 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to EdgeSuccessive Subspace Learning: An Overview
Feb 27, 2021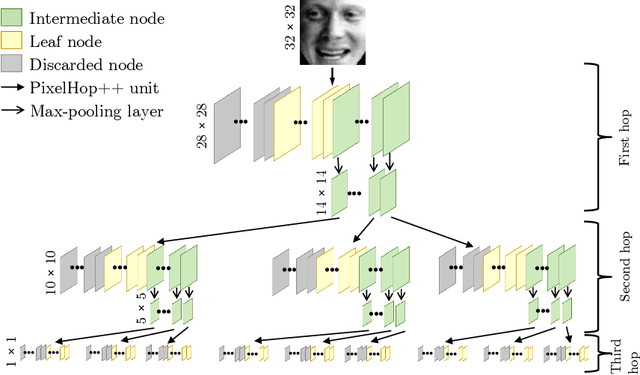
Successive Subspace Learning (SSL) offers a light-weight unsupervised feature learning method based on inherent statistical properties of data units (e.g. image pixels and points in point cloud sets). It has shown promising results, especially on small datasets. In this paper, we intuitively explain this method, provide an overview of its development, and point out some open questions and challenges for future research.
A Machine Learning Approach to Optimal Inverse Discrete Cosine Transform (IDCT) Design
Jan 31, 2021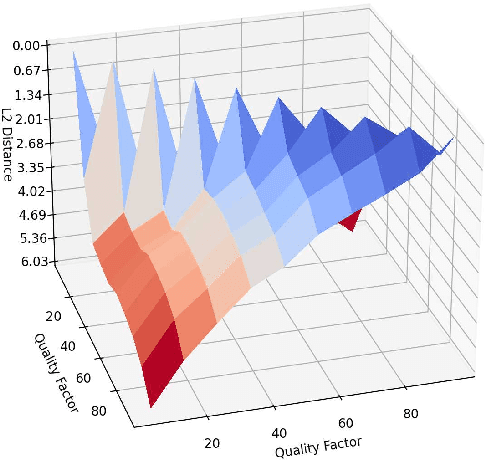
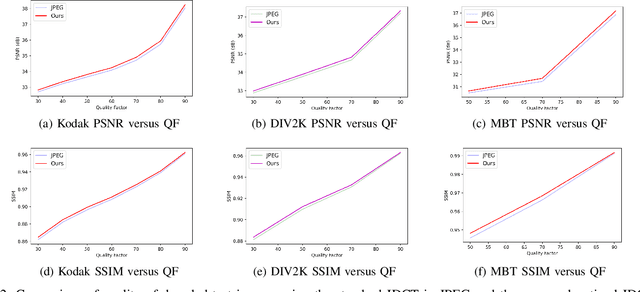


The design of the optimal inverse discrete cosine transform (IDCT) to compensate the quantization error is proposed for effective lossy image compression in this work. The forward and inverse DCTs are designed in pair in current image/video coding standards without taking the quantization effect into account. Yet, the distribution of quantized DCT coefficients deviate from that of original DCT coefficients. This is particularly obvious when the quality factor of JPEG compressed images is small. To address this problem, we first use a set of training images to learn the compound effect of forward DCT, quantization and dequantization in cascade. Then, a new IDCT kernel is learned to reverse the effect of such a pipeline. Experiments are conducted to demonstrate that the advantage of the new method, which has a gain of 0.11-0.30dB over the standard JPEG over a wide range of quality factors.
