 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to EdgeA Systematic Framework for Tabular Data Disentanglement
Apr 09, 2026Tabular data, widely used in various applications such as industrial control systems, finance, and supply chain, often contains complex interrelationships among its attributes. Data disentanglement seeks to transform such data into latent variables with reduced interdependencies, facilitating more effective and efficient processing. Despite the extensive studies on data disentanglement over image, text, or audio data, tabular data disentanglement may require further investigation due to the more intricate attribute interactions typically found in tabular data. Moreover, due to the highly complex interrelationships, direct translation from other data domains results in suboptimal data disentanglement. Existing tabular data disentanglement methods, such as factor analysis, CT-GAN, and VAE face limitations including scalability issues, mode collapse, and poor extrapolation. In this paper, we propose the use of a framework to provide a systematic view on tabular data disentanglement that modularizes the process into four core components: data extraction, data modeling, model analysis, and latent representation extrapolation. We believe this work provides a deeper understanding of tabular data disentanglement and existing methods, and lays the foundation for potential future research in developing robust, efficient, and scalable data disentanglement techniques. Finally, we demonstrate the framework's applicability through a case study on synthetic tabular data generation, showcasing its potential in the particular downstream task of data synthesis.
MPRU: Modular Projection-Redistribution Unlearning as Output Filter for Classification Pipelines
Oct 30, 2025As a new and promising approach, existing machine unlearning (MU) works typically emphasize theoretical formulations or optimization objectives to achieve knowledge removal. However, when deployed in real-world scenarios, such solutions typically face scalability issues and have to address practical requirements such as full access to original datasets and model. In contrast to the existing approaches, we regard classification training as a sequential process where classes are learned sequentially, which we call \emph{inductive approach}. Unlearning can then be done by reversing the last training sequence. This is implemented by appending a projection-redistribution layer in the end of the model. Such an approach does not require full access to the original dataset or the model, addressing the challenges of existing methods. This enables modular and model-agnostic deployment as an output filter into existing classification pipelines with minimal alterations. We conducted multiple experiments across multiple datasets including image (CIFAR-10/100 using CNN-based model) and tabular datasets (Covertype using tree-based model). Experiment results show consistently similar output to a fully retrained model with a high computational cost reduction. This demonstrates the applicability, scalability, and system compatibility of our solution while maintaining the performance of the output in a more practical setting.
Protecting Big Data Privacy Using Randomized Tensor Network Decomposition and Dispersed Tensor Computation
Jan 04, 2021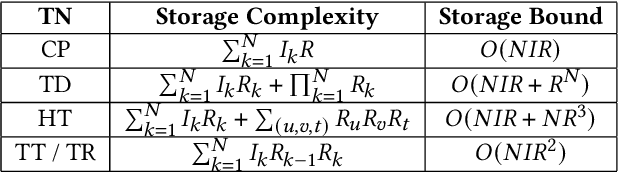
