 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to EdgeAbstraction Induces the Brain Alignment of Language and Speech Models
Feb 03, 2026Research has repeatedly demonstrated that intermediate hidden states extracted from large language models and speech audio models predict measured brain response to natural language stimuli. Yet, very little is known about the representation properties that enable this high prediction performance. Why is it the intermediate layers, and not the output layers, that are most effective for this unique and highly general transfer task? We give evidence that the correspondence between speech and language models and the brain derives from shared meaning abstraction and not their next-word prediction properties. In particular, models construct higher-order linguistic features in their middle layers, cued by a peak in the layerwise intrinsic dimension, a measure of feature complexity. We show that a layer's intrinsic dimension strongly predicts how well it explains fMRI and ECoG signals; that the relation between intrinsic dimension and brain predictivity arises over model pre-training; and finetuning models to better predict the brain causally increases both representations' intrinsic dimension and their semantic content. Results suggest that semantic richness, high intrinsic dimension, and brain predictivity mirror each other, and that the key driver of model-brain similarity is rich meaning abstraction of the inputs, where language modeling is a task sufficiently complex (but perhaps not the only) to require it.
AVMeme Exam: A Multimodal Multilingual Multicultural Benchmark for LLMs' Contextual and Cultural Knowledge and Thinking
Jan 25, 2026Internet audio-visual clips convey meaning through time-varying sound and motion, which extend beyond what text alone can represent. To examine whether AI models can understand such signals in human cultural contexts, we introduce AVMeme Exam, a human-curated benchmark of over one thousand iconic Internet sounds and videos spanning speech, songs, music, and sound effects. Each meme is paired with a unique Q&A assessing levels of understanding from surface content to context and emotion to usage and world knowledge, along with metadata such as original year, transcript, summary, and sensitivity. We systematically evaluate state-of-the-art multimodal large language models (MLLMs) alongside human participants using this benchmark. Our results reveal a consistent limitation: current models perform poorly on textless music and sound effects, and struggle to think in context and in culture compared to surface content. These findings highlight a key gap in human-aligned multimodal intelligence and call for models that can perceive contextually and culturally beyond the surface of what they hear and see. Project page: avmemeexam.github.io/public
Far from the Shallow: Brain-Predictive Reasoning Embedding through Residual Disentanglement
Oct 26, 2025Understanding how the human brain progresses from processing simple linguistic inputs to performing high-level reasoning is a fundamental challenge in neuroscience. While modern large language models (LLMs) are increasingly used to model neural responses to language, their internal representations are highly "entangled," mixing information about lexicon, syntax, meaning, and reasoning. This entanglement biases conventional brain encoding analyses toward linguistically shallow features (e.g., lexicon and syntax), making it difficult to isolate the neural substrates of cognitively deeper processes. Here, we introduce a residual disentanglement method that computationally isolates these components. By first probing an LM to identify feature-specific layers, our method iteratively regresses out lower-level representations to produce four nearly orthogonal embeddings for lexicon, syntax, meaning, and, critically, reasoning. We used these disentangled embeddings to model intracranial (ECoG) brain recordings from neurosurgical patients listening to natural speech. We show that: 1) This isolated reasoning embedding exhibits unique predictive power, accounting for variance in neural activity not explained by other linguistic features and even extending to the recruitment of visual regions beyond classical language areas. 2) The neural signature for reasoning is temporally distinct, peaking later (~350-400ms) than signals related to lexicon, syntax, and meaning, consistent with its position atop a processing hierarchy. 3) Standard, non-disentangled LLM embeddings can be misleading, as their predictive success is primarily attributable to linguistically shallow features, masking the more subtle contributions of deeper cognitive processing.
A generative framework to bridge data-driven models and scientific theories in language neuroscience
Oct 01, 2024



Representations from large language models are highly effective at predicting BOLD fMRI responses to language stimuli. However, these representations are largely opaque: it is unclear what features of the language stimulus drive the response in each brain area. We present generative explanation-mediated validation, a framework for generating concise explanations of language selectivity in the brain and then validating those explanations in follow-up experiments that use synthetic stimuli. This approach is successful at explaining selectivity both in individual voxels and cortical regions of interest (ROIs).We show that explanatory accuracy is closely related to the predictive power and stability of the underlying statistical models. These results demonstrate that LLMs can be used to bridge the widening gap between data-driven models and formal scientific theories.
Crafting Interpretable Embeddings by Asking LLMs Questions
May 26, 2024Large language models (LLMs) have rapidly improved text embeddings for a growing array of natural-language processing tasks. However, their opaqueness and proliferation into scientific domains such as neuroscience have created a growing need for interpretability. Here, we ask whether we can obtain interpretable embeddings through LLM prompting. We introduce question-answering embeddings (QA-Emb), embeddings where each feature represents an answer to a yes/no question asked to an LLM. Training QA-Emb reduces to selecting a set of underlying questions rather than learning model weights. We use QA-Emb to flexibly generate interpretable models for predicting fMRI voxel responses to language stimuli. QA-Emb significantly outperforms an established interpretable baseline, and does so while requiring very few questions. This paves the way towards building flexible feature spaces that can concretize and evaluate our understanding of semantic brain representations. We additionally find that QA-Emb can be effectively approximated with an efficient model, and we explore broader applications in simple NLP tasks.
