 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to EdgePGT: A Progressive Method for Training Models on Long Videos
Mar 21, 2021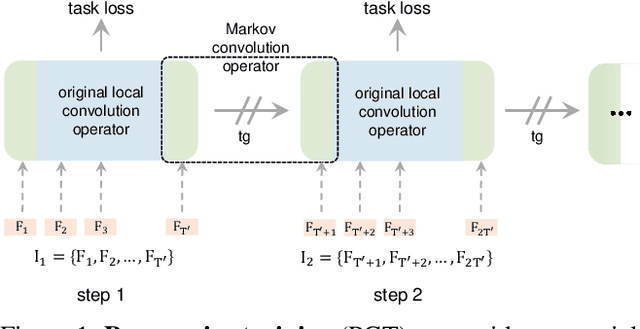
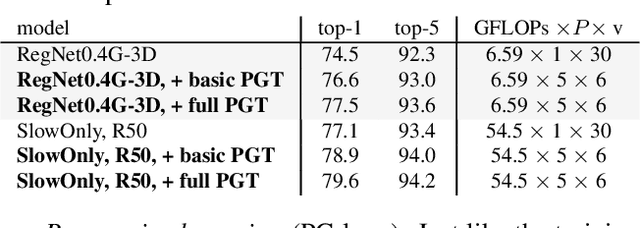
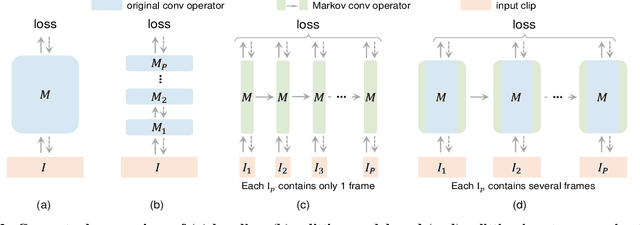
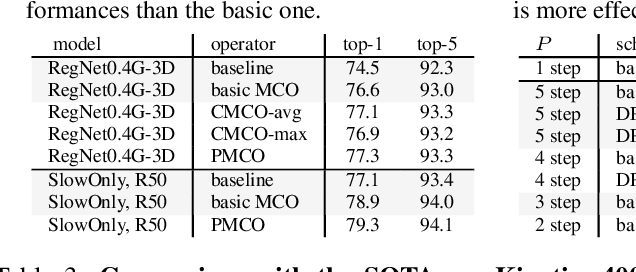
Convolutional video models have an order of magnitude larger computational complexity than their counterpart image-level models. Constrained by computational resources, there is no model or training method that can train long video sequences end-to-end. Currently, the main-stream method is to split a raw video into clips, leading to incomplete fragmentary temporal information flow. Inspired by natural language processing techniques dealing with long sentences, we propose to treat videos as serial fragments satisfying Markov property, and train it as a whole by progressively propagating information through the temporal dimension in multiple steps. This progressive training (PGT) method is able to train long videos end-to-end with limited resources and ensures the effective transmission of information. As a general and robust training method, we empirically demonstrate that it yields significant performance improvements on different models and datasets. As an illustrative example, the proposed method improves SlowOnly network by 3.7 mAP on Charades and 1.9 top-1 accuracy on Kinetics with negligible parameter and computation overhead. Code is available at https://github.com/BoPang1996/PGT.
