 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to EdgeThe Sandbox Environment for Generalizable Agent Research (SEGAR)
Mar 19, 2022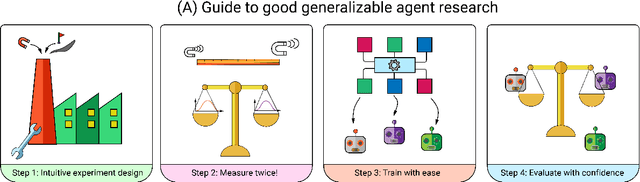
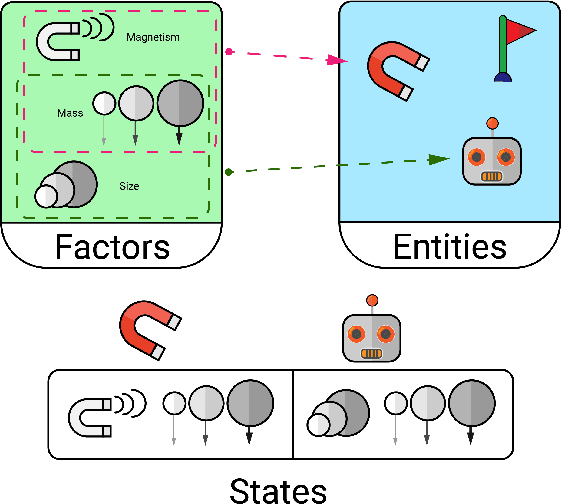
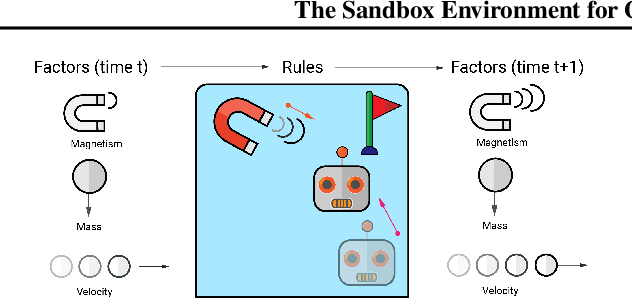
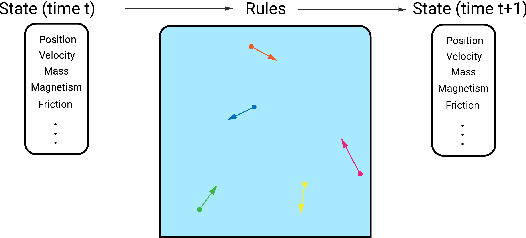
A broad challenge of research on generalization for sequential decision-making tasks in interactive environments is designing benchmarks that clearly landmark progress. While there has been notable headway, current benchmarks either do not provide suitable exposure nor intuitive control of the underlying factors, are not easy-to-implement, customizable, or extensible, or are computationally expensive to run. We built the Sandbox Environment for Generalizable Agent Research (SEGAR) with all of these things in mind. SEGAR improves the ease and accountability of generalization research in RL, as generalization objectives can be easy designed by specifying task distributions, which in turns allows the researcher to measure the nature of the generalization objective. We present an overview of SEGAR and how it contributes to these goals, as well as experiments that demonstrate a few types of research questions SEGAR can help answer.
