 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to EdgeEnd-to-end Robustness for Sensing-Reasoning Machine Learning Pipelines
Mar 06, 2020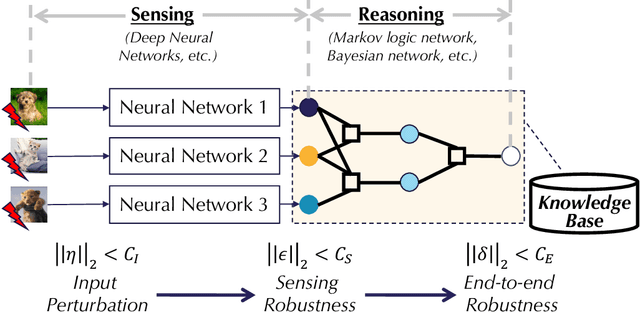
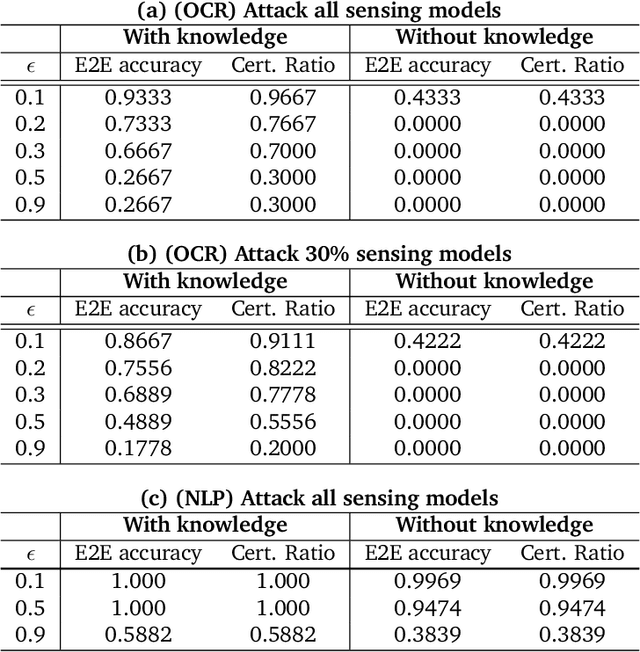
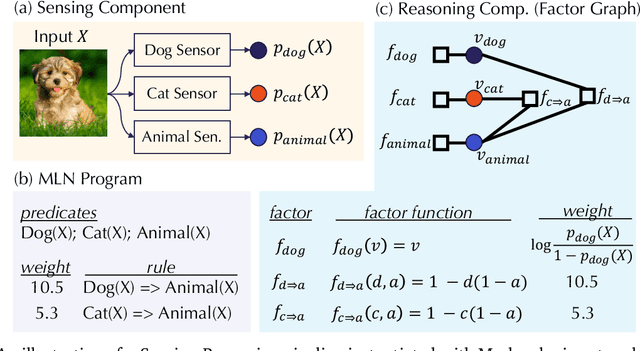
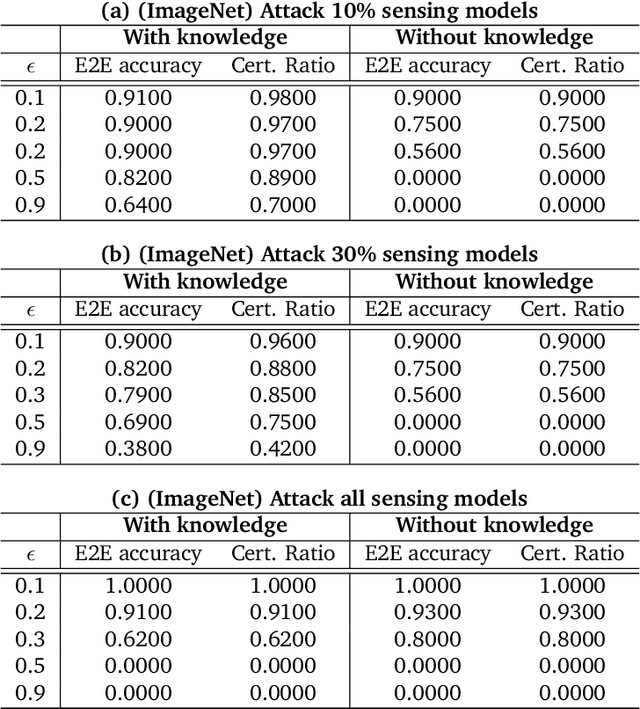
As machine learning (ML) being applied to many mission-critical scenarios, certifying ML model robustness becomes increasingly important. Many previous works focuses on the robustness of independent ML and ensemble models, and can only certify a very small magnitude of the adversarial perturbation. In this paper, we take a different viewpoint and improve learning robustness by going beyond independent ML and ensemble models. We aim at promoting the generic Sensing-Reasoning machine learning pipeline which contains both the sensing (e.g. deep neural networks) and reasoning (e.g. Markov logic networks (MLN)) components enriched with domain knowledge. Can domain knowledge help improve learning robustness? Can we formally certify the end-to-end robustness of such an ML pipeline? We first theoretically analyze the computational complexity of checking the provable robustness in the reasoning component. We then derive the provable robustness bound for several concrete reasoning components. We show that for reasoning components such as MLN and a specific family of Bayesian networks it is possible to certify the robustness of the whole pipeline even with a large magnitude of perturbation which cannot be certified by existing work. Finally, we conduct extensive real-world experiments on large scale datasets to evaluate the certified robustness for Sensing-Reasoning ML pipelines.