* CVPR21, Oral
TDAF: Top-Down Attention Framework for Vision Tasks
Dec 14, 2020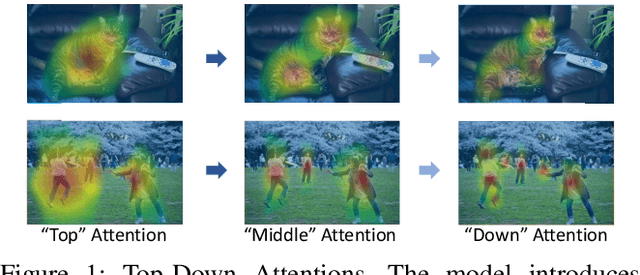
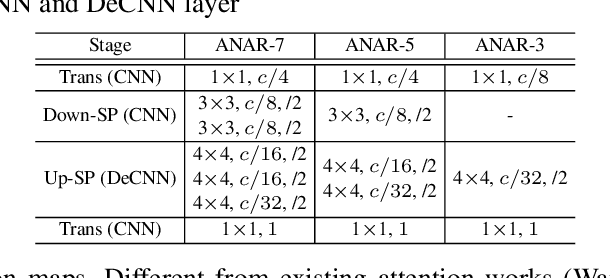
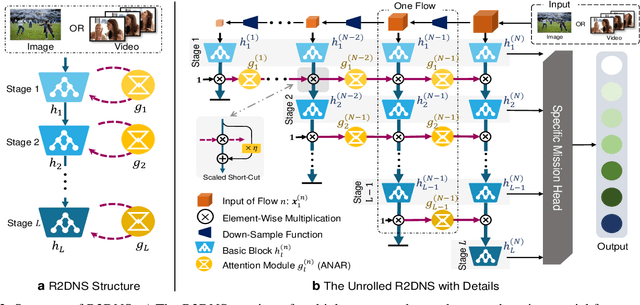
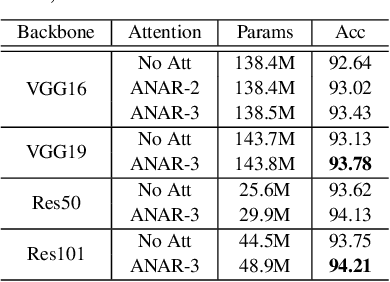
Human attention mechanisms often work in a top-down manner, yet it is not well explored in vision research. Here, we propose the Top-Down Attention Framework (TDAF) to capture top-down attentions, which can be easily adopted in most existing models. The designed Recursive Dual-Directional Nested Structure in it forms two sets of orthogonal paths, recursive and structural ones, where bottom-up spatial features and top-down attention features are extracted respectively. Such spatial and attention features are nested deeply, therefore, the proposed framework works in a mixed top-down and bottom-up manner. Empirical evidence shows that our TDAF can capture effective stratified attention information and boost performance. ResNet with TDAF achieves 2.0% improvements on ImageNet. For object detection, the performance is improved by 2.7% AP over FCOS. For pose estimation, TDAF improves the baseline by 1.6%. And for action recognition, the 3D-ResNet adopting TDAF achieves improvements of 1.7% accuracy.
Understanding Guided Image Captioning Performance across Domains
Dec 04, 2020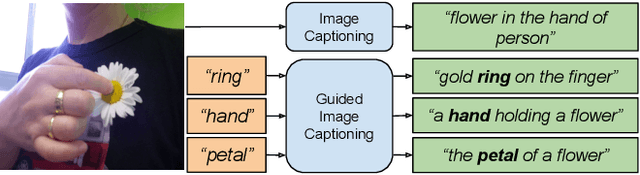

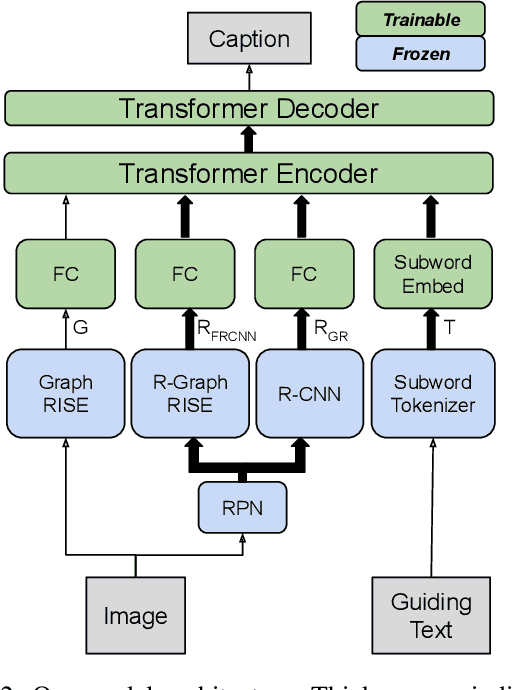
Image captioning models generally lack the capability to take into account user interest, and usually default to global descriptions that try to balance readability, informativeness, and information overload. On the other hand, VQA models generally lack the ability to provide long descriptive answers, while expecting the textual question to be quite precise. We present a method to control the concepts that an image caption should focus on, using an additional input called the guiding text that refers to either groundable or ungroundable concepts in the image. Our model consists of a Transformer-based multimodal encoder that uses the guiding text together with global and object-level image features to derive early-fusion representations used to generate the guided caption. While models trained on Visual Genome data have an in-domain advantage of fitting well when guided with automatic object labels, we find that guided captioning models trained on Conceptual Captions generalize better on out-of-domain images and guiding texts. Our human-evaluation results indicate that attempting in-the-wild guided image captioning requires access to large, unrestricted-domain training datasets, and that increased style diversity (even without increasing vocabulary size) is a key factor for improved performance.
