 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to EdgeMulti-Objective Policy Generation for Multi-Robot Systems Using Riemannian Motion Policies
Feb 16, 2019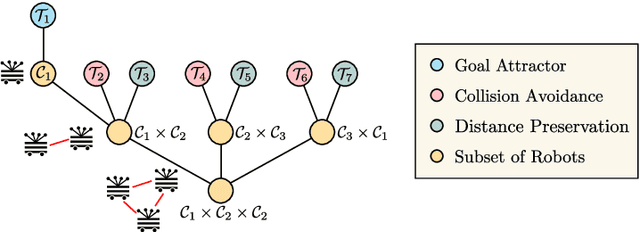
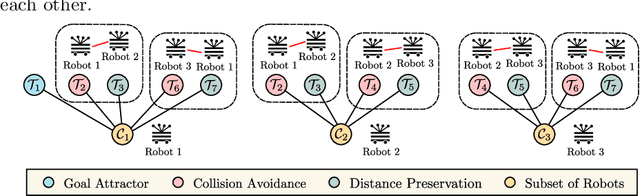
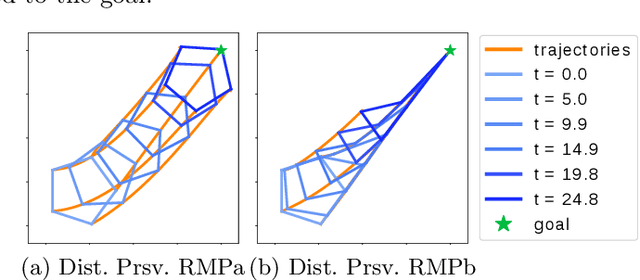
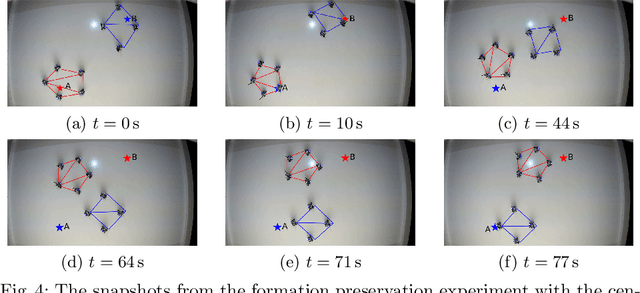
In the multi-robot systems literature, control policies are typically obtained through descent rules for a potential function which encodes a single team-level objective. However, for multi-objective tasks, it can be hard to design a single control policy that fulfills all the objectives. In this paper, we exploit the idea of decomposing the multi-objective task into a set of simple subtasks. We associate each subtask with a potentially lower-dimensional manifold, and design Riemannian Motion Policies (RMPs) on these manifolds. Centralized and decentralized algorithms are proposed to combine these policies into a final control policy on the configuration space that the robots can execute. We propose a collection of RMPs for simple multi-robot tasks that can be used for building controllers for more complicated tasks. In particular, we prove that many existing multi-robot controllers can be closely approximated by combining the proposed RMPs. Theoretical analysis shows that the multi-robot system under the generated control policy is stable. The proposed framework is validated through both simulated tasks and robotic implementations.
Continuous-Time Gaussian Process Motion Planning via Probabilistic Inference
Nov 22, 2018


We introduce a novel formulation of motion planning, for continuous-time trajectories, as probabilistic inference. We first show how smooth continuous-time trajectories can be represented by a small number of states using sparse Gaussian process (GP) models. We next develop an efficient gradient-based optimization algorithm that exploits this sparsity and GP interpolation. We call this algorithm the Gaussian Process Motion Planner (GPMP). We then detail how motion planning problems can be formulated as probabilistic inference on a factor graph. This forms the basis for GPMP2, a very efficient algorithm that combines GP representations of trajectories with fast, structure-exploiting inference via numerical optimization. Finally, we extend GPMP2 to an incremental algorithm, iGPMP2, that can efficiently replan when conditions change. We benchmark our algorithms against several sampling-based and trajectory optimization-based motion planning algorithms on planning problems in multiple environments. Our evaluation reveals that GPMP2 is several times faster than previous algorithms while retaining robustness. We also benchmark iGPMP2 on replanning problems, and show that it can find successful solutions in a fraction of the time required by GPMP2 to replan from scratch.