A Robust Imbalanced SAR Image Change Detection Approach Based on Deep Difference Image and PCANet
Mar 03, 2020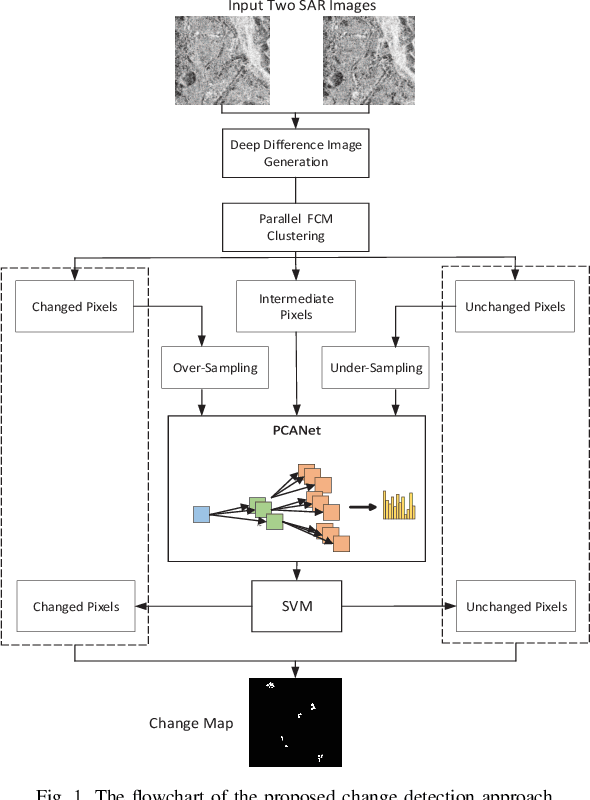
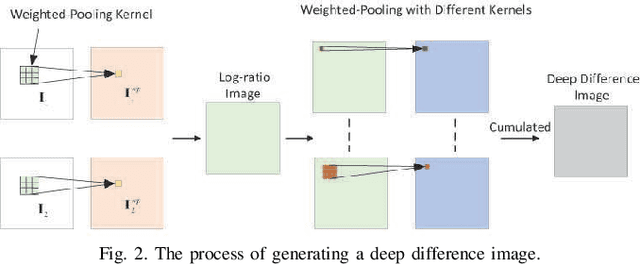

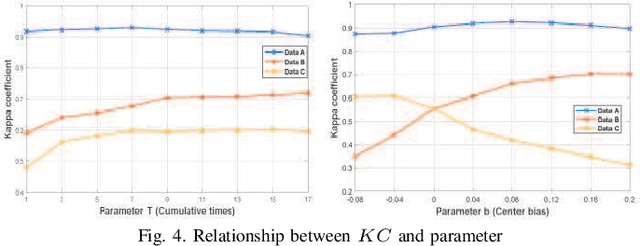
In this research, a novel robust change detection approach is presented for imbalanced multi-temporal synthetic aperture radar (SAR) image based on deep learning. Our main contribution is to develop a novel method for generating difference image and a parallel fuzzy c-means (FCM) clustering method. The main steps of our proposed approach are as follows: 1) Inspired by convolution and pooling in deep learning, a deep difference image (DDI) is obtained based on parameterized pooling leading to better speckle suppression and feature enhancement than traditional difference images. 2) Two different parameter Sigmoid nonlinear mapping are applied to the DDI to get two mapped DDIs. Parallel FCM are utilized on these two mapped DDIs to obtain three types of pseudo-label pixels, namely, changed pixels, unchanged pixels, and intermediate pixels. 3) A PCANet with support vector machine (SVM) are trained to classify intermediate pixels to be changed or unchanged. Three imbalanced multi-temporal SAR image sets are used for change detection experiments. The experimental results demonstrate that the proposed approach is effective and robust for imbalanced SAR data, and achieve up to 99.52% change detection accuracy superior to most state-of-the-art methods.