How Many Bytes Can You Take Out Of Brain-To-Text Decoding?
May 22, 2024Brain-computer interfaces have promising medical and scientific applications for aiding speech and studying the brain. In this work, we propose an information-based evaluation metric for brain-to-text decoders. Using this metric, we examine two methods to augment existing state-of-the-art continuous text decoders. We show that these methods, in concert, can improve brain decoding performance by upwards of 40% when compared to a baseline model. We further examine the informatic properties of brain-to-text decoders and show empirically that they have Zipfian power law dynamics. Finally, we provide an estimate for the idealized performance of an fMRI-based text decoder. We compare this idealized model to our current model, and use our information-based metric to quantify the main sources of decoding error. We conclude that a practical brain-to-text decoder is likely possible given further algorithmic improvements.
Scaling laws for language encoding models in fMRI
May 22, 2023Representations from transformer-based unidirectional language models are known to be effective at predicting brain responses to natural language. However, most studies comparing language models to brains have used GPT-2 or similarly sized language models. Here we tested whether larger open-source models such as those from the OPT and LLaMA families are better at predicting brain responses recorded using fMRI. Mirroring scaling results from other contexts, we found that brain prediction performance scales log-linearly with model size from 125M to 30B parameter models, with ~15% increased encoding performance as measured by correlation with a held-out test set across 3 subjects. Similar log-linear behavior was observed when scaling the size of the fMRI training set. We also characterized scaling for acoustic encoding models that use HuBERT, WavLM, and Whisper, and we found comparable improvements with model size. A noise ceiling analysis of these large, high-performance encoding models showed that performance is nearing the theoretical maximum for brain areas such as the precuneus and higher auditory cortex. These results suggest that increasing scale in both models and data will yield incredibly effective models of language processing in the brain, enabling better scientific understanding as well as applications such as decoding.
Explaining black box text modules in natural language with language models
May 17, 2023



Large language models (LLMs) have demonstrated remarkable prediction performance for a growing array of tasks. However, their rapid proliferation and increasing opaqueness have created a growing need for interpretability. Here, we ask whether we can automatically obtain natural language explanations for black box text modules. A "text module" is any function that maps text to a scalar continuous value, such as a submodule within an LLM or a fitted model of a brain region. "Black box" indicates that we only have access to the module's inputs/outputs. We introduce Summarize and Score (SASC), a method that takes in a text module and returns a natural language explanation of the module's selectivity along with a score for how reliable the explanation is. We study SASC in 3 contexts. First, we evaluate SASC on synthetic modules and find that it often recovers ground truth explanations. Second, we use SASC to explain modules found within a pre-trained BERT model, enabling inspection of the model's internals. Finally, we show that SASC can generate explanations for the response of individual fMRI voxels to language stimuli, with potential applications to fine-grained brain mapping. All code for using SASC and reproducing results is made available on Github.
Low-Dimensional Structure in the Space of Language Representations is Reflected in Brain Responses
Jun 15, 2021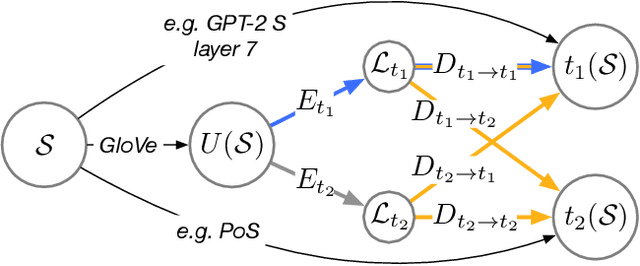
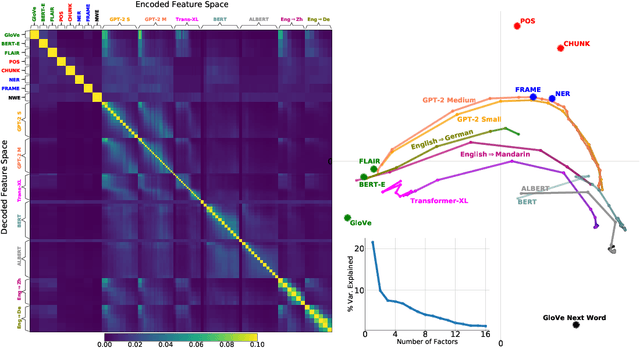
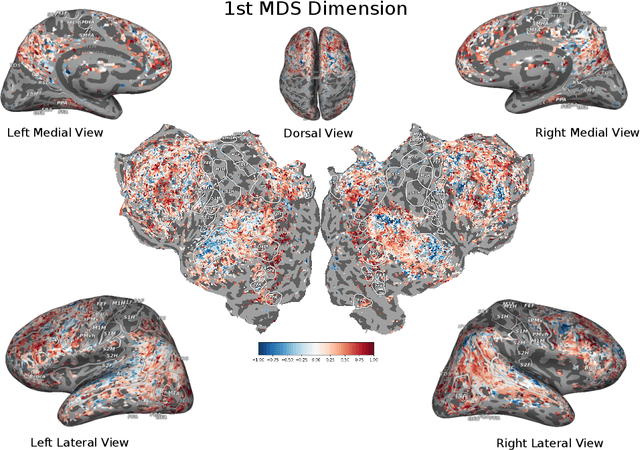
How related are the representations learned by neural language models, translation models, and language tagging tasks? We answer this question by adapting an encoder-decoder transfer learning method from computer vision to investigate the structure among 100 different feature spaces extracted from hidden representations of various networks trained on language tasks. This method reveals a low-dimensional structure where language models and translation models smoothly interpolate between word embeddings, syntactic and semantic tasks, and future word embeddings. We call this low-dimensional structure a language representation embedding because it encodes the relationships between representations needed to process language for a variety of NLP tasks. We find that this representation embedding can predict how well each individual feature space maps to human brain responses to natural language stimuli recorded using fMRI. Additionally, we find that the principal dimension of this structure can be used to create a metric which highlights the brain's natural language processing hierarchy. This suggests that the embedding captures some part of the brain's natural language representation structure.
