 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to EdgeExplaining black box text modules in natural language with language models
May 17, 2023



Large language models (LLMs) have demonstrated remarkable prediction performance for a growing array of tasks. However, their rapid proliferation and increasing opaqueness have created a growing need for interpretability. Here, we ask whether we can automatically obtain natural language explanations for black box text modules. A "text module" is any function that maps text to a scalar continuous value, such as a submodule within an LLM or a fitted model of a brain region. "Black box" indicates that we only have access to the module's inputs/outputs. We introduce Summarize and Score (SASC), a method that takes in a text module and returns a natural language explanation of the module's selectivity along with a score for how reliable the explanation is. We study SASC in 3 contexts. First, we evaluate SASC on synthetic modules and find that it often recovers ground truth explanations. Second, we use SASC to explain modules found within a pre-trained BERT model, enabling inspection of the model's internals. Finally, we show that SASC can generate explanations for the response of individual fMRI voxels to language stimuli, with potential applications to fine-grained brain mapping. All code for using SASC and reproducing results is made available on Github.
Explaining Patterns in Data with Language Models via Interpretable Autoprompting
Oct 04, 2022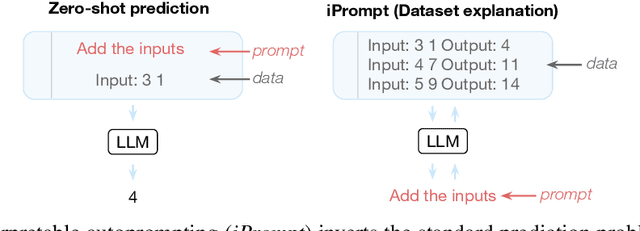
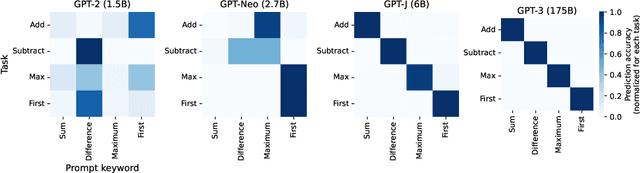

Large language models (LLMs) have displayed an impressive ability to harness natural language to perform complex tasks. In this work, we explore whether we can leverage this learned ability to find and explain patterns in data. Specifically, given a pre-trained LLM and data examples, we introduce interpretable autoprompting (iPrompt), an algorithm that generates a natural-language string explaining the data. iPrompt iteratively alternates between generating explanations with an LLM and reranking them based on their performance when used as a prompt. Experiments on a wide range of datasets, from synthetic mathematics to natural-language understanding, show that iPrompt can yield meaningful insights by accurately finding groundtruth dataset descriptions. Moreover, the prompts produced by iPrompt are simultaneously human-interpretable and highly effective for generalization: on real-world sentiment classification datasets, iPrompt produces prompts that match or even improve upon human-written prompts for GPT-3. Finally, experiments with an fMRI dataset show the potential for iPrompt to aid in scientific discovery. All code for using the methods and data here is made available on Github.
