 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to EdgeKuaiRec: A Fully-observed Dataset for Recommender Systems
Feb 22, 2022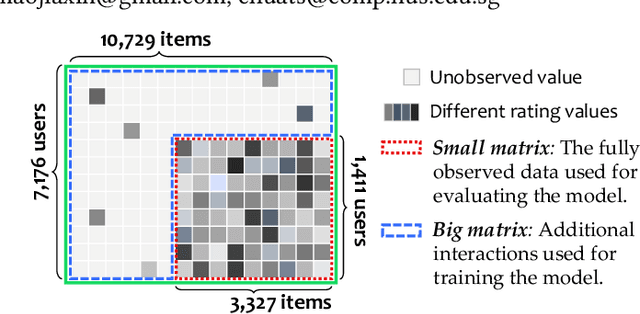
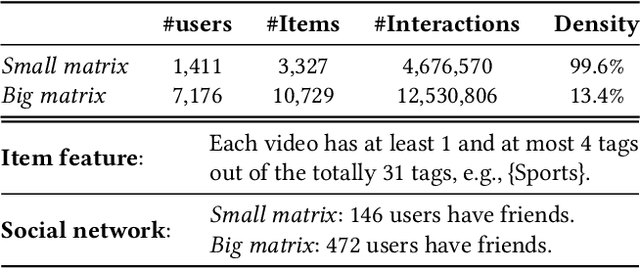

Recommender systems are usually developed and evaluated on the historical user-item logs. However, most offline recommendation datasets are highly sparse and contain various biases, which hampers the evaluation of recommendation policies. Existing efforts aim to improve the data quality by collecting users' preferences on randomly selected items (e.g., Yahoo! and Coat). However, they still suffer from the high variance issue caused by the sparsely observed data. To fundamentally solve the problem, we present KuaiRec, a fully-observed dataset collected from the social video-sharing mobile App, Kuaishou. The feedback of 1,411 users on almost all of the 3,327 videos is explicitly observed. To the best of our knowledge, this is the first real-world fully-observed dataset with millions of user-item interactions in recommendation. To demonstrate the advantage of KuaiRec, we leverage it to explore the key questions in evaluating conversational recommender systems. The experimental results show that two factors in traditional partially-observed data -- the data density and the exposure bias -- greatly affect the evaluation results. This entails the significance of our fully-observed data in researching many directions in recommender systems, e.g., the unbiased recommendation, interactive/conversational recommendation, and evaluation. We release the dataset and the pipeline implementation for evaluation at https://chongminggao.github.io/KuaiRec/.
LBCF: A Large-Scale Budget-Constrained Causal Forest Algorithm
Jan 29, 2022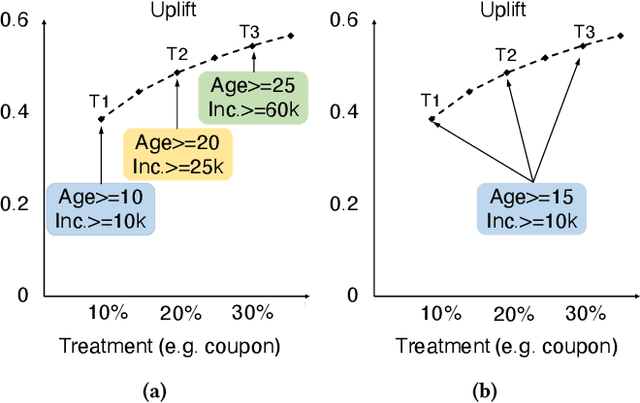
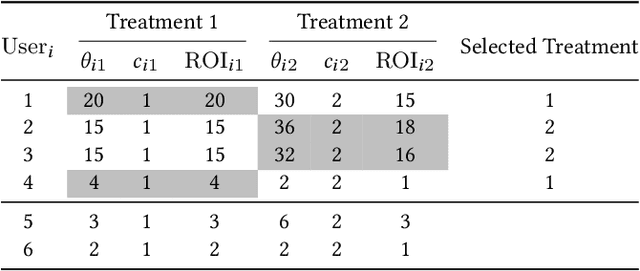
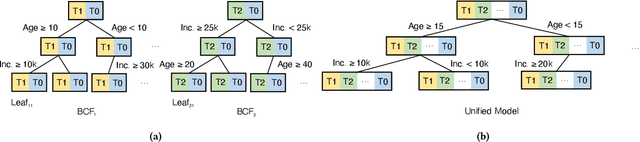

Offering incentives (e.g., coupons at Amazon, discounts at Uber and video bonuses at Tiktok) to user is a common strategy used by online platforms to increase user engagement and platform revenue. Despite its proven effectiveness, these marketing incentives incur an inevitable cost and might result in a low ROI (Return on Investment) if not used properly. On the other hand, different users respond differently to these incentives, for instance, some users never buy certain products without coupons, while others do anyway. Thus, how to select the right amount of incentives (i.e. treatment) to each user under budget constraints is an important research problem with great practical implications. In this paper, we call such problem as a budget-constrained treatment selection (BTS) problem. The challenge is how to efficiently solve BTS problem on a Large-Scale dataset and achieve improved results over the existing techniques. We propose a novel tree-based treatment selection technique under budget constraints, called Large-Scale Budget-Constrained Causal Forest (LBCF) algorithm, which is also an efficient treatment selection algorithm suitable for modern distributed computing systems. A novel offline evaluation method is also proposed to overcome an intrinsic challenge in assessing solutions' performance for BTS problem in randomized control trials (RCT) data. We deploy our approach in a real-world scenario on a large-scale video platform, where the platform gives away bonuses in order to increase users' campaign engagement duration. The simulation analysis, offline and online experiments all show that our method outperforms various tree-based state-of-the-art baselines. The proposed approach is currently serving over hundreds of millions of users on the platform and achieves one of the most tremendous improvements over these months.
