute to the restoration quality. On the basis of FRSNet, we further design our Multiple Facial Prior Searching Network (MFPSNet) with a multi-prior learning scheme. MFPSNet optimally extracts information from diverse facial priors and fuses the information into image features, ensuring that both external guidance and internal features are reserved. In this way, MFPSNet takes full advantage of semantic-level (parsing maps), geometric-level (facial heatmaps), reference-level (facial dictionaries) and pixel-level (degraded images) information and thus generates faithful and realistic images. Quantitative and qualitative experiments show that MFPSNet performs favorably on both synthetic and real-world datasets against the state-of-the-art BFR methods. The codes are publicly available at: https://github.com/YYJ1anG/MFPSNet.
FreeKD: Free-direction Knowledge Distillation for Graph Neural Networks
Jun 21, 2022
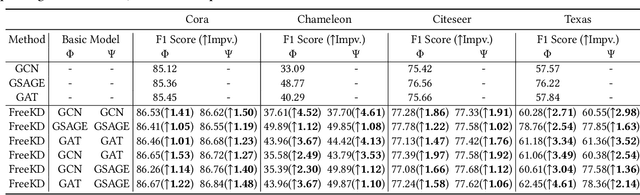
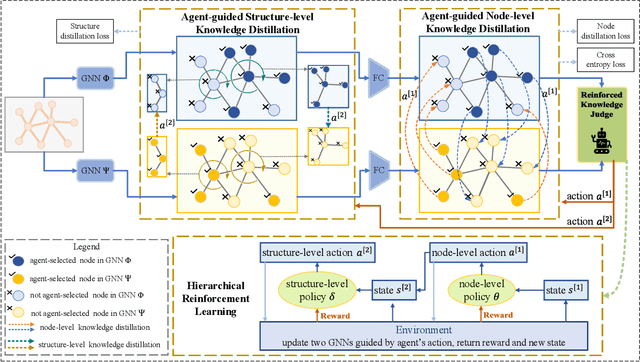
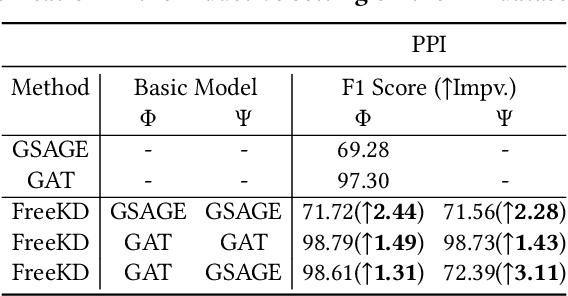
Knowledge distillation (KD) has demonstrated its effectiveness to boost the performance of graph neural networks (GNNs), where its goal is to distill knowledge from a deeper teacher GNN into a shallower student GNN. However, it is actually difficult to train a satisfactory teacher GNN due to the well-known over-parametrized and over-smoothing issues, leading to invalid knowledge transfer in practical applications. In this paper, we propose the first Free-direction Knowledge Distillation framework via Reinforcement learning for GNNs, called FreeKD, which is no longer required to provide a deeper well-optimized teacher GNN. The core idea of our work is to collaboratively build two shallower GNNs in an effort to exchange knowledge between them via reinforcement learning in a hierarchical way. As we observe that one typical GNN model often has better and worse performances at different nodes during training, we devise a dynamic and free-direction knowledge transfer strategy that consists of two levels of actions: 1) node-level action determines the directions of knowledge transfer between the corresponding nodes of two networks; and then 2) structure-level action determines which of the local structures generated by the node-level actions to be propagated. In essence, our FreeKD is a general and principled framework which can be naturally compatible with GNNs of different architectures. Extensive experiments on five benchmark datasets demonstrate our FreeKD outperforms two base GNNs in a large margin, and shows its efficacy to various GNNs. More surprisingly, our FreeKD has comparable or even better performance than traditional KD algorithms that distill knowledge from a deeper and stronger teacher GNN.
Blind Face Restoration: Benchmark Datasets and a Baseline Model
Jun 08, 2022
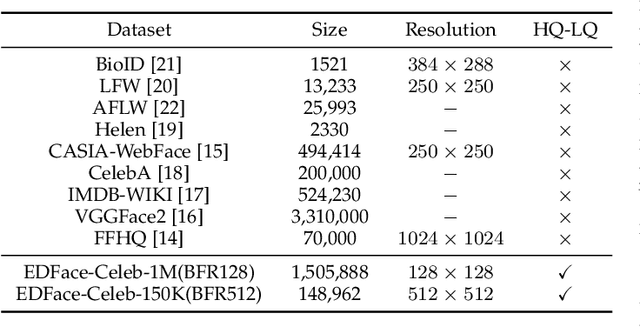


Blind Face Restoration (BFR) aims to construct a high-quality (HQ) face image from its corresponding low-quality (LQ) input. Recently, many BFR methods have been proposed and they have achieved remarkable success. However, these methods are trained or evaluated on privately synthesized datasets, which makes it infeasible for the subsequent approaches to fairly compare with them. To address this problem, we first synthesize two blind face restoration benchmark datasets called EDFace-Celeb-1M (BFR128) and EDFace-Celeb-150K (BFR512). State-of-the-art methods are benchmarked on them under five settings including blur, noise, low resolution, JPEG compression artifacts, and the combination of them (full degradation). To make the comparison more comprehensive, five widely-used quantitative metrics and two task-driven metrics including Average Face Landmark Distance (AFLD) and Average Face ID Cosine Similarity (AFICS) are applied. Furthermore, we develop an effective baseline model called Swin Transformer U-Net (STUNet). The STUNet with U-net architecture applies an attention mechanism and a shifted windowing scheme to capture long-range pixel interactions and focus more on significant features while still being trained efficiently. Experimental results show that the proposed baseline method performs favourably against the SOTA methods on various BFR tasks.