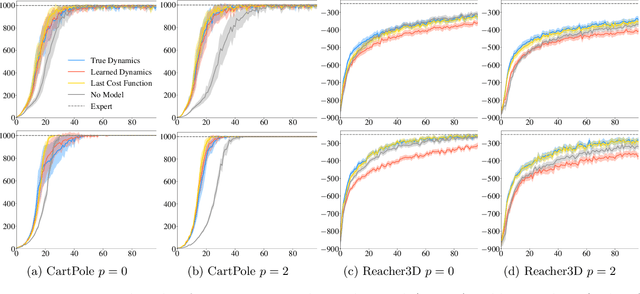
Differentiable MPC for End-to-end Planning and Control
Oct 31, 2018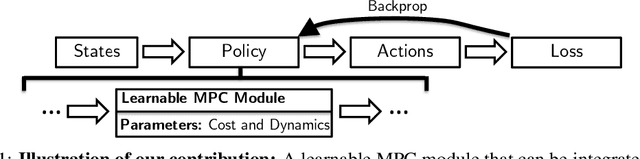
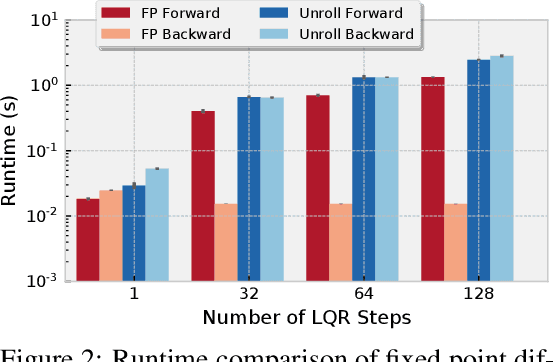
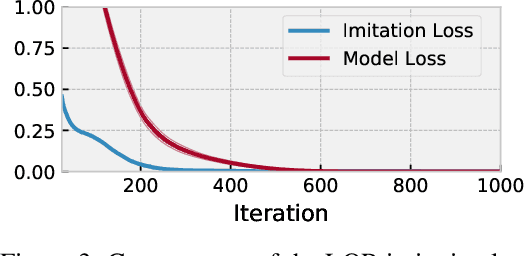
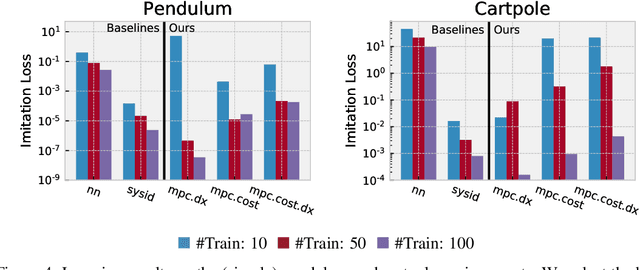
We present foundations for using Model Predictive Control (MPC) as a differentiable policy class for reinforcement learning in continuous state and action spaces. This provides one way of leveraging and combining the advantages of model-free and model-based approaches. Specifically, we differentiate through MPC by using the KKT conditions of the convex approximation at a fixed point of the controller. Using this strategy, we are able to learn the cost and dynamics of a controller via end-to-end learning. Our experiments focus on imitation learning in the pendulum and cartpole domains, where we learn the cost and dynamics terms of an MPC policy class. We show that our MPC policies are significantly more data-efficient than a generic neural network and that our method is superior to traditional system identification in a setting where the expert is unrealizable.