An Improved Discriminative Optimization for 3D Rigid Point Cloud Registration
Apr 18, 2021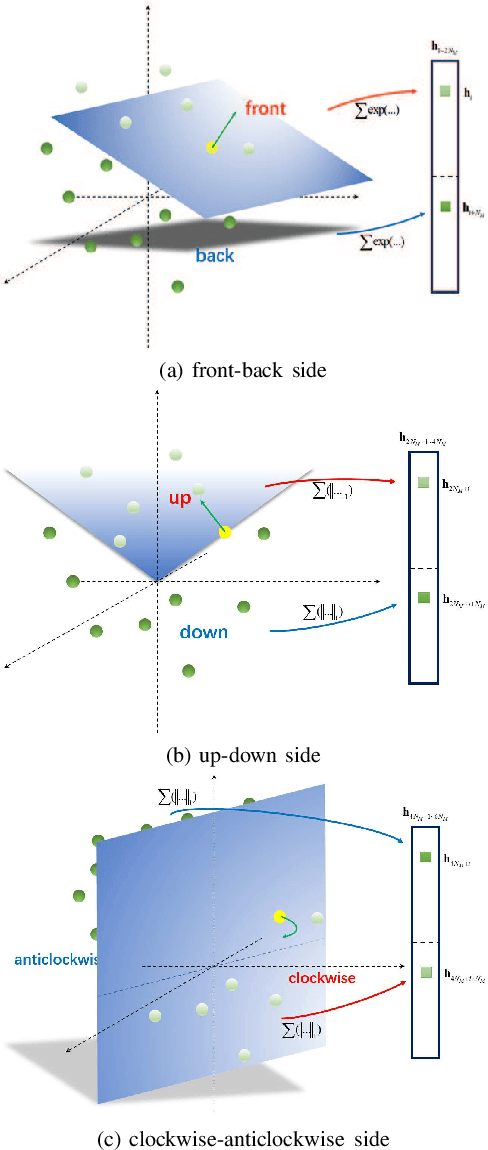
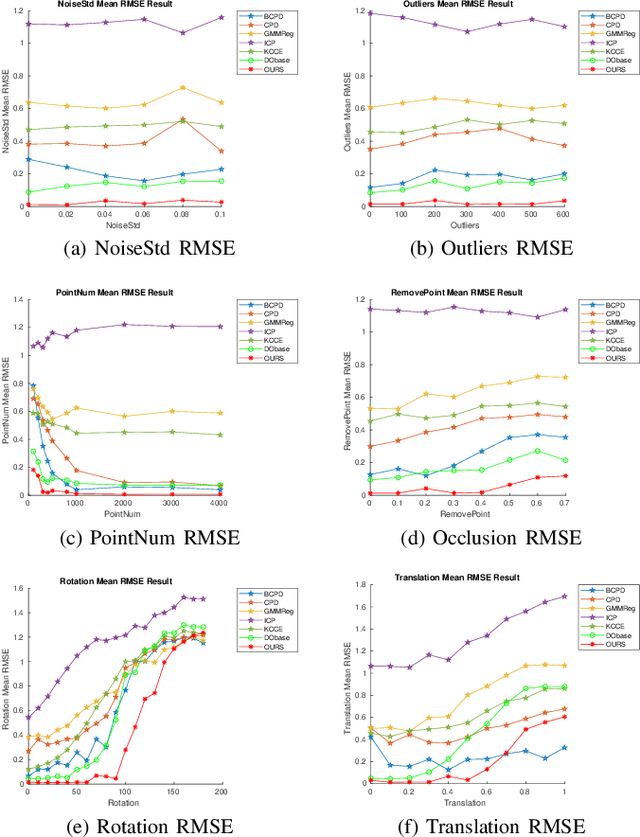
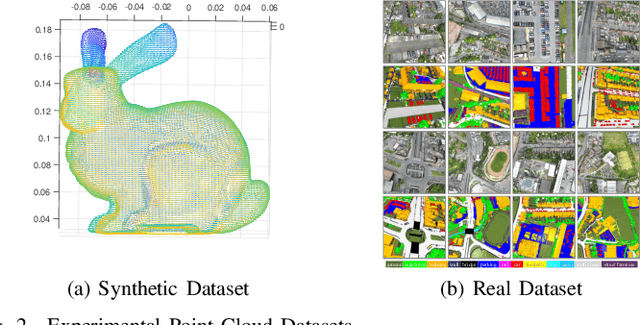
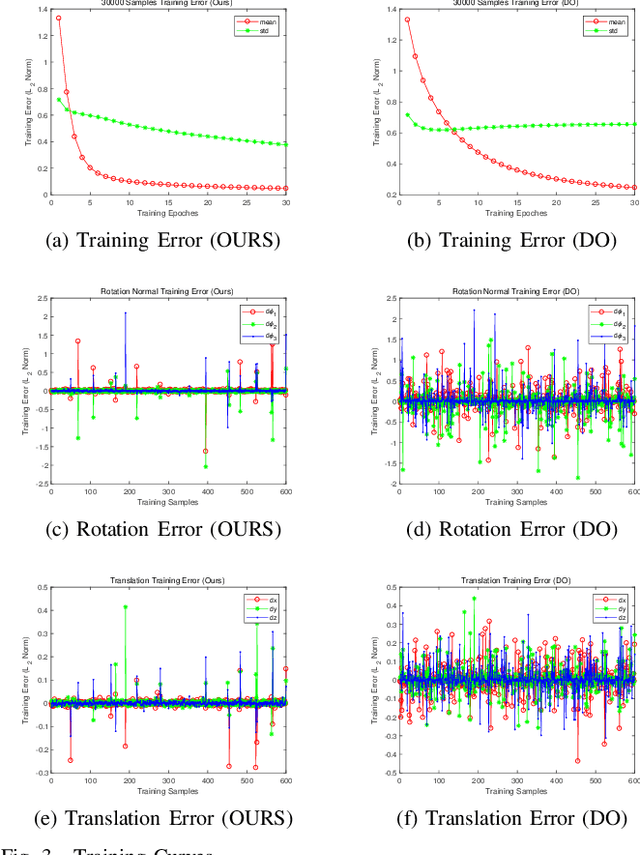
The Discriminative Optimization (DO) algorithm has been proved much successful in 3D point cloud registration. In the original DO, the feature (descriptor) of two point cloud was defined as a histogram, and the element of histogram indicates the weights of scene points in "front" or "back" side of a model point. In this paper, we extended the histogram which indicate the sides from "front-back" to "front-back", "up-down", and "clockwise-anticlockwise". In addition, we reweighted the extended histogram according to the model points' distribution. We evaluated the proposed Improved DO on the Stanford Bunny and Oxford SensatUrban dataset, and compared it with six classical State-Of-The-Art point cloud registration algorithms. The experimental result demonstrates our algorithm achieves comparable performance in point registration accuracy and root-mean-sqart-error.
A Multiscale Graph Convolutional Network for Change Detection in Homogeneous and Heterogeneous Remote Sensing Images
Feb 16, 2021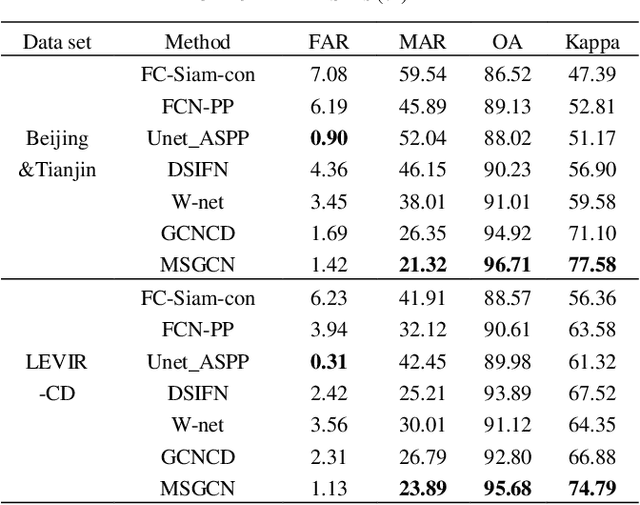
Change detection (CD) in remote sensing images has been an ever-expanding area of research. To date, although many methods have been proposed using various techniques, accurately identifying changes is still a great challenge, especially in the high resolution or heterogeneous situations, due to the difficulties in effectively modeling the features from ground objects with different patterns. In this paper, a novel CD method based on the graph convolutional network (GCN) and multiscale object-based technique is proposed for both homogeneous and heterogeneous images. First, the object-wise high level features are obtained through a pre-trained U-net and the multiscale segmentations. Treating each parcel as a node, the graph representations can be formed and then, fed into the proposed multiscale graph convolutional network with each channel corresponding to one scale. The multiscale GCN propagates the label information from a small number of labeled nodes to the other ones which are unlabeled. Further, to comprehensively incorporate the information from the output channels of multiscale GCN, a fusion strategy is designed using the father-child relationships between scales. Extensive Experiments on optical, SAR and heterogeneous optical/SAR data sets demonstrate that the proposed method outperforms some state-of the-art methods in both qualitative and quantitative evaluations. Besides, the Influences of some factors are also discussed.
