 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to EdgeRankSteer: Activation Steering for Pointwise LLM Ranking
Feb 03, 2026Large language models (LLMs) have recently shown strong performance as zero-shot rankers, yet their effectiveness is highly sensitive to prompt formulation, particularly role-play instructions. Prior analyses suggest that role-related signals are encoded along activation channels that are largely separate from query-document representations, raising the possibility of steering ranking behavior directly at the activation level rather than through brittle prompt engineering. In this work, we propose RankSteer, a post-hoc activation steering framework for zero-shot pointwise LLM ranking. We characterize ranking behavior through three disentangled and steerable directions in representation space: a \textbf{decision direction} that maps hidden states to relevance scores, an \textbf{evidence direction} that captures relevance signals not directly exploited by the decision head, and a \textbf{role direction} that modulates model behavior without injecting relevance information. Using projection-based interventions at inference time, RankSteer jointly controls these directions to calibrate ranking behavior without modifying model weights or introducing explicit cross-document comparisons. Experiments on TREC DL 20 and multiple BEIR benchmarks show that RankSteer consistently improves ranking quality using only a small number of anchor queries, demonstrating that substantial ranking capacity remains under-utilized in pointwise LLM rankers. We further provide a geometric analysis revealing that steering improves ranking by stabilizing ranking geometry and reducing dispersion, offering new insight into how LLMs internally represent and calibrate relevance judgments.
Cross-Encoder Rediscovers a Semantic Variant of BM25
Feb 07, 2025



Neural Ranking Models (NRMs) have rapidly advanced state-of-the-art performance on information retrieval tasks. In this work, we investigate a Cross-Encoder variant of MiniLM to determine which relevance features it computes and where they are stored. We find that it employs a semantic variant of the traditional BM25 in an interpretable manner, featuring localized components: (1) Transformer attention heads that compute soft term frequency while controlling for term saturation and document length effects, and (2) a low-rank component of its embedding matrix that encodes inverse document frequency information for the vocabulary. This suggests that the Cross-Encoder uses the same fundamental mechanisms as BM25, but further leverages their capacity to capture semantics for improved retrieval performance. The granular understanding lays the groundwork for model editing to enhance model transparency, addressing safety concerns, and improving scalability in training and real-world applications.
MechIR: A Mechanistic Interpretability Framework for Information Retrieval
Jan 17, 2025Mechanistic interpretability is an emerging diagnostic approach for neural models that has gained traction in broader natural language processing domains. This paradigm aims to provide attribution to components of neural systems where causal relationships between hidden layers and output were previously uninterpretable. As the use of neural models in IR for retrieval and evaluation becomes ubiquitous, we need to ensure that we can interpret why a model produces a given output for both transparency and the betterment of systems. This work comprises a flexible framework for diagnostic analysis and intervention within these highly parametric neural systems specifically tailored for IR tasks and architectures. In providing such a framework, we look to facilitate further research in interpretable IR with a broader scope for practical interventions derived from mechanistic interpretability. We provide preliminary analysis and look to demonstrate our framework through an axiomatic lens to show its applications and ease of use for those IR practitioners inexperienced in this emerging paradigm.
Political-LLM: Large Language Models in Political Science
Dec 09, 2024



In recent years, large language models (LLMs) have been widely adopted in political science tasks such as election prediction, sentiment analysis, policy impact assessment, and misinformation detection. Meanwhile, the need to systematically understand how LLMs can further revolutionize the field also becomes urgent. In this work, we--a multidisciplinary team of researchers spanning computer science and political science--present the first principled framework termed Political-LLM to advance the comprehensive understanding of integrating LLMs into computational political science. Specifically, we first introduce a fundamental taxonomy classifying the existing explorations into two perspectives: political science and computational methodologies. In particular, from the political science perspective, we highlight the role of LLMs in automating predictive and generative tasks, simulating behavior dynamics, and improving causal inference through tools like counterfactual generation; from a computational perspective, we introduce advancements in data preparation, fine-tuning, and evaluation methods for LLMs that are tailored to political contexts. We identify key challenges and future directions, emphasizing the development of domain-specific datasets, addressing issues of bias and fairness, incorporating human expertise, and redefining evaluation criteria to align with the unique requirements of computational political science. Political-LLM seeks to serve as a guidebook for researchers to foster an informed, ethical, and impactful use of Artificial Intelligence in political science. Our online resource is available at: http://political-llm.org/.