Improving Zero-shot Generalization in Offline Reinforcement Learning using Generalized Similarity Functions
Nov 29, 2021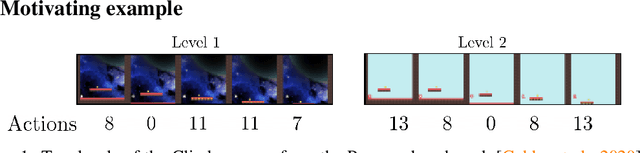

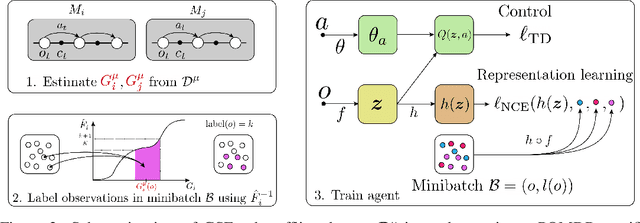
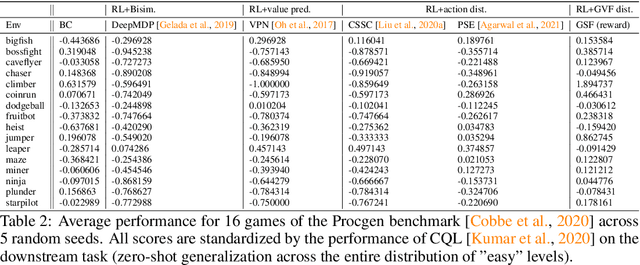
Reinforcement learning (RL) agents are widely used for solving complex sequential decision making tasks, but still exhibit difficulty in generalizing to scenarios not seen during training. While prior online approaches demonstrated that using additional signals beyond the reward function can lead to better generalization capabilities in RL agents, i.e. using self-supervised learning (SSL), they struggle in the offline RL setting, i.e. learning from a static dataset. We show that performance of online algorithms for generalization in RL can be hindered in the offline setting due to poor estimation of similarity between observations. We propose a new theoretically-motivated framework called Generalized Similarity Functions (GSF), which uses contrastive learning to train an offline RL agent to aggregate observations based on the similarity of their expected future behavior, where we quantify this similarity using \emph{generalized value functions}. We show that GSF is general enough to recover existing SSL objectives while also improving zero-shot generalization performance on a complex offline RL benchmark, offline Procgen.
Cross-Trajectory Representation Learning for Zero-Shot Generalization in RL
Jun 04, 2021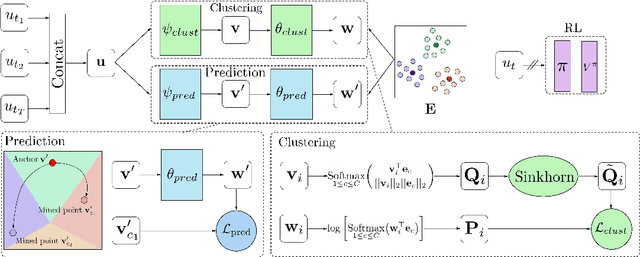
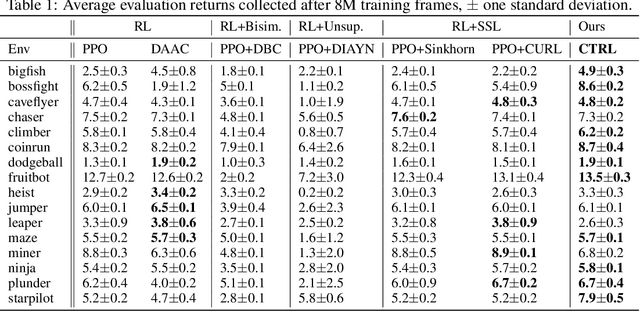
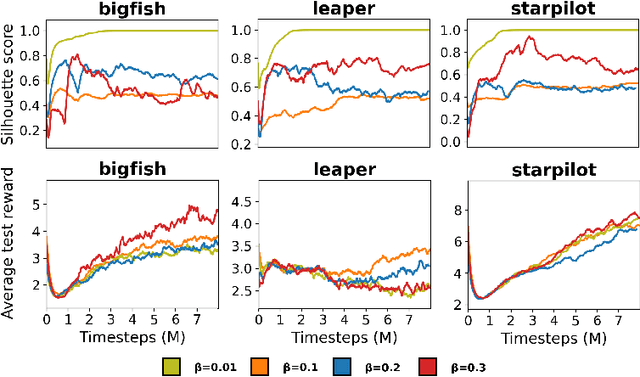

A highly desirable property of a reinforcement learning (RL) agent -- and a major difficulty for deep RL approaches -- is the ability to generalize policies learned on a few tasks over a high-dimensional observation space to similar tasks not seen during training. Many promising approaches to this challenge consider RL as a process of training two functions simultaneously: a complex nonlinear encoder that maps high-dimensional observations to a latent representation space, and a simple linear policy over this space. We posit that a superior encoder for zero-shot generalization in RL can be trained by using solely an auxiliary SSL objective if the training process encourages the encoder to map behaviorally similar observations to similar representations, as reward-based signal can cause overfitting in the encoder (Raileanu et al., 2021). We propose Cross-Trajectory Representation Learning (CTRL), a method that runs within an RL agent and conditions its encoder to recognize behavioral similarity in observations by applying a novel SSL objective to pairs of trajectories from the agent's policies. CTRL can be viewed as having the same effect as inducing a pseudo-bisimulation metric but, crucially, avoids the use of rewards and associated overfitting risks. Our experiments ablate various components of CTRL and demonstrate that in combination with PPO it achieves better generalization performance on the challenging Procgen benchmark suite (Cobbe et al., 2020).