Semi-supervised Learning by Latent Space Energy-Based Model of Symbol-Vector Coupling
Oct 19, 2020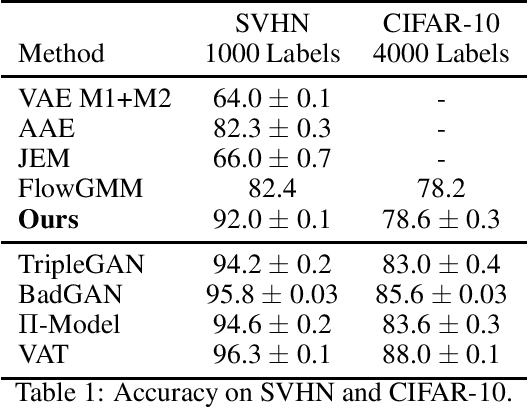
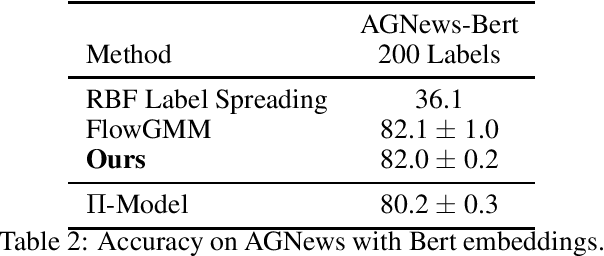
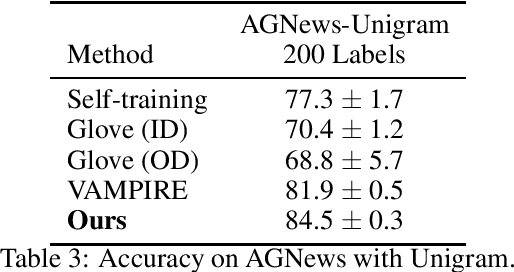
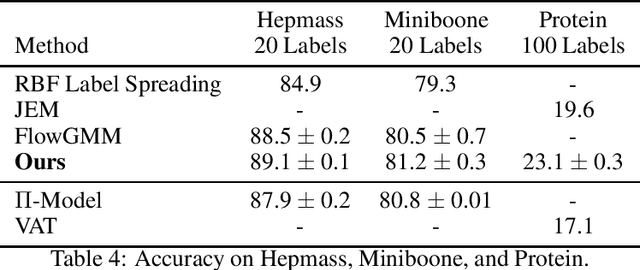
This paper proposes a latent space energy-based prior model for semi-supervised learning. The model stands on a generator network that maps a latent vector to the observed example. The energy term of the prior model couples the latent vector and a symbolic one-hot vector, so that classification can be based on the latent vector inferred from the observed example. In our learning method, the symbol-vector coupling, the generator network and the inference network are learned jointly. Our method is applicable to semi-supervised learning in various data domains such as image, text, and tabular data. Our experiments demonstrate that our method performs well on semi-supervised learning tasks.
