 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to EdgeConstructing Self-motivated Pyramid Curriculums for Cross-Domain Semantic Segmentation: A Non-Adversarial Approach
Aug 26, 2019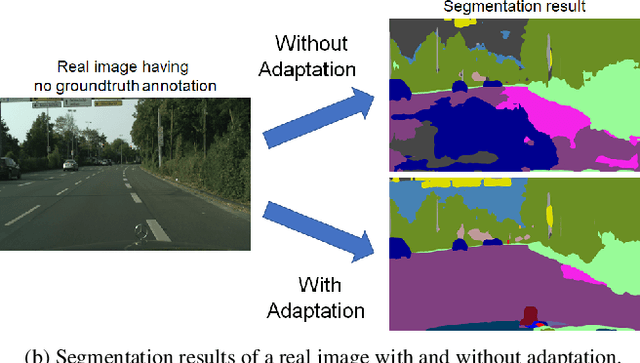
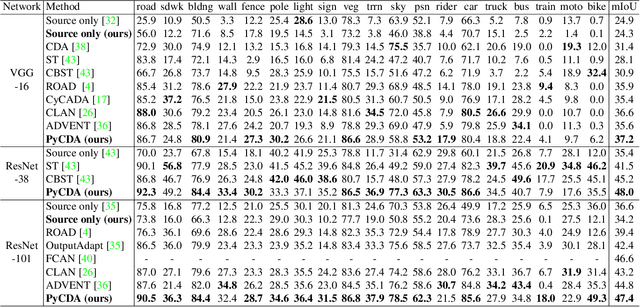

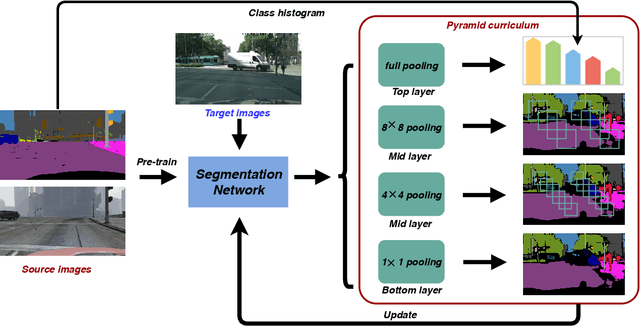
We propose a new approach, called self-motivated pyramid curriculum domain adaptation (PyCDA), to facilitate the adaptation of semantic segmentation neural networks from synthetic source domains to real target domains. Our approach draws on an insight connecting two existing works: curriculum domain adaptation and self-training. Inspired by the former, PyCDA constructs a pyramid curriculum which contains various properties about the target domain. Those properties are mainly about the desired label distributions over the target domain images, image regions, and pixels. By enforcing the segmentation neural network to observe those properties, we can improve the network's generalization capability to the target domain. Motivated by the self-training, we infer this pyramid of properties by resorting to the semantic segmentation network itself. Unlike prior work, we do not need to maintain any additional models (e.g., logistic regression or discriminator networks) or to solve minmax problems which are often difficult to optimize. We report state-of-the-art results for the adaptation from both GTAV and SYNTHIA to Cityscapes, two popular settings in unsupervised domain adaptation for semantic segmentation.
