 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to EdgeA Comprehensive Evaluation of Tool-Assisted Generation Strategies
Oct 16, 2023



A growing area of research investigates augmenting language models with tools (e.g., search engines, calculators) to overcome their shortcomings (e.g., missing or incorrect knowledge, incorrect logical inferences). Various few-shot tool-usage strategies have been proposed. However, there is no systematic and fair comparison across different strategies, or between these strategies and strong baselines that do not leverage tools. We conduct an extensive empirical analysis, finding that (1) across various datasets, example difficulty levels, and models, strong no-tool baselines are competitive to tool-assisted strategies, implying that effectively using tools with in-context demonstrations is a difficult unsolved problem; (2) for knowledge-retrieval tasks, strategies that *refine* incorrect outputs with tools outperform strategies that retrieve relevant information *ahead of* or *during generation*; (3) tool-assisted strategies are expensive in the number of tokens they require to work -- incurring additional costs by orders of magnitude -- which does not translate into significant improvement in performance. Overall, our findings suggest that few-shot tool integration is still an open challenge, emphasizing the need for comprehensive evaluations of future strategies to accurately assess their *benefits* and *costs*.
Attributed Question Answering: Evaluation and Modeling for Attributed Large Language Models
Dec 15, 2022



Large language models (LLMs) have shown impressive results across a variety of tasks while requiring little or no direct supervision. Further, there is mounting evidence that LLMs may have potential in information-seeking scenarios. We believe the ability of an LLM to attribute the text that it generates is likely to be crucial for both system developers and users in this setting. We propose and study Attributed QA as a key first step in the development of attributed LLMs. We develop a reproducable evaluation framework for the task, using human annotations as a gold standard and a correlated automatic metric that we show is suitable for development settings. We describe and benchmark a broad set of architectures for the task. Our contributions give some concrete answers to two key questions (How to measure attribution?, and How well do current state-of-the-art methods perform on attribution?), and give some hints as to how to address a third key question (How to build LLMs with attribution?).
Coreference Resolution through a seq2seq Transition-Based System
Nov 22, 2022Most recent coreference resolution systems use search algorithms over possible spans to identify mentions and resolve coreference. We instead present a coreference resolution system that uses a text-to-text (seq2seq) paradigm to predict mentions and links jointly. We implement the coreference system as a transition system and use multilingual T5 as an underlying language model. We obtain state-of-the-art accuracy on the CoNLL-2012 datasets with 83.3 F1-score for English (a 2.3 higher F1-score than previous work (Dobrovolskii, 2021)) using only CoNLL data for training, 68.5 F1-score for Arabic (+4.1 higher than previous work) and 74.3 F1-score for Chinese (+5.3). In addition we use the SemEval-2010 data sets for experiments in the zero-shot setting, a few-shot setting, and supervised setting using all available training data. We get substantially higher zero-shot F1-scores for 3 out of 4 languages than previous approaches and significantly exceed previous supervised state-of-the-art results for all five tested languages.
Honest Students from Untrusted Teachers: Learning an Interpretable Question-Answering Pipeline from a Pretrained Language Model
Oct 05, 2022
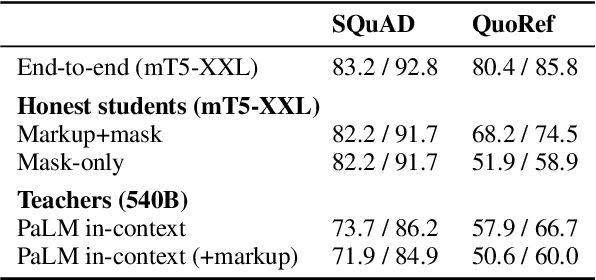


Explainable question answering systems should produce not only accurate answers but also rationales that justify their reasoning and allow humans to check their work. But what sorts of rationales are useful and how can we train systems to produce them? We propose a new style of rationale for open-book question answering, called \emph{markup-and-mask}, which combines aspects of extractive and free-text explanations. In the markup phase, the passage is augmented with free-text markup that enables each sentence to stand on its own outside the discourse context. In the masking phase, a sub-span of the marked-up passage is selected. To train a system to produce markup-and-mask rationales without annotations, we leverage in-context learning. Specifically, we generate silver annotated data by sending a series of prompts to a frozen pretrained language model, which acts as a teacher. We then fine-tune a smaller student model by training on the subset of rationales that led to correct answers. The student is "honest" in the sense that it is a pipeline: the rationale acts as a bottleneck between the passage and the answer, while the "untrusted" teacher operates under no such constraints. Thus, we offer a new way to build trustworthy pipeline systems from a combination of end-task annotations and frozen pretrained language models.