Axiomatic Causal Interventions for Reverse Engineering Relevance Computation in Neural Retrieval Models
May 03, 2024



Neural models have demonstrated remarkable performance across diverse ranking tasks. However, the processes and internal mechanisms along which they determine relevance are still largely unknown. Existing approaches for analyzing neural ranker behavior with respect to IR properties rely either on assessing overall model behavior or employing probing methods that may offer an incomplete understanding of causal mechanisms. To provide a more granular understanding of internal model decision-making processes, we propose the use of causal interventions to reverse engineer neural rankers, and demonstrate how mechanistic interpretability methods can be used to isolate components satisfying term-frequency axioms within a ranking model. We identify a group of attention heads that detect duplicate tokens in earlier layers of the model, then communicate with downstream heads to compute overall document relevance. More generally, we propose that this style of mechanistic analysis opens up avenues for reverse engineering the processes neural retrieval models use to compute relevance. This work aims to initiate granular interpretability efforts that will not only benefit retrieval model development and training, but ultimately ensure safer deployment of these models.
Outlier Dimensions Encode Task-Specific Knowledge
Oct 26, 2023Representations from large language models (LLMs) are known to be dominated by a small subset of dimensions with exceedingly high variance. Previous works have argued that although ablating these outlier dimensions in LLM representations hurts downstream performance, outlier dimensions are detrimental to the representational quality of embeddings. In this study, we investigate how fine-tuning impacts outlier dimensions and show that 1) outlier dimensions that occur in pre-training persist in fine-tuned models and 2) a single outlier dimension can complete downstream tasks with a minimal error rate. Our results suggest that outlier dimensions can encode crucial task-specific knowledge and that the value of a representation in a single outlier dimension drives downstream model decisions.
SSE: A Metric for Evaluating Search System Explainability
Jun 16, 2023Explainable Information Retrieval (XIR) is a growing research area focused on enhancing transparency and trustworthiness of the complex decision-making processes taking place in modern information retrieval systems. While there has been progress in developing XIR systems, empirical evaluation tools to assess the degree of explainability attained by such systems are lacking. To close this gap and gain insights into the true merit of XIR systems, we extend existing insights from a factor analysis of search explainability to introduce SSE (Search System Explainability), an evaluation metric for XIR search systems. Through a crowdsourced user study, we demonstrate SSE's ability to distinguish between explainable and non-explainable systems, showing that systems with higher scores indeed indicate greater interpretability. Additionally, we observe comparable perceived temporal demand and performance levels between non-native and native English speakers. We hope that aside from these concrete contributions to XIR, this line of work will serve as a blueprint for similar explainability evaluation efforts in other domains of machine learning and natural language processing.
Are Layout-Infused Language Models Robust to Layout Distribution Shifts? A Case Study with Scientific Documents
Jun 01, 2023Recent work has shown that infusing layout features into language models (LMs) improves processing of visually-rich documents such as scientific papers. Layout-infused LMs are often evaluated on documents with familiar layout features (e.g., papers from the same publisher), but in practice models encounter documents with unfamiliar distributions of layout features, such as new combinations of text sizes and styles, or new spatial configurations of textual elements. In this work we test whether layout-infused LMs are robust to layout distribution shifts. As a case study we use the task of scientific document structure recovery, segmenting a scientific paper into its structural categories (e.g., "title", "caption", "reference"). To emulate distribution shifts that occur in practice we re-partition the GROTOAP2 dataset. We find that under layout distribution shifts model performance degrades by up to 20 F1. Simple training strategies, such as increasing training diversity, can reduce this degradation by over 35% relative F1; however, models fail to reach in-distribution performance in any tested out-of-distribution conditions. This work highlights the need to consider layout distribution shifts during model evaluation, and presents a methodology for conducting such evaluations.
Does unsupervised grammar induction need pixels?
Dec 20, 2022Are extralinguistic signals such as image pixels crucial for inducing constituency grammars? While past work has shown substantial gains from multimodal cues, we investigate whether such gains persist in the presence of rich information from large language models (LLMs). We find that our approach, LLM-based C-PCFG (LC-PCFG), outperforms previous multi-modal methods on the task of unsupervised constituency parsing, achieving state-of-the-art performance on a variety of datasets. Moreover, LC-PCFG results in an over 50% reduction in parameter count, and speedups in training time of 1.7x for image-aided models and more than 5x for video-aided models, respectively. These results challenge the notion that extralinguistic signals such as image pixels are needed for unsupervised grammar induction, and point to the need for better text-only baselines in evaluating the need of multi-modality for the task.