A Fast and Accurate One-Stage Approach to Visual Grounding
Aug 18, 2019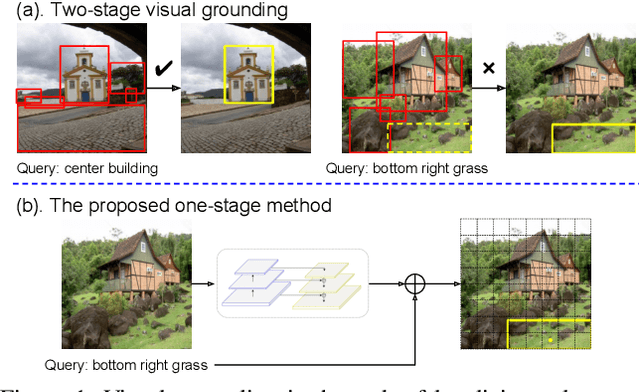
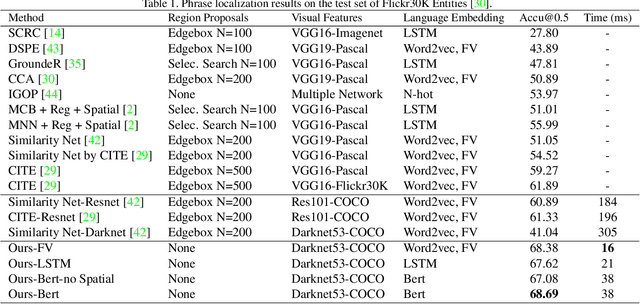
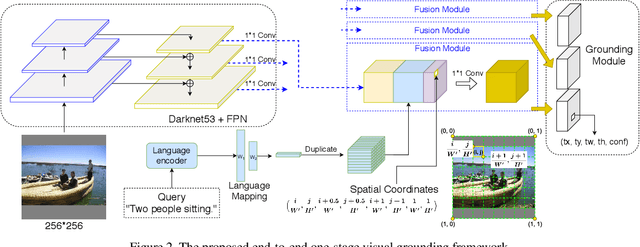

We propose a simple, fast, and accurate one-stage approach to visual grounding, inspired by the following insight. The performances of existing propose-and-rank two-stage methods are capped by the quality of the region candidates they propose in the first stage --- if none of the candidates could cover the ground truth region, there is no hope in the second stage to rank the right region to the top. To avoid this caveat, we propose a one-stage model that enables end-to-end joint optimization. The main idea is as straightforward as fusing a text query's embedding into the YOLOv3 object detector, augmented by spatial features so as to account for spatial mentions in the query. Despite being simple, this one-stage approach shows great potential in terms of both accuracy and speed for both phrase localization and referring expression comprehension, according to our experiments. Given these results along with careful investigations into some popular region proposals, we advocate for visual grounding a paradigm shift from the conventional two-stage methods to the one-stage framework.
Defending Against Adversarial Attacks Using Random Forests
Jun 16, 2019



As deep neural networks (DNNs) have become increasingly important and popular, the robustness of DNNs is the key to the safety of both the Internet and the physical world. Unfortunately, some recent studies show that adversarial examples, which are hard to be distinguished from real examples, can easily fool DNNs and manipulate their predictions. Upon observing that adversarial examples are mostly generated by gradient-based methods, in this paper, we first propose to use a simple yet very effective non-differentiable hybrid model that combines DNNs and random forests, rather than hide gradients from attackers, to defend against the attacks. Our experiments show that our model can successfully and completely defend the white-box attacks, has a lower transferability, and is quite resistant to three representative types of black-box attacks; while at the same time, our model achieves similar classification accuracy as the original DNNs. Finally, we investigate and suggest a criterion to define where to grow random forests in DNNs.