Two-Phase Object-Based Deep Learning for Multi-temporal SAR Image Change Detection
Jan 17, 2020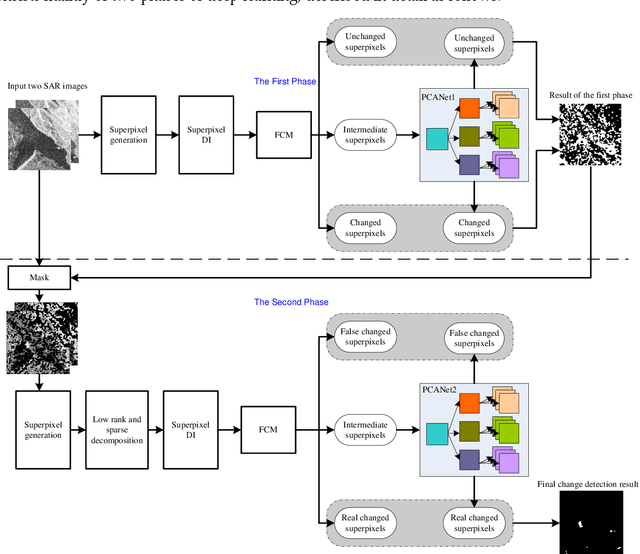
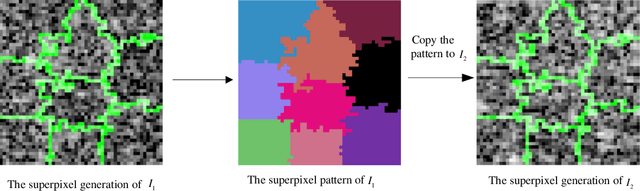
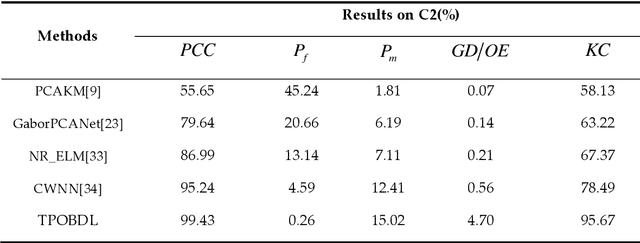
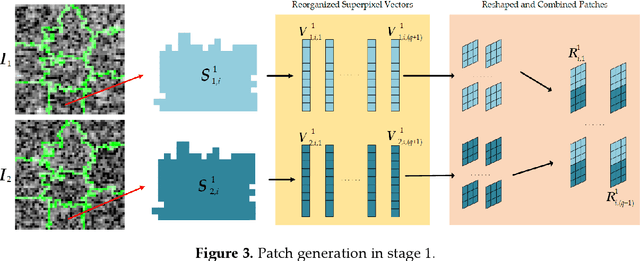
Change detection is one of the fundamental applications of synthetic aperture radar (SAR) images. However, speckle noise presented in SAR images has a much negative effect on change detection. In this research, a novel two-phase object-based deep learning approach is proposed for multi-temporal SAR image change detection. Compared with traditional methods, the proposed approach brings two main innovations. One is to classify all pixels into three categories rather than two categories: unchanged pixels, changed pixels caused by strong speckle (false changes), and changed pixels formed by real terrain variation (real changes). The other is to group neighboring pixels into segmented into superpixel objects (from pixels) such as to exploit local spatial context. Two phases are designed in the methodology: 1) Generate objects based on the simple linear iterative clustering algorithm, and discriminate these objects into changed and unchanged classes using fuzzy c-means (FCM) clustering and a deep PCANet. The prediction of this Phase is the set of changed and unchanged superpixels. 2) Deep learning on the pixel sets over the changed superpixels only, obtained in the first phase, to discriminate real changes from false changes. SLIC is employed again to achieve new superpixels in the second phase. Low rank and sparse decomposition are applied to these new superpixels to suppress speckle noise significantly. A further clustering step is applied to these new superpixels via FCM. A new PCANet is then trained to classify two kinds of changed superpixels to achieve the final change maps. Numerical experiments demonstrate that, compared with benchmark methods, the proposed approach can distinguish real changes from false changes effectively with significantly reduced false alarm rates, and achieve up to 99.71% change detection accuracy using multi-temporal SAR imagery.
TextNAS: A Neural Architecture Search Space tailored for Text Representation
Dec 23, 2019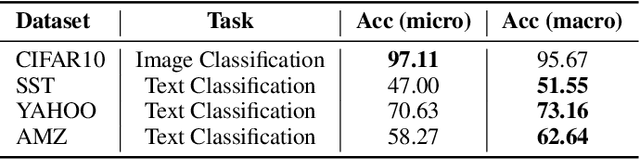
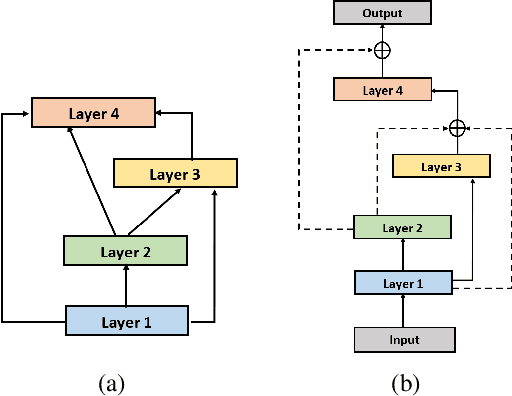
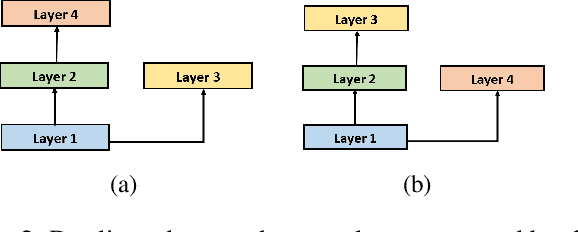
Learning text representation is crucial for text classification and other language related tasks. There are a diverse set of text representation networks in the literature, and how to find the optimal one is a non-trivial problem. Recently, the emerging Neural Architecture Search (NAS) techniques have demonstrated good potential to solve the problem. Nevertheless, most of the existing works of NAS focus on the search algorithms and pay little attention to the search space. In this paper, we argue that the search space is also an important human prior to the success of NAS in different applications. Thus, we propose a novel search space tailored for text representation. Through automatic search, the discovered network architecture outperforms state-of-the-art models on various public datasets on text classification and natural language inference tasks. Furthermore, some of the design principles found in the automatic network agree well with human intuition.