Symmetric-Constrained Irregular Structure Inpainting for Brain MRI Registration with Tumor Pathology
Jan 17, 2021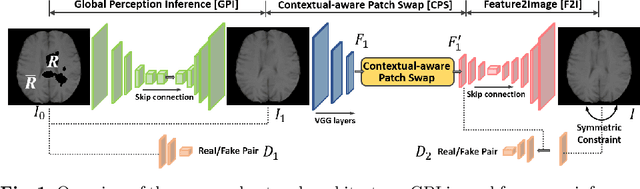
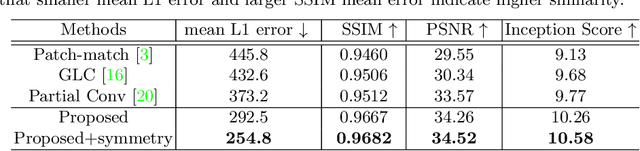
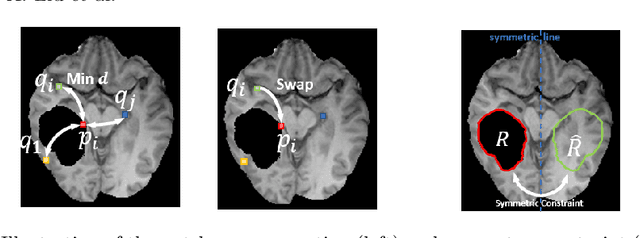

Deformable registration of magnetic resonance images between patients with brain tumors and healthy subjects has been an important tool to specify tumor geometry through location alignment and facilitate pathological analysis. Since tumor region does not match with any ordinary brain tissue, it has been difficult to deformably register a patients brain to a normal one. Many patient images are associated with irregularly distributed lesions, resulting in further distortion of normal tissue structures and complicating registration's similarity measure. In this work, we follow a multi-step context-aware image inpainting framework to generate synthetic tissue intensities in the tumor region. The coarse image-to-image translation is applied to make a rough inference of the missing parts. Then, a feature-level patch-match refinement module is applied to refine the details by modeling the semantic relevance between patch-wise features. A symmetry constraint reflecting a large degree of anatomical symmetry in the brain is further proposed to achieve better structure understanding. Deformable registration is applied between inpainted patient images and normal brains, and the resulting deformation field is eventually used to deform original patient data for the final alignment. The method was applied to the Multimodal Brain Tumor Segmentation (BraTS) 2018 challenge database and compared against three existing inpainting methods. The proposed method yielded results with increased peak signal-to-noise ratio, structural similarity index, inception score, and reduced L1 error, leading to successful patient-to-normal brain image registration.
VoxelHop: Successive Subspace Learning for ALS Disease Classification Using Structural MRI
Jan 13, 2021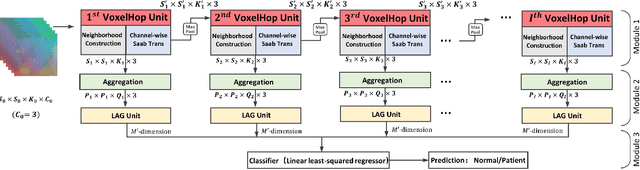
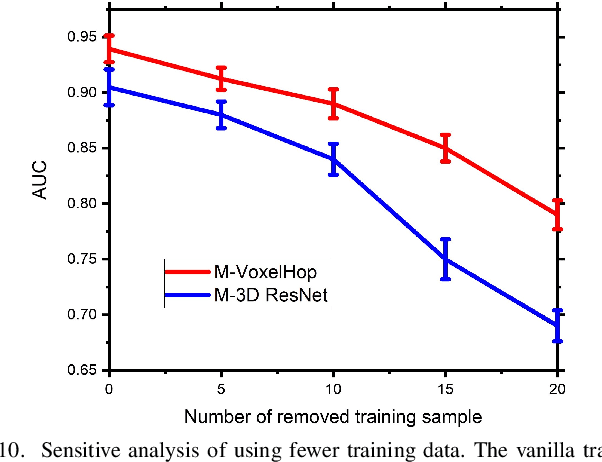
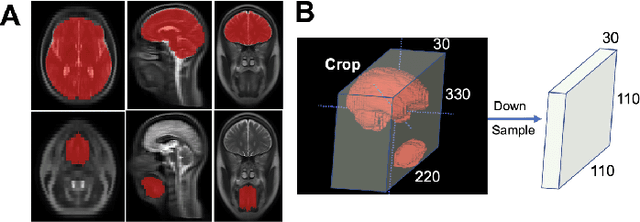
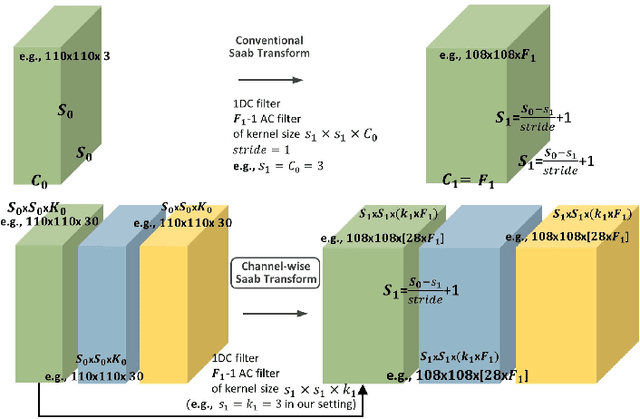
