 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to EdgeESGReveal: An LLM-based approach for extracting structured data from ESG reports
Dec 25, 2023ESGReveal is an innovative method proposed for efficiently extracting and analyzing Environmental, Social, and Governance (ESG) data from corporate reports, catering to the critical need for reliable ESG information retrieval. This approach utilizes Large Language Models (LLM) enhanced with Retrieval Augmented Generation (RAG) techniques. The ESGReveal system includes an ESG metadata module for targeted queries, a preprocessing module for assembling databases, and an LLM agent for data extraction. Its efficacy was appraised using ESG reports from 166 companies across various sectors listed on the Hong Kong Stock Exchange in 2022, ensuring comprehensive industry and market capitalization representation. Utilizing ESGReveal unearthed significant insights into ESG reporting with GPT-4, demonstrating an accuracy of 76.9% in data extraction and 83.7% in disclosure analysis, which is an improvement over baseline models. This highlights the framework's capacity to refine ESG data analysis precision. Moreover, it revealed a demand for reinforced ESG disclosures, with environmental and social data disclosures standing at 69.5% and 57.2%, respectively, suggesting a pursuit for more corporate transparency. While current iterations of ESGReveal do not process pictorial information, a functionality intended for future enhancement, the study calls for continued research to further develop and compare the analytical capabilities of various LLMs. In summary, ESGReveal is a stride forward in ESG data processing, offering stakeholders a sophisticated tool to better evaluate and advance corporate sustainability efforts. Its evolution is promising in promoting transparency in corporate reporting and aligning with broader sustainable development aims.
AutoPCF: Efficient Product Carbon Footprint Accounting with Large Language Models
Aug 11, 2023The product carbon footprint (PCF) is crucial for decarbonizing the supply chain, as it measures the direct and indirect greenhouse gas emissions caused by all activities during the product's life cycle. However, PCF accounting often requires expert knowledge and significant time to construct life cycle models. In this study, we test and compare the emergent ability of five large language models (LLMs) in modeling the 'cradle-to-gate' life cycles of products and generating the inventory data of inputs and