Data Science through the looking glass and what we found there
Dec 19, 2019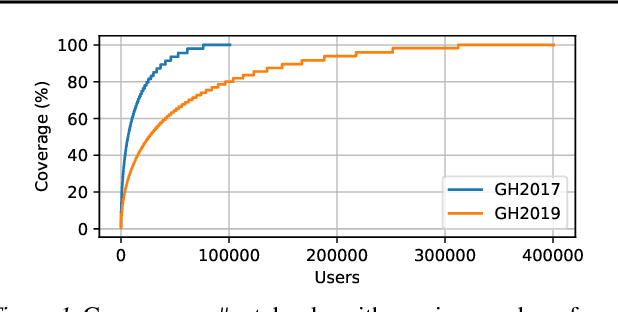
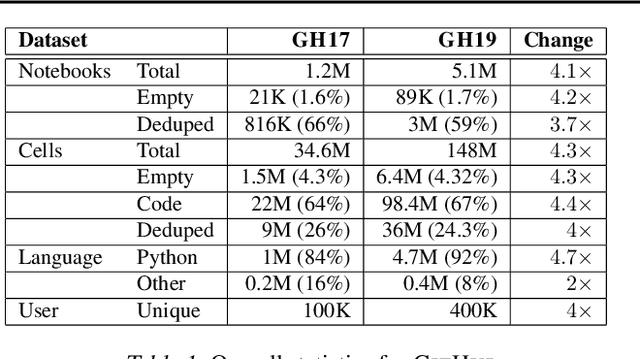
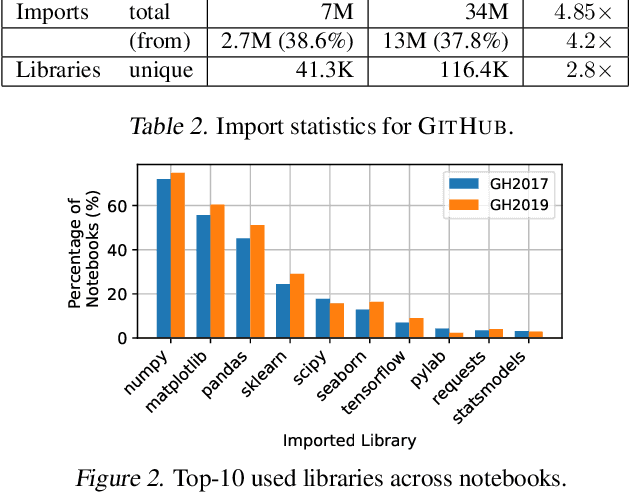
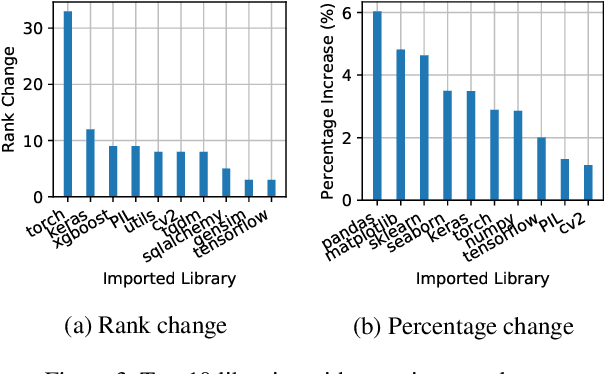
The recent success of machine learning (ML) has led to an explosive growth both in terms of new systems and algorithms built in industry and academia, and new applications built by an ever-growing community of data science (DS) practitioners. This quickly shifting panorama of technologies and applications is challenging for builders and practitioners alike to follow. In this paper, we set out to capture this panorama through a wide-angle lens, by performing the largest analysis of DS projects to date, focusing on questions that can help determine investments on either side. Specifically, we download and analyze: (a) over 6M Python notebooks publicly available on GITHUB, (b) over 2M enterprise DS pipelines developed within COMPANYX, and (c) the source code and metadata of over 900 releases from 12 important DS libraries. The analysis we perform ranges from coarse-grained statistical characterizations to analysis of library imports, pipelines, and comparative studies across datasets and time. We report a large number of measurements for our readers to interpret, and dare to draw a few (actionable, yet subjective) conclusions on (a) what systems builders should focus on to better serve practitioners, and (b) what technologies should practitioners bet on given current trends. We plan to automate this analysis and release associated tools and results periodically.
