 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to EdgeRMM: Reinforced Memory Management for Class-Incremental Learning
Jan 14, 2023Class-Incremental Learning (CIL) [40] trains classifiers under a strict memory budget: in each incremental phase, learning is done for new data, most of which is abandoned to free space for the next phase. The preserved data are exemplars used for replaying. However, existing methods use a static and ad hoc strategy for memory allocation, which is often sub-optimal. In this work, we propose a dynamic memory management strategy that is optimized for the incremental phases and different object classes. We call our method reinforced memory management (RMM), leveraging reinforcement learning. RMM training is not naturally compatible with CIL as the past, and future data are strictly non-accessible during the incremental phases. We solve this by training the policy function of RMM on pseudo CIL tasks, e.g., the tasks built on the data of the 0-th phase, and then applying it to target tasks. RMM propagates two levels of actions: Level-1 determines how to split the memory between old and new classes, and Level-2 allocates memory for each specific class. In essence, it is an optimizable and general method for memory management that can be used in any replaying-based CIL method. For evaluation, we plug RMM into two top-performing baselines (LUCIR+AANets and POD+AANets [30]) and conduct experiments on three benchmarks (CIFAR-100, ImageNet-Subset, and ImageNet-Full). Our results show clear improvements, e.g., boosting POD+AANets by 3.6%, 4.4%, and 1.9% in the 25-Phase settings of the above benchmarks, respectively.
Online Hyperparameter Optimization for Class-Incremental Learning
Jan 11, 2023



Class-incremental learning (CIL) aims to train a classification model while the number of classes increases phase-by-phase. An inherent challenge of CIL is the stability-plasticity tradeoff, i.e., CIL models should keep stable to retain old knowledge and keep plastic to absorb new knowledge. However, none of the existing CIL models can achieve the optimal tradeoff in different data-receiving settings--where typically the training-from-half (TFH) setting needs more stability, but the training-from-scratch (TFS) needs more plasticity. To this end, we design an online learning method that can adaptively optimize the tradeoff without knowing the setting as a priori. Specifically, we first introduce the key hyperparameters that influence the trade-off, e.g., knowledge distillation (KD) loss weights, learning rates, and classifier types. Then, we formulate the hyperparameter optimization process as an online Markov Decision Process (MDP) problem and propose a specific algorithm to solve it. We apply local estimated rewards and a classic bandit algorithm Exp3 [4] to address the issues when applying online MDP methods to the CIL protocol. Our method consistently improves top-performing CIL methods in both TFH and TFS settings, e.g., boosting the average accuracy of TFH and TFS by 2.2 percentage points on ImageNet-Full, compared to the state-of-the-art [23].
Learning by Sorting: Self-supervised Learning with Group Ordering Constraints
Jan 05, 2023



Contrastive learning has become a prominent ingredient in learning representations from unlabeled data. However, existing methods primarily consider pairwise relations. This paper proposes a new approach towards self-supervised contrastive learning based on Group Ordering Constraints (GroCo). The GroCo loss leverages the idea of comparing groups of positive and negative images instead of pairs of images. Building on the recent success of differentiable sorting algorithms, group ordering constraints enforce that the distances of all positive samples (a positive group) are smaller than the distances of all negative images (a negative group); thus, enforcing positive samples to gather around an anchor. This leads to a more holistic optimization of the local neighborhoods. We evaluate the proposed setting on a suite of competitive self-supervised learning benchmarks and show that our method is not only competitive to current methods in the case of linear probing but also leads to higher consistency in local representations, as can be seen from a significantly improved k-NN performance across all benchmarks.
Urban Scene Semantic Segmentation with Low-Cost Coarse Annotation
Dec 15, 2022



For best performance, today's semantic segmentation methods use large and carefully labeled datasets, requiring expensive annotation budgets. In this work, we show that coarse annotation is a low-cost but highly effective alternative for training semantic segmentation models. Considering the urban scene segmentation scenario, we leverage cheap coarse annotations for real-world captured data, as well as synthetic data to train our model and show competitive performance compared with finely annotated real-world data. Specifically, we propose a coarse-to-fine self-training framework that generates pseudo labels for unlabeled regions of the coarsely annotated data, using synthetic data to improve predictions around the boundaries between semantic classes, and using cross-domain data augmentation to increase diversity. Our extensive experimental results on Cityscapes and BDD100k datasets demonstrate that our method achieves a significantly better performance vs annotation cost tradeoff, yielding a comparable performance to fully annotated data with only a small fraction of the annotation budget. Also, when used as pretraining, our framework performs better compared to the standard fully supervised setting.
Discovering Class-Specific GAN Controls for Semantic Image Synthesis
Dec 02, 2022



