 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to EdgeComparison of Multilingual Self-Supervised and Weakly-Supervised Speech Pre-Training for Adaptation to Unseen Languages
May 21, 2023



Recent models such as XLS-R and Whisper have made multilingual speech technologies more accessible by pre-training on audio from around 100 spoken languages each. However, there are thousands of spoken languages worldwide, and adapting to new languages is an important problem. In this work, we aim to understand which model adapts better to languages unseen during pre-training. We fine-tune both models on 13 unseen languages and 18 seen languages. Our results show that the number of hours seen per language and language family during pre-training is predictive of how the models compare, despite the significant differences in the pre-training methods.
High-Dimensional Smoothed Entropy Estimation via Dimensionality Reduction
May 11, 2023



We study the problem of overcoming exponential sample complexity in differential entropy estimation under Gaussian convolutions. Specifically, we consider the estimation of the differential entropy $h(X+Z)$ via $n$ independently and identically distributed samples of $X$, where $X$ and $Z$ are independent $D$-dimensional random variables with $X$ sub-Gaussian with bounded second moment and $Z\sim\mathcal{N}(0,\sigma^2I_D)$. Under the absolute-error loss, the above problem has a parametric estimation rate of $\frac{c^D}{\sqrt{n}}$, which is exponential in data dimension $D$ and often problematic for applications. We overcome this exponential sample complexity by projecting $X$ to a low-dimensional space via principal component analysis (PCA) before the entropy estimation, and show that the asymptotic error overhead vanishes as the unexplained variance of the PCA vanishes. This implies near-optimal performance for inherently low-dimensional structures embedded in high-dimensional spaces, including hidden-layer outputs of deep neural networks (DNN), which can be used to estimate mutual information (MI) in DNNs. We provide numerical results verifying the performance of our PCA approach on Gaussian and spiral data. We also apply our method to analysis of information flow through neural network layers (c.f. information bottleneck), with results measuring mutual information in a noisy fully connected network and a noisy convolutional neural network (CNN) for MNIST classification.
C2KD: Cross-Lingual Cross-Modal Knowledge Distillation for Multilingual Text-Video Retrieval
Oct 07, 2022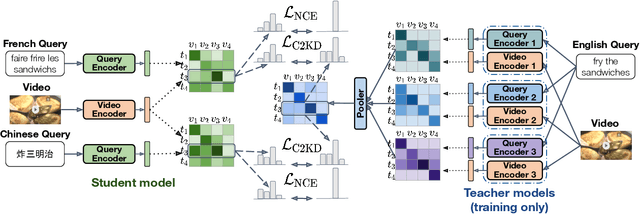
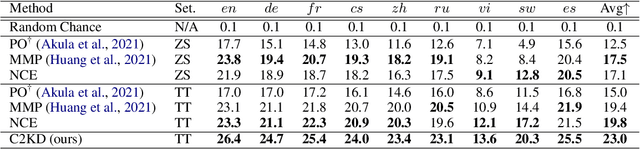

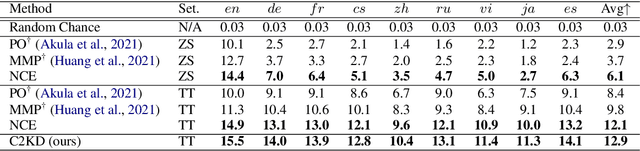
Multilingual text-video retrieval methods have improved significantly in recent years, but the performance for other languages lags behind English. We propose a Cross-Lingual Cross-Modal Knowledge Distillation method to improve multilingual text-video retrieval. Inspired by the fact that English text-video retrieval outperforms other languages, we train a student model using input text in different languages to match the cross-modal predictions from teacher models using input text in English. We propose a cross entropy based objective which forces the distribution over the student's text-video similarity scores to be similar to those of the teacher models. We introduce a new multilingual video dataset, Multi-YouCook2, by translating the English captions in the YouCook2 video dataset to 8 other languages. Our method improves multilingual text-video retrieval performance on Multi-YouCook2 and several other datasets such as Multi-MSRVTT and VATEX. We also conducted an analysis on the effectiveness of different multilingual text models as teachers.