NATTACK: Learning the Distributions of Adversarial Examples for an Improved Black-Box Attack on Deep Neural Networks
May 13, 2019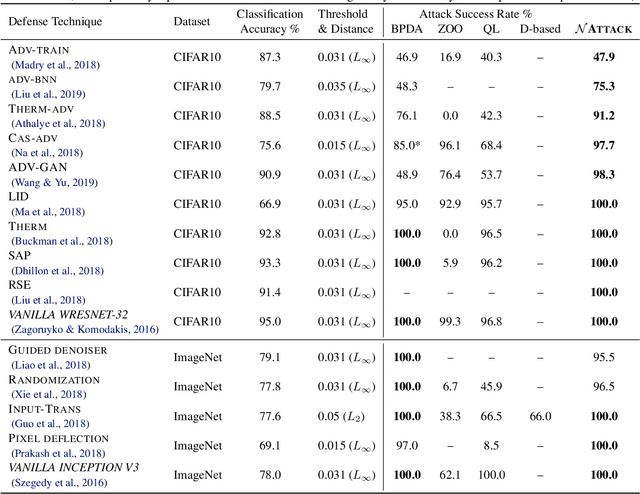
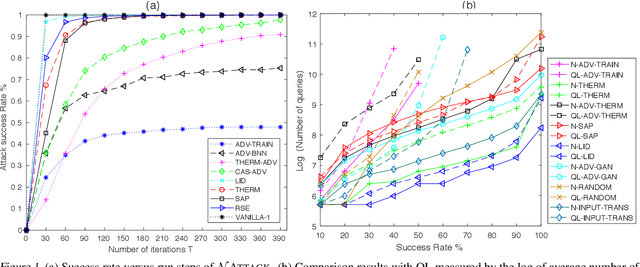
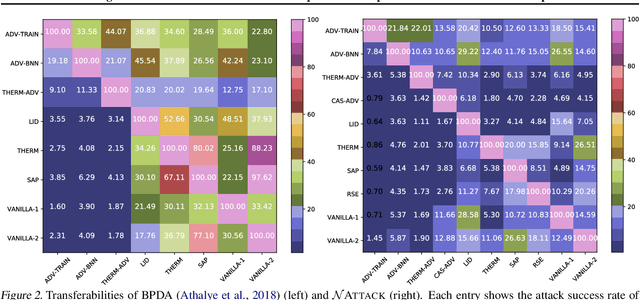
Powerful adversarial attack methods are vital for understanding how to construct robust deep neural networks (DNNs) and for thoroughly testing defense techniques. In this paper, we propose a black-box adversarial attack algorithm that can defeat both vanilla DNNs and those generated by various defense techniques developed recently. Instead of searching for an "optimal" adversarial example for a benign input to a targeted DNN, our algorithm finds a probability density distribution over a small region centered around the input, such that a sample drawn from this distribution is likely an adversarial example, without the need of accessing the DNN's internal layers or weights. Our approach is universal as it can successfully attack different neural networks by a single algorithm. It is also strong; according to the testing against 2 vanilla DNNs and 13 defended ones, it outperforms state-of-the-art black-box or white-box attack methods for most test cases. Additionally, our results reveal that adversarial training remains one of the best defense techniques, and the adversarial examples are not as transferable across defended DNNs as them across vanilla DNNs.
Large-Scale Long-Tailed Recognition in an Open World
Apr 16, 2019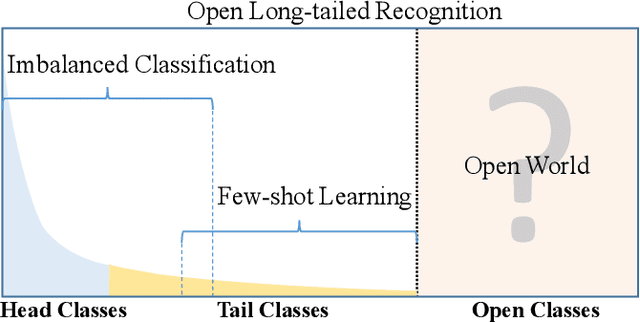

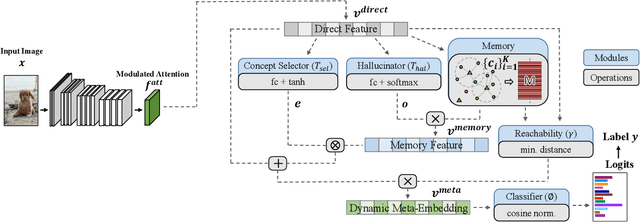
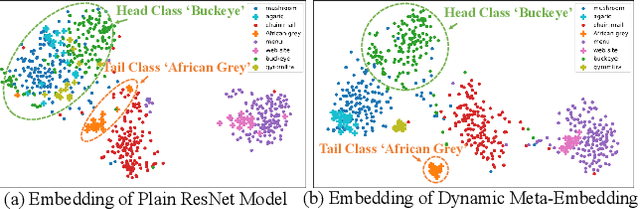
Real world data often have a long-tailed and open-ended distribution. A practical recognition system must classify among majority and minority classes, generalize from a few known instances, and acknowledge novelty upon a never seen instance. We define Open Long-Tailed Recognition (OLTR) as learning from such naturally distributed data and optimizing the classification accuracy over a balanced test set which include head, tail, and open classes. OLTR must handle imbalanced classification, few-shot learning, and open-set recognition in one integrated algorithm, whereas