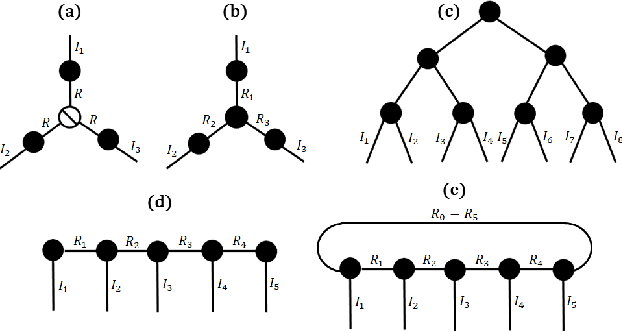
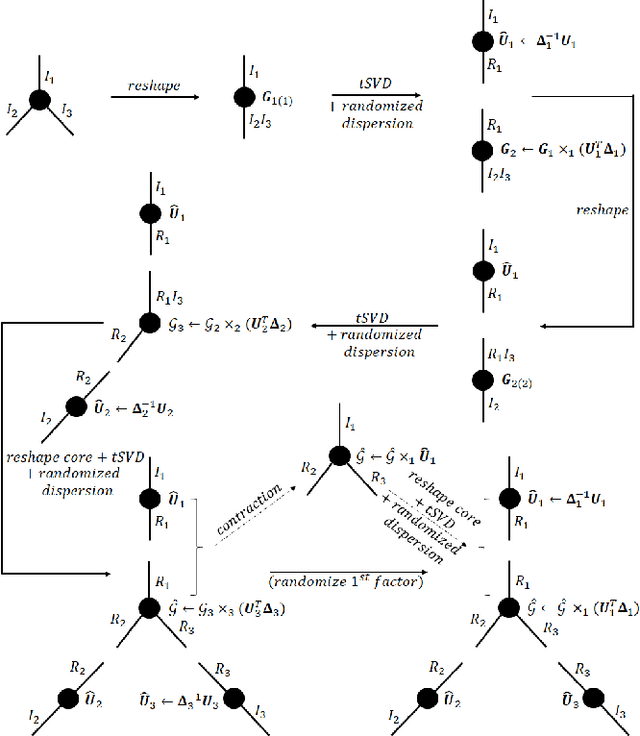
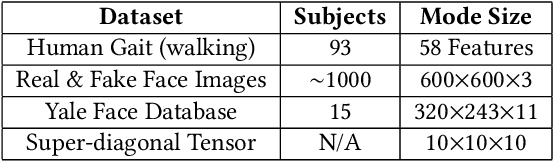
Data privacy is an important issue for organizations and enterprises to securely outsource data storage, sharing, and computation on clouds / fogs. However, data encryption is complicated in terms of the key management and distribution; existing secure computation techniques are expensive in terms of computational / communication cost and therefore do not scale to big data computation. Tensor network decomposition and distributed tensor computation have been widely used in signal processing and machine learning for dimensionality reduction and large-scale optimization. However, the potential of distributed tensor networks for big data privacy preservation have not been considered before, this motivates the current study. Our primary intuition is that tensor network representations are mathematically non-unique, unlinkable, and uninterpretable; tensor network representations naturally support a range of multilinear operations for compressed and distributed / dispersed computation. Therefore, we propose randomized algorithms to decompose big data into randomized tensor network representations and analyze the privacy leakage for 1D to 3D data tensors. The randomness mainly comes from the complex structural information commonly found in big data; randomization is based on controlled perturbation applied to the tensor blocks prior to decomposition. The distributed tensor representations are dispersed on multiple clouds / fogs or servers / devices with metadata privacy, this provides both distributed trust and management to seamlessly secure big data storage, communication, sharing, and computation. Experiments show that the proposed randomization techniques are helpful for big data anonymization and efficient for big data storage and computation.
MPC-enabled Privacy-Preserving Neural Network Training against Malicious Attack
Aug 12, 2020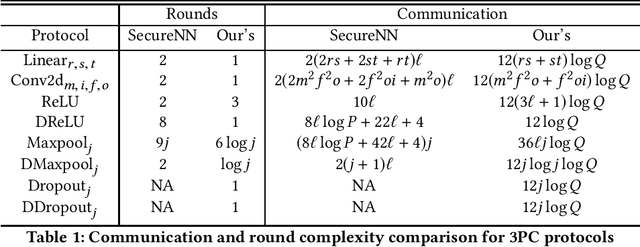
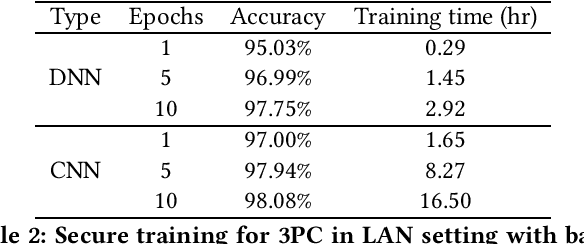
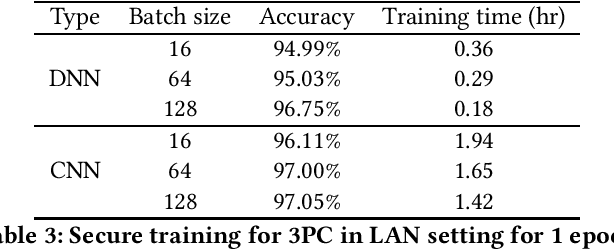
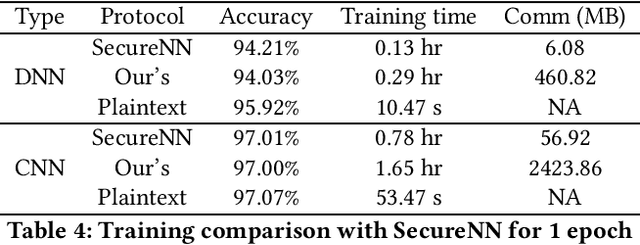
In the past decades, the application of secure multiparty computation (MPC) to machine learning, especially privacy-preserving neural network training, has attracted tremendous attention from both academia and industry. MPC enables several data owners to jointly train a neural network while preserving their data privacy. However, most previous works focus on semi-honest threat model which cannot withstand fraudulent messages sent by malicious participants. In this work, we propose a construction of efficient $n$-party protocols for secure neural network training that can secure the privacy of all honest participants even when a majority of the parties are malicious. Compared to the other designs that provides semi-honest security in a dishonest majority setting, our actively secured neural network training incurs affordable efficiency overheads. In addition, we propose a scheme to allow additive shares defined over an integer ring $\mathbb{Z}_N$ to be securely converted to additive shares over a finite field $\mathbb{Z}_Q$. This conversion scheme is essential in correctly converting shared Beaver triples in order to make the values generated in preprocessing phase to be usable in online phase, which may be of independent interest.