Named Entity Recognition as Dependency Parsing
Jun 13, 2020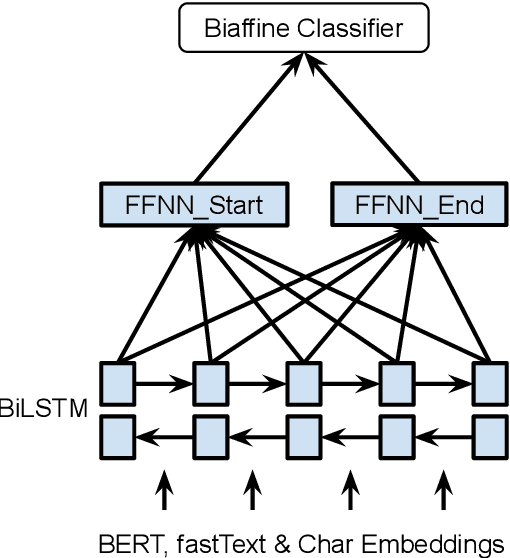

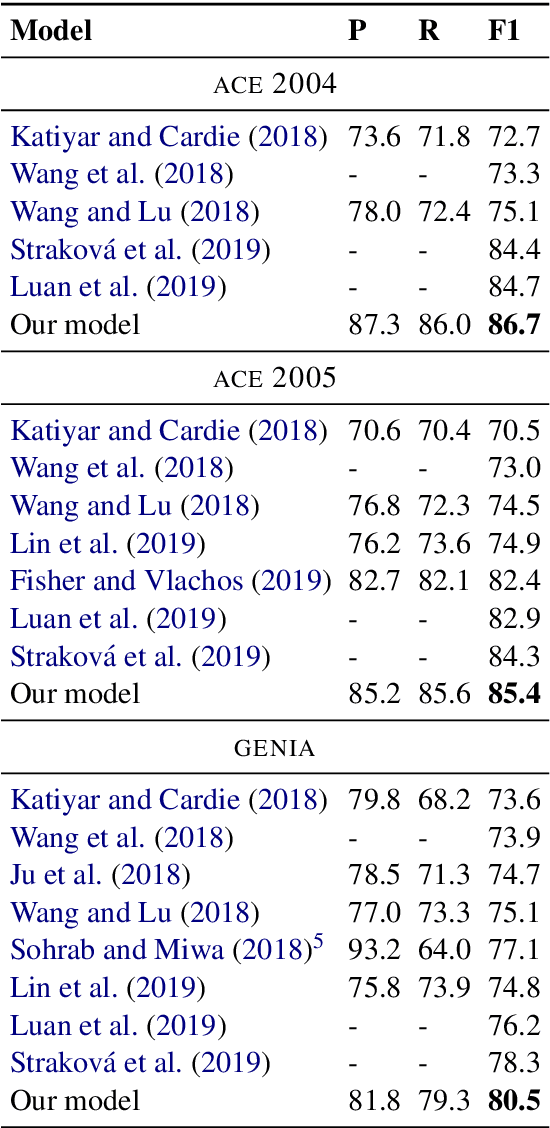
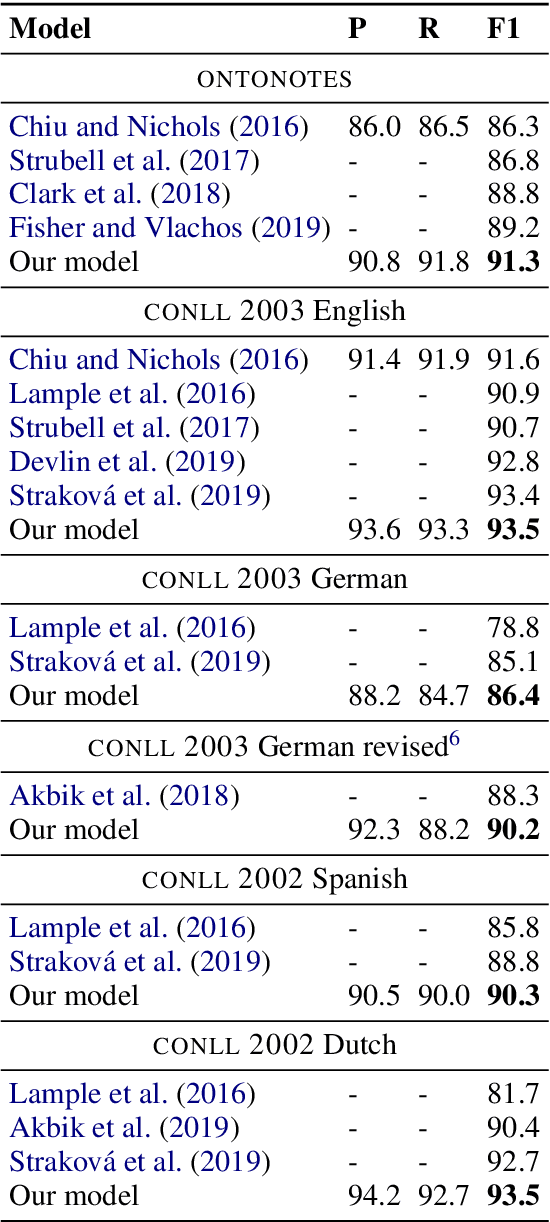
Named Entity Recognition (NER) is a fundamental task in Natural Language Processing, concerned with identifying spans of text expressing references to entities. NER research is often focused on flat entities only (flat NER), ignoring the fact that entity references can be nested, as in [Bank of [China]] (Finkel and Manning, 2009). In this paper, we use ideas from graph-based dependency parsing to provide our model a global view on the input via a biaffine model (Dozat and Manning, 2017). The biaffine model scores pairs of start and end tokens in a sentence which we use to explore all spans, so that the model is able to predict named entities accurately. We show that the model works well for both nested and flat NER through evaluation on 8 corpora and achieving SoTA performance on all of them, with accuracy gains of up to 2.2 percentage points.
On Faithfulness and Factuality in Abstractive Summarization
May 02, 2020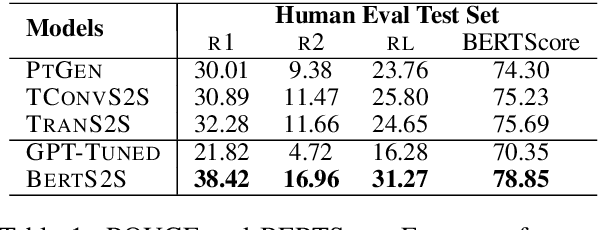

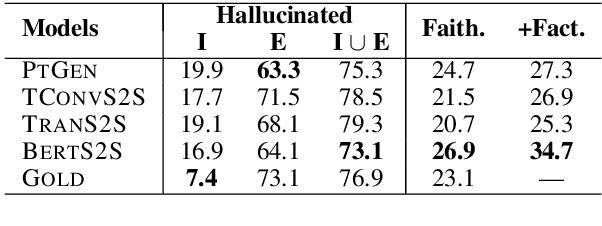
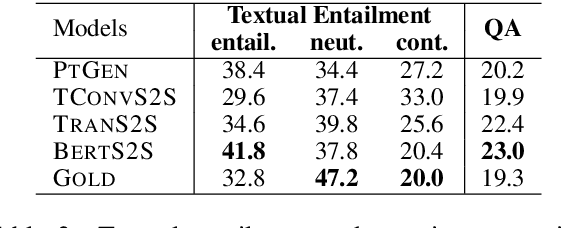
It is well known that the standard likelihood training and approximate decoding objectives in neural text generation models lead to less human-like responses for open-ended tasks such as language modeling and story generation. In this paper we have analyzed limitations of these models for abstractive document summarization and found that these models are highly prone to hallucinate content that is unfaithful to the input document. We conducted a large scale human evaluation of several neural abstractive summarization systems to better understand the types of hallucinations they produce. Our human annotators found substantial amounts of hallucinated content in all model generated summaries. However, our analysis does show that pretrained models are better summarizers not only in terms of raw metrics, i.e., ROUGE, but also in generating faithful and factual summaries as evaluated by humans. Furthermore, we show that textual entailment measures better correlate with faithfulness than standard metrics, potentially leading the way to automatic evaluation metrics as well as training and decoding criteria.