A Learning-based Optimization Algorithm:Image Registration Optimizer Network
Nov 23, 2020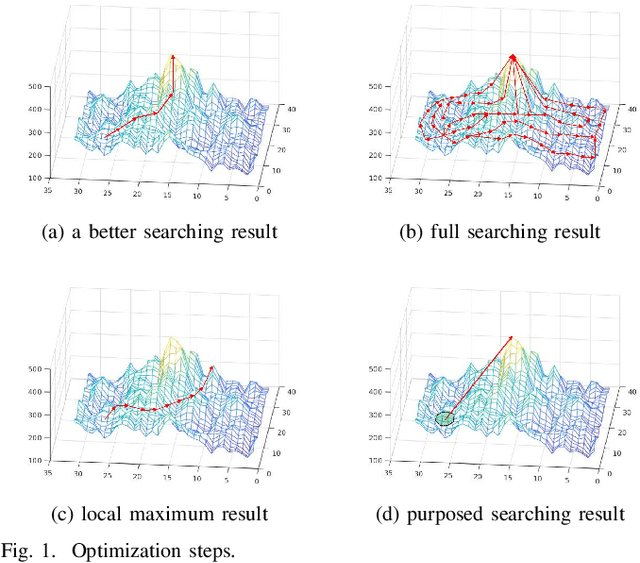
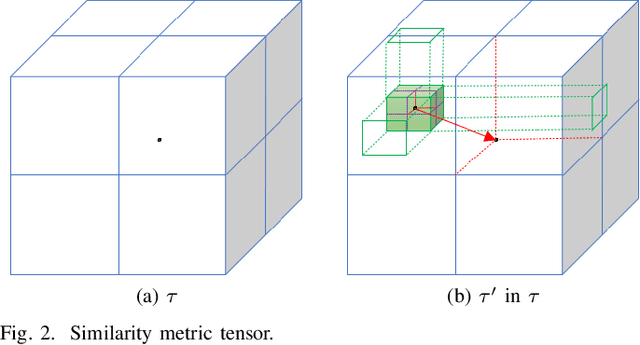
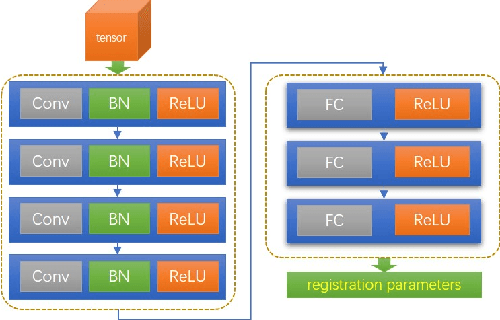
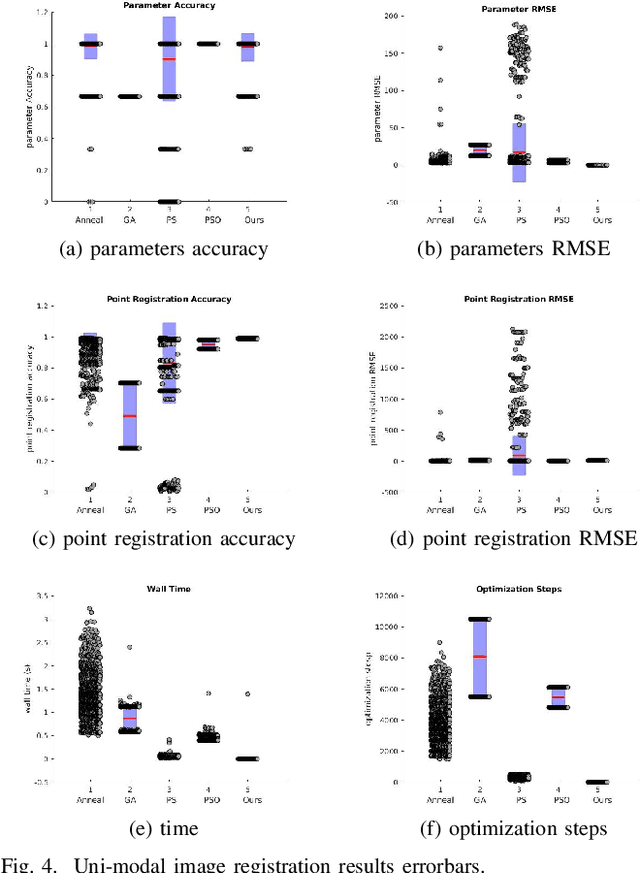
Remote sensing image registration is valuable for image-based navigation system despite posing many challenges. As the search space of registration is usually non-convex, the optimization algorithm, which aims to search the best transformation parameters, is a challenging step. Conventional optimization algorithms can hardly reconcile the contradiction of simultaneous rapid convergence and the global optimization. In this paper, a novel learning-based optimization algorithm named Image Registration Optimizer Network (IRON) is proposed, which can predict the global optimum after single iteration. The IRON is trained by a 3D tensor (9x9x9), which consists of similar metric values. The elements of the 3D tensor correspond to the 9x9x9 neighbors of the initial parameters in the search space. Then, the tensor's label is a vector that points to the global optimal parameters from the initial parameters. Because of the special architecture, the IRON could predict the global optimum directly for any initialization. The experimental results demonstrate that the proposed algorithm performs better than other classical optimization algorithms as it has higher accuracy, lower root of mean square error (RMSE), and more efficiency. Our IRON codes are available for further study.https://www.github.com/jaxwangkd04/IRON