Emb-GAM: an Interpretable and Efficient Predictor using Pre-trained Language Models
Sep 23, 2022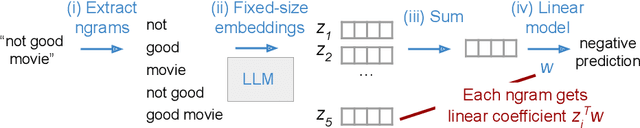

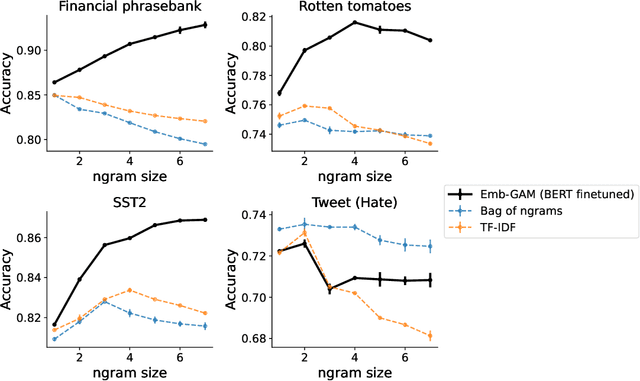

Deep learning models have achieved impressive prediction performance but often sacrifice interpretability, a critical consideration in high-stakes domains such as healthcare or policymaking. In contrast, generalized additive models (GAMs) can maintain interpretability but often suffer from poor prediction performance due to their inability to effectively capture feature interactions. In this work, we aim to bridge this gap by using pre-trained neural language models to extract embeddings for each input before learning a linear model in the embedding space. The final model (which we call Emb-GAM) is a transparent, linear function of its input features and feature interactions. Leveraging the language model allows Emb-GAM to learn far fewer linear coefficients, model larger interactions, and generalize well to novel inputs (e.g. unseen ngrams in text). Across a variety of natural-language-processing datasets, Emb-GAM achieves strong prediction performance without sacrificing interpretability. All code is made available on Github.
Learning Invariant Representations for Equivariant Neural Networks Using Orthogonal Moments
Sep 22, 2022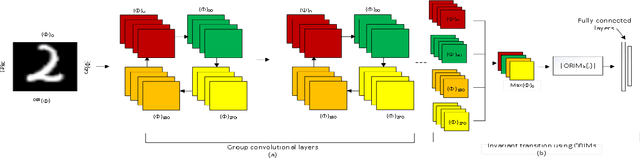
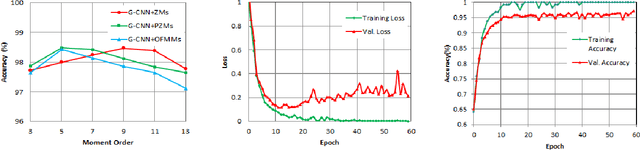


The convolutional layers of standard convolutional neural networks (CNNs) are equivariant to translation. However, the convolution and fully-connected layers are not equivariant or invariant to other affine geometric transformations. Recently, a new class of CNNs is proposed in which the conventional layers of CNNs are replaced with equivariant convolution, pooling, and batch-normalization layers. The final classification layer in equivariant neural networks is invariant to different affine geometric transformations such as rotation, reflection and translation, and the scalar value is obtained by either eliminating the spatial dimensions of filter responses using convolution and down-sampling throughout the network or average is taken over the filter responses. In this work, we propose to integrate the orthogonal moments which gives the high-order statistics of the function as an effective means for encoding global invariance with respect to rotation, reflection and translation in fully-connected layers. As a result, the intermediate layers of the network become equivariant while the classification layer becomes invariant. The most widely used Zernike, pseudo-Zernike and orthogonal Fourier-Mellin moments are considered for this purpose. The effectiveness of the proposed work is evaluated by integrating the invariant transition and fully-connected layer in the architecture of group-equivariant CNNs (G-CNNs) on rotated MNIST and CIFAR10 datasets.
Beyond the Imitation Game: Quantifying and extrapolating the capabilities of language models
Jun 10, 2022Language models demonstrate both quantitative improvement and new qualitative capabilities with increasing scale. Despite their potentially transformative impact, these new capabilities are as yet poorly characterized. In order to inform future research, prepare for disruptive new model capabilities, and ameliorate socially harmful effects, it is vital that we understand the present and near-future capabilities and limitations of language models. To address this challenge, we introduce the Beyond the Imitation Game benchmark (BIG-bench). BIG-bench currently consists of 204 tasks, contributed by 442 authors across 132 institutions. Task topics are diverse, drawing problems from linguistics, childhood development, math, common-sense reasoning, biology, physics, social bias, software development, and beyond. BIG-bench focuses on tasks that are believed to be beyond the capabilities of current language models. We evaluate the behavior of OpenAI's GPT models, Google-internal dense transformer architectures, and Switch-style sparse transformers on BIG-bench, across model sizes spanning millions to hundreds of billions of parameters. In addition, a team of human expert raters performed all tasks in order to provide a strong baseline. Findings include: model performance and calibration both improve with scale, but are poor in absolute terms (and when compared with rater performance); performance is remarkably similar across model classes, though with benefits from sparsity; tasks that improve gradually and predictably commonly involve a large knowledge or memorization component, whereas tasks that exhibit "breakthrough" behavior at a critical scale often involve multiple steps or components, or brittle metrics; social bias typically increases with scale in settings with ambiguous context, but this can be improved with prompting.