Neural Mention Detection
Jul 29, 2019
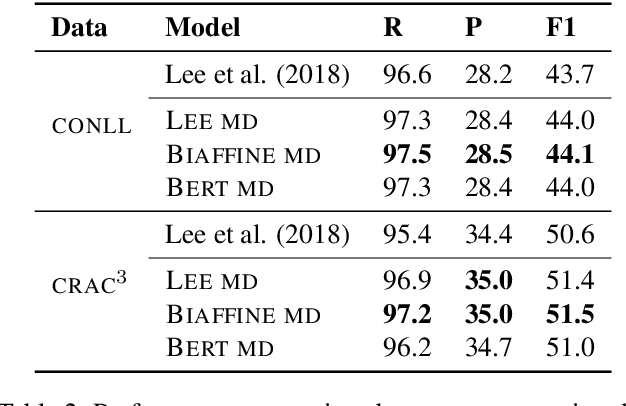
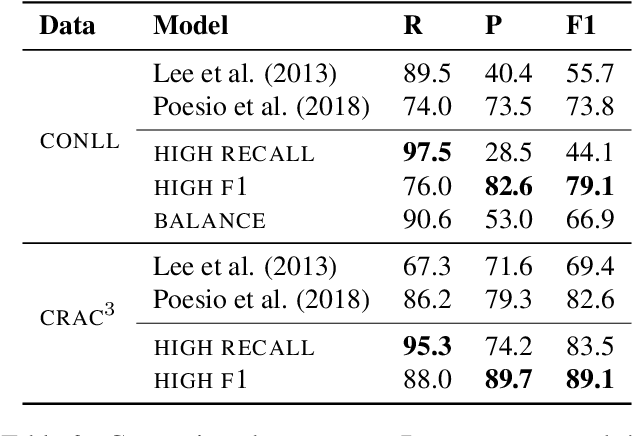
Mention detection is an important aspect of the annotation task and interpretation process for applications such as coreference resolution. In this work, we propose and compare three neural network-based approaches to mention detection. The first approach is based on the mention detection part of a state-of-the-art coreference resolution system; the second uses ELMo embeddings together with a bidirectional LSTM and a biaffine classifier; the third approach uses the recently introduced BERT model. Our best model (using a biaffine classifier) achieved gains of up to 1.8 percentage points on mention recall when compared with a strong baseline in a HIGH RECALL setting. The same model achieved improvements of up to 5.3 and 6.5 p.p. when compared with the best-reported mention detection F1 on thevCONLL and CRAC data sets respectively in a HIGH F1 setting. We further evaluated our models on coreference resolution by using mentions predicted by our best model in the start-of-the-art coreference systems. The enhanced model achieved absolute improvements of up to 1.7 and 0.7 p.p. when compared with the best pipeline system and the state-of-the-art end-to-end system respectively.