Deep learning has great potential for accurate detection and classification of diseases with medical imaging data, but the performance is often limited by the number of training datasets and memory requirements. In addition, many deep learning models are considered a "black-box," thereby often limiting their adoption in clinical applications. To address this, we present a successive subspace learning model, termed VoxelHop, for accurate classification of Amyotrophic Lateral Sclerosis (ALS) using T2-weighted structural MRI data. Compared with popular convolutional neural network (CNN) architectures, VoxelHop has modular and transparent structures with fewer parameters without any backpropagation, so it is well-suited to small dataset size and 3D imaging data. Our VoxelHop has four key components, including (1) sequential expansion of near-to-far neighborhood for multi-channel 3D data; (2) subspace approximation for unsupervised dimension reduction; (3) label-assisted regression for supervised dimension reduction; and (4) concatenation of features and classification between controls and patients. Our experimental results demonstrate that our framework using a total of 20 controls and 26 patients achieves an accuracy of 93.48$\%$ and an AUC score of 0.9394 in differentiating patients from controls, even with a relatively small number of datasets, showing its robustness and effectiveness. Our thorough evaluations also show its validity and superiority to the state-of-the-art 3D CNN classification methods. Our framework can easily be generalized to other classification tasks using different imaging modalities.
Subtype-aware Unsupervised Domain Adaptation for Medical Diagnosis
Jan 11, 2021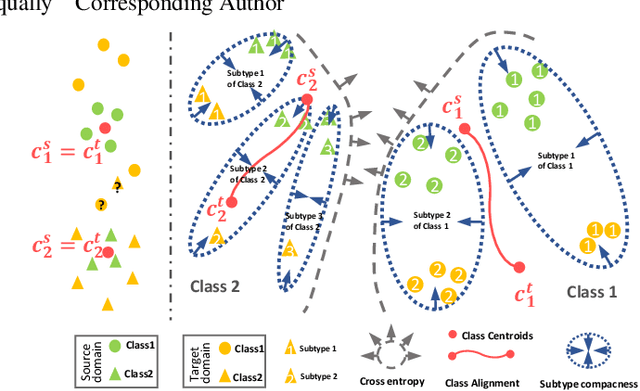
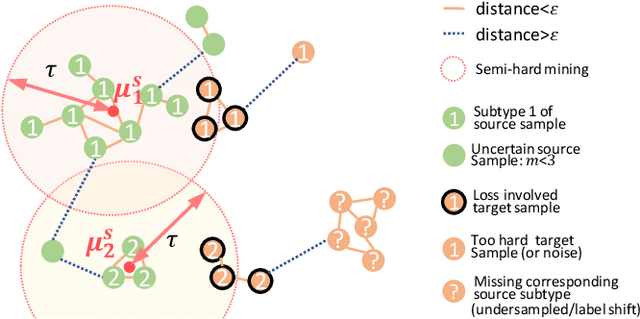
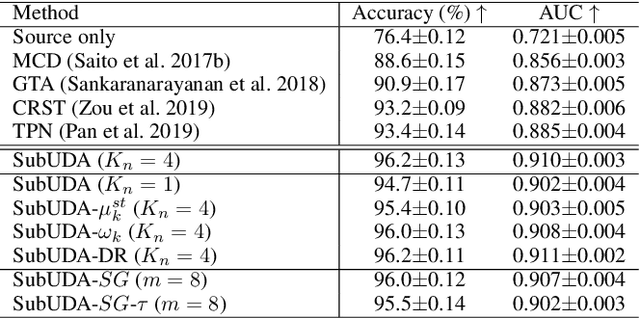
Recent advances in unsupervised domain adaptation (UDA) show that transferable prototypical learning presents a powerful means for class conditional alignment, which encourages the closeness of cross-domain class centroids. However, the cross-domain inner-class compactness and the underlying fine-grained subtype structure remained largely underexplored. In this work, we propose to adaptively carry out the fine-grained subtype-aware alignment by explicitly enforcing the class-wise separation and subtype-wise compactness with intermediate pseudo labels. Our key insight is that the unlabeled subtypes of a class can be divergent to one another with different conditional and label shifts, while inheriting the local proximity within a subtype. The cases of with or without the prior information on subtype numbers are investigated to discover the underlying subtype structure in an online fashion. The proposed subtype-aware dynamic UDA achieves promising results on medical diagnosis tasks.