Learning and Inference in Hilbert Space with Quantum Graphical Models
Oct 29, 2018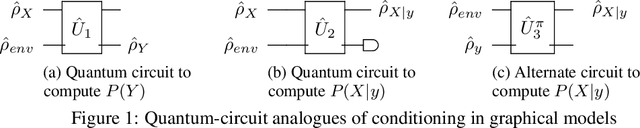
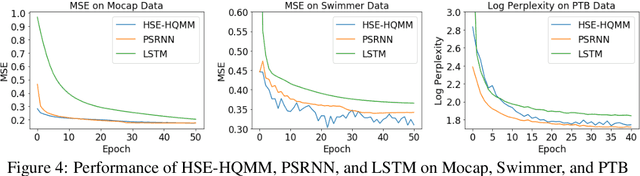
Quantum Graphical Models (QGMs) generalize classical graphical models by adopting the formalism for reasoning about uncertainty from quantum mechanics. Unlike classical graphical models, QGMs represent uncertainty with density matrices in complex Hilbert spaces. Hilbert space embeddings (HSEs) also generalize Bayesian inference in Hilbert spaces. We investigate the link between QGMs and HSEs and show that the sum rule and Bayes rule for QGMs are equivalent to the kernel sum rule in HSEs and a special case of Nadaraya-Watson kernel regression, respectively. We show that these operations can be kernelized, and use these insights to propose a Hilbert Space Embedding of Hidden Quantum Markov Models (HSE-HQMM) to model dynamics. We present experimental results showing that HSE-HQMMs are competitive with state-of-the-art models like LSTMs and PSRNNs on several datasets, while also providing a nonparametric method for maintaining a probability distribution over continuous-valued features.
Orthogonally Decoupled Variational Gaussian Processes
Oct 28, 2018

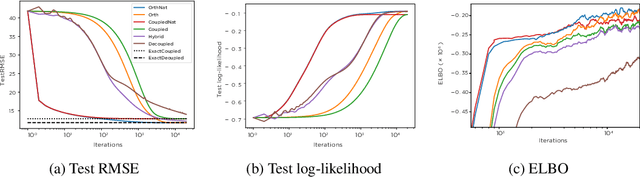

Gaussian processes (GPs) provide a powerful non-parametric framework for reasoning over functions. Despite appealing theory, its superlinear computational and memory complexities have presented a long-standing challenge. State-of-the-art sparse variational inference methods trade modeling accuracy against complexity. However, the complexities of these methods still scale superlinearly in the number of basis functions, implying that that sparse GP methods are able to learn from large datasets only when a small model is used. Recently, a decoupled approach was proposed that removes the unnecessary coupling between the complexities of modeling the mean and the covariance functions of a GP. It achieves a linear complexity in the number of mean parameters, so an expressive posterior mean function can be modeled. While promising, this approach suffers from optimization difficulties due to ill-conditioning and non-convexity. In this work, we propose an alternative decoupled parametrization. It adopts an orthogonal basis in the mean function to model the residues that cannot be learned by the standard coupled approach. Therefore, our method extends, rather than replaces, the coupled approach to achieve strictly better performance. This construction admits a straightforward natural gradient update rule, so the structure of the information manifold that is lost during decoupling can be leveraged to speed up learning. Empirically, our algorithm demonstrates significantly faster convergence in multiple experiments.