Improving Long-Term Metrics in Recommendation Systems using Short-Horizon Offline RL
Jun 01, 2021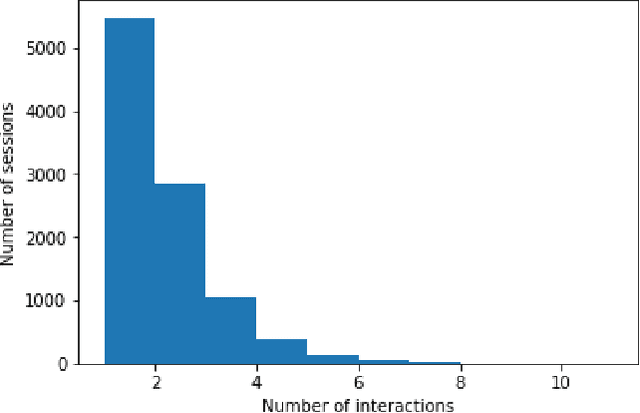

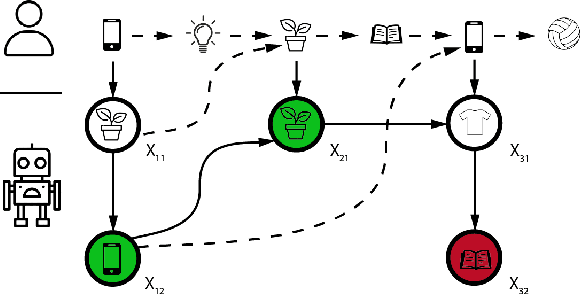

We study session-based recommendation scenarios where we want to recommend items to users during sequential interactions to improve their long-term utility. Optimizing a long-term metric is challenging because the learning signal (whether the recommendations achieved their desired goals) is delayed and confounded by other user interactions with the system. Immediately measurable proxies such as clicks can lead to suboptimal recommendations due to misalignment with the long-term metric. Many works have applied episodic reinforcement learning (RL) techniques for session-based recommendation but these methods do not account for policy-induced drift in user intent across sessions. We develop a new batch RL algorithm called Short Horizon Policy Improvement (SHPI) that approximates policy-induced distribution shifts across sessions. By varying the horizon hyper-parameter in SHPI, we recover well-known policy improvement schemes in the RL literature. Empirical results on four recommendation tasks show that SHPI can outperform matrix factorization, offline bandits, and offline RL baselines. We also provide a stable and computationally efficient implementation using weighted regression oracles.
A Theoretical Analysis of Catastrophic Forgetting through the NTK Overlap Matrix
Oct 07, 2020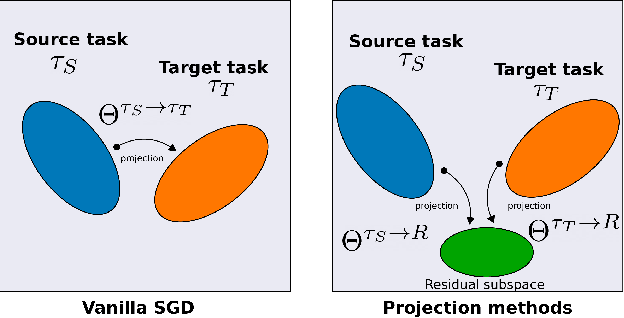
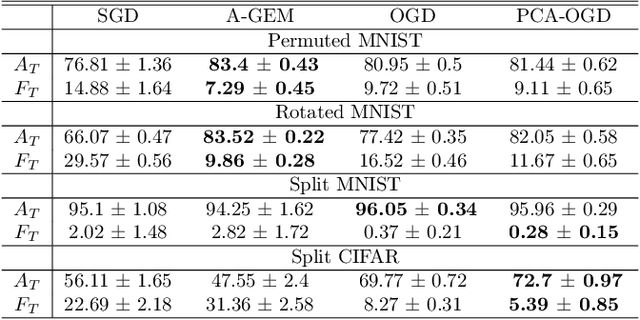
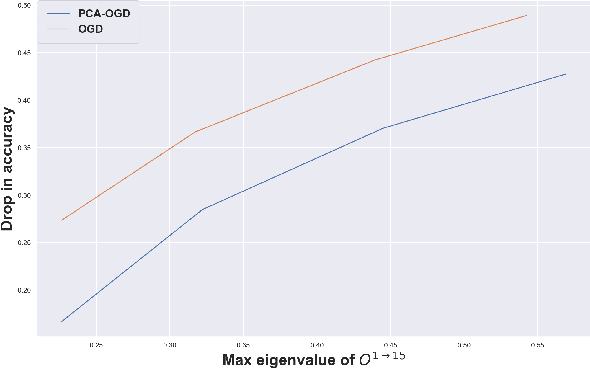

Continual learning (CL) is a setting in which an agent has to learn from an incoming stream of data during its entire lifetime. Although major advances have been made in the field, one recurring problem which remains unsolved is that of Catastrophic Forgetting (CF). While the issue has been extensively studied empirically, little attention has been paid from a theoretical angle. In this paper, we show that the impact of CF increases as two tasks increasingly align. We introduce a measure of task similarity called the NTK overlap matrix which is at the core of CF. We analyze common projected gradient algorithms and demonstrate how they mitigate forgetting. Then, we propose a variant of Orthogonal Gradient Descent (OGD) which leverages structure of the data through Principal Component Analysis (PCA). Experiments support our theoretical findings and show how our method reduces CF on classical CL datasets.