Prior work has extensively studied the latent space structure of GANs for unconditional image synthesis, enabling global editing of generated images by the unsupervised discovery of interpretable latent directions. However, the discovery of latent directions for conditional GANs for semantic image synthesis (SIS) has remained unexplored. In this work, we specifically focus on addressing this gap. We propose a novel optimization method for finding spatially disentangled class-specific directions in the latent space of pretrained SIS models. We show that the latent directions found by our method can effectively control the local appearance of semantic classes, e.g., changing their internal structure, texture or color independently from each other. Visual inspection and quantitative evaluation of the discovered GAN controls on various datasets demonstrate that our method discovers a diverse set of unique and semantically meaningful latent directions for class-specific edits.
An Embarrassingly Simple Baseline for Imbalanced Semi-Supervised Learning
Nov 20, 2022



Semi-supervised learning (SSL) has shown great promise in leveraging unlabeled data to improve model performance. While standard SSL assumes uniform data distribution, we consider a more realistic and challenging setting called imbalanced SSL, where imbalanced class distributions occur in both labeled and unlabeled data. Although there are existing endeavors to tackle this challenge, their performance degenerates when facing severe imbalance since they can not reduce the class imbalance sufficiently and effectively. In this paper, we study a simple yet overlooked baseline -- SimiS -- which tackles data imbalance by simply supplementing labeled data with pseudo-labels, according to the difference in class distribution from the most frequent class. Such a simple baseline turns out to be highly effective in reducing class imbalance. It outperforms existing methods by a significant margin, e.g., 12.8%, 13.6%, and 16.7% over previous SOTA on CIFAR100-LT, FOOD101-LT, and ImageNet127 respectively. The reduced imbalance results in faster convergence and better pseudo-label accuracy of SimiS. The simplicity of our method also makes it possible to be combined with other re-balancing techniques to improve the performance further. Moreover, our method shows great robustness to a wide range of data distributions, which holds enormous potential in practice. Code will be publicly available.
Normalization Perturbation: A Simple Domain Generalization Method for Real-World Domain Shifts
Nov 09, 2022