82 Treebanks, 34 Models: Universal Dependency Parsing with Multi-Treebank Models
Sep 06, 2018
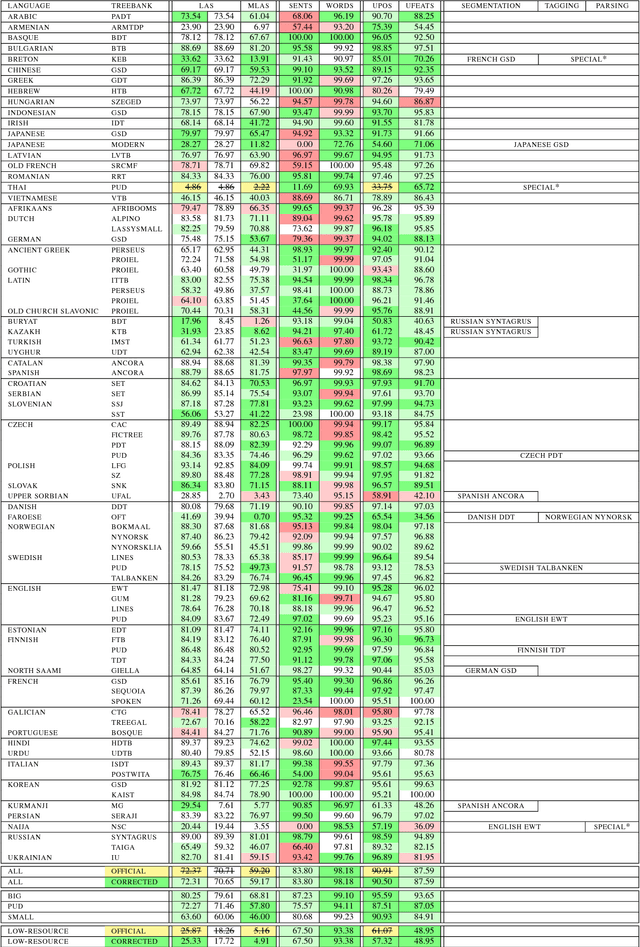
We present the Uppsala system for the CoNLL 2018 Shared Task on universal dependency parsing. Our system is a pipeline consisting of three components: the first performs joint word and sentence segmentation; the second predicts part-of- speech tags and morphological features; the third predicts dependency trees from words and tags. Instead of training a single parsing model for each treebank, we trained models with multiple treebanks for one language or closely related languages, greatly reducing the number of models. On the official test run, we ranked 7th of 27 teams for the LAS and MLAS metrics. Our system obtained the best scores overall for word segmentation, universal POS tagging, and morphological features.
Morphosyntactic Tagging with a Meta-BiLSTM Model over Context Sensitive Token Encodings
May 21, 2018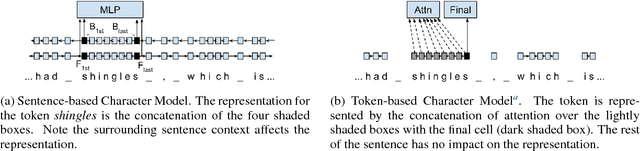
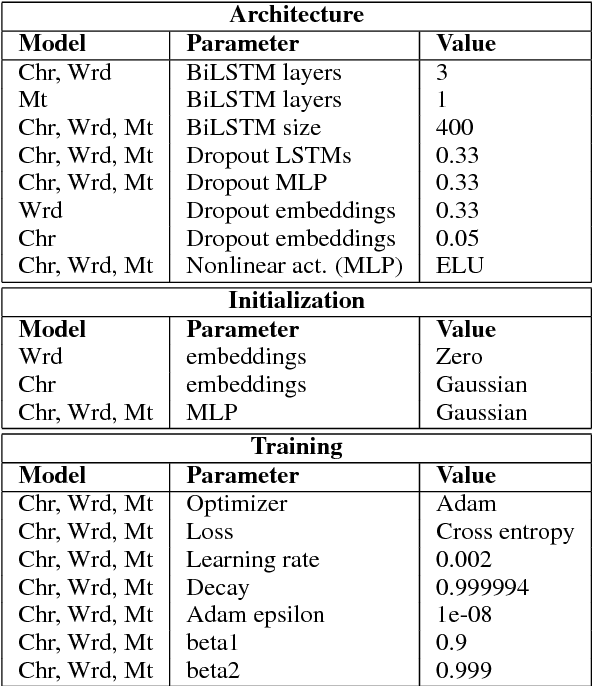
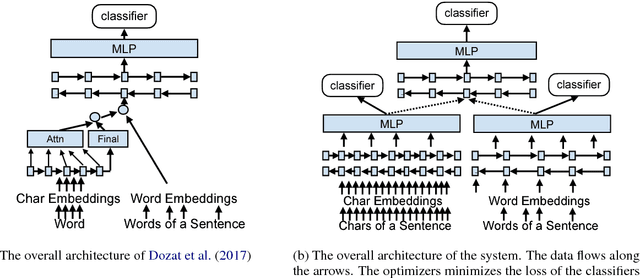