Group Probability-Weighted Tree Sums for Interpretable Modeling of Heterogeneous Data
May 30, 2022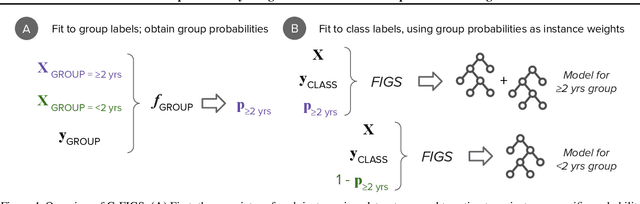

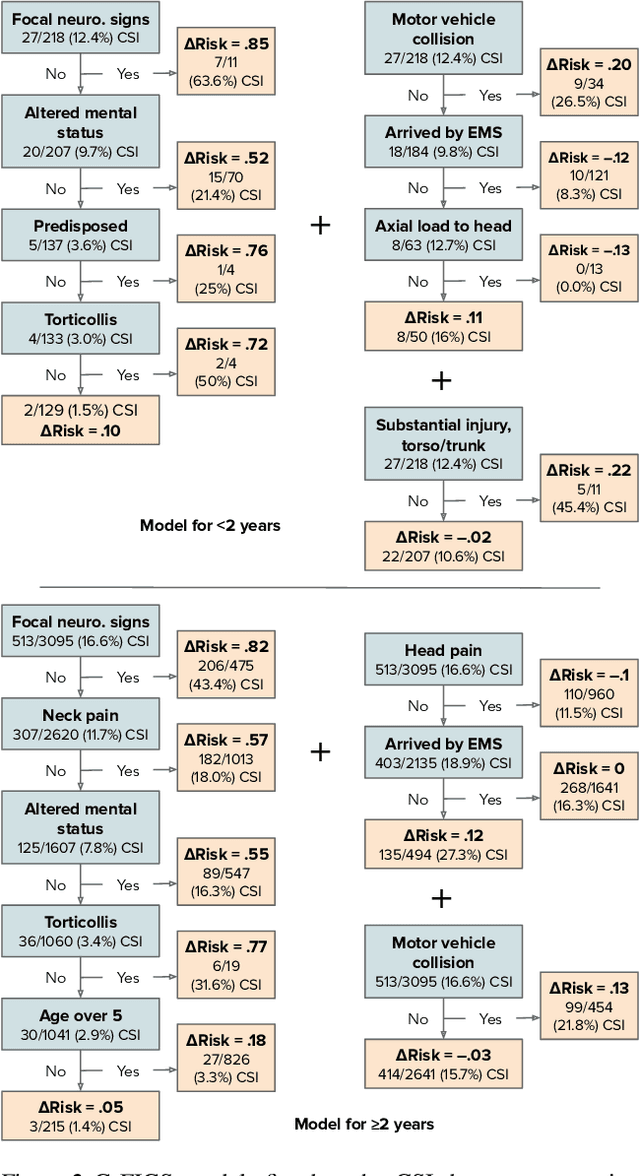
Machine learning in high-stakes domains, such as healthcare, faces two critical challenges: (1) generalizing to diverse data distributions given limited training data while (2) maintaining interpretability. To address these challenges, we propose an instance-weighted tree-sum method that effectively pools data across diverse groups to output a concise, rule-based model. Given distinct groups of instances in a dataset (e.g., medical patients grouped by age or treatment site), our method first estimates group membership probabilities for each instance. Then, it uses these estimates as instance weights in FIGS (Tan et al. 2022), to grow a set of decision trees whose values sum to the final prediction. We call this new method Group Probability-Weighted Tree Sums (G-FIGS). G-FIGS achieves state-of-the-art prediction performance on important clinical datasets; e.g., holding the level of sensitivity fixed at 92%, G-FIGS increases specificity for identifying cervical spine injury by up to 10% over CART and up to 3% over FIGS alone, with larger gains at higher sensitivity levels. By keeping the total number of rules below 16 in FIGS, the final models remain interpretable, and we find that their rules match medical domain expertise. All code, data, and models are released on Github.