Deep Reinforcement and InfoMax Learning
Jun 12, 2020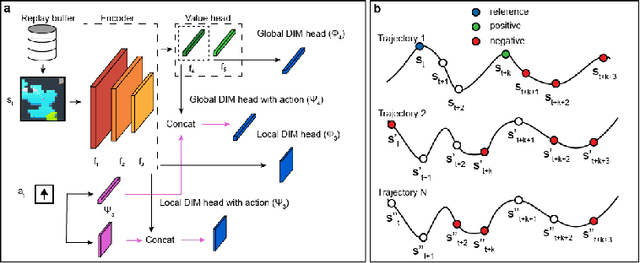
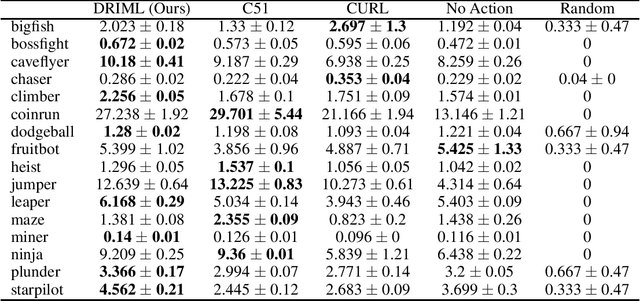

Our work is based on the hypothesis that a model-free agent whose representations are predictive of properties of future states (beyond expected rewards) will be more capable of solving and adapting to new RL problems. To test that hypothesis, we introduce an objective based on Deep InfoMax (DIM) which trains the agent to predict the future by maximizing the mutual information between its internal representation of successive timesteps. We provide an intuitive analysis of the convergence properties of our approach from the perspective of Markov chain mixing times and argue that convergence of the lower bound on mutual information is related to the inverse absolute spectral gap of the transition model. We test our approach in several synthetic settings, where it successfully learns representations that are predictive of the future. Finally, we augment C51, a strong RL baseline, with our temporal DIM objective and demonstrate improved performance on a continual learning task and on the recently introduced Procgen environment.
Provably efficient reconstruction of policy networks
Feb 07, 2020
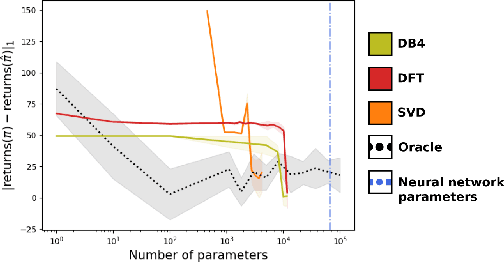
Recent research has shown that learning poli-cies parametrized by large neural networks can achieve significant success on challenging reinforcement learning problems. However, when memory is limited, it is not always possible to store such models exactly for inference, and com-pressing the policy into a compact representation might be necessary. We propose a general framework for policy representation, which reduces this problem to finding a low-dimensional embedding of a given density function in a separable inner product space. Our framework allows us to de-rive strong theoretical guarantees, controlling the error of the reconstructed policies. Such guaran-tees are typically lacking in black-box models, but are very desirable in risk-sensitive tasks. Our experimental results suggest that the reconstructed policies can use less than 10%of the number of parameters in the original networks, while incurring almost no decrease in rewards.