Learning Latent Space Energy-Based Prior Model for Molecule Generation
Oct 19, 2020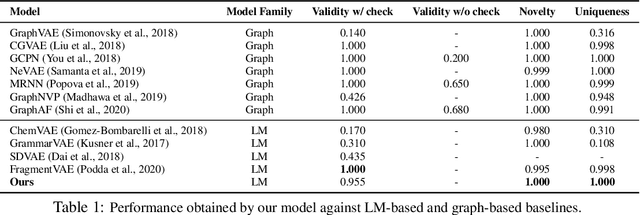

Deep generative models have recently been applied to molecule design. If the molecules are encoded in linear SMILES strings, modeling becomes convenient. However, models relying on string representations tend to generate invalid samples and duplicates. Prior work addressed these issues by building models on chemically-valid fragments or explicitly enforcing chemical rules in the generation process. We argue that an expressive model is sufficient to implicitly and automatically learn the complicated chemical rules from the data, even if molecules are encoded in simple character-level SMILES strings. We propose to learn latent space energy-based prior model with SMILES representation for molecule modeling. Our experiments show that our method is able to generate molecules with validity and uniqueness competitive with state-of-the-art models. Interestingly, generated molecules have structural and chemical features whose distributions almost perfectly match those of the real molecules.
Unsupervised Constrative Person Re-identification
Oct 15, 2020
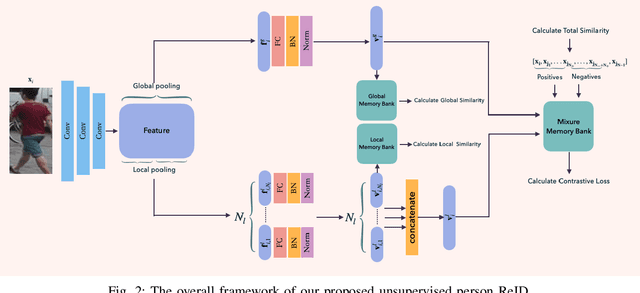
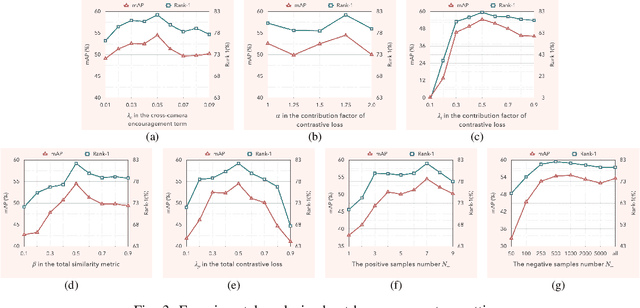

Person re-identification (ReID) aims at searching the same identity person among images captured by various cameras. Unsupervised person ReID attracts a lot of attention recently, due to it works without intensive manual annotation and thus shows great potential of adapting to new conditions. Representation learning plays a critical role in unsupervised person ReID. In this work, we propose a novel selective contrastive learning framework for unsupervised feature learning. Specifically, different from traditional contrastive learning strategies, we propose to use multiple positives and adaptively sampled negatives for defining the contrastive loss, enabling to learn a feature embedding model with stronger identity discriminative representation. Moreover, we propose to jointly leverage global and local features to construct three dynamic dictionaries, among which the global and local memory banks are used for pairwise similarity computation and the mixture memory bank are used for contrastive loss definition. Experimental results demonstrate the superiority of our method in unsupervised person ReID compared with the state-of-the-arts.
Robust Reinforcement Learning: A Case Study in Linear Quadratic Regulation
Sep 01, 2020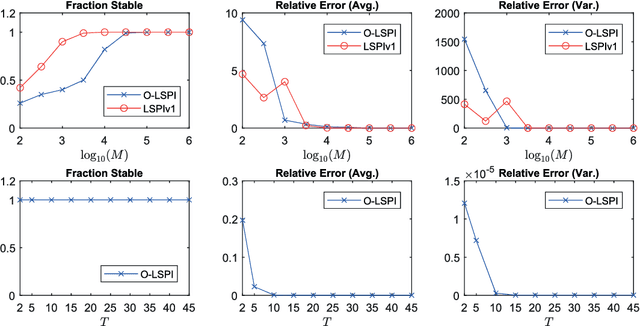
This paper studies the robustness aspect of reinforcement learning algorithms in the presence of errors. Specifically, we revisit the benchmark problem of discrete-time linear quadratic regulation (LQR) and study the long-standing open question: Under what conditions is the policy iteration method robustly stable for dynamical systems with unbounded, continuous state and action spaces? Using advanced stability results in control theory, it is shown that policy iteration for LQR is inherently robust to small errors and enjoys local input-to-state stability: whenever the error in each iteration is bounded and small, the solutions of the policy iteration algorithm are also bounded, and, moreover, enter and stay in a small neighborhood of the optimal LQR solution. As an application, a novel off-policy optimistic least-squares policy iteration for the LQR problem is proposed, when the system dynamics are subjected to additive stochastic disturbances. The proposed new results in robust reinforcement learning are validated by a numerical example.