Fast Interpretable Greedy-Tree Sums (FIGS)
Feb 17, 2022
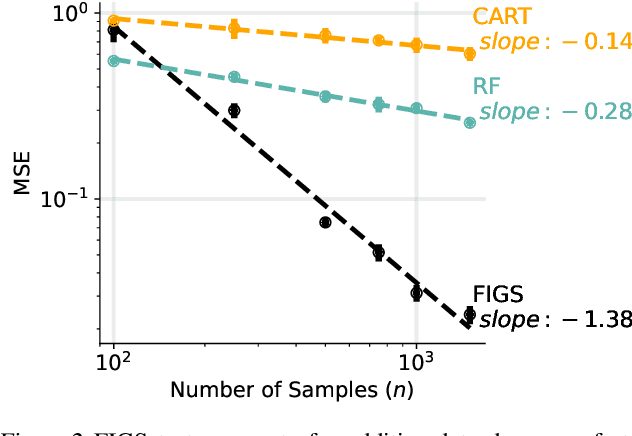
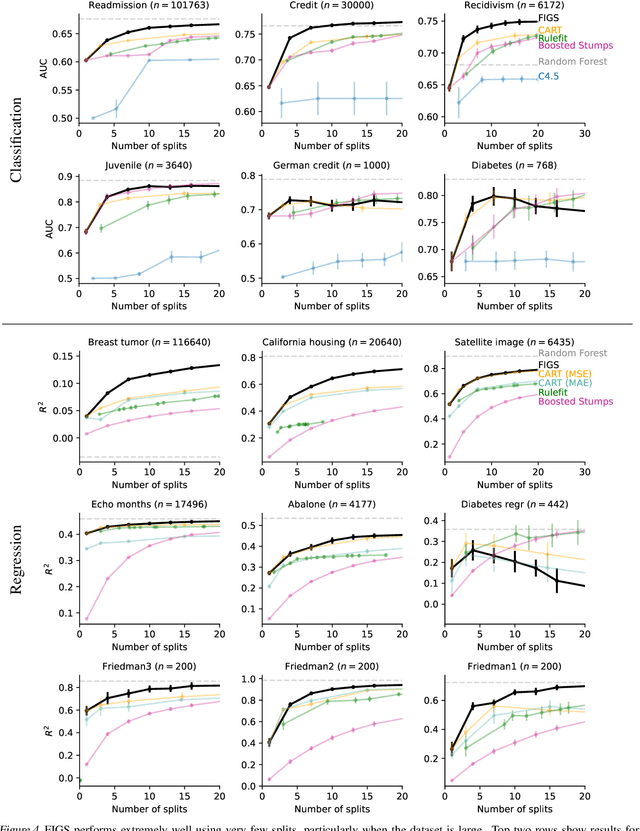
Modern machine learning has achieved impressive prediction performance, but often sacrifices interpretability, a critical consideration in many problems. Here, we propose Fast Interpretable Greedy-Tree Sums (FIGS), an algorithm for fitting concise rule-based models. Specifically, FIGS generalizes the CART algorithm to simultaneously grow a flexible number of trees in a summation. The total number of splits across all the trees can be restricted by a pre-specified threshold, thereby keeping both the size and number of its trees under control. When both are small, the fitted tree-sum can be easily visualized and written out by hand, making it highly interpretable. A partially oracle theoretical result hints at the potential for FIGS to overcome a key weakness of single-tree models by disentangling additive components of generative additive models, thereby reducing redundancy from repeated splits on the same feature. Furthermore, given oracle access to optimal tree structures, we obtain L2 generalization bounds for such generative models in the case of C1 component functions, matching known minimax rates in some cases. Extensive experiments across a wide array of real-world datasets show that FIGS achieves state-of-the-art prediction performance (among all popular rule-based methods) when restricted to just a few splits (e.g. less than 20). We find empirically that FIGS is able to avoid repeated splits, and often provides more concise decision rules than fitted decision trees, without sacrificing predictive performance. All code and models are released in a full-fledged package on Github \url{https://github.com/csinva/imodels}.