Support Vector Machine Classifier via $L_{0/1}$ Soft-Margin Loss
Dec 16, 2019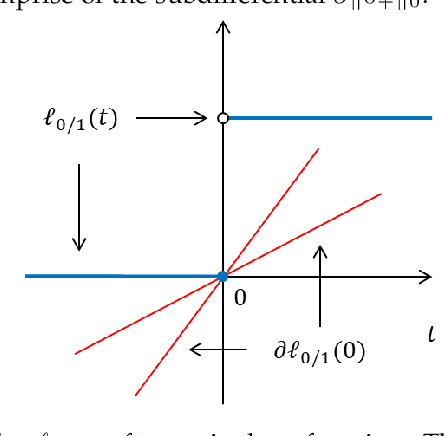
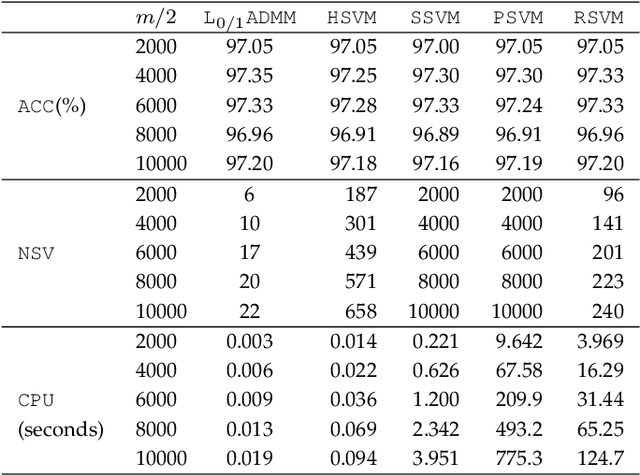
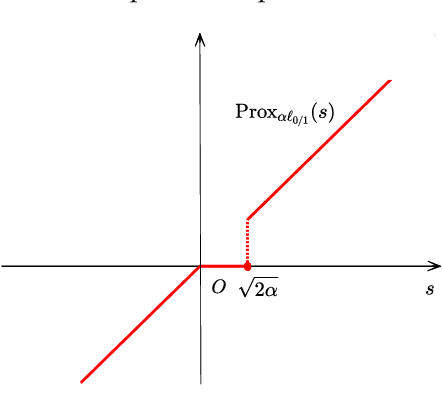
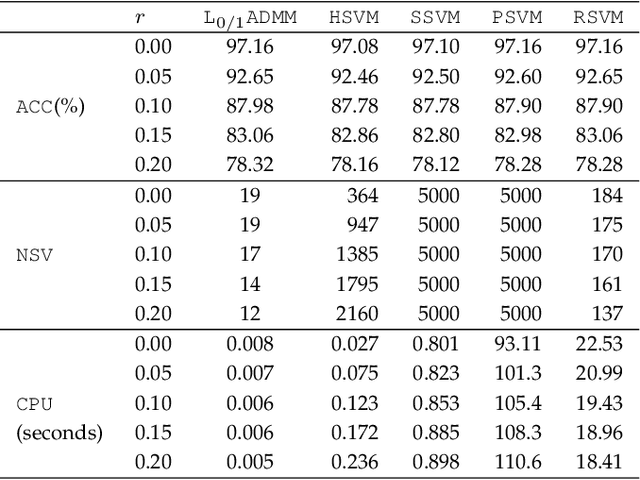
Support vector machine (SVM) has attracted great attentions for the last two decades due to its extensive applications, and thus numerous optimization models have been proposed. To distinguish all of them, in this paper, we introduce a new model equipped with an $L_{0/1}$ soft-margin loss (dubbed as $L_{0/1}$-SVM) which well captures the nature of the binary classification. Many of the existing convex/non-convex soft-margin losses can be viewed as a surrogate of the $L_{0/1}$ soft-margin loss. Despite the discrete nature of $L_{0/1}$, we manage to establish the existence of global minimizer of the new model as well as revealing the relationship among its minimizers and KKT/P-stationary points. These theoretical properties allow us to take advantage of the alternating direction method of multipliers. In addition, the $L_{0/1}$-support vector operator is introduced as a filter to prevent outliers from being support vectors during the training process. Hence, the method is expected to be relatively robust. Finally, numerical experiments demonstrate that our proposed method generates better performance in terms of much shorter computational time with much fewer number of support vectors when against with some other leading methods in areas of SVM. When the data size gets bigger, its advantage becomes more evident.