Axiom-based Grad-CAM: Towards Accurate Visualization and Explanation of CNNs
Aug 19, 2020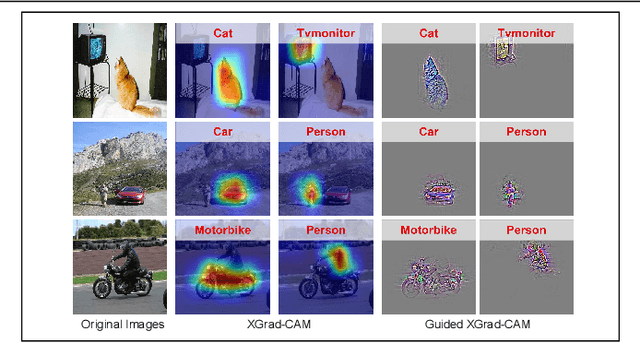
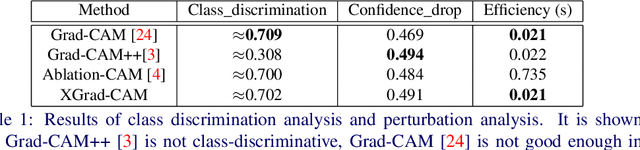
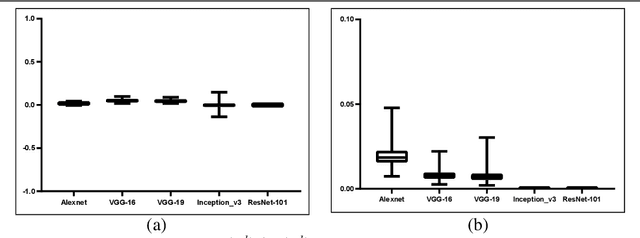
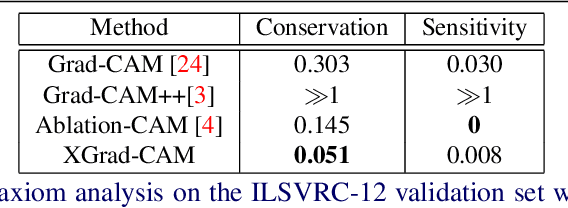
To have a better understanding and usage of Convolution Neural Networks (CNNs), the visualization and interpretation of CNNs has attracted increasing attention in recent years. In particular, several Class Activation Mapping (CAM) methods have been proposed to discover the connection between CNN's decision and image regions. In spite of the reasonable visualization, lack of clear and sufficient theoretical support is the main limitation of these methods. In this paper, we introduce two axioms -- Conservation and Sensitivity -- to the visualization paradigm of the CAM methods. Meanwhile, a dedicated Axiom-based Grad-CAM (XGrad-CAM) is proposed to satisfy these axioms as much as possible. Experiments demonstrate that XGrad-CAM is an enhanced version of Grad-CAM in terms of conservation and sensitivity. It is able to achieve better visualization performance than Grad-CAM, while also be class-discriminative and easy-to-implement compared with Grad-CAM++ and Ablation-CAM. The code is available at https://github.com/Fu0511/XGrad-CAM.