ASAP-Net: Attention and Structure Aware Point Cloud Sequence Segmentation
Aug 12, 2020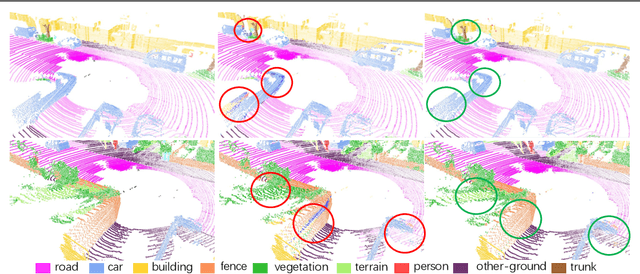
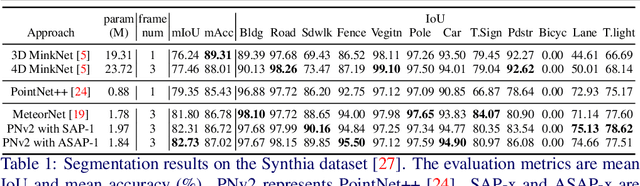
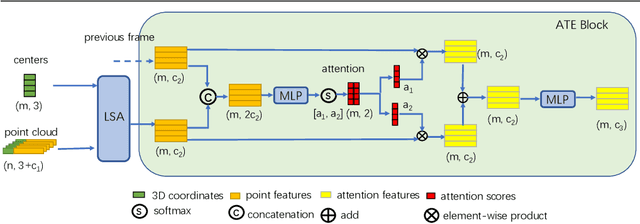
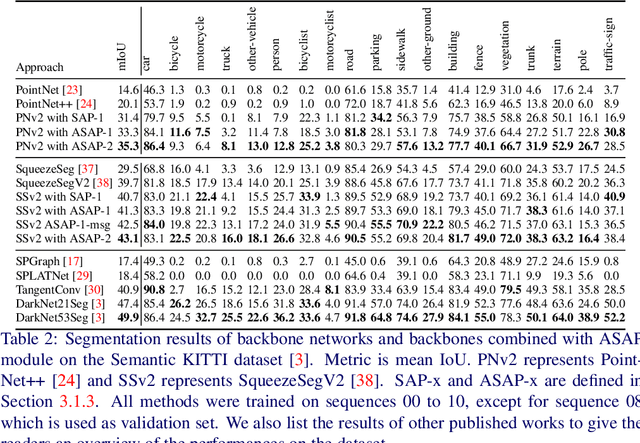
Recent works of point clouds show that mulit-frame spatio-temporal modeling outperforms single-frame versions by utilizing cross-frame information. In this paper, we further improve spatio-temporal point cloud feature learning with a flexible module called ASAP considering both attention and structure information across frames, which we find as two important factors for successful segmentation in dynamic point clouds. Firstly, our ASAP module contains a novel attentive temporal embedding layer to fuse the relatively informative local features across frames in a recurrent fashion. Secondly, an efficient spatio-temporal correlation method is proposed to exploit more local structure for embedding, meanwhile enforcing temporal consistency and reducing computation complexity. Finally, we show the generalization ability of the proposed ASAP module with different backbone networks for point cloud sequence segmentation. Our ASAP-Net (backbone plus ASAP module) outperforms baselines and previous methods on both Synthia and SemanticKITTI datasets (+3.4 to +15.2 mIoU points with different backbones). Code is availabe at https://github.com/intrepidChw/ASAP-Net
Learning Latent Space Energy-Based Prior Model
Jun 15, 2020
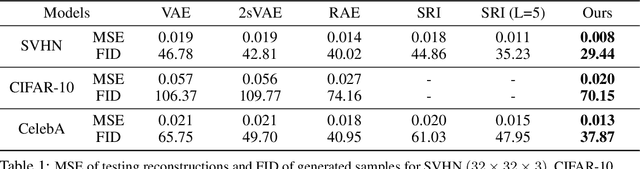

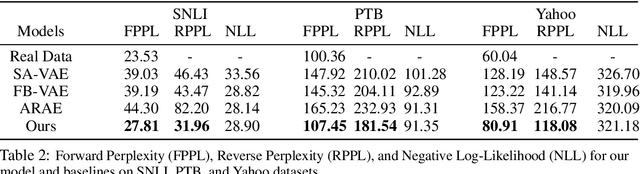
The generator model assumes that the observed example is generated by a low-dimensional latent vector via a top-down network, and the latent vector follows a simple and known prior distribution, such as uniform or Gaussian white noise distribution. While we can learn an expressive top-down network to map the prior distribution to the data distribution, we