ZuCo 2.0: A Dataset of Physiological Recordings During Natural Reading and Annotation
Dec 02, 2019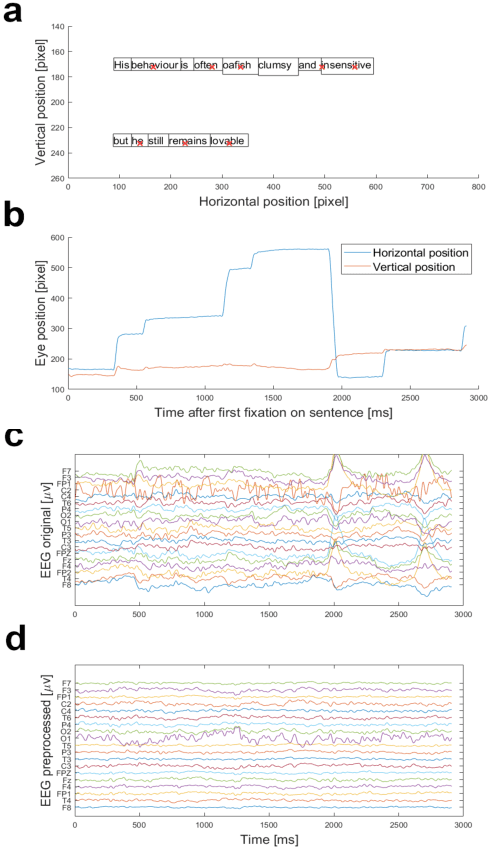
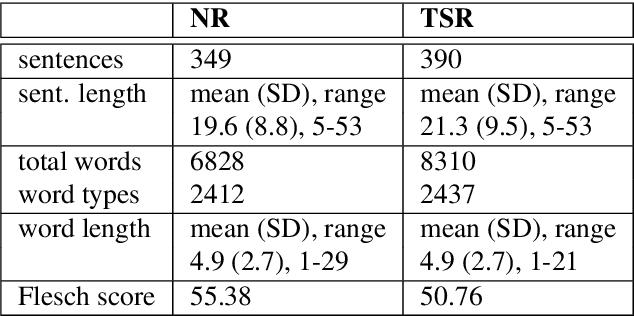

We recorded and preprocessed ZuCo 2.0, a new dataset of simultaneous eye-tracking and electroencephalography during natural reading and during annotation. This corpus contains gaze and brain activity data of 739 sentences, 349 in a normal reading paradigm and 390 in a task-specific paradigm, in which the 18 participants actively search for a semantic relation type in the given sentences as a linguistic annotation task. This new dataset complements ZuCo 1.0 by providing experiments designed to analyze the differences in cognitive processing between natural reading and annotation. The data is freely available here: url{https://osf.io/2urht/
An Empirical and Comparative Analysis of Data Valuation with Scalable Algorithms
Nov 17, 2019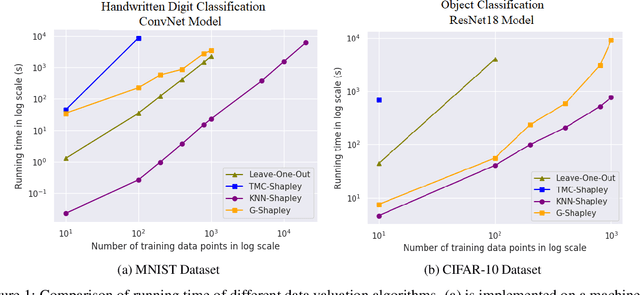

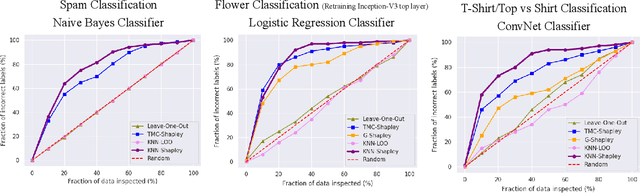
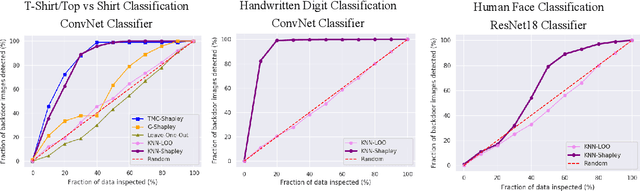
This paper focuses on valuating training data for supervised learning tasks and studies the Shapley value, a data value notion originated in cooperative game theory. The Shapley value defines a unique value distribution scheme that satisfies a set of appealing properties desired by a data value notion. However, the Shapley value requires exponential complexity to calculate exactly. Existing approximation algorithms, although achieving great improvement over the exact algorithm, relies on retraining models for multiple times, thus remaining limited when applied to larger-scale learning tasks and real-world datasets. In this work, we develop a simple and efficient heuristic for data valuation based on the Shapley value with complexity independent with the model size. The key idea is to approximate the model via a $K$-nearest neighbor ($K$NN) classifier, which has a locality structure that can lead to efficient Shapley value calculation. We evaluate the utility of the values produced by the $K$NN proxies in various settings, including label noise correction, watermark detection, data summarization, active data acquisition, and domain adaption. Extensive experiments demonstrate that our algorithm achieves at least comparable utility to the values produced by existing algorithms while significant efficiency improvement. Moreover, we theoretically analyze the Shapley value and justify its advantage over the leave-one-out error as a data value measure.