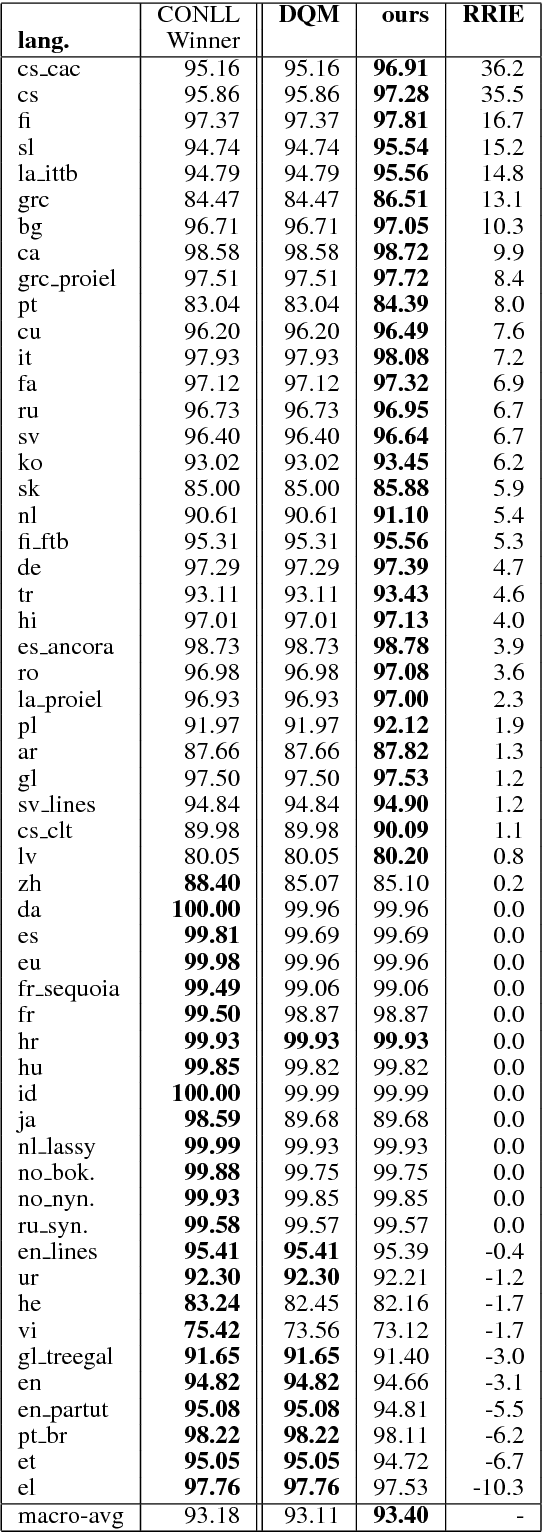
The rise of neural networks, and particularly recurrent neural networks, has produced significant advances in part-of-speech tagging accuracy. One characteristic common among these models is the presence of rich initial word encodings. These encodings typically are composed of a recurrent character-based representation with learned and pre-trained word embeddings. However, these encodings do not consider a context wider than a single word and it is only through subsequent recurrent layers that word or sub-word information interacts. In this paper, we investigate models that use recurrent neural networks with sentence-level context for initial character and word-based representations. In particular we show that optimal results are obtained by integrating these context sensitive representations through synchronized training with a meta-model that learns to combine their states. We present results on part-of-speech and morphological tagging with state-of-the-art performance on a number of languages.