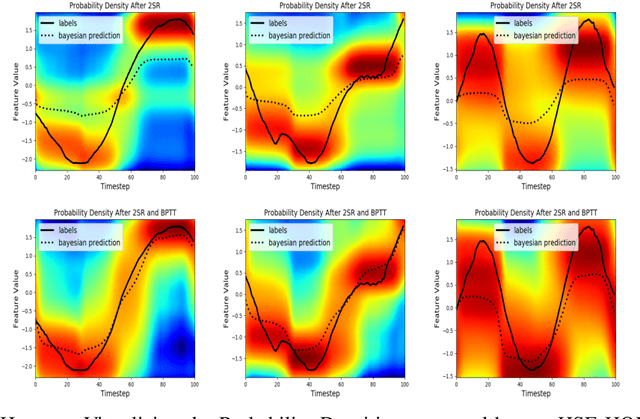
Truncated Back-propagation for Bilevel Optimization
Oct 25, 2018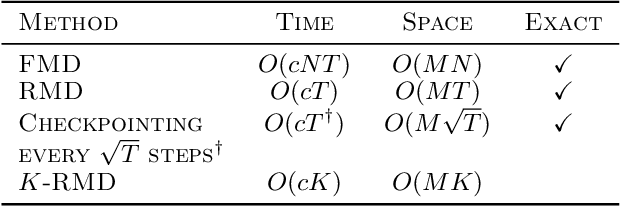
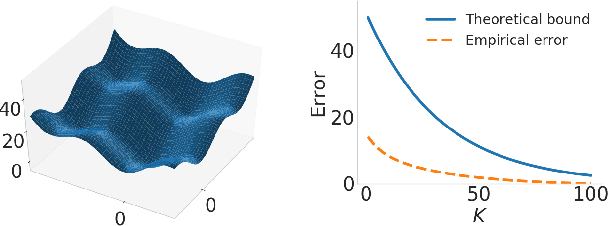
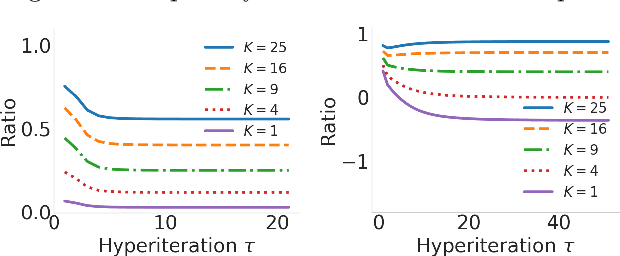
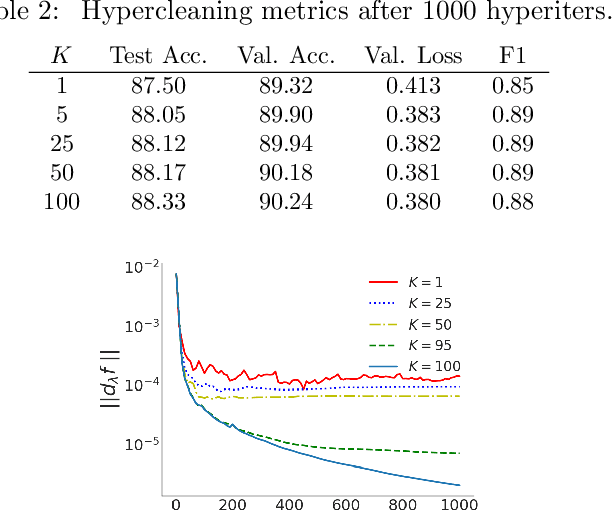
Bilevel optimization has been recently revisited for designing and analyzing algorithms in hyperparameter tuning and meta learning tasks. However, due to its nested structure, evaluating exact gradients for high-dimensional problems is computationally challenging. One heuristic to circumvent this difficulty is to use the approximate gradient given by performing truncated back-propagation through the iterative optimization procedure that solves the lower-level problem. Although promising empirical performance has been reported, its theoretical properties are still unclear. In this paper, we analyze the properties of this family of approximate gradients and establish sufficient conditions for convergence. We validate this on several hyperparameter tuning and meta learning tasks. We find that optimization with the approximate gradient computed using few-step back-propagation often performs comparably to optimization with the exact gradient, while requiring far less memory and half the computation time.