DocParser: Hierarchical Structure Parsing of Document Renderings
Nov 05, 2019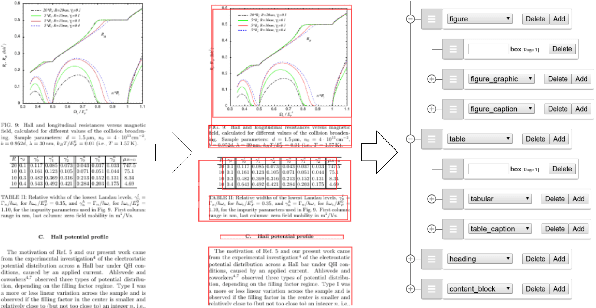
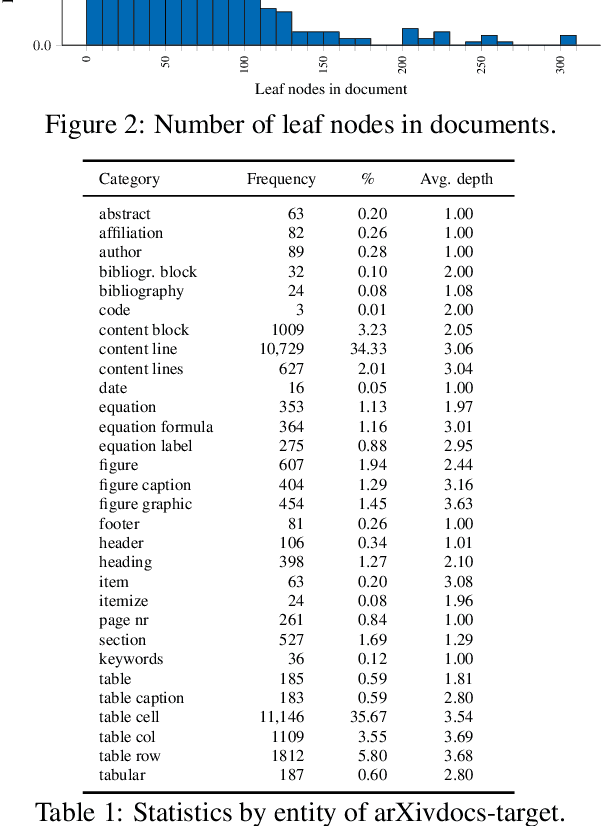
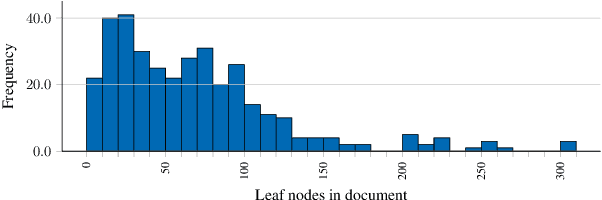
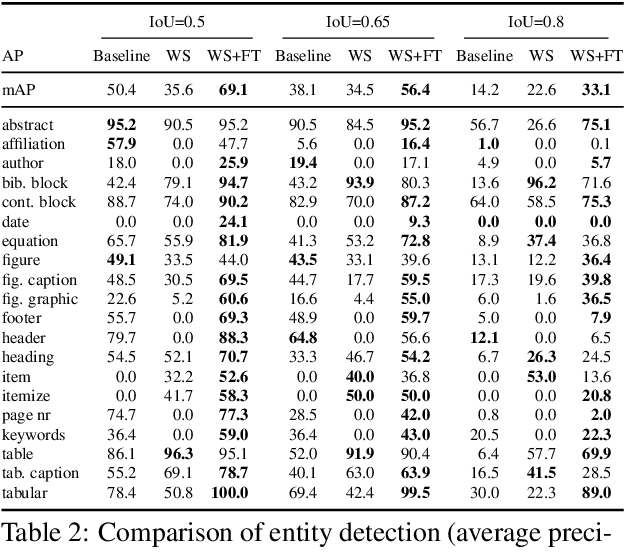
Translating document renderings (e.g. PDFs, scans) into hierarchical structures is extensively demanded in the daily routines of many real-world applications, and is often a prerequisite step of many downstream NLP tasks. Earlier attempts focused on different but simpler tasks such as the detection of table or cell locations within documents; however, a holistic, principled approach to inferring the complete hierarchical structure in documents is missing. As a remedy, we developed "DocParser": an end-to-end system for parsing the complete document structure - including all text elements, figures, tables, and table cell structures. To the best of our knowledge, DocParser is the first system that derives the full hierarchical document compositions. Given the complexity of the task, annotating appropriate datasets is costly. Therefore, our second contribution is to provide a dataset for evaluating hierarchical document structure parsing. Our third contribution is to propose a scalable learning framework for settings where domain-specific data is scarce, which we address by a novel approach to weak supervision. Our computational experiments confirm the effectiveness of our proposed weak supervision: Compared to the baseline without weak supervision, it improves the mean average precision for detecting document entities by 37.1%. When classifying hierarchical relations between entity pairs, it improves the F1 score by 27.6%.