Evaluating Search Explainability with Psychometrics and Crowdsourcing
Oct 17, 2022
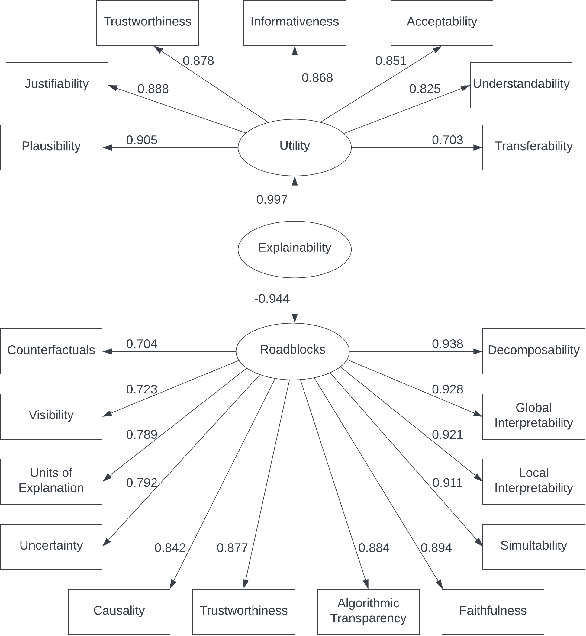
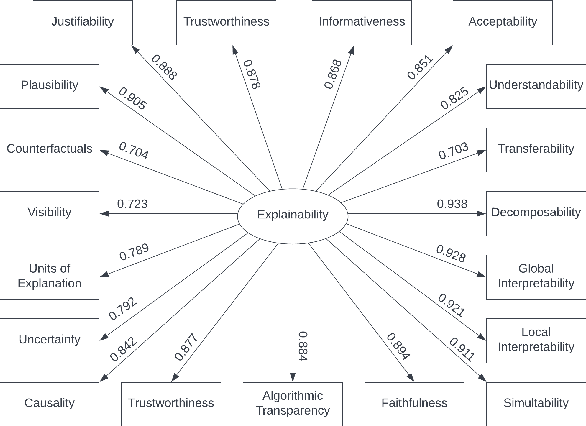
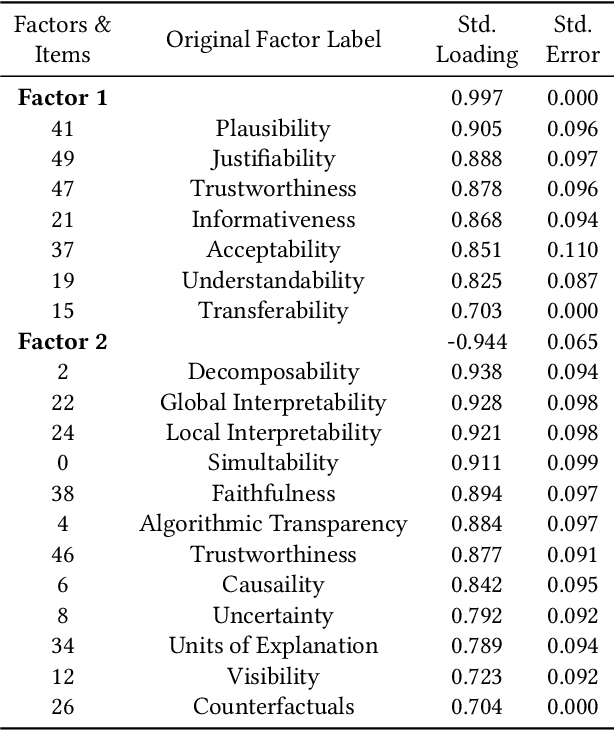
Information retrieval (IR) systems have become an integral part of our everyday lives. As search engines, recommender systems, and conversational agents are employed across various domains from recreational search to clinical decision support, there is an increasing need for transparent and explainable systems to guarantee accountable, fair, and unbiased results. Despite many recent advances towards explainable AI and IR techniques, there is no consensus on what it means for a system to be explainable. Although a growing body of literature suggests that explainability is comprised of multiple subfactors, virtually all existing approaches treat it as a singular notion. In this paper, we examine explainability in Web search systems, leveraging psychometrics and crowdsourcing to identify human-centered factors of explainability. Based on these factors, we establish a continuous-scale evaluation instrument for explainable search systems that allows researchers and practitioners to trade-off performance in a more flexible manner than what was previously possible.