VQ-T: RNN Transducers using Vector-Quantized Prediction Network States
Aug 03, 2022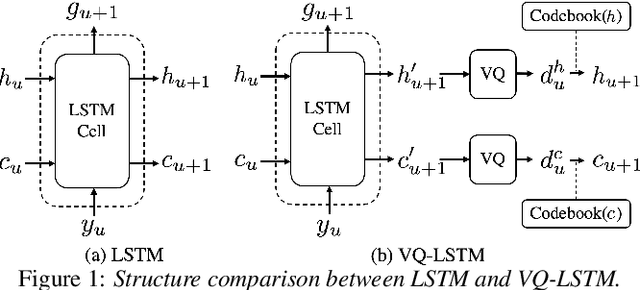
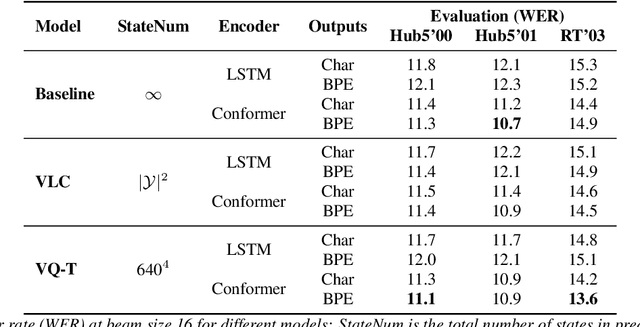

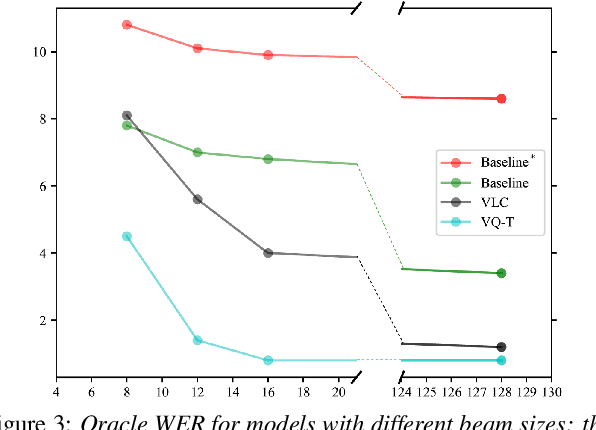
Beam search, which is the dominant ASR decoding algorithm for end-to-end models, generates tree-structured hypotheses. However, recent studies have shown that decoding with hypothesis merging can achieve a more efficient search with comparable or better performance. But, the full context in recurrent networks is not compatible with hypothesis merging. We propose to use vector-quantized long short-term memory units (VQ-LSTM) in the prediction network of RNN transducers. By training the discrete representation jointly with the ASR network, hypotheses can be actively merged for lattice generation. Our experiments on the Switchboard corpus show that the proposed VQ RNN transducers improve ASR performance over transducers with regular prediction networks while also producing denser lattices with a very low oracle word error rate (WER) for the same beam size. Additional language model rescoring experiments also demonstrate the effectiveness of the proposed lattice generation scheme.