Efficient Planning under Partial Observability with Unnormalized Q Functions and Spectral Learning
Nov 22, 2019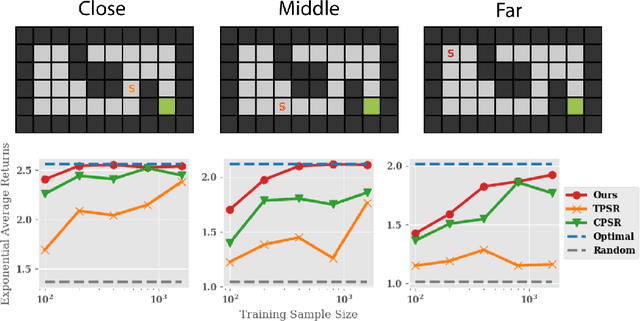
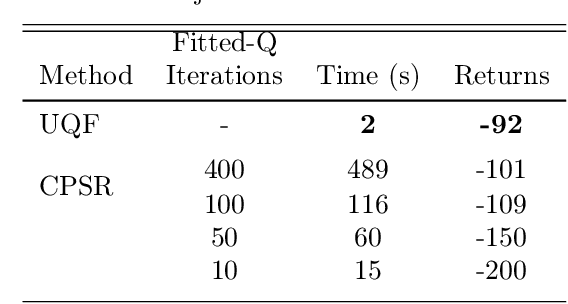
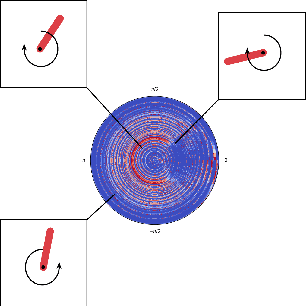
Learning and planning in partially-observable domains is one of the most difficult problems in reinforcement learning. Traditional methods consider these two problems as independent, resulting in a classical two-stage paradigm: first learn the environment dynamics and then plan accordingly. This approach, however, disconnects the two problems and can consequently lead to algorithms that are sample inefficient and time consuming. In this paper, we propose a novel algorithm that combines learning and planning together. Our algorithm is closely related to the spectral learning algorithm for predicitive state representations and offers appealing theoretical guarantees and time complexity. We empirically show on two domains that our approach is more sample and time efficient compared to classical methods.
Attraction-Repulsion Actor-Critic for Continuous Control Reinforcement Learning
Sep 24, 2019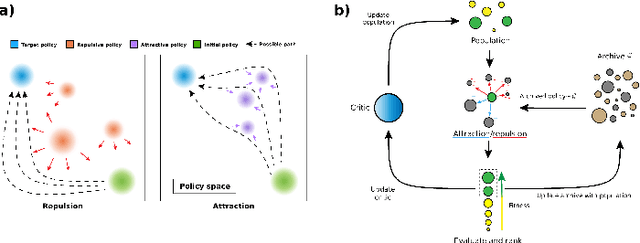
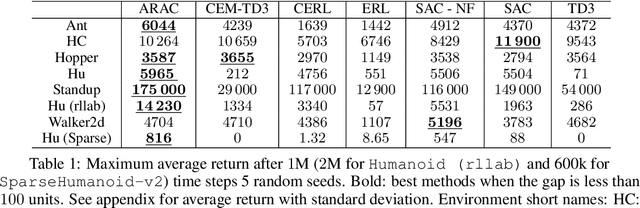
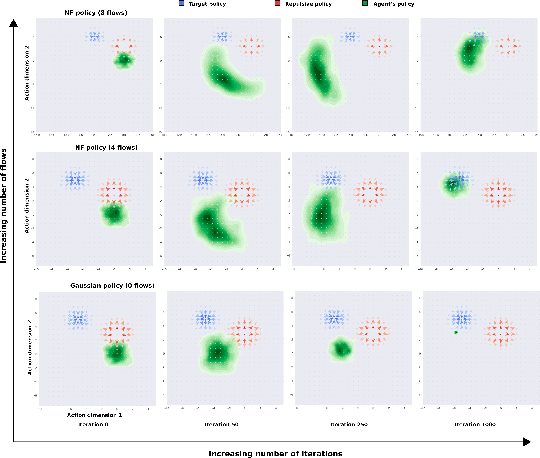
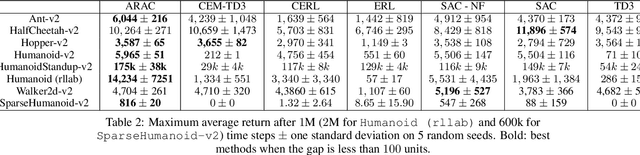
Continuous control tasks in reinforcement learning are important because they provide an important framework for learning in high-dimensional state spaces with deceptive rewards, where the agent can easily become trapped into suboptimal solutions. One way to avoid local optima is to use a population of agents to ensure coverage of the policy space, yet learning a population with the "best" coverage is still an open problem. In this work, we present a novel approach to population-based RL in continuous control that leverages properties of normalizing flows to perform attractive and repulsive operations between current members of the population and previously observed policies. Empirical results on the MuJoCo suite demonstrate a high performance gain for our algorithm compared to prior work, including Soft-Actor Critic (SAC).