s-LWSR: Super Lightweight Super-Resolution Network
Sep 24, 2019
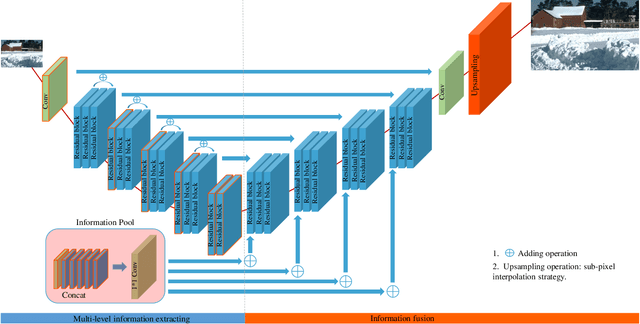
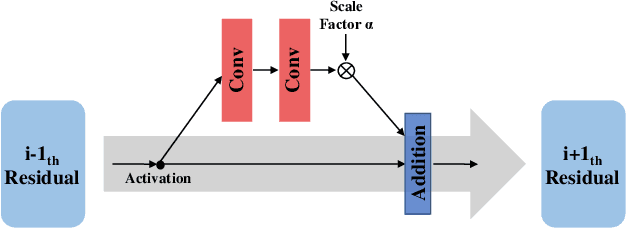
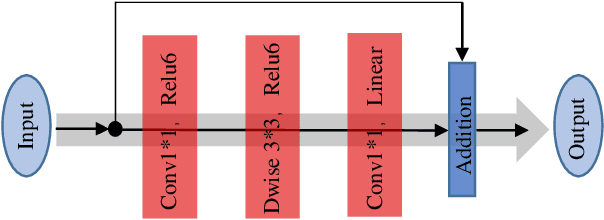
Deep learning (DL) architectures for superresolution (SR) normally contain tremendous parameters, which has been regarded as the crucial advantage for obtaining satisfying performance. However, with the widespread use of mobile phones for taking and retouching photos, this character greatly hampers the deployment of DL-SR models on the mobile devices. To address this problem, in this paper, we propose a super lightweight SR network: s-LWSR. There are mainly three contributions in our work. Firstly, in order to efficiently abstract features from the low resolution image, we build an information pool to mix multi-level information from the first half part of the pipeline. Accordingly, the information pool feeds the second half part with the combination of hierarchical features from the previous layers. Secondly, we employ a compression module to further decrease the size of parameters. Intensive analysis confirms its capacity of trade-off between model complexity and accuracy. Thirdly, by revealing the specific role of activation in deep models, we remove several activation layers in our SR model to retain more information for performance improvement. Extensive experiments show that our s-LWSR, with limited parameters and operations, can achieve similar performance to other cumbersome DL-SR methods.
Position Focused Attention Network for Image-Text Matching
Jul 23, 2019
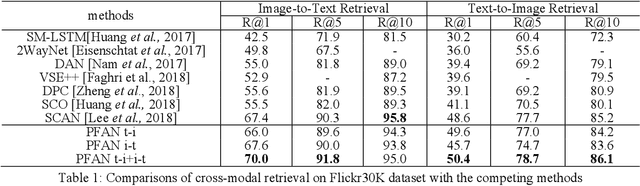
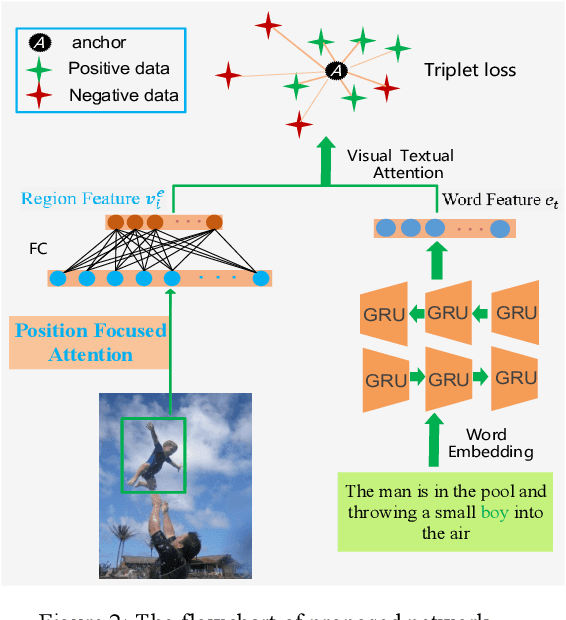
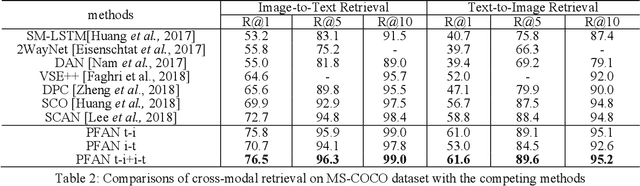
Image-text matching tasks have recently attracted a lot of attention in the computer vision field. The key point of this cross-domain problem is how to accurately measure the similarity between the visual and the textual contents, which demands a fine understanding of both modalities. In this paper, we propose a novel position focused attention network (PFAN) to investigate the relation between the visual and the textual views. In this work, we integrate the object position clue to enhance the visual-text joint-embedding learning. We first split the images into blocks, by which we infer the relative position of region in the image. Then, an attention mechanism is proposed to model the relations between the image region and blocks and generate the valuable position feature, which will be further utilized to enhance the region expression and model a more reliable relationship between the visual image and the textual sentence. Experiments on the popular datasets Flickr30K and MS-COCO show the effectiveness of the proposed method. Besides the public datasets, we also conduct experiments on our collected practical large-scale news dataset (Tencent-News) to validate the practical application value of proposed method. As far as we know, this is the first attempt to test the performance on the practical application. Our method achieves the state-of-art performance on all of these three datasets.