can also learn an expressive prior model instead of assuming a given prior distribution. This follows the philosophy of empirical Bayes where the prior model is learned from the observed data. We propose to learn an energy-based prior model for the latent vector, where the energy function is parametrized by a very simple multi-layer perceptron. Due to the low-dimensionality of the latent space, learning a latent space energy-based prior model proves to be both feasible and desirable. In this paper, we develop the maximum likelihood learning algorithm and its variation based on short-run Markov chain Monte Carlo sampling from the prior and the posterior distributions of the latent vector, and we show that the learned model exhibits strong performance in terms of image and text generation and anomaly detection.
Learning Energy-based Model with Flow-based Backbone by Neural Transport MCMC
Jun 12, 2020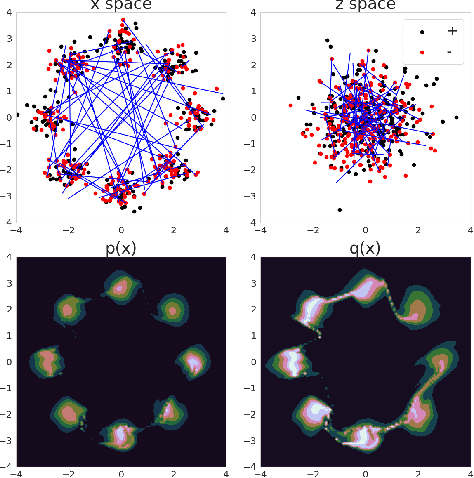
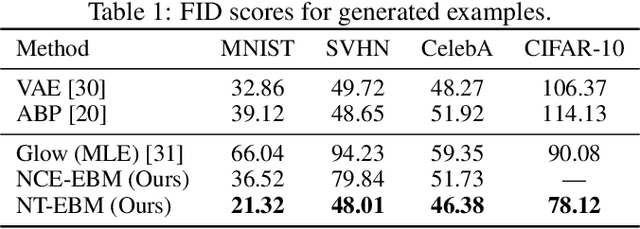
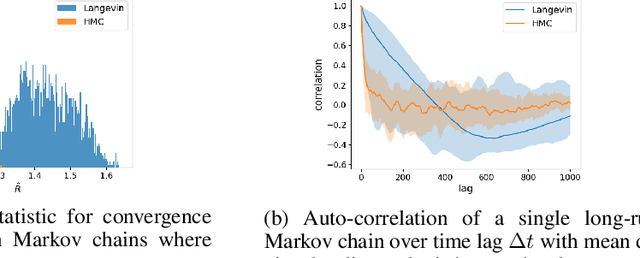

Learning energy-based model (EBM) requires MCMC sampling of the learned model as the inner loop of the learning algorithm. However, MCMC sampling of EBM in data space is generally not mixing, because the energy function, which is usually parametrized by deep network, is highly multi-modal in the data space. This is a serious handicap for both the theory and practice of EBM. In this paper, we propose to learn EBM with a flow-based model serving as a backbone, so that the EBM is a correction or an exponential tilting of the flow-based model. We show that the model has a particularly simple form in the space of the latent variables of the flow-based model, and MCMC sampling of the EBM in the latent space, which is a simple special case of neural transport MCMC, mixes well and traverses modes in the data space. This enables proper sampling and learning of EBM.