Accelerating Inference and Language Model Fusion of Recurrent Neural Network Transducers via End-to-End 4-bit Quantization
Jun 16, 2022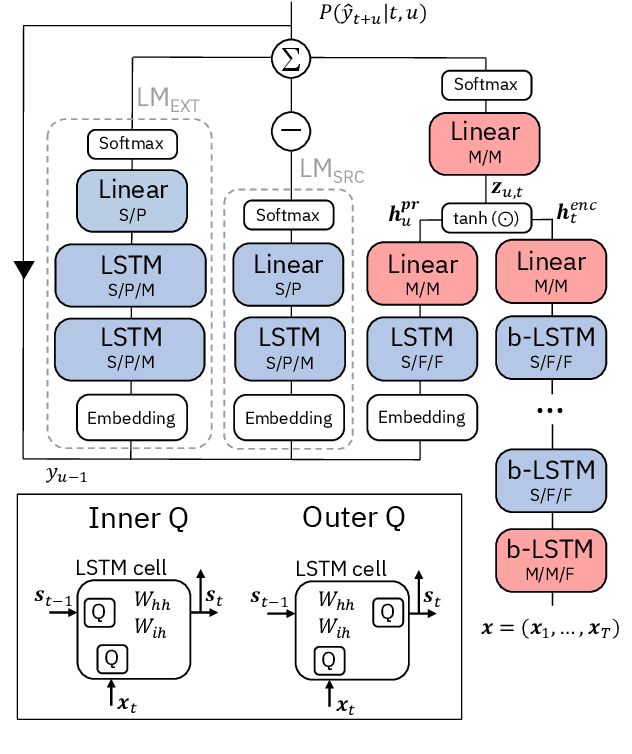
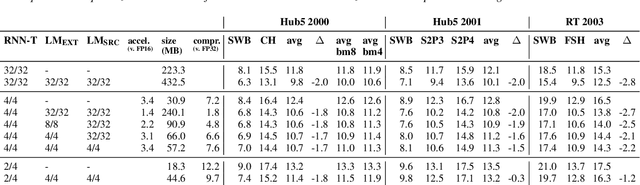
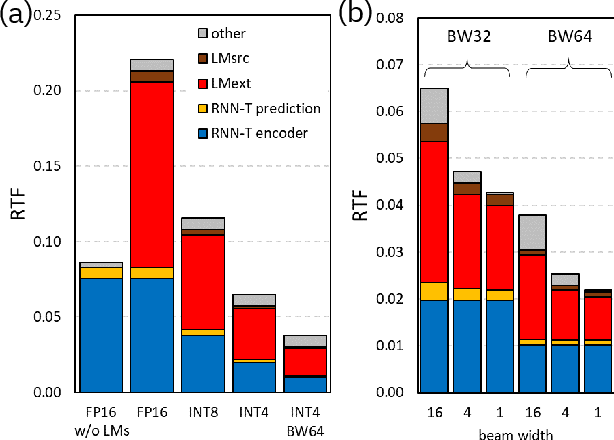
We report on aggressive quantization strategies that greatly accelerate inference of Recurrent Neural Network Transducers (RNN-T). We use a 4 bit integer representation for both weights and activations and apply Quantization Aware Training (QAT) to retrain the full model (acoustic encoder and language model) and achieve near-iso-accuracy. We show that customized quantization schemes that are tailored to the local properties of the network are essential to achieve good performance while limiting the computational overhead of QAT. Density ratio Language Model fusion has shown remarkable accuracy gains on RNN-T workloads but it severely increases the computational cost of inference. We show that our quantization strategies enable using large beam widths for hypothesis search while achieving streaming-compatible runtimes and a full model compression ratio of 7.6$\times$ compared to the full precision model. Via hardware simulations, we estimate a 3.4$\times$ acceleration from FP16 to INT4 for the end-to-end quantized RNN-T inclusive of LM fusion, resulting in a Real Time Factor (RTF) of 0.06. On the NIST Hub5 2000, Hub5 2001, and RT-03 test sets, we retain most of the gains associated with LM fusion, improving the average WER by $>$1.5%.