existing classification approaches focus only on one aspect and deliver poorly over the entire class spectrum. The key challenges are how to share visual knowledge between head and tail classes and how to reduce confusion between tail and open classes. We develop an integrated OLTR algorithm that maps an image to a feature space such that visual concepts can easily relate to each other based on a learned metric that respects the closed-world classification while acknowledging the novelty of the open world. Our so-called dynamic meta-embedding combines a direct image feature and an associated memory feature, with the feature norm indicating the familiarity to known classes. On three large-scale OLTR datasets we curate from object-centric ImageNet, scene-centric Places, and face-centric MS1M data, our method consistently outperforms the state-of-the-art. Our code, datasets, and models enable future OLTR research and are publicly available at https://liuziwei7.github.io/projects/LongTail.html.
Synthesized Policies for Transfer and Adaptation across Tasks and Environments
Apr 05, 2019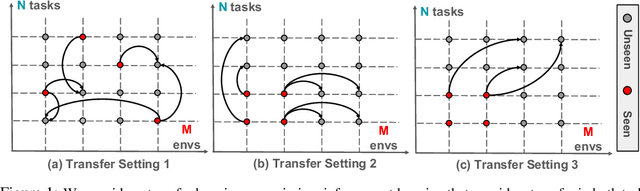

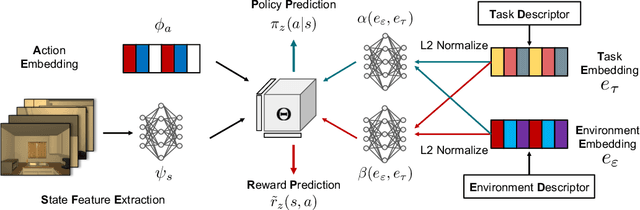

The ability to transfer in reinforcement learning is key towards building an agent of general artificial intelligence. In this paper, we consider the problem of learning to simultaneously transfer across both environments (ENV) and tasks (TASK), probably more importantly, by learning from only sparse (ENV, TASK) pairs out of all the possible combinations. We propose a novel compositional neural network architecture which depicts a meta rule for composing policies from the environment and task embeddings. Notably, one of the main challenges is to learn the embeddings jointly with the meta rule. We further propose new training methods to disentangle the embeddings, making them both distinctive signatures of the environments and tasks and effective building blocks for composing the policies. Experiments on GridWorld and Thor, of which the agent takes as input an egocentric view, show that our approach gives rise to high success rates on all the (ENV, TASK) pairs after learning from only 40\% of them.