Predictor-Corrector Policy Optimization
Oct 15, 2018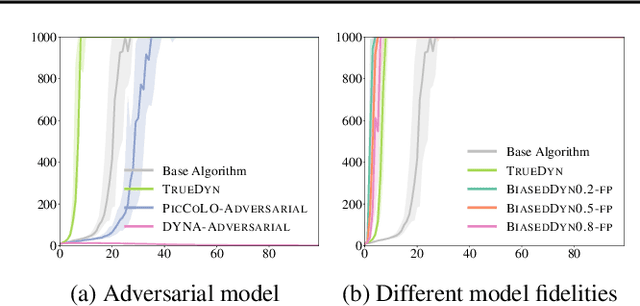
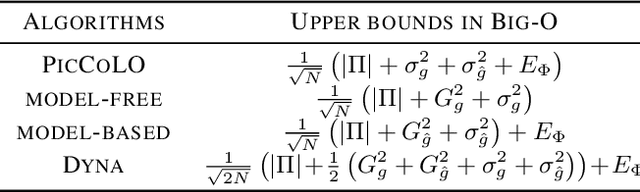
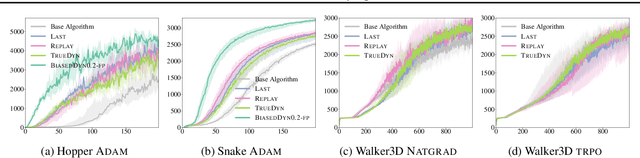
We present a predictor-corrector framework, called PicCoLO, that can transform a first-order model-free reinforcement or imitation learning algorithm into a new hybrid method that leverages predictive models to accelerate policy learning. The new "PicCoLOed" algorithm optimizes a policy by recursively repeating two steps: In the Prediction Step, the learner uses a model to predict the unseen future gradient and then applies the predicted estimate to update the policy; in the Correction Step, the learner runs the updated policy in the environment, receives the true gradient, and then corrects the policy using the gradient error. Unlike previous algorithms, PicCoLO corrects for the mistakes of using imperfect predicted gradients and hence does not suffer from model bias. The development of PicCoLO is made possible by a novel reduction from predictable online learning to adversarial online learning, which provides a systematic way to modify existing first-order algorithms to achieve the optimal regret with respect to predictable information. We show, in both theory and simulation, that the convergence rate of several first-order model-free algorithms can be improved by PicCoLO.
Accelerating Imitation Learning with Predictive Models
Oct 13, 2018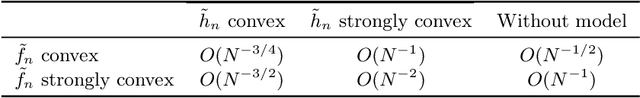
Sample efficiency is critical in solving real-world reinforcement learning problems, where agent-environment interactions can be costly. Imitation learning from expert advice has proved to be an effective strategy for reducing the number of interactions required to train a policy. Online imitation learning, which interleaves policy evaluation and policy optimization, is a particularly effective technique with provable performance guarantees. In this work, we seek to further accelerate the convergence rate of online imitation learning, thereby making it more sample efficient. We propose two model-based algorithms inspired by Follow-the-Leader (FTL) with prediction: MoBIL-VI based on solving variational inequalities and MoBIL-Prox based on stochastic first-order updates. These two methods leverage a model to predict future gradients to speed up policy learning. When the model oracle is learned online, these algorithms can provably accelerate the best known convergence rate up to an order. Our algorithms can be viewed as a generalization of stochastic Mirror-Prox (Juditsky et al., 2011), and admit a simple constructive FTL-style analysis of performance.
