 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to EdgeLearning to Reason in LLMs by Expectation Maximization
Dec 23, 2025



Large language models (LLMs) solve reasoning problems by first generating a rationale and then answering. We formalize reasoning as a latent variable model and derive an expectation-maximization (EM) objective for learning to reason. This view connects EM and modern reward-based optimization, and shows that the main challenge lies in designing a sampling distribution that generates rationales that justify correct answers. We instantiate and compare several sampling schemes: rejection sampling with a budget, self-taught reasoner (STaR), and prompt posterior sampling (PPS), which only keeps the rationalization stage of STaR. Our experiments on the ARC, MMLU, and OpenBookQA datasets with the Llama and Qwen models show that the sampling scheme can significantly affect the accuracy of learned reasoning models. Despite its simplicity, we observe that PPS outperforms the other sampling schemes.
Learning to Clarify by Reinforcement Learning Through Reward-Weighted Fine-Tuning
Jun 08, 2025



Question answering (QA) agents automatically answer questions posed in natural language. In this work, we learn to ask clarifying questions in QA agents. The key idea in our method is to simulate conversations that contain clarifying questions and learn from them using reinforcement learning (RL). To make RL practical, we propose and analyze offline RL objectives that can be viewed as reward-weighted supervised fine-tuning (SFT) and easily optimized in large language models. Our work stands in a stark contrast to recently proposed methods, based on SFT and direct preference optimization, which have additional hyper-parameters and do not directly optimize rewards. We compare to these methods empirically and report gains in both optimized rewards and language quality.
LaMP-Cap: Personalized Figure Caption Generation With Multimodal Figure Profiles
Jun 06, 2025Figure captions are crucial for helping readers understand and remember a figure's key message. Many models have been developed to generate these captions, helping authors compose better quality captions more easily. Yet, authors almost always need to revise generic AI-generated captions to match their writing style and the domain's style, highlighting the need for personalization. Despite language models' personalization (LaMP) advances, these technologies often focus on text-only settings and rarely address scenarios where both inputs and profiles are multimodal. This paper introduces LaMP-Cap, a dataset for personalized figure caption generation with multimodal figure profiles. For each target figure, LaMP-Cap provides not only the needed inputs, such as figure images, but also up to three other figures from the same document--each with its image, caption, and figure-mentioning paragraphs--as a profile to characterize the context. Experiments with four LLMs show that using profile information consistently helps generate captions closer to the original author-written ones. Ablation studies reveal that images in the profile are more helpful than figure-mentioning paragraphs, highlighting the advantage of using multimodal profiles over text-only ones.
A Personalized Conversational Benchmark: Towards Simulating Personalized Conversations
May 20, 2025
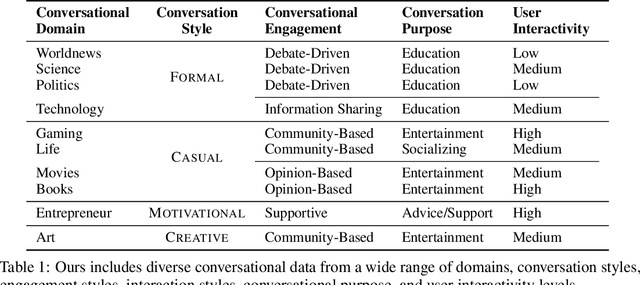