Hierarchical Shrinkage: improving the accuracy and interpretability of tree-based methods
Feb 02, 2022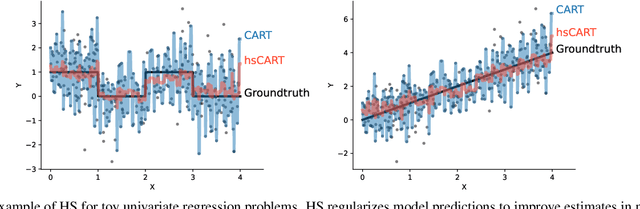
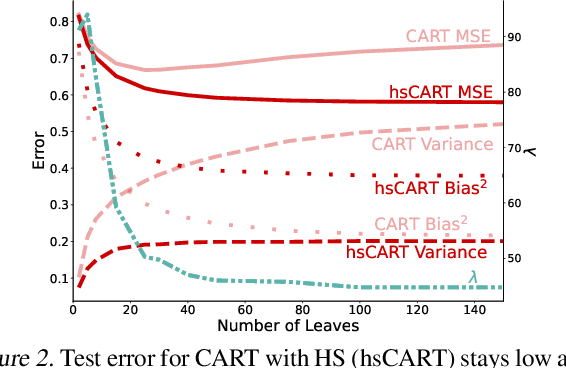
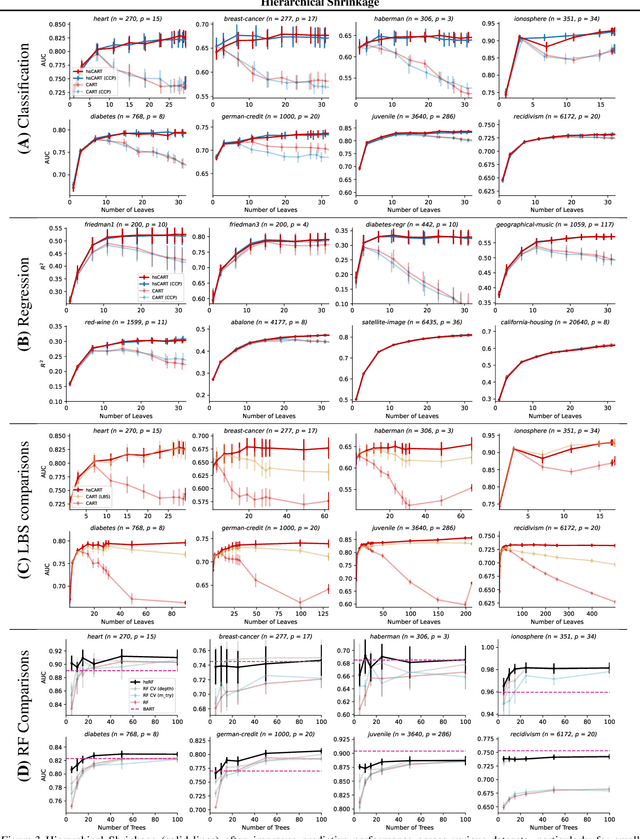
Tree-based models such as decision trees and random forests (RF) are a cornerstone of modern machine-learning practice. To mitigate overfitting, trees are typically regularized by a variety of techniques that modify their structure (e.g. pruning). We introduce Hierarchical Shrinkage (HS), a post-hoc algorithm that does not modify the tree structure, and instead regularizes the tree by shrinking the prediction over each node towards the sample means of its ancestors. The amount of shrinkage is controlled by a single regularization parameter and the number of data points in each ancestor. Since HS is a post-hoc method, it is extremely fast, compatible with any tree growing algorithm, and can be used synergistically with other regularization techniques. Extensive experiments over a wide variety of real-world datasets show that HS substantially increases the predictive performance of decision trees, even when used in conjunction with other regularization techniques. Moreover, we find that applying HS to each tree in an RF often improves accuracy, as well as its interpretability by simplifying and stabilizing its decision boundaries and SHAP values. We further explain the success of HS in improving prediction performance by showing its equivalence to ridge regression on a (supervised) basis constructed of decision stumps associated with the internal nodes of a tree. All code and models are released in a full-fledged package available on Github (github.com/csinva/imodels)
NL-Augmenter: A Framework for Task-Sensitive Natural Language Augmentation
Dec 06, 2021