A Simple LSTM model for Transition-based Dependency Parsing
Sep 08, 2017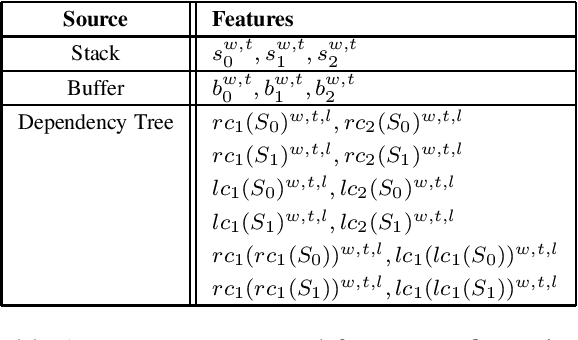
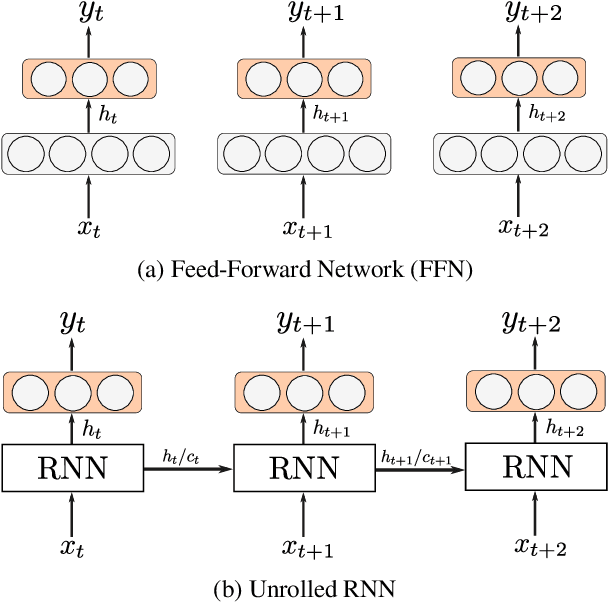
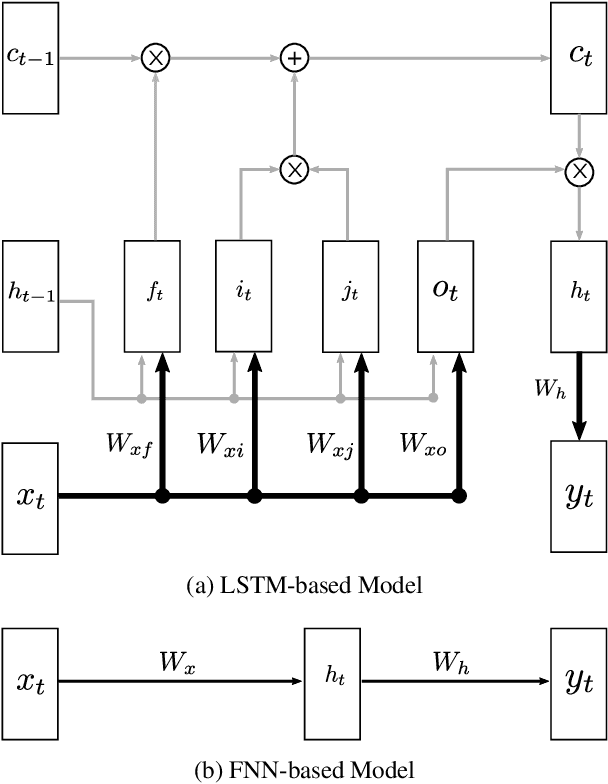
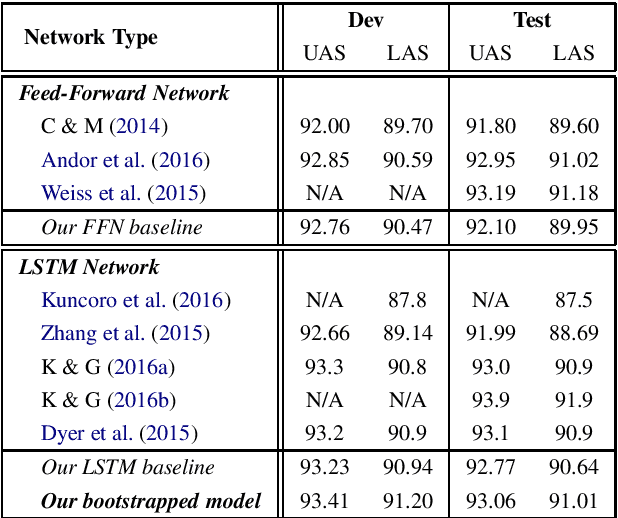
We present a simple LSTM-based transition-based dependency parser. Our model is composed of a single LSTM hidden layer replacing the hidden layer in the usual feed-forward network architecture. We also propose a new initialization method that uses the pre-trained weights from a feed-forward neural network to initialize our LSTM-based model. We also show that using dropout on the input layer has a positive effect on performance. Our final parser achieves a 93.06% unlabeled and 91.01% labeled attachment score on the Penn Treebank. We additionally replace LSTMs with GRUs and Elman units in our model and explore the effectiveness of our initialization method on individual gates constituting all three types of RNN units.