We present PersonaConvBench, a large-scale benchmark for evaluating personalized reasoning and generation in multi-turn conversations with large language models (LLMs). Unlike existing work that focuses on either personalization or conversational structure in isolation, PersonaConvBench integrates both, offering three core tasks: sentence classification, impact regression, and user-centric text generation across ten diverse Reddit-based domains. This design enables systematic analysis of how personalized conversational context shapes LLM outputs in realistic multi-user scenarios. We benchmark several commercial and open-source LLMs under a unified prompting setup and observe that incorporating personalized history yields substantial performance improvements, including a 198 percent relative gain over the best non-conversational baseline in sentiment classification. By releasing PersonaConvBench with evaluations and code, we aim to support research on LLMs that adapt to individual styles, track long-term context, and produce contextually rich, engaging responses.
FisherSFT: Data-Efficient Supervised Fine-Tuning of Language Models Using Information Gain
May 20, 2025Supervised fine-tuning (SFT) is a standard approach to adapting large language models (LLMs) to new domains. In this work, we improve the statistical efficiency of SFT by selecting an informative subset of training examples. Specifically, for a fixed budget of training examples, which determines the computational cost of fine-tuning, we determine the most informative ones. The key idea in our method is to select examples that maximize information gain, measured by the Hessian of the log-likelihood of the LLM. We approximate it efficiently by linearizing the LLM at the last layer using multinomial logistic regression models. Our approach is computationally efficient, analyzable, and performs well empirically. We demonstrate this on several problems, and back our claims with both quantitative results and an LLM evaluation.
RecGaze: The First Eye Tracking and User Interaction Dataset for Carousel Interfaces
Apr 29, 2025Carousel interfaces are widely used in e-commerce and streaming services, but little research has been devoted to them. Previous studies of interfaces for presenting search and recommendation results have focused on single ranked lists, but it appears their results cannot be extrapolated to carousels due to the added complexity. Eye tracking is a highly informative approach to understanding how users click, yet there are no eye tracking studies concerning carousels. There are very few interaction datasets on recommenders with carousel interfaces and none that contain gaze data. We introduce the RecGaze dataset: the first comprehensive feedback dataset on carousels that includes eye tracking results, clicks, cursor movements, and selection explanations. The dataset comprises of interactions from 3 movie selection tasks with 40 different carousel interfaces per user. In total, 87 users and 3,477 interactions are logged. In addition to the dataset, its description and possible use cases, we provide results of a survey on carousel design and the first analysis of gaze data on carousels, which reveals a golden triangle or F-pattern browsing behavior. Our work seeks to advance the field of carousel interfaces by providing the first dataset with eye tracking results on carousels. In this manner, we provide and encourage an empirical understanding of interactions with carousel interfaces, for building better recommender systems through gaze information, and also encourage the development of gaze-based recommenders.
Towards Agentic Recommender Systems in the Era of Multimodal Large Language Models
Mar 20, 2025Recent breakthroughs in Large Language Models (LLMs) have led to the emergence of agentic AI systems that extend beyond the capabilities of standalone models. By empowering LLMs to perceive external environments, integrate multimodal information, and interact with various tools, these agentic systems exhibit greater autonomy and adaptability across complex tasks. This evolution brings new opportunities to recommender systems (RS): LLM-based Agentic RS (LLM-ARS) can offer more interactive, context-aware, and proactive recommendations, potentially reshaping the user experience and broadening the application scope of RS. Despite promising early results, fundamental challenges remain, including how to effectively incorporate external knowledge, balance autonomy with controllability, and evaluate performance in dynamic, multimodal settings. In this perspective paper, we first present a systematic analysis of LLM-ARS: (1) clarifying core concepts and architectures; (2) highlighting how agentic capabilities -- such as planning, memory, and multimodal reasoning -- can enhance recommendation quality; and (3) outlining key research questions in areas such as safety, efficiency, and lifelong personalization. We also discuss open problems and future directions, arguing that LLM-ARS will drive the next wave of RS innovation. Ultimately, we foresee a paradigm shift toward intelligent, autonomous, and collaborative recommendation experiences that more closely align with users' evolving needs and complex decision-making processes.
An Efficient Plugin Method for Metric Optimization of Black-Box Models
Mar 03, 2025Many machine learning algorithms and classifiers are available only via API queries as a ``black-box'' -- that is, the downstream user has no ability to change, re-train, or fine-tune the model on a particular target distribution. Indeed, the downstream user may not even have knowledge of the \emph{original} training distribution or performance metric used to construct and optimize the black-box model. We propose a simple and efficient method, Plugin, which \emph{post-processes} arbitrary multiclass predictions from any black-box classifier in order to simultaneously (1) adapt these predictions to a target distribution; and (2) optimize a particular metric of the confusion matrix. Importantly, Plugin is a completely \textit{post-hoc} method which does not rely on feature information, only requires a small amount of probabilistic predictions along with their corresponding true label, and optimizes metrics by querying. We empirically demonstrate that Plugin is both broadly applicable and has performance competitive with related methods on a variety of tabular and language tasks.
Active Learning for Direct Preference Optimization
Mar 03, 2025Direct preference optimization (DPO) is a form of reinforcement learning from human feedback (RLHF) where the policy is learned directly from preferential feedback. Although many models of human preferences exist, the critical task of selecting the most informative feedback for training them is under-explored. We propose an active learning framework for DPO, which can be applied to collect human feedback online or to choose the most informative subset of already collected feedback offline. We propose efficient algorithms for both settings. The key idea is to linearize the DPO objective at the last layer of the neural network representation of the optimized policy and then compute the D-optimal design to collect preferential feedback. We prove that the errors in our DPO logit estimates diminish with more feedback. We show the effectiveness of our algorithms empirically in the setting that matches our theory and also on large language models.
From Selection to Generation: A Survey of LLM-based Active Learning
Feb 17, 2025Active Learning (AL) has been a powerful paradigm for improving model efficiency and performance by selecting the most informative data points for labeling and training. In recent active learning frameworks, Large Language Models (LLMs) have been employed not only for selection but also for generating entirely new data instances and providing more cost-effective annotations. Motivated by the increasing importance of high-quality data and efficient model training in the era of LLMs, we present a comprehensive survey on LLM-based Active Learning. We introduce an intuitive taxonomy that categorizes these techniques and discuss the transformative roles LLMs can play in the active learning loop. We further examine the impact of AL on LLM learning paradigms and its applications across various domains. Finally, we identify open challenges and propose future research directions. This survey aims to serve as an up-to-date resource for researchers and practitioners seeking to gain an intuitive understanding of LLM-based AL techniques and deploy them to new applications.