Tokenwise Contrastive Pretraining for Finer Speech-to-BERT Alignment in End-to-End Speech-to-Intent Systems
Apr 11, 2022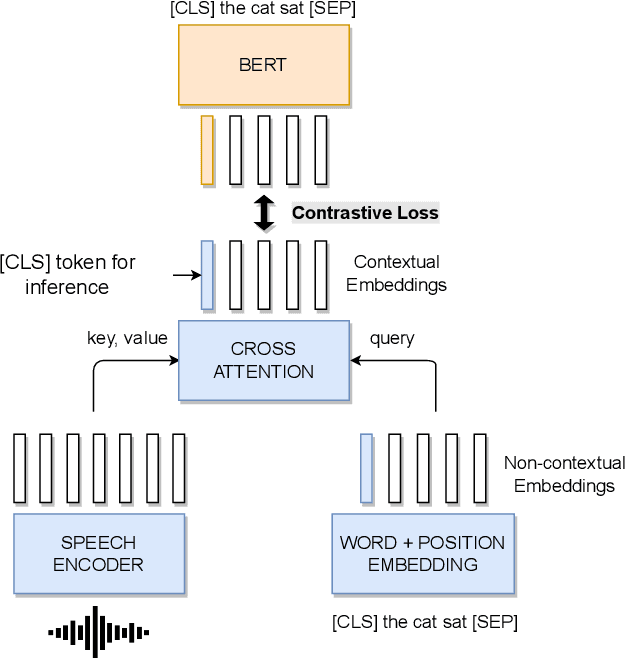
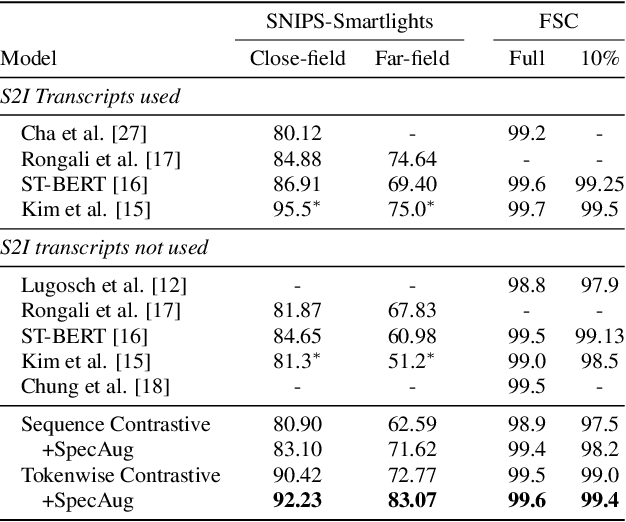
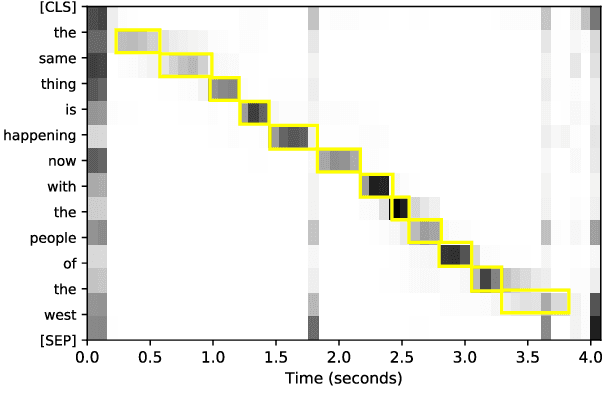
Recent advances in End-to-End (E2E) Spoken Language Understanding (SLU) have been primarily due to effective pretraining of speech representations. One such pretraining paradigm is the distillation of semantic knowledge from state-of-the-art text-based models like BERT to speech encoder neural networks. This work is a step towards doing the same in a much more efficient and fine-grained manner where we align speech embeddings and BERT embeddings on a token-by-token basis. We introduce a simple yet novel technique that uses a cross-modal attention mechanism to extract token-level contextual embeddings from a speech encoder such that these can be directly compared and aligned with BERT based contextual embeddings. This alignment is performed using a novel tokenwise contrastive loss. Fine-tuning such a pretrained model to perform intent recognition using speech directly yields state-of-the-art performance on two widely used SLU datasets. Our model improves further when fine-tuned with additional regularization using SpecAugment especially when speech is noisy, giving an absolute improvement as high as 8% over previous results.