GraphHop: An Enhanced Label Propagation Method for Node Classification
Jan 07, 2021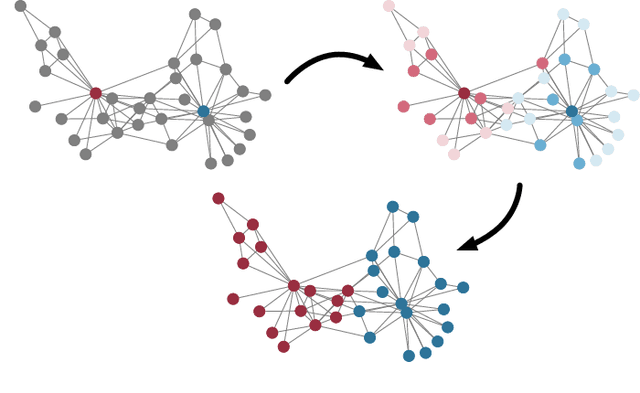
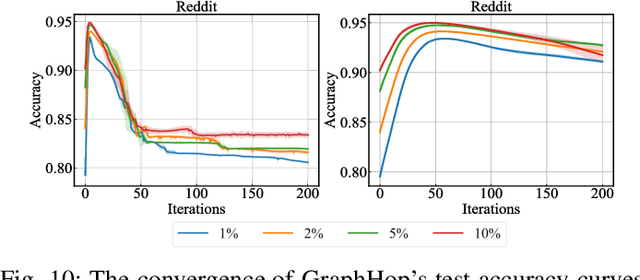
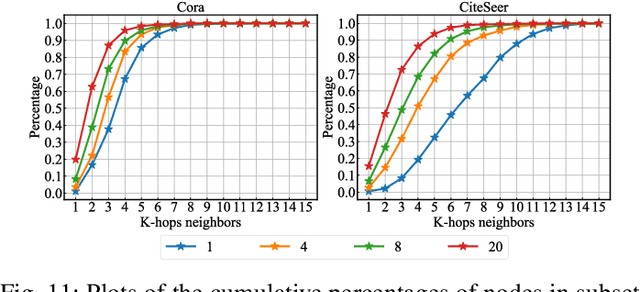
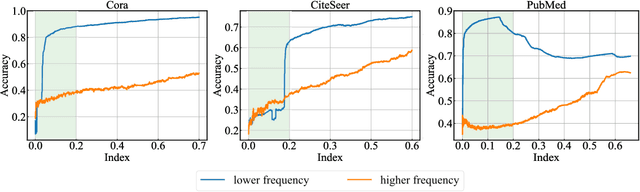
A scalable semi-supervised node classification method on graph-structured data, called GraphHop, is proposed in this work. The graph contains attributes of all nodes but labels of a few nodes. The classical label propagation (LP) method and the emerging graph convolutional network (GCN) are two popular semi-supervised solutions to this problem. The LP method is not effective in modeling node attributes and labels jointly or facing a slow convergence rate on large-scale graphs. GraphHop is proposed to its shortcoming. With proper initial label vector embeddings, each iteration of GraphHop contains two steps: 1) label aggregation and 2) label update. In Step 1, each node aggregates its neighbors' label vectors obtained in the previous iteration. In Step 2, a new label vector is predicted for each node based on the label of the node itself and the aggregated label information obtained in Step 1. This iterative procedure exploits the neighborhood information and enables GraphHop to perform well in an extremely small label rate setting and scale well for very large graphs. Experimental results show that GraphHop outperforms state-of-the-art graph learning methods on a wide range of tasks (e.g., multi-label and multi-class classification on citation networks, social graphs, and commodity consumption graphs) in graphs of various sizes. Our codes are publicly available on GitHub (https://github.com/TianXieUSC/GraphHop).