Selecting Informative Contexts Improves Language Model Finetuning
May 01, 2020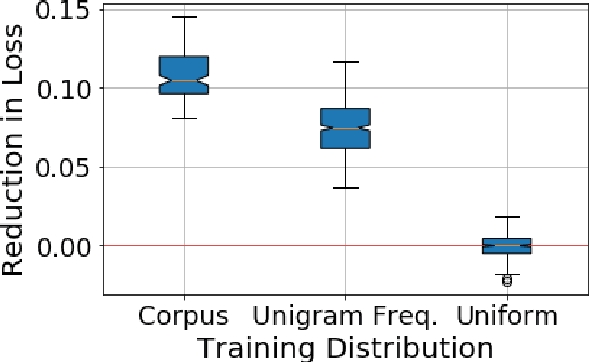
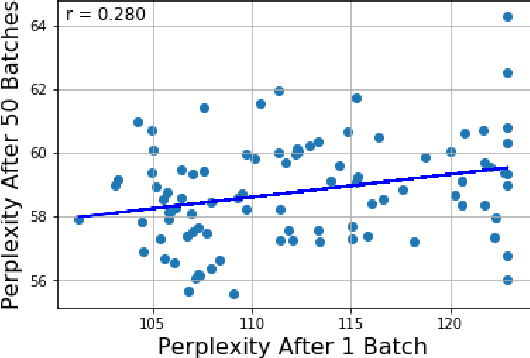
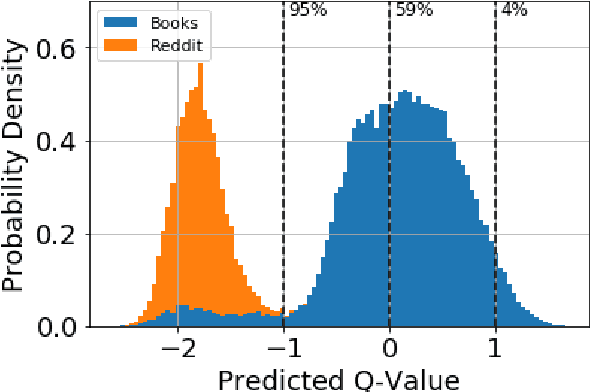
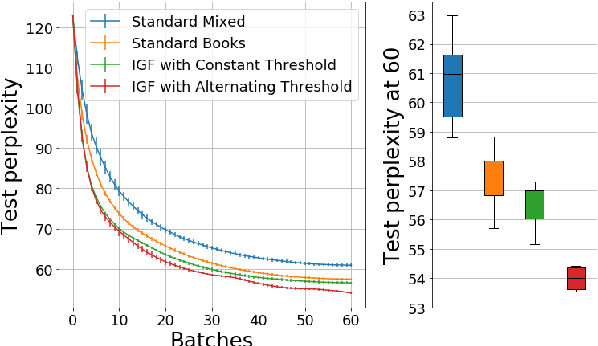
We present a general finetuning meta-method that we call information gain filtration for improving the overall training efficiency and final performance of language model finetuning. This method uses a secondary learner which attempts to quantify the benefit of finetuning the language model on each given example. During the finetuning process, we use this learner to decide whether or not each given example should be trained on or skipped. We show that it suffices for this learner to be simple and that the finetuning process itself is dominated by the relatively trivial relearning of a new unigram frequency distribution over the modelled language domain, a process which the learner aids. Our method trains to convergence using 40% fewer batches than normal finetuning, and achieves a median perplexity of 54.0 on a books dataset compared to a median perplexity of 57.3 for standard finetuning using the same neural architecture.