Towards End-to-End Integration of Dialog History for Improved Spoken Language Understanding
Apr 11, 2022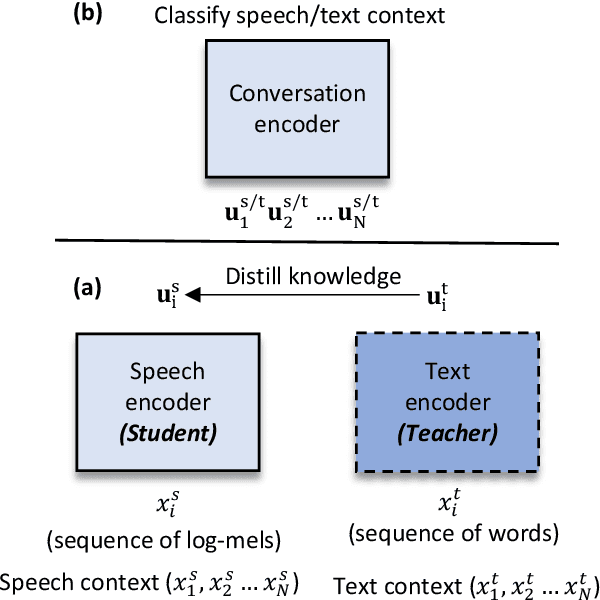
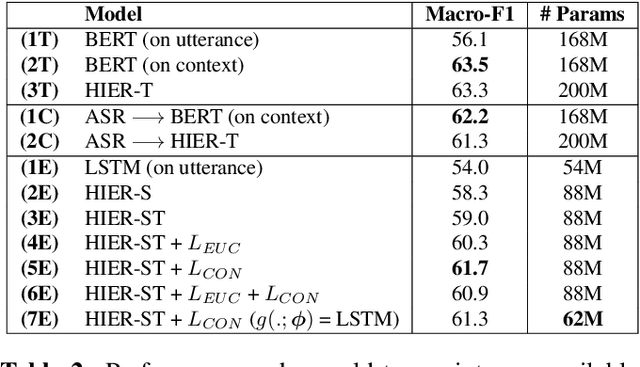

Dialog history plays an important role in spoken language understanding (SLU) performance in a dialog system. For end-to-end (E2E) SLU, previous work has used dialog history in text form, which makes the model dependent on a cascaded automatic speech recognizer (ASR). This rescinds the benefits of an E2E system which is intended to be compact and robust to ASR errors. In this paper, we propose a hierarchical conversation model that is capable of directly using dialog history in speech form, making it fully E2E. We also distill semantic knowledge from the available gold conversation transcripts by jointly training a similar text-based conversation model with an explicit tying of acoustic and semantic embeddings. We also propose a novel technique that we call DropFrame to deal with the long training time incurred by adding dialog history in an E2E manner. On the HarperValleyBank dialog dataset, our E2E history integration outperforms a history independent baseline by 7.7% absolute F1 score on the task of dialog action recognition. Our model performs competitively with the state-of-the-art history based cascaded baseline, but uses 48% fewer parameters. In the absence of gold transcripts to fine-tune an ASR model, our model outperforms this baseline by a significant margin of 10% absolute F1 score.
Improving Generalization of Deep Neural Network Acoustic Models with Length Perturbation and N-best Based Label Smoothing
Mar 29, 2022
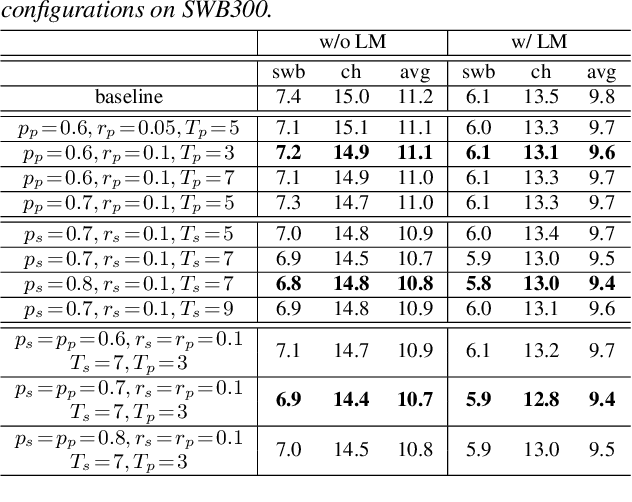
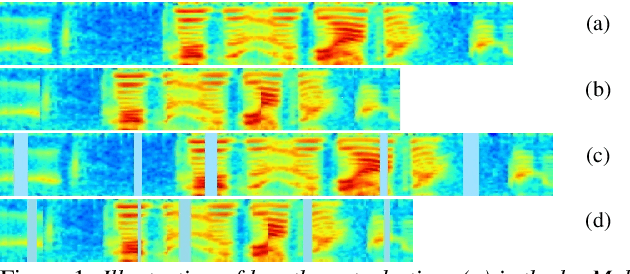

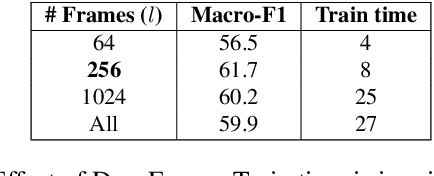