Joint Modeling of Dense and Incomplete Trajectories for Citywide Traffic Volume Inference
Feb 25, 2019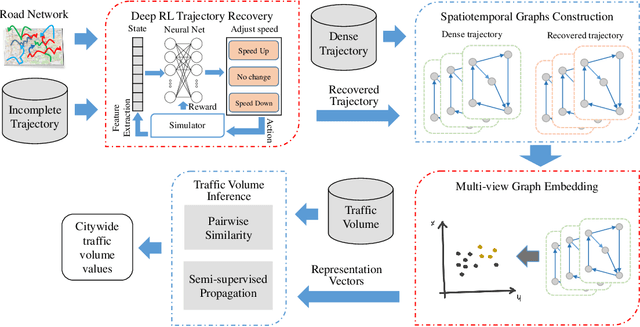

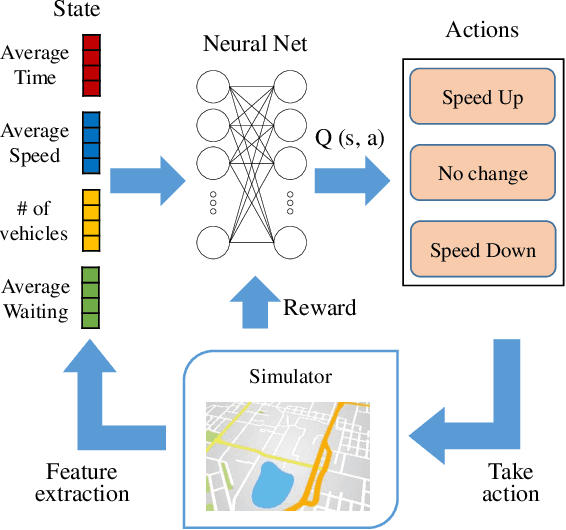
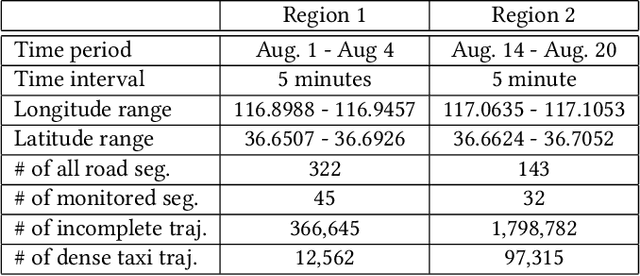
Real-time traffic volume inference is key to an intelligent city. It is a challenging task because accurate traffic volumes on the roads can only be measured at certain locations where sensors are installed. Moreover, the traffic evolves over time due to the influences of weather, events, holidays, etc. Existing solutions to the traffic volume inference problem often rely on dense GPS trajectories, which inevitably fail to account for the vehicles which carry no GPS devices or have them turned off. Consequently, the results are biased to taxicabs because they are almost always online for GPS tracking. In this paper, we propose a novel framework for the citywide traffic volume inference using both dense GPS trajectories and incomplete trajectories captured by camera surveillance systems. Our approach employs a high-fidelity traffic simulator and deep reinforcement learning to recover full vehicle movements from the incomplete trajectories. In order to jointly model the recovered trajectories and dense GPS trajectories, we construct spatiotemporal graphs and use multi-view graph embedding to encode the multi-hop correlations between road segments into real-valued vectors. Finally, we infer the citywide traffic volumes by propagating the traffic values of monitored road segments to the unmonitored ones through masked pairwise similarities. Extensive experiments with two big regions in a provincial capital city in China verify the effectiveness of our approach.
A Curriculum Domain Adaptation Approach to the Semantic Segmentation of Urban Scenes
Jan 10, 2019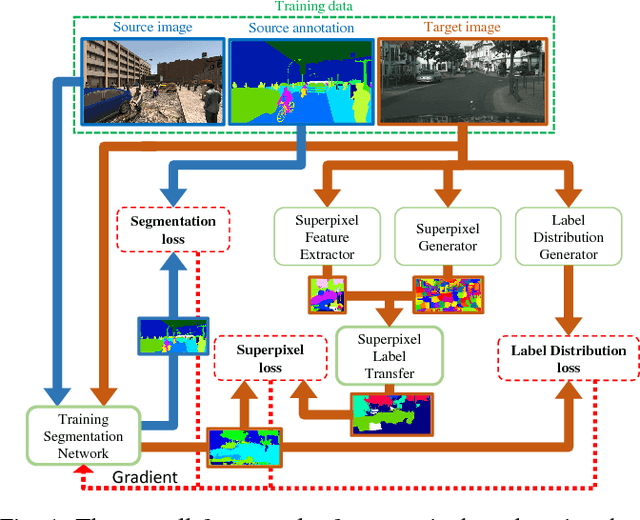


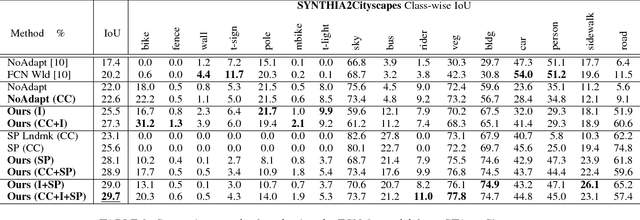