Protecting Big Data Privacy Using Randomized Tensor Network Decomposition and Dispersed Tensor Computation
Jan 04, 2021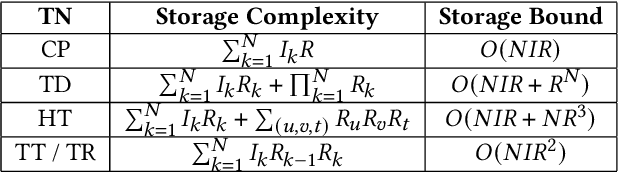
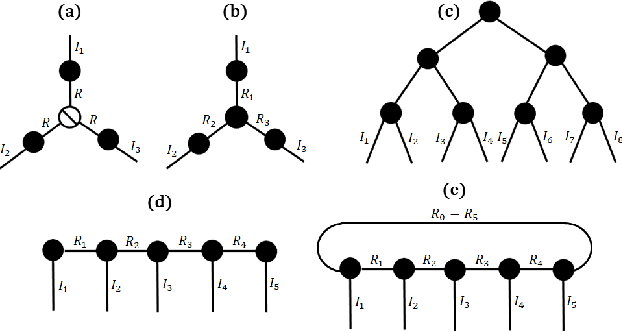
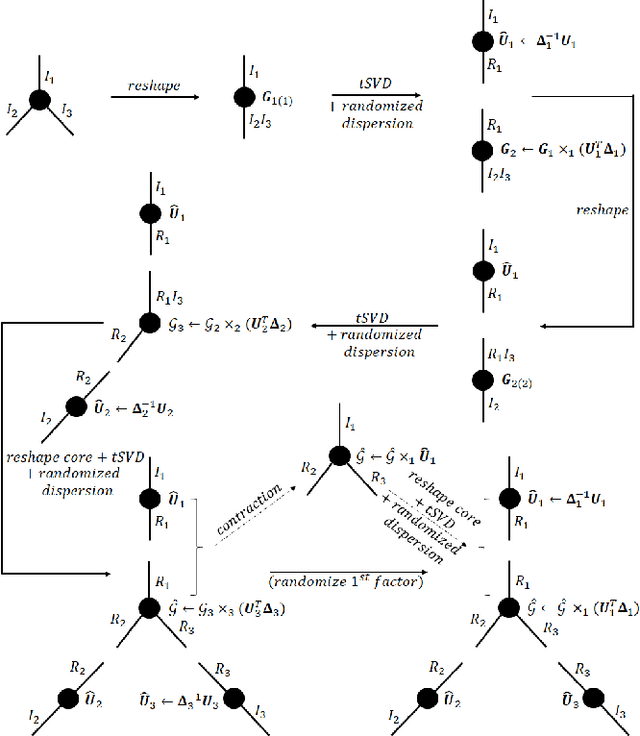
Data privacy is an important issue for organizations and enterprises to securely outsource data storage, sharing, and computation on clouds / fogs. However, data encryption is complicated in terms of the key management and distribution; existing secure computation techniques are expensive in terms of computational / communication cost and therefore do not scale to big data computation. Tensor network decomposition and distributed tensor computation have been widely used in signal processing and machine learning for dimensionality reduction and large-scale optimization. However, the potential of distributed tensor networks for big data privacy preservation have not been considered before, this motivates the current study. Our primary intuition is that tensor network representations are mathematically non-unique, unlinkable, and uninterpretable; tensor network representations naturally support a range of multilinear operations for compressed and distributed / dispersed computation. Therefore, we propose randomized algorithms to decompose big data into randomized tensor network representations and analyze the privacy leakage for 1D to 3D data tensors. The randomness mainly comes from the complex structural information commonly found in big data; randomization is based on controlled perturbation applied to the tensor blocks prior to decomposition. The distributed tensor representations are dispersed on multiple clouds / fogs or servers / devices with metadata privacy, this provides both distributed trust and management to seamlessly secure big data storage, communication, sharing, and computation. Experiments show that the proposed randomization techniques are helpful for big data anonymization and efficient for big data storage and computation.