outputs, revealing their limitations as a generalized PCF knowledge database. By utilizing LLMs, we propose an automatic AI-driven PCF accounting framework, called AutoPCF, which also applies deep learning algorithms to automatically match calculation parameters, and ultimately calculate the PCF. The results of estimating the carbon footprint for three case products using the AutoPCF framework demonstrate its potential in achieving automatic modeling and estimation of PCF with a large reduction in modeling time from days to minutes.
Estimates of daily ground-level NO2 concentrations in China based on big data and machine learning approaches
Nov 18, 2020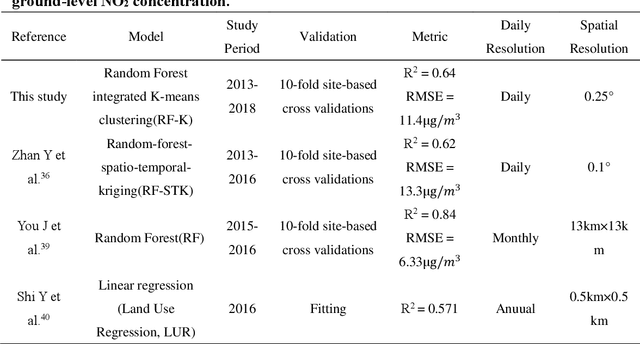
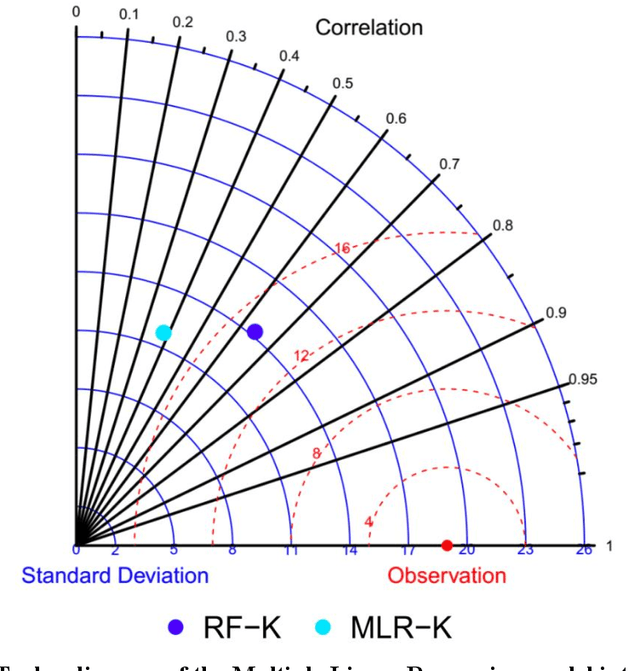
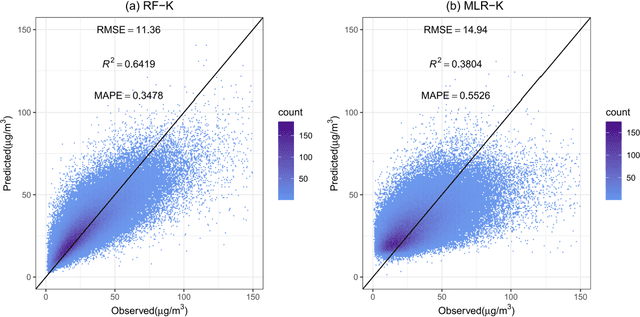
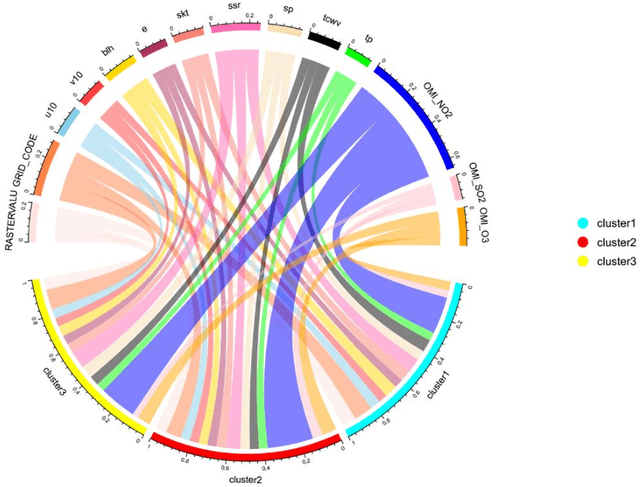
Nitrogen dioxide (NO2) is one of the most important atmospheric pollutants. However, current ground-level NO2 concentration data are lack of either high-resolution coverage or full coverage national wide, due to the poor quality of source data and the computing power of the models. To our knowledge, this study is the first to estimate the ground-level NO2 concentration in China with national coverage as well as relatively high spatiotemporal resolution (0.25 degree; daily intervals) over the newest past 6 years (2013-2018). We advanced a Random Forest model integrated K-means (RF-K) for the estimates with multi-source parameters. Besides meteorological parameters, satellite retrievals parameters, we also, for the first time, introduce socio-economic parameters to assess the impact by human activities. The results show that: (1) the RF-K model we developed shows better prediction performance than other models, with cross-validation R2 = 0.64 (MAPE = 34.78%). (2) The annual average concentration of NO2 in China showed a weak increasing trend . While in the economic zones such as Beijing-Tianjin-Hebei region, Yangtze River Delta, and Pearl River Delta, the NO2 concentration there even decreased or remained unchanged, especially in spring. Our dataset has verified that pollutant controlling targets have been achieved in these areas. With mapping daily nationwide ground-level NO2 concentrations, this study provides timely data with high quality for air quality management for China. We provide a universal model framework to quickly generate a timely national atmospheric pollutants concentration map with a high spatial-temporal resolution, based on improved machine learning methods.