Agile Off-Road Autonomous Driving Using End-to-End Deep Imitation Learning
Sep 10, 2018
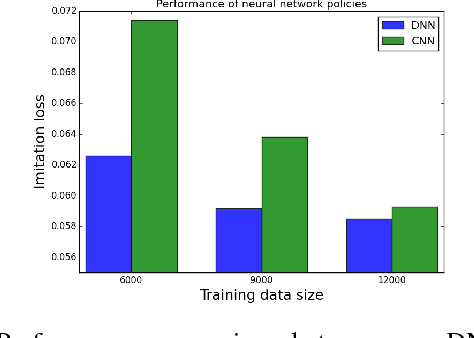
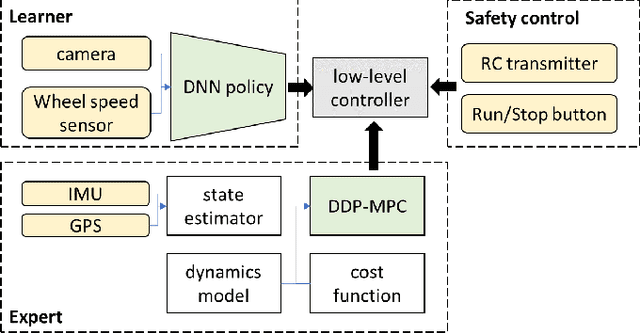

We present an end-to-end imitation learning system for agile, off-road autonomous driving using only low-cost on-board sensors. By imitating a model predictive controller equipped with advanced sensors, we train a deep neural network control policy to map raw, high-dimensional observations to continuous steering and throttle commands. Compared with recent approaches to similar tasks, our method requires neither state estimation nor on-the-fly planning to navigate the vehicle. Our approach relies on, and experimentally validates, recent imitation learning theory. Empirically, we show that policies trained with online imitation learning overcome well-known challenges related to covariate shift and generalize better than policies trained with batch imitation learning. Built on these insights, our autonomous driving system demonstrates successful high-speed off-road driving, matching the state-of-the-art performance.
Learning to Align Images using Weak Geometric Supervision
Aug 04, 2018
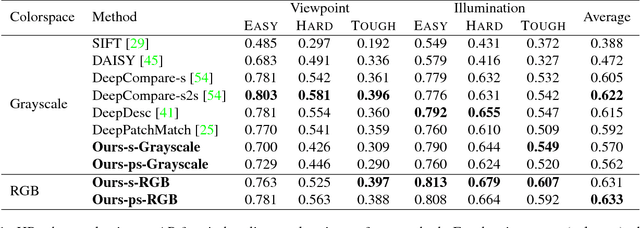
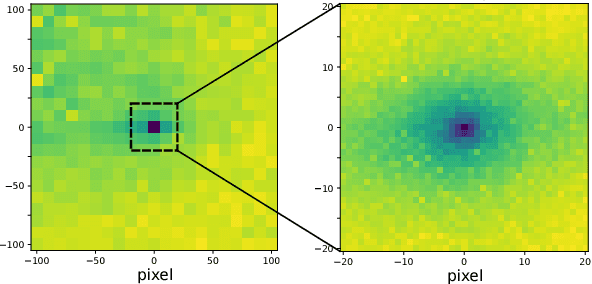
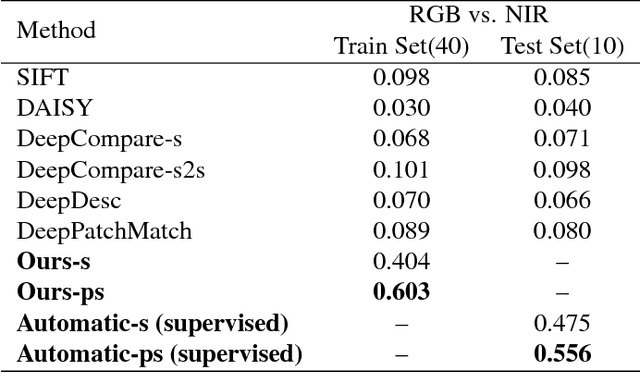
Image alignment tasks require accurate pixel correspondences, which are usually recovered by matching local feature descriptors. Such descriptors are often derived using supervised learning on existing datasets with ground truth correspondences. However, the cost of creating such datasets is usually prohibitive. In this paper, we propose a new approach to align two images related by an unknown 2D homography where the local descriptor is learned from scratch from the images and the homography is estimated simultaneously. Our key insight is that a siamese convolutional neural network can be trained jointly while iteratively updating the homography parameters by optimizing a single loss function. Our method is currently weakly supervised because the input images need to be roughly aligned. We have used this method to align images of different modalities such as RGB and near-infra-red (NIR) without using any prior labeled data. Images automatically aligned by our method were then used to train descriptors that generalize to new images. We also evaluated our method on RGB images. On the HPatches benchmark, our method achieves comparable accuracy to deep local descriptors that were trained offline in a supervised setting.