Explainable Machine Learning based Transform Coding for High Efficiency Intra Prediction
Dec 21, 2020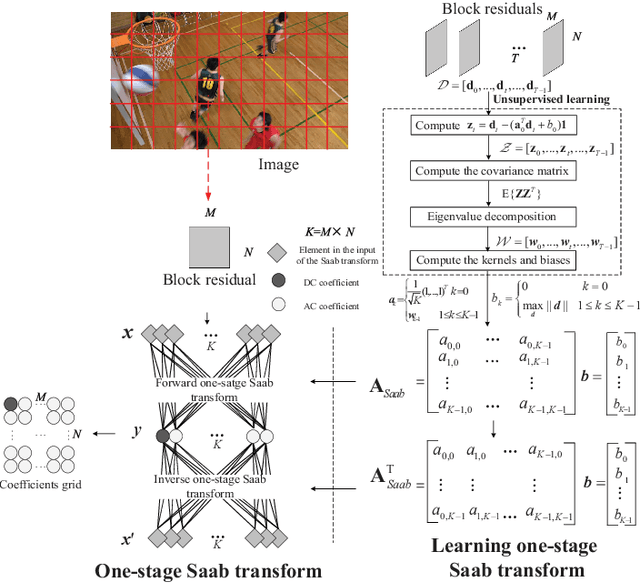
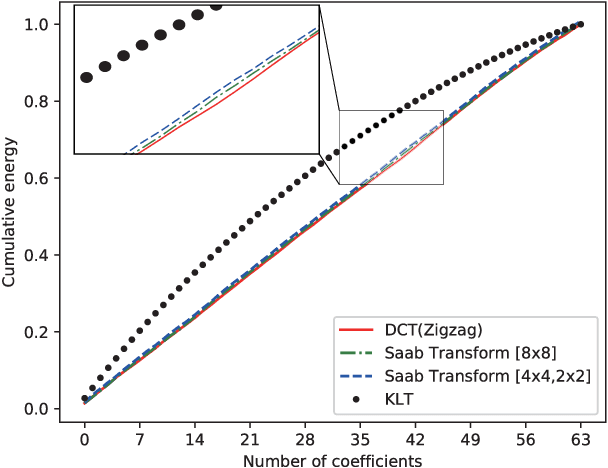
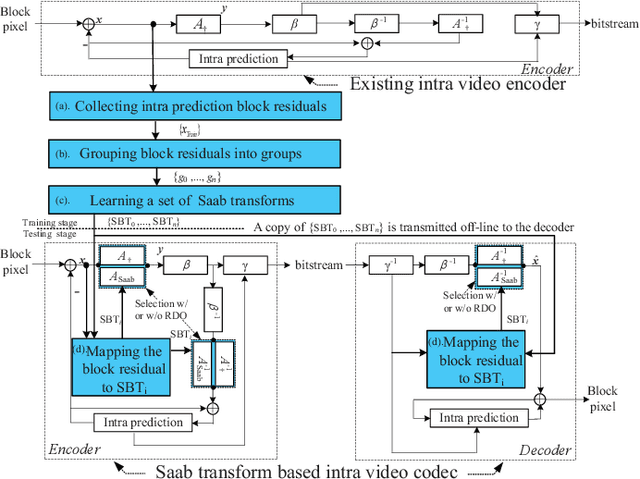
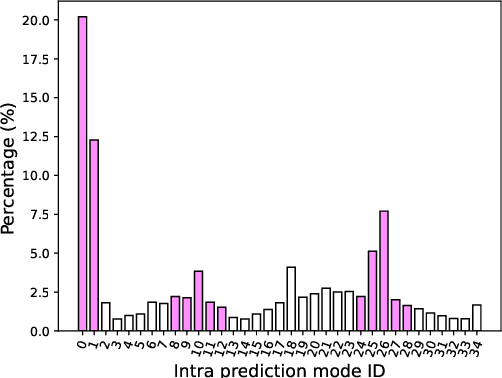
Machine learning techniques provide a chance to explore the coding performance potential of transform. In this work, we propose an explainable transform based intra video coding to improve the coding efficiency. Firstly, we model machine learning based transform design as an optimization problem of maximizing the energy compaction or decorrelation capability. The explainable machine learning based transform, i.e., Subspace Approximation with Adjusted Bias (Saab) transform, is analyzed and compared with the mainstream Discrete Cosine Transform (DCT) on their energy compaction and decorrelation capabilities. Secondly, we propose a Saab transform based intra video coding framework with off-line Saab transform learning. Meanwhile, intra mode dependent Saab transform is developed. Then, Rate Distortion (RD) gain of Saab transform based intra video coding is theoretically and experimentally analyzed in detail. Finally, three strategies on integrating the Saab transform and DCT in intra video coding are developed to improve the coding efficiency. Experimental results demonstrate that the proposed 8$\times$8 Saab transform based intra video coding can achieve Bj{\o}nteggard Delta Bit Rate (BDBR) from -1.19% to -10.00% and -3.07% on average as compared with the mainstream 8$\times$8 DCT based coding scheme.
