 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to EdgeVQS: Linking Segmentations to Questions and Answers for Supervised Attention in VQA and Question-Focused Semantic Segmentation
Paper and Code

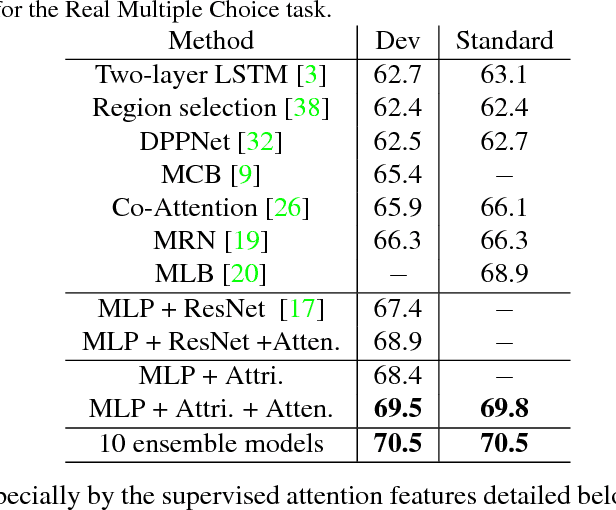

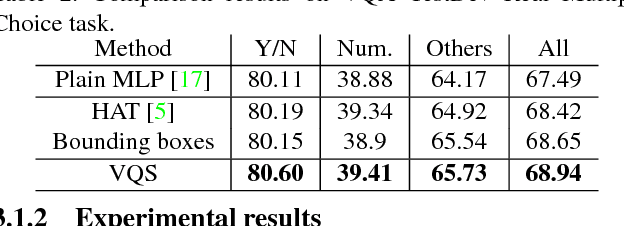
Rich and dense human labeled datasets are among the main enabling factors for the recent advance on vision-language understanding. Many seemingly distant annotations (e.g., semantic segmentation and visual question answering (VQA)) are inherently connected in that they reveal different levels and perspectives of human understandings about the same visual scenes --- and even the same set of images (e.g., of COCO). The popularity of COCO correlates those annotations and tasks. Explicitly linking them up may significantly benefit both individual tasks and the unified vision and language modeling. We present the preliminary work of linking the instance segmentations provided by COCO to the questions and answers (QAs) in the VQA dataset, and name the collected links visual questions and segmentation answers (VQS). They transfer human supervision between the previously separate tasks, offer more effective leverage to existing problems, and also open the door for new research problems and models. We study two applications of the VQS data in this paper: supervised attention for VQA and a novel question-focused semantic segmentation task. For the former, we obtain state-of-the-art results on the VQA real multiple-choice task by simply augmenting the multilayer perceptrons with some attention features that are learned using the segmentation-QA links as explicit supervision. To put the latter in perspective, we study two plausible methods and compare them to an oracle method assuming that the instance segmentations are given at the test stage.