CogniVal: A Framework for Cognitive Word Embedding Evaluation
Oct 29, 2019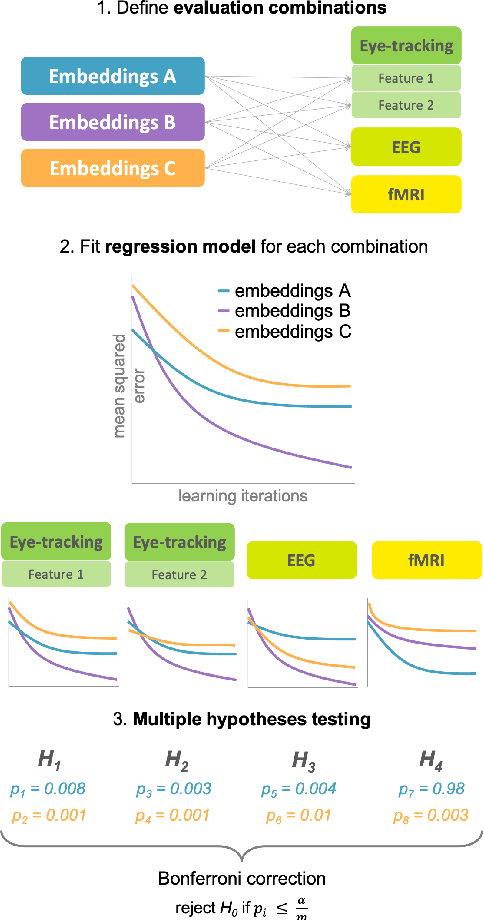
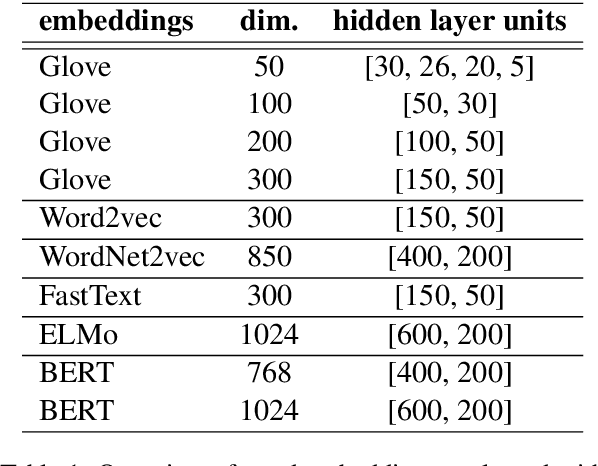
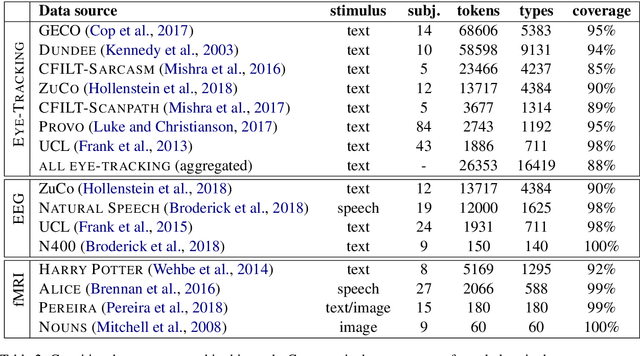
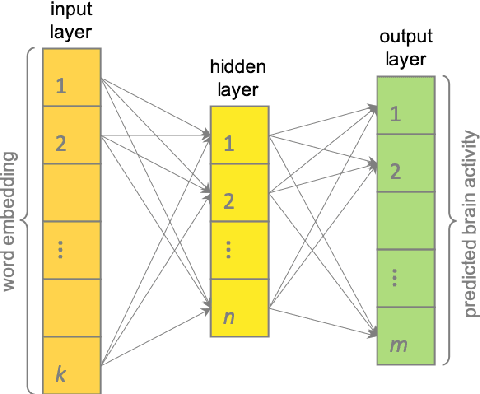
An interesting method of evaluating word representations is by how much they reflect the semantic representations in the human brain. However, most, if not all, previous works only focus on small datasets and a single modality. In this paper, we present the first multi-modal framework for evaluating English word representations based on cognitive lexical semantics. Six types of word embeddings are evaluated by fitting them to 15 datasets of eye-tracking, EEG and fMRI signals recorded during language processing. To achieve a global score over all evaluation hypotheses, we apply statistical significance testing accounting for the multiple comparisons problem. This framework is easily extensible and available to include other intrinsic and extrinsic evaluation methods. We find strong correlations in the results between cognitive datasets, across recording modalities and to their performance on extrinsic NLP tasks.