Low-Resolution Face Recognition In Resource-Constrained Environments
Nov 23, 2020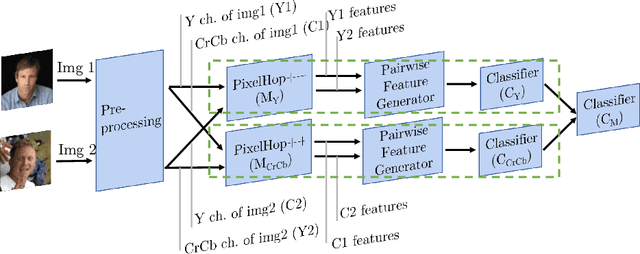

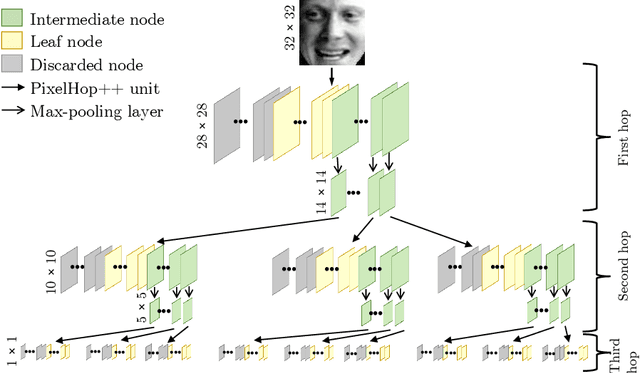

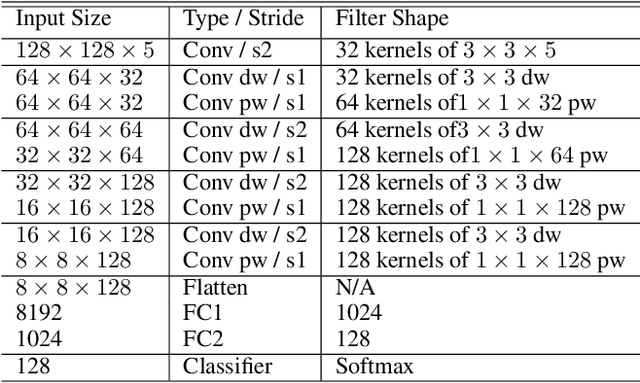
A non-parametric low-resolution face recognition model for resource-constrained environments with limited networking and computing is proposed in this work. Such environments often demand a small model capable of being effectively trained on a small number of labeled data samples, with low training complexity, and low-resolution input images. To address these challenges, we adopt an emerging explainable machine learning methodology called successive subspace learning (SSL).SSL offers an explainable non-parametric model that flexibly trades the model size for verification performance. Its training complexity is significantly lower since its model is trained in a one-pass feedforward manner without backpropagation. Furthermore, active learning can be conveniently incorporated to reduce the labeling cost. The effectiveness of the proposed model is demonstrated by experiments on the LFW and the CMU Multi-PIE datasets.