We introduce two techniques, length perturbation and n-best based label smoothing, to improve generalization of deep neural network (DNN) acoustic models for automatic speech recognition (ASR). Length perturbation is a data augmentation algorithm that randomly drops and inserts frames of an utterance to alter the length of the speech feature sequence. N-best based label smoothing randomly injects noise to ground truth labels during training in order to avoid overfitting, where the noisy labels are generated from n-best hypotheses. We evaluate these two techniques extensively on the 300-hour Switchboard (SWB300) dataset and an in-house 500-hour Japanese (JPN500) dataset using recurrent neural network transducer (RNNT) acoustic models for ASR. We show that both techniques improve the generalization of RNNT models individually and they can also be complementary. In particular, they yield good improvements over a strong SWB300 baseline and give state-of-art performance on SWB300 using RNNT models.
Towards Reducing the Need for Speech Training Data To Build Spoken Language Understanding Systems
Feb 26, 2022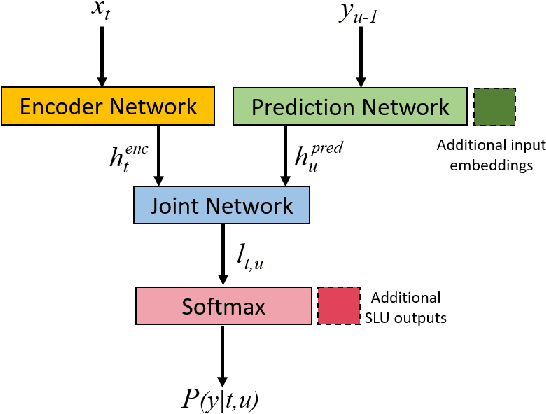
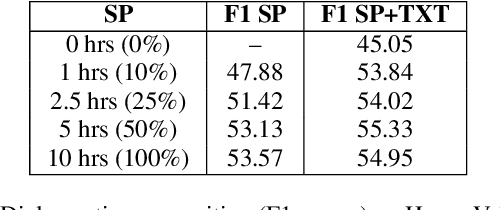
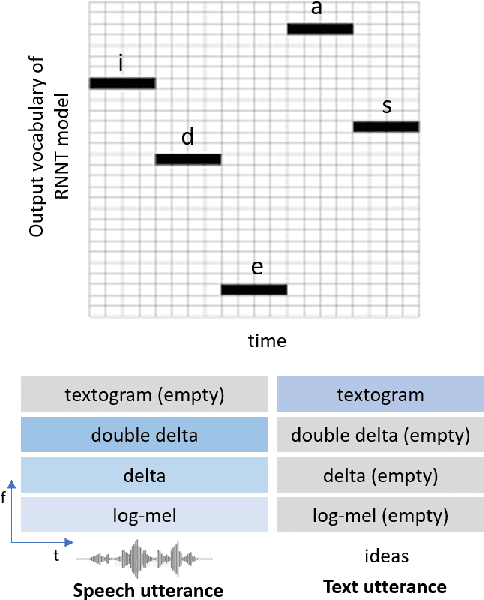
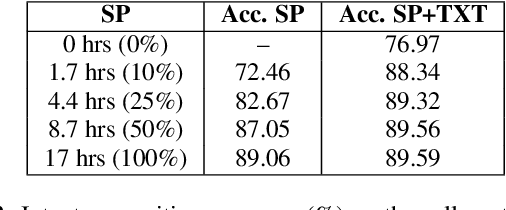
The lack of speech data annotated with labels required for spoken language understanding (SLU) is often a major hurdle in building end-to-end (E2E) systems that can directly process speech inputs. In contrast, large amounts of text data with suitable labels are usually available. In this paper, we propose a novel text representation and training methodology that allows E2E SLU systems to be effectively constructed using these text resources. With very limited amounts of additional speech, we show that these models can be further improved to perform at levels close to similar systems built on the full speech datasets. The efficacy of our proposed approach is demonstrated on both intent and entity tasks using three different SLU datasets. With text-only training, the proposed system achieves up to 90% of the performance possible with full speech training. With just an additional 10% of speech data, these models significantly improve further to 97% of full performance.