During the last half decade, convolutional neural networks (CNNs) have triumphed over semantic segmentation, which is one of the core tasks in many applications such as autonomous driving and augmented reality. However, to train CNNs requires a considerable amount of data, which is difficult to collect and laborious to annotate. Recent advances in computer graphics make it possible to train CNNs on photo-realistic synthetic imagery with computer-generated annotations. Despite this, the domain mismatch between the real images and the synthetic data hinders the models' performance. Hence, we propose a curriculum-style learning approach to minimizing the domain gap in urban scene semantic segmentation. The curriculum domain adaptation solves easy tasks first to infer necessary properties about the target domain; in particular, the first task is to learn global label distributions over images and local distributions over landmark superpixels. These are easy to estimate because images of urban scenes have strong idiosyncrasies (e.g., the size and spatial relations of buildings, streets, cars, etc.). We then train a segmentation network, while regularizing its predictions in the target domain to follow those inferred properties. In experiments, our method outperforms the baselines on two datasets and two backbone networks. We also report extensive ablation studies about our approach.
Classifier and Exemplar Synthesis for Zero-Shot Learning
Dec 16, 2018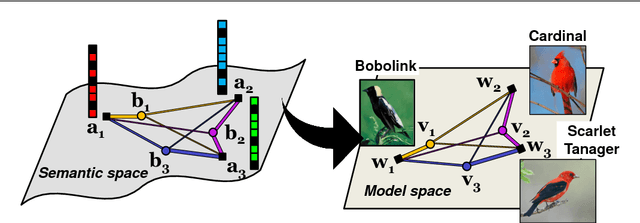
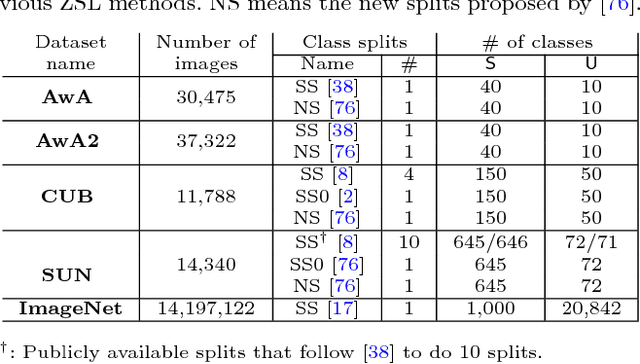
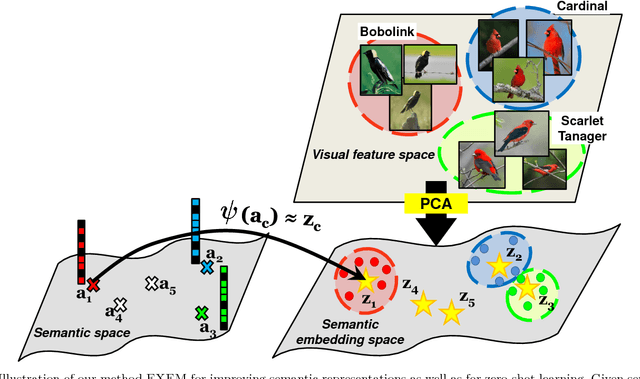
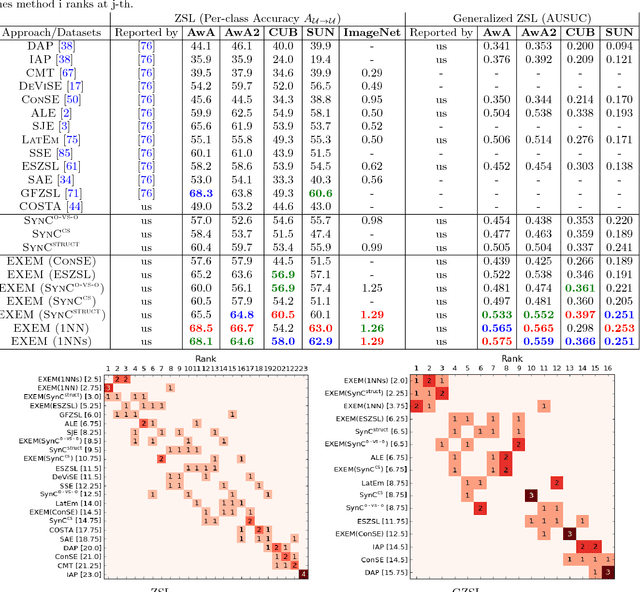
Zero-shot learning (ZSL) enables solving a task without the need to see its examples. In this paper, we propose two ZSL frameworks that learn to synthesize parameters for novel unseen classes. First, we propose to cast the problem of ZSL as learning manifold embeddings from graphs composed of object classes, leading to a flexible approach that synthesizes "classifiers" for the unseen classes. Then, we define an auxiliary task of