SLADE: A Self-Training Framework For Distance Metric Learning
Nov 20, 2020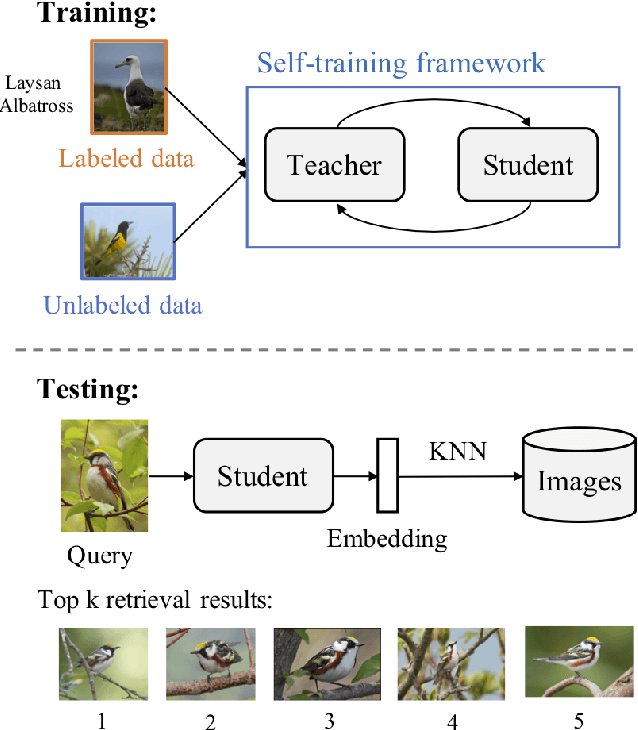
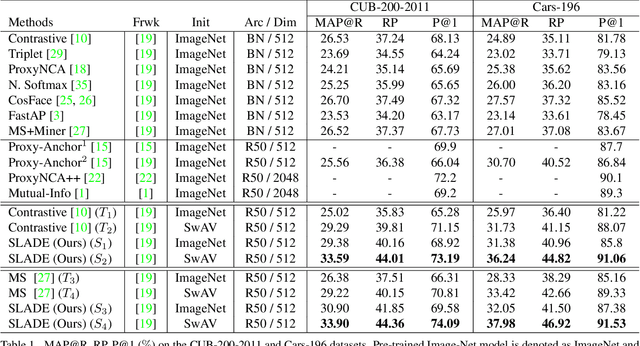
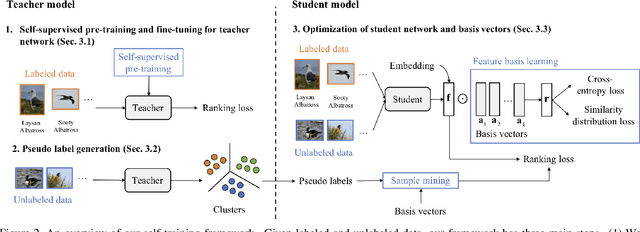
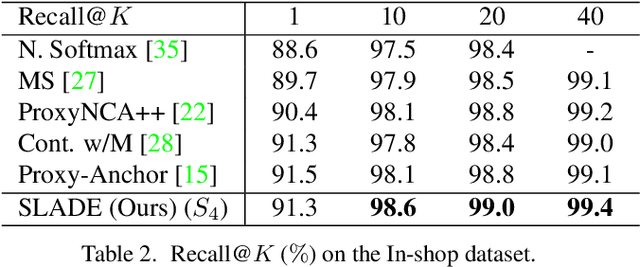
Most existing distance metric learning approaches use fully labeled data to learn the sample similarities in an embedding space. We present a self-training framework, SLADE, to improve retrieval performance by leveraging additional unlabeled data. We first train a teacher model on the labeled data and use it to generate pseudo labels for the unlabeled data. We then train a student model on both labels and pseudo labels to generate final feature embeddings. We use self-supervised representation learning to initialize the teacher model. To better deal with noisy pseudo labels generated by the teacher network, we design a new feature basis learning component for the student network, which learns basis functions of feature representations for unlabeled data. The learned basis vectors better measure the pairwise similarity and are used to select high-confident samples for training the student network. We evaluate our method on standard retrieval benchmarks: CUB-200, Cars-196 and In-shop. Experimental results demonstrate that our approach significantly improves the performance over the state-of-the-art methods.