Learning Gaussian Graphical Models with Ordered Weighted L1 Regularization
Jun 06, 2019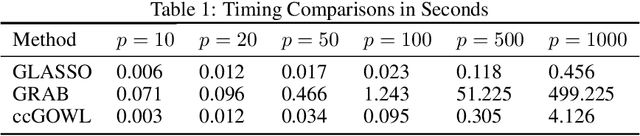
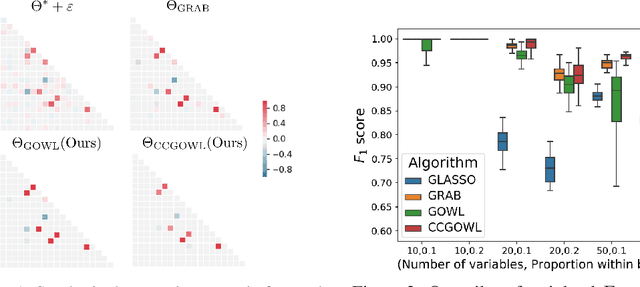
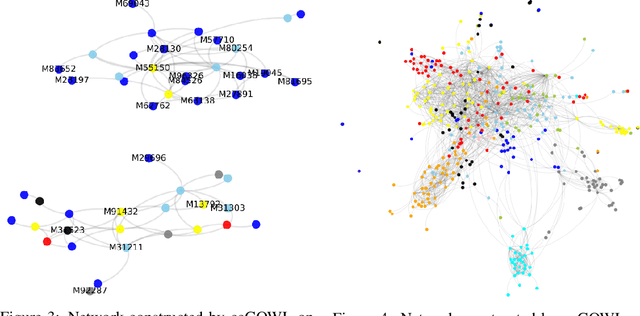
We address the task of identifying densely connected subsets of multivariate Gaussian random variables within a graphical model framework. We propose two novel estimators based on the Ordered Weighted $\ell_1$ (OWL) norm: 1) The Graphical OWL (GOWL) is a penalized likelihood method that applies the OWL norm to the lower triangle components of the precision matrix. 2) The column-by-column Graphical OWL (ccGOWL) estimates the precision matrix by performing OWL regularized linear regressions. Both methods can simultaneously identify highly correlated groups of variables and control the sparsity in the resulting precision matrix. We formulate GOWL such that it solves a composite optimization problem and establish that the estimator has a unique global solution. In addition, we prove sufficient grouping conditions for each column of the ccGOWL precision matrix estimate. We propose proximal descent algorithms to find the optimum for both estimators. For synthetic data where group structure is present, the ccGOWL estimator requires significantly reduced computation and achieves similar or greater accuracy than state-of-the-art estimators. Timing comparisons are presented and demonstrates the superior computational efficiency of the ccGOWL. We illustrate the grouping performance of the ccGOWL method on a cancer gene expression data set and an equities data set.