Cross-Domain Collaborative Learning via Cluster Canonical Correlation Analysis and Random Walker for Hyperspectral Image Classification
Oct 30, 2018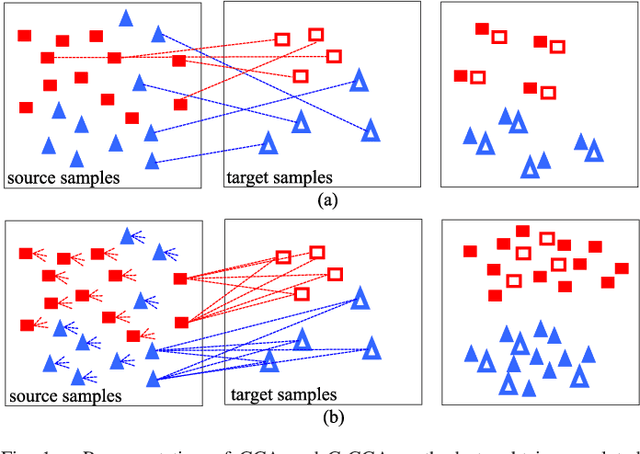
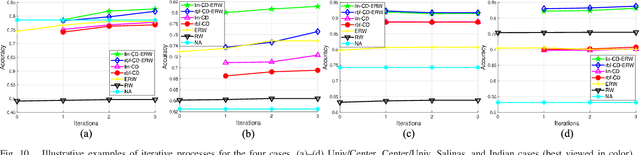
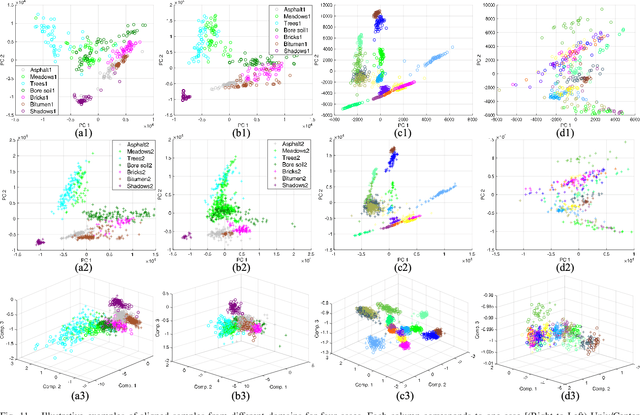
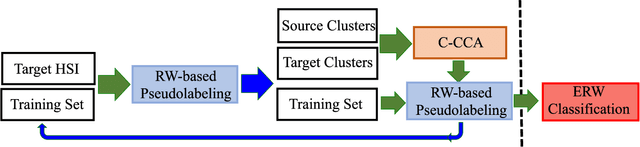
This paper introduces a novel heterogenous domain adaptation (HDA) method for hyperspectral image classification with a limited amount of labeled samples in both domains. The method is achieved in the way of cross-domain collaborative learning (CDCL), which is addressed via cluster canonical correlation analysis (C-CCA) and random walker (RW) algorithms. To be specific, the proposed CDCL method is an iterative process of three main stages, i.e. twice of RW-based pseudolabeling and cross domain learning via C-CCA. Firstly, given the initially labeled target samples as training set ($\mathbf{TS}$), the RW-based pseudolabeling is employed to update $\mathbf{TS}$ and extract target clusters ($\mathbf{TCs}$) by fusing the segmentation results obtained by RW and extended RW (ERW) classifiers. Secondly, cross domain learning via C-CCA is applied using labeled source samples and $\mathbf{TCs}$. The unlabeled target samples are then classified with the estimated probability maps using the model trained in the projected correlation subspace. Thirdly, both $\mathbf{TS}$ and estimated probability maps are used for updating $\mathbf{TS}$ again via RW-based pseudolabeling. When the iterative process finishes, the result obtained by the ERW classifier using the final $\mathbf{TS}$ and estimated probability maps is regarded as the final classification map. Experimental results on four real HSIs demonstrate that the proposed method can achieve better performance compared with the state-of-the-art HDA and ERW methods.