Data augmentation is an important component in the robustness evaluation of models in natural language processing (NLP) and in enhancing the diversity of the data they are trained on. In this paper, we present NL-Augmenter, a new participatory Python-based natural language augmentation framework which supports the creation of both transformations (modifications to the data) and filters (data splits according to specific features). We describe the framework and an initial set of 117 transformations and 23 filters for a variety of natural language tasks. We demonstrate the efficacy of NL-Augmenter by using several of its transformations to analyze the robustness of popular natural language models. The infrastructure, datacards and robustness analysis results are available publicly on the NL-Augmenter repository (\url{https://github.com/GEM-benchmark/NL-Augmenter}).
Interpreting and improving deep-learning models with reality checks
Aug 19, 2021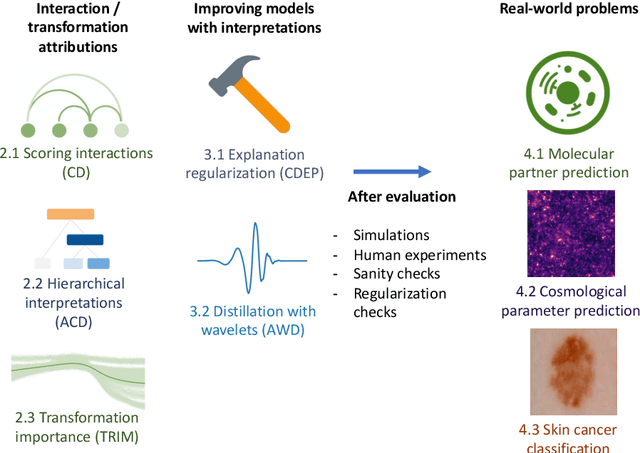

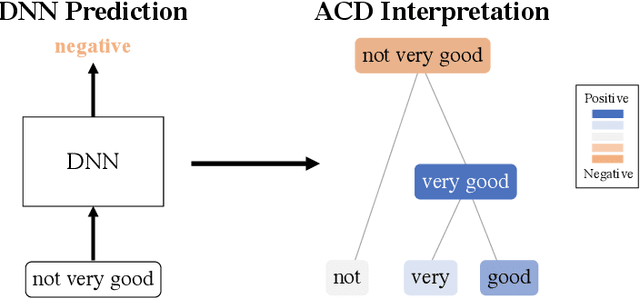
Recent deep-learning models have achieved impressive predictive performance by learning complex functions of many variables, often at the cost of interpretability. This chapter covers recent work aiming to interpret models by attributing importance to features and feature groups for a single prediction. Importantly, the proposed attributions assign importance to interactions between features, in addition to features in isolation. These attributions are shown to yield insights across real-world domains, including bio-imaging, cosmology image and natural-language processing. We then show how these attributions can be used to directly improve the generalization of a neural network or to distill it into a simple model. Throughout the chapter, we emphasize the use of reality checks to scrutinize the proposed interpretation techniques.