synthesizing "exemplars" for the unseen classes to be used as an automatic denoising mechanism for any existing ZSL approaches or as an effective ZSL model by itself. On five visual recognition benchmark datasets, we demonstrate the superior performances of our proposed frameworks in various scenarios of both conventional and generalized ZSL. Finally, we provide valuable insights through a series of empirical analyses, among which are a comparison of semantic representations on the full ImageNet benchmark as well as a comparison of metrics used in generalized ZSL. Our code and data are publicly available at https://github.com/pujols/Zero-shot-learning-journal
Improving Sequential Determinantal Point Processes for Supervised Video Summarization
Oct 24, 2018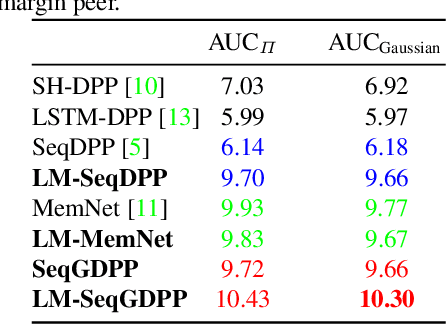
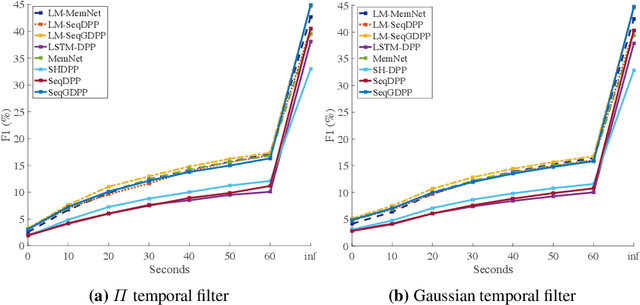
It is now much easier than ever before to produce videos. While the ubiquitous video data is a great source for information discovery and extraction, the computational challenges are unparalleled. Automatically summarizing the videos has become a substantial need for browsing, searching, and indexing visual content. This paper is in the vein of supervised video summarization using sequential determinantal point process (SeqDPP), which models diversity by a probabilistic distribution. We improve this model in two folds. In terms of learning, we propose a large-margin algorithm to address the exposure bias problem in SeqDPP. In terms of modeling, we design a new probabilistic distribution such that, when it is integrated into SeqDPP, the resulting model accepts user input about the expected length of the summary. Moreover, we also significantly extend a popular video summarization dataset by 1) more egocentric videos, 2) dense user annotations, and 3) a refined evaluation scheme. We conduct extensive experiments on this dataset (about 60 hours of videos in total) and compare our approach to several competitive baselines.