Tensor Alignment Based Domain Adaptation for Hyperspectral Image Classification
Sep 04, 2018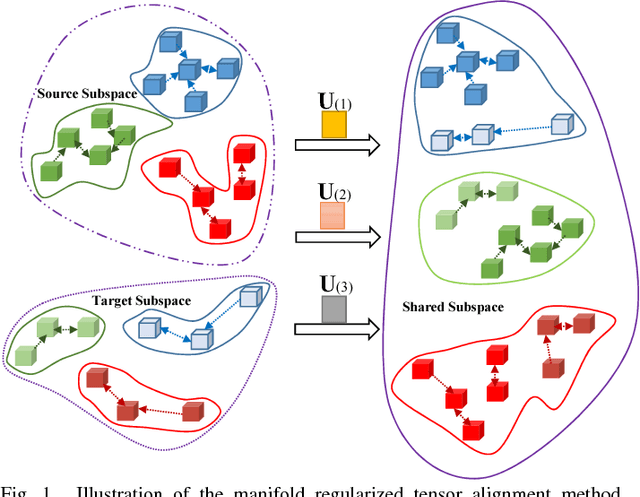
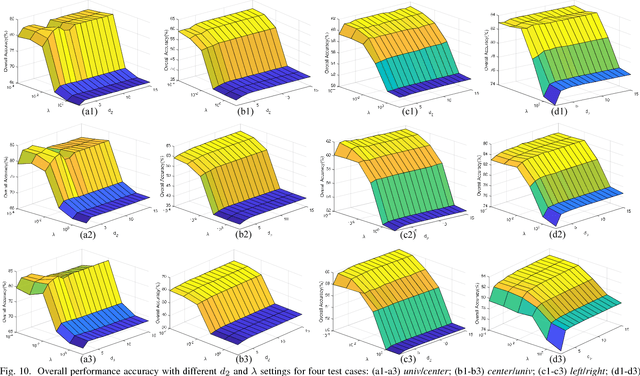
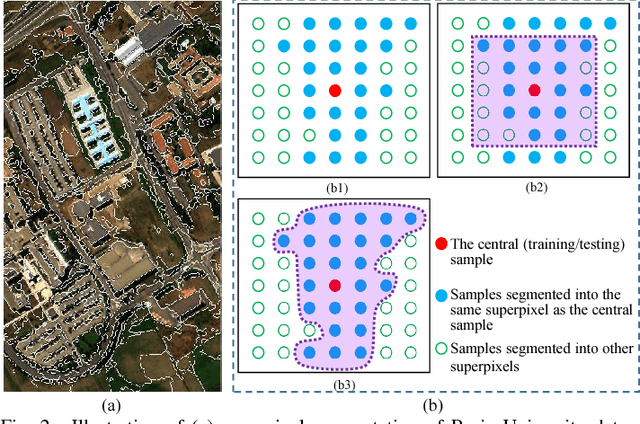
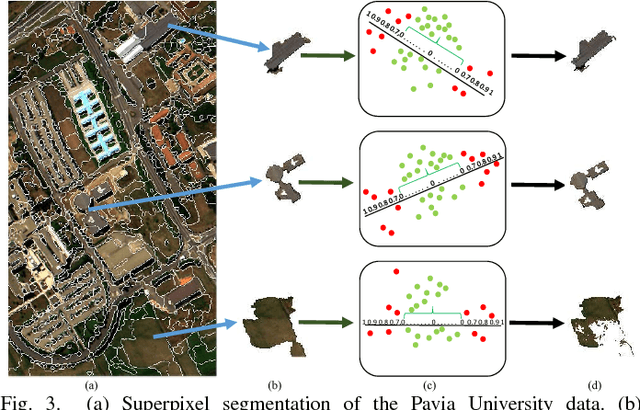
This paper presents a tensor alignment (TA) based domain adaptation method for hyperspectral image (HSI) classification. To be specific, HSIs in both domains are first segmented into superpixels and tensors of both domains are constructed to include neighboring samples from single superpixel. Then we consider the subspace invariance between two domains as projection matrices and original tensors are projected as core tensors with lower dimensions into the invariant tensor subspace by applying Tucker decomposition. To preserve geometric information in original tensors, we employ a manifold regularization term for core tensors into the decomposition progress. The projection matrices and core tensors are solved in an alternating optimization manner and the convergence of TA algorithm is analyzed. In addition, a post-processing strategy is defined via pure samples extraction for each superpixel to further improve classification performance. Experimental results on four real HSIs demonstrate that the proposed method can achieve better performance compared with the state-of-the-art subspace learning methods when a limited amount of source labeled samples are available.