Integrating Text Inputs For Training and Adapting RNN Transducer ASR Models
Feb 26, 2022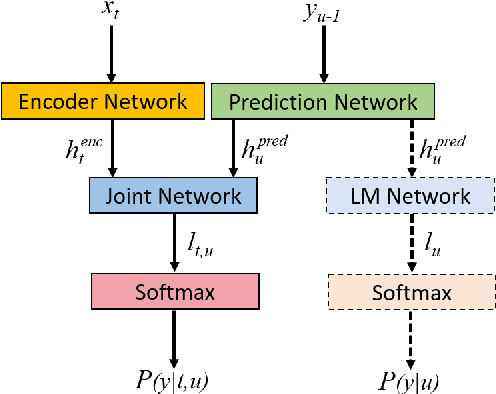
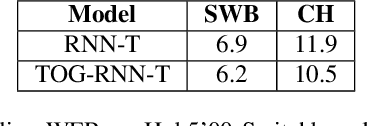
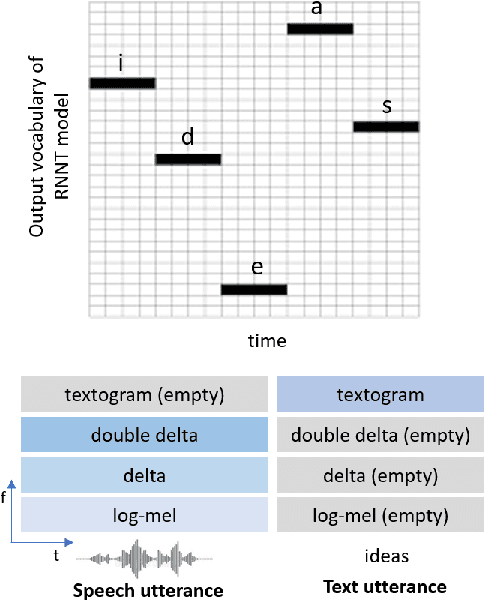
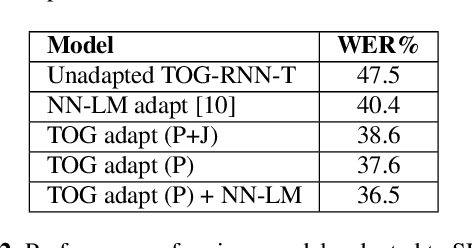
Compared to hybrid automatic speech recognition (ASR) systems that use a modular architecture in which each component can be independently adapted to a new domain, recent end-to-end (E2E) ASR system are harder to customize due to their all-neural monolithic construction. In this paper, we propose a novel text representation and training framework for E2E ASR models. With this approach, we show that a trained RNN Transducer (RNN-T) model's internal LM component can be effectively adapted with text-only data. An RNN-T model trained using both speech and text inputs improves over a baseline model trained on just speech with close to 13% word error rate (WER) reduction on the Switchboard and CallHome test sets of the NIST Hub5 2000 evaluation. The usefulness of the proposed approach is further demonstrated by customizing this general purpose RNN-T model to three separate datasets. We observe 20-45% relative word error rate (WER) reduction in these settings with this novel LM style customization technique using only unpaired text data from the new domains.