Improving model's generalizability against domain shifts is crucial, especially for safety-critical applications such as autonomous driving. Real-world domain styles can vary substantially due to environment changes and sensor noises, but deep models only know the training domain style. Such domain style gap impedes model generalization on diverse real-world domains. Our proposed Normalization Perturbation (NP) can effectively overcome this domain style overfitting problem. We observe that this problem is mainly caused by the biased distribution of low-level features learned in shallow CNN layers. Thus, we propose to perturb the channel statistics of source domain features to synthesize various latent styles, so that the trained deep model can perceive diverse potential domains and generalizes well even without observations of target domain data in training. We further explore the style-sensitive channels for effective style synthesis. Normalization Perturbation only relies on a single source domain and is surprisingly effective and extremely easy to implement. Extensive experiments verify the effectiveness of our method for generalizing models under real-world domain shifts.
Motion Transformer with Global Intention Localization and Local Movement Refinement
Sep 27, 2022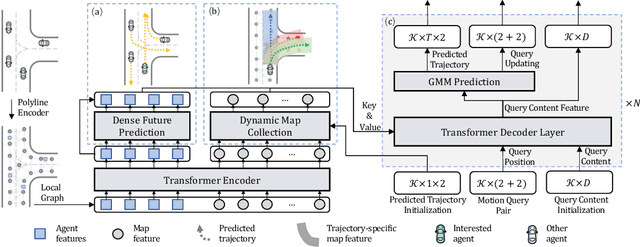
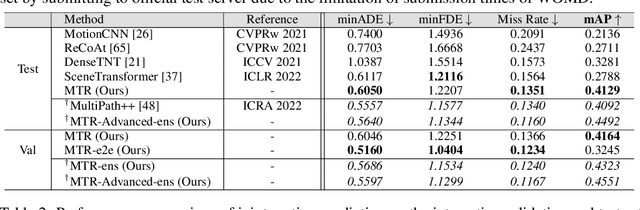
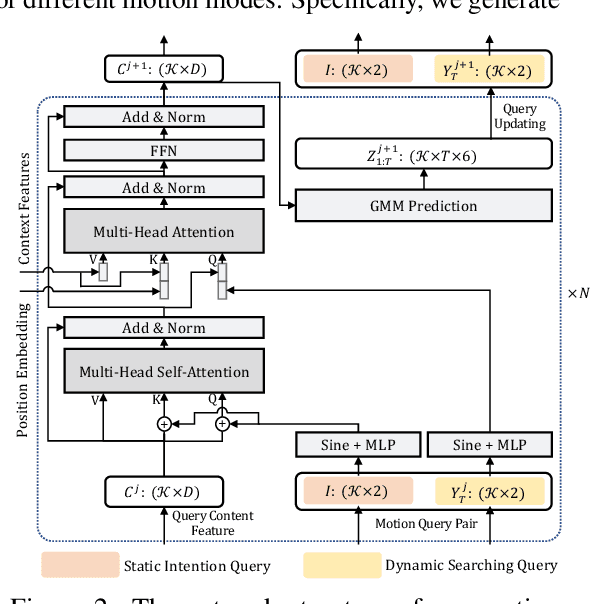
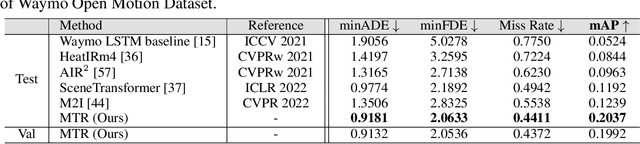
Predicting multimodal future behavior of traffic participants is essential for robotic vehicles to make safe decisions. Existing works explore to directly predict future trajectories based on latent features or utilize dense goal candidates to identify agent's destinations, where the former strategy converges slowly since all motion modes are derived from the same feature while the latter strategy has efficiency issue since its performance highly relies on the density of goal candidates. In this paper, we propose Motion TRansformer (MTR) framework that models motion prediction as the joint optimization of global intention localization and local movement refinement. Instead of using goal candidates, MTR incorporates spatial intention priors by adopting a small set of learnable motion query pairs. Each motion query pair takes charge of trajectory prediction and refinement for a specific motion mode, which stabilizes the training process and facilitates better multimodal predictions. Experiments show that MTR achieves state-of-the-art performance on both the marginal and joint motion prediction challenges, ranking 1st on the leaderboards of Waymo Open Motion Dataset. Code will be available at https://github.com/sshaoshuai/MTR.
Leveraging Self-Supervised Training for Unintentional Action Recognition
Sep 23, 2022Unintentional actions are rare occurrences that are difficult to define precisely and that are highly dependent on the temporal context of the action. In this work, we explore such actions and seek to identify the points in videos where the actions transition from intentional to unintentional. We propose a multi-stage framework that exploits inherent biases such as motion speed, motion direction, and order to recognize unintentional actions. To enhance representations via self-supervised training for the task of unintentional action recognition we propose temporal transformations, called Temporal Transformations of Inherent Biases of Unintentional Actions (T2IBUA). The multi-stage approach models the temporal information on both the level of individual frames and full clips. These enhanced representations show strong performance for unintentional action recognition tasks. We provide an extensive ablation study of our framework and report results that significantly improve over the state-of-the-art.
TeST: Test-time Self-Training under Distribution Shift
Sep 23, 2022
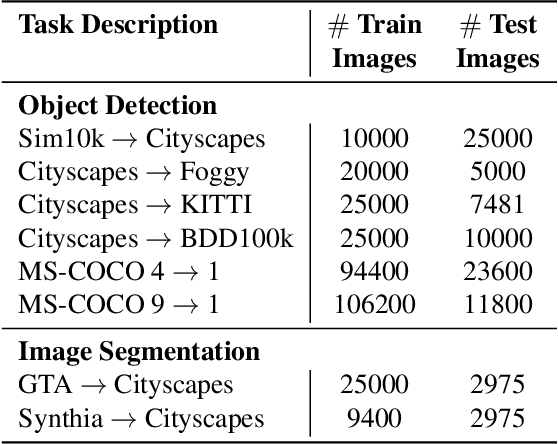
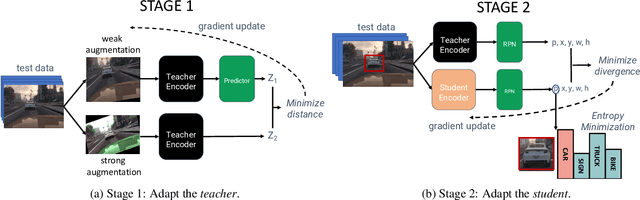
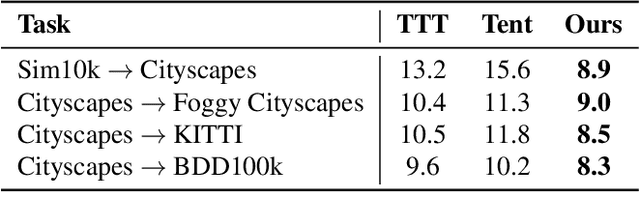
Despite their recent success, deep neural networks continue to perform poorly when they encounter distribution shifts at test time. Many recently proposed approaches try to counter this by aligning the model to the new distribution prior to inference. With no labels available this requires unsupervised objectives to adapt the model on the observed test data. In this paper, we propose Test-Time Self-Training (TeST): a technique that takes as input a model trained on some source data and a novel data distribution at test time, and learns invariant and robust representations using a student-teacher framework. We find that models adapted using TeST significantly improve over baseline test-time adaptation algorithms. TeST achieves competitive performance to modern domain adaptation algorithms, while having access to 5-10x less data at time of adaption. We thoroughly evaluate a variety of baselines on two tasks: object detection and image segmentation and find that models adapted with TeST. We find that TeST sets the new